







Java基础(一)
1、注释、关键字、标识符
注释
平时我们编写代码,在代码量比较少的时候,我们还可以看懂自己写的,但是当项目结构一旦复杂起来,我们就需要用到注释了。
注释并不会被执行,是给我们写代码的人看的
书写注释是一个非常好的习惯
平时写代码一定要注意规范。
Java中的注释有三种:
- 单行注释:单行注释并不会输出,是写给人看的 //单行注释
- 多行注释:多行注释可以注释一段文字 /* 多行注释 */
- 文档注释:(JavaDoc)有功能,可以加参数 /** 文档注释 */
public class Demo01 {
public static void main(String[] args) {
//单行注释
//单行注释并不会输出,是写给人看的
//输出HelloWorld
System.out.println("HelloWorld");
//多行注释 /* 多行注释 */
/*
多行注释可以注释一段文字
1、xxxx
2、xxxx
3、xxxx
*/
//JavaDoc:文档注释(有功能,可以加参数) /** 文档注释 */
/**
* @Description HelloWorld
* @Auther 小小树苗l
*
*/
}
}
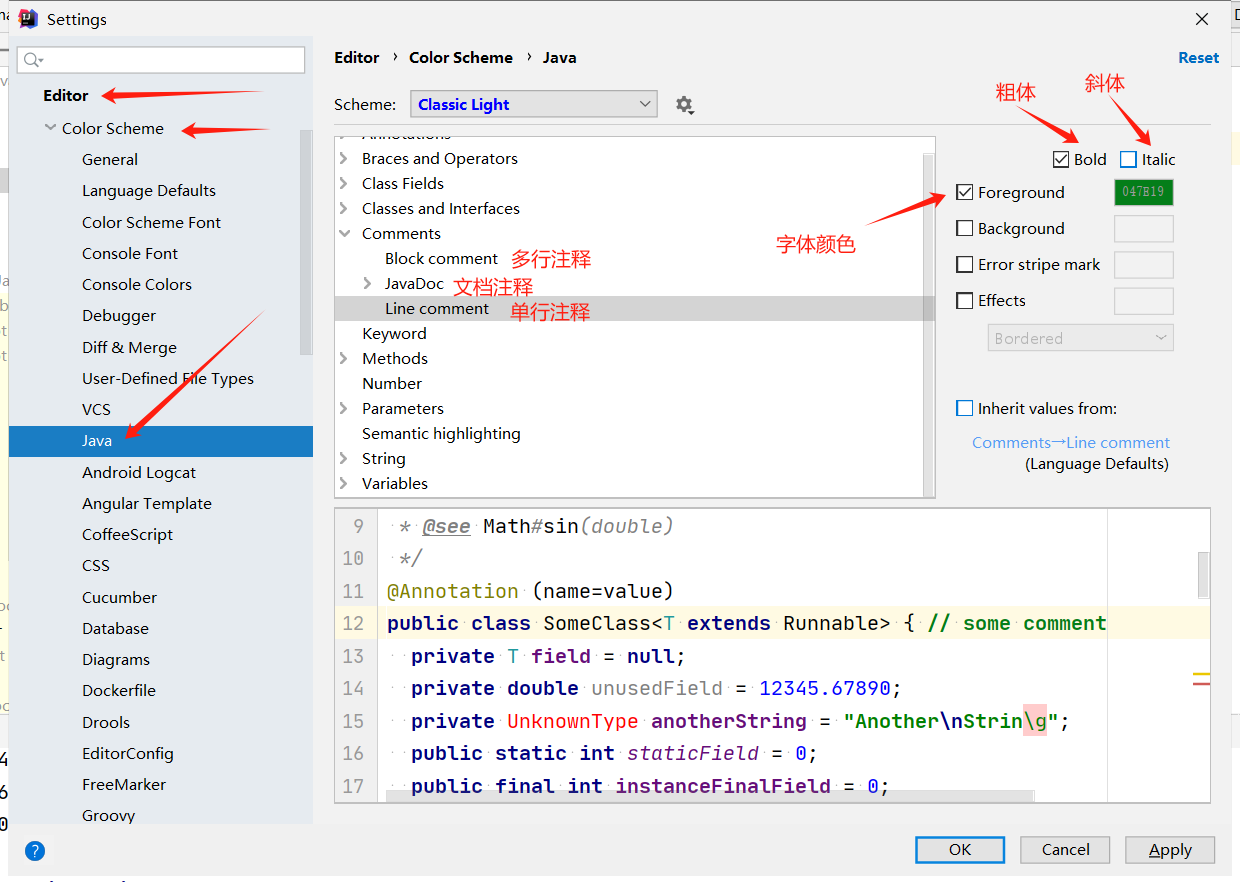
修改注释样式
File——>settings——>Editor——>Color Scheme——>Java——>Comments
关键字
Java所有的关键字

标识符
Java所有的组成部分都需要名字。类名、变量名以及方法名都被称为标识符。
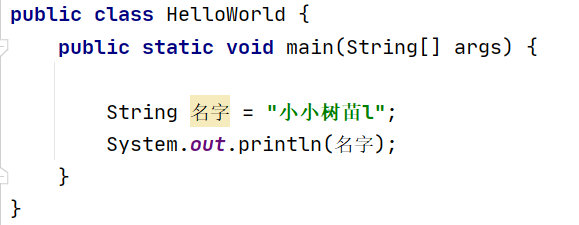
public class Demo01 {
public static void main(String[] args) {
String name = "小小树苗l";
System.out.println(name);
}
}
这里的Helloword为类名,name为变量名,main为方法名。
标识符注意点
- 所有的标识符都应该以字母(A-Z或者a-z)、美元符($)、或者下划线(_)开始
- 首字符之后可以是字母(A-Z或者a-z)、美元符($)、下划线(_)或数字的任何字符组合
- 不能使用关键字作为变量名或方法名。
- 标识符是大小写敏感的
- 合法标识符举例:age、$salary、_value、__1_value
- 非法标识符举例:123abc、-salary、#abc
- public static void main(String[]args){
- 可以使用中文命名,但是一般不建议这样去使用,也不建议使用拼音,很Low
2、数据类型
-
强类型语言(安全性高,速度低)
- 要求变量的使用要严格符合规定,所有变量都必须先定义后才能使用
-
弱类型语言
- 变量的使用可以不符合规定,VB、JS这种语言就属于弱类型语言
-
Java的数据类型分为两大类
-
基本类型(primitive type)
-
引用类型(reference type)
-

byte占1个字节,int和float都占4个字节,long和double都占8个字节,而boolean占1位,这里到底什么是字节和位呢?
什么是字节
-
位(bit):是计算机 内部数据 储存的最小单位,11001100是一个八位二进制数。
-
字节(byte):是计算机中 数据处理 的基本单位,习惯上用大写B来表示,
-
1B(byte,字节)=8bit(位)
-
字符:是指计算机中使用的字母、数字、字和符号
-
1bit表示1位,
-
1Byte表示一个字节1B=8b。
-
1024B=1KB
-
1024KB=1M
-
1024M=1G.
思考:电脑的32位和64位的区别是什么呢?
| 32位 | 64位 | |
|---|---|---|
| 数据处理能力 | 每次处理4个字节的数据 | 每次处理8个字节的数据,速度更快 |
| 内存寻址能力 | 最多只能识别或使用4GB的内存 | 能够支持远超4GB的内存容量,理论上没有上限(但受物理内存限制) |
| 软件兼容性 | 主要运行32位软件 | 可以运行64位和32位软件,兼容性更广 |
| 系统资源消耗 | 相对较低 | 可能消耗更多的CPU和内存资源,但大多数情况下可接受 |
| 安全性 | 基本的内存管理和安全特性 | 通常具有更高级的内存管理和安全特性,安全性更高 |
数据类型拓展及面试题讲解
1、整数拓展
public class Demo03 {
public static void main(String[] args) {
//整数拓展 进制问题
//二进制0b 十进制 八进制0 十六进制0x
int i = 0b10; //二进制0b
int i1 = 10;
int i2 = 010; //八进制0
int i3 = 0x10; //十六进制0x 0~9 A~F
int i4 = 0x1A;
System.out.println(i);
System.out.println(i1);
System.out.println(i2);
System.out.println(i3);
System.out.println(i4);
}
}
输出结果
2
10
8
16
26
知识点
- 进制基础:
- 十进制:我们日常生活中最常用的进制,每一位上的数字可以是0-9。
- 二进制:计算机内部使用的进制,每一位上的数字只能是0或1。
- 八进制:每一位上的数字可以是0-7。
- 十六进制:每一位上的数字可以是0-9以及A-F(或a-f,大小写不敏感)。
- Java中的表示方法:
- 十进制:直接写数字,如
10。 - 二进制:以
0b或0B开头,如0b10(表示十进制的2)。 - 八进制:以
0开头(注意,单独的0表示八进制的0,而不是无符号整数0),如010(表示十进制的8)。 - 十六进制:以
0x或0X开头,如0x10(表示十进制的16)和0x1A(表示十进制的26)。
- 十进制:直接写数字,如
- 输出:
- 在Java中,使用
System.out.println()可以输出整数的十进制表示。尽管在代码中我们使用了不同的进制来表示整数,但输出时它们都会被转换为十进制并显示。
- 在Java中,使用
- 注意事项:
- 当使用八进制表示时,要特别小心,因为以
0开头的数字在Java中会被视为八进制(除非它是0本身)。 - 十六进制中的字母A-F或a-f都可以使用,大小写不敏感。
- 当使用八进制表示时,要特别小心,因为以
- 实际应用:
- 二进制:在低级编程、硬件设计和计算机科学理论中非常重要。
- 八进制:在某些上下文中(如Unix文件权限)可能会使用到。
- 十六进制:在表示内存地址、颜色代码和机器代码等场景中经常使用。
2、浮点数拓展
public class Demo03 {
public static void main(String[] args) {
//浮点数拓展 银行业务怎么表示?钱
//使用BigDecimal 数学工具类
//float和double是有问题的
//float 浮点数能表现的字长是有限的 也是离散的 浮点数会舍入误差 结果是个大约数 接近但不等于
//结论:最好完全避免使用浮点数进行比较
//例1
float f = 0.1f; //0.1
double d = 1.0/10; //0.1
System.out.println(f==d); //false
System.out.println(f); //0,1
System.out.println(d); //0.1
//例2
float f1 = 829714821892748f; //任意一个数
float f2 = f1 + 1;
System.out.println(f1==f2); //true
}
}
输出结果
false
0.1
0.1
true
例1思考:为什么看上去相同的数返回False呢
结果是 false 而不是 true 是因为 float 和 double 是两种不同的数据类型,它们在内存中的表示方式是不同的,特别是关于精度的部分。尽管在这个例子中 f 和 d 都表示数值 0.1,但由于 float 类型的精度低于 double 类型,所以它们实际上在内存中的表示并不完全相同。
具体来说:
float类型通常有 23 位尾数(mantissa)和 8 位指数(exponent),而double类型通常有 52 位尾数和 11 位指数。这意味着double类型可以表示更大范围、更高精度的数值。- 当我们将
0.1赋值给float类型的变量f时,实际上这个值在float精度下是近似的,因为0.1在二进制下是一个无限循环小数,无法精确表示。 - 同样地,当我们用
1.0 / 10得到一个double类型的值时,这个值在double精度下是更精确的近似值。
由于 f 和 d 在内存中的二进制表示不同,所以比较 f == d 时会返回 false。
当你打印这两个值时,由于输出格式的限制(例如,可能只打印小数点后几位),它们看起来可能是一样的,但实际上它们的内部表示是不同的。
为了验证这一点,可以尝试打印它们的十六进制表示,例如使用 Float.toHexString(f) 和 Double.toHexString(d) 方法,你会看到它们是不同的。
例2思考:为什么明明+1,但是返回的还是true呢
这是浮点数的一个常见问题,称为“浮点数精度丢失”或“浮点数的舍入误差”。在Java中,float 类型只有大约 7 位十进制有效数字的精度。当尝试将一个超过这个精度范围的大整数直接赋值给 float 变量或进行运算时,就会发生精度丢失。
具体来说,当将 829714821892748 赋值给 float 类型的变量 f1 时,这个数已经远远超出了 float 类型的精度范围。因此,这个数在转换为 float 时会被舍入到一个接近但不同的值。同样地,当对 f1 加1时,由于之前的舍入误差和 float 的精度限制,f1 + 1 的结果也可能被舍入到与 f1 相同的值。
这就是为什么 f1 == f2 返回 true 的原因。但是,这并不意味着 f1 和 f2 在数学上是相等的,只是由于精度限制和舍入误差,它们在 float 类型的表示上是相同的。
要验证这一点,可以打印出 f1 和 f2 的值,可能会发现它们看起来是相同的,或者至少非常接近,但由于舍入误差,它们并不完全相等。如果打印它们的十六进制表示,会更清楚地看到它们之间的差异。
为了避免这种问题,当需要处理大数或需要高精度计算时,应该使用 double 类型(尽管它也有精度限制)或 BigDecimal 类,后者提供了任意精度的十进制数运算。
知识点
-
浮点数精度问题
-
float和double都是浮点类型,用于存储有小数部分的数。但它们的精度不同,double的精度高于float。 -
浮点数在计算机中通常是近似存储的,因为有些小数(如0.1)在二进制中是无限循环的,无法精确表示。
-
因此,直接比较两个浮点数是否相等(如
f == d)通常是不安全的,因为即使它们数学上相等,由于舍入误差,它们的内存表示也可能不同。
-
-
浮点数舍入误差
-
当一个数超过
float或double类型的精度范围时,会发生舍入误差。这意味着原始数值在转换为浮点数时可能会丢失一些精度。 -
在您的例2中,
829714821892748远远超出了float类型的精度范围,因此当它被转换为float类型并加1时,由于之前的舍入误差和float的精度限制,结果可能仍然是相同的float值。
-
-
最佳实践
-
避免直接比较浮点数:如果需要比较浮点数是否相等,应该检查它们的差的绝对值是否小于一个很小的阈值。
-
使用
BigDecimal:对于需要高精度计算的场景(如金融计算),应该使用BigDecimal类而不是float或double。 -
了解浮点数的范围和精度:在编写代码时,要确保你的数值在可表示范围内,并了解可能存在的精度损失。
-
打印浮点数的十六进制表示:使用
Float.toHexString(floatValue)和Double.toHexString(doubleValue)方法可以打印浮点数的十六进制表示,这有助于理解它们在内存中的实际表示。
-
-
注意事项
-
浮点数在计算机科学中是一个复杂且容易出错的主题。了解它们的限制和特性是避免潜在问题的关键。
-
当处理浮点数时,要特别小心,尤其是在需要精确比较或高精度计算的场景中。
-
3、字符拓展
public class Demo03 {
public static void main(String[] args) {
//字符拓展
char c1 = 'a';
char c2 = '中';
System.out.println(c1);
System.out.println((int)c1); //强制转换
System.out.println(c2);
System.out.println((int)c2); //强制转换
//所有的字符本质还是数字
//编码 Unicode编码 占2字节 最多可以表示65536个字符 0~65535
//Unicode编码 有一个ASCII表(97=a 65=A) 区间范围是U0000 ~ UFFFF (16进制)
//最早的Excel表格只有2^16=65536这么长
char c3 = '\u0061'; //61是十进制97的16位进制的表示,Unicode是16进制的
System.out.println(c3); //a
//转义字符
// \t 制表符
// \n 换行符
System.out.println("Hello\tworld"); //Hello world
System.out.println("Hello\nworld"); //Hello
//world
}
}
输出结果
a
97
中
20013
a
Hello world
Hello
world
知识点
-
字符类型(char):
- Java中的
char类型用于存储单个字符。 char类型使用Unicode编码,可以表示世界上几乎所有的字符,包括拉丁字母、中文、日文等。
- Java中的
-
字符与整数的转换:
- 字符在内存中实际上是以整数(Unicode编码)的形式存储的。
- 可以使用类型转换(如
(int)c1)将char类型的变量转换为int类型,显示其对应的Unicode编码值。
-
Unicode编码:
- Unicode是一个国际编码标准,用于统一编码全球的各种字符。
- Unicode编码使用16位(即2字节)来表示一个字符,因此可以表示最多65536个字符。
- Unicode编码范围是从
U+0000到U+FFFF(十六进制表示)。
-
ASCII表:
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是Unicode编码的一个子集,主要用于表示英语字符。
- ASCII编码只使用7位或8位二进制数,但在Unicode中,它占据了从
U+0000到U+007F的范围。
-
转义字符:
- 转义字符是一种特殊的字符序列,它以反斜杠(
\)开始,用于表示不能直接输入或无法直接显示的字符。 - 常见的转义字符包括
\t(制表符)、\n(换行符)、\\(反斜杠自身)等。
转义字符 描述 \t制表符(Tab),用于在输出中插入一个制表符,相当于按下Tab键 \n换行符,用于在输出中插入一个换行符,将光标移动到下一行的开头 \r回车符,用于将光标移动到当前行的开头(在某些系统中与 \n结合使用表示换行)\f换页符,用于在输出中插入一个换页符 \"双引号,用于在字符串常量中插入一个双引号 \'单引号,用于在字符常量中插入一个单引号 \\反斜杠,用于在字符串常量中插入一个反斜杠 \b退格符,用于删除前一个字符(在某些环境中可能不被支持或表现不同) 请注意,
\b在 Java 中的行为可能会因平台或环境而异,并不总是表示退格符。此外,Java 还支持 Unicode 转义字符,如
\uXXXX(其中XXXX是四个十六进制数字),用于插入 Unicode 字符集中的字符。例如,\u0061表示字符 ‘a’。 - 转义字符是一种特殊的字符序列,它以反斜杠(
-
字符常量:
- 字符常量使用单引号(
')括起来,如'a'、'中'。 - 可以使用Unicode编码的转义序列来表示字符,如
'\u0061'表示字符a。
- 字符常量使用单引号(
4、内存拓展
public class Demo03 {
public static void main(String[] args) {
String sa = new String("hello world");
String sb = new String("hello world");
System.out.println(sa==sb); //false
String sc = "hello world";
String sd = "hello world";
System.out.println(sc==sd); //true
//对像 从内存分析
}
}
输出结果
false
true
思考:看着相同,为什么两个结果一个false,一个true
在Java中,字符串(String)是一个特殊的类。让我们来分析一下为什么sa == sb返回false而sc == sd返回true。
sa == sb返回false
当使用new String("hello world"),实际上是做了两件事情:
* 首先,Java会在字符串常量池中查找是否已经有了一个"hello world"的字符串实例。由于此时还没有,所以JVM会在字符串常量池中创建一个新的"hello world"实例(但在这个例子中,由于new关键字的使用,这个创建并不会真正发生)。
* 然后,new String(...)会在堆内存中创建一个新的String对象,并将字符串常量池中的"hello world"作为这个新对象的内部字符数组(char[])的副本。
因此,sa和sb都是堆上不同的String对象,尽管它们的内容相同,但它们在内存中的位置(即引用)是不同的,所以sa == sb返回false。
sc == sd返回true
当直接使用字符串字面量(如"hello world")时,JVM首先会在字符串常量池中查找是否已经有了一个相同的字符串。如果找到了,它就会返回这个字符串的引用;如果没有找到,它会在字符串常量池中创建一个新的字符串。
由于sc和sd都引用了同一个字符串字面量"hello world",并且字符串常量池中的字符串实例是唯一的(对于相同内容的字符串),所以sc和sd实际上引用的是内存中的同一个对象。因此,sc == sd返回true。
注意:要比较字符串的内容是否相等,应该使用equals()方法而不是==操作符。例如:
System.out.println(sa.equals(sb)); // true
System.out.println(sc.equals(sd)); // true
这里,equals()方法会比较两个String对象的内容是否相同,而不是它们是否引用同一个对象。
知识点
- 字符串常量池:
- Java中有一个特殊的内存区域叫做字符串常量池(String Constant Pool),它用于存储字符串字面量。
- 当创建一个字符串字面量时(例如
String sc = "hello world";),JVM首先会在字符串常量池中查找是否已经存在一个相同内容的字符串。 - 如果找到,则直接引用该字符串;如果没有找到,则会在池中创建一个新的字符串。
- new关键字与String对象:
- 使用
new关键字创建一个String对象(例如String sa = new String("hello world");)会在堆内存中创建一个新的对象,并将字符串常量池中的字符串作为新对象的内部字符数组(char[])的副本。 - 因此,即使内容相同,通过
new创建的String对象也会在堆上有不同的内存地址。
- 使用
- ==操作符与equals方法:
==操作符用于比较两个引用是否指向内存中的同一个对象。equals()方法用于比较两个对象的内容是否相等。对于String类,它通常用于比较两个字符串的内容是否相同。- 因此,当比较两个字符串的内容时,应使用
equals()方法而不是==操作符。
- 内存管理:
- Java中的对象通常存储在堆内存中,而基本数据类型和引用(即对象的内存地址)则存储在栈内存中。
- 字符串常量池位于堆内存中的特殊区域,用于存储字符串字面量。
- 字符串的不可变性:
- Java中的
String类是不可变的,即一旦创建了一个字符串对象,就不能修改它的内容。 - 每次对字符串进行修改(例如拼接、替换等)时,都会创建一个新的
String对象。
- Java中的
5、布尔值拓展
public class Demo03 {
public static void main(String[] args) {
boolean flag = true;
if(flag==true){ } //新手
if(flag){ } //老手
//Less is More! 代码要精简易读
}
}
知识点
- 代码简洁性:
- 如代码所示,使用
if(flag)比使用if(flag==true)更简洁。这是因为if语句期望一个布尔表达式,而flag本身就是一个布尔值,所以无需与true进行比较。 - 在编写代码时,应追求“Less is More”(少即是多)的原则,尽量让代码简洁易读。
- 如代码所示,使用
- 最佳实践:
- 在使用
if语句时,如果条件是一个布尔变量,则直接使用该变量,而无需与true或false进行比较。这有助于提高代码的可读性和简洁性。 - 同样,当在
if语句中使用非布尔值(如整数、浮点数等)时,应确保该值在上下文中是合理的,并且不会导致意外的行为。
- 在使用
- 代码可读性:
- 代码的可读性对于程序员来说非常重要。简洁、清晰的代码更容易被其他程序员理解和维护。
- 因此,在编写代码时,应始终关注代码的可读性,并遵循最佳编程实践。
整体代码
public class Demo03 {
public static void main(String[] args) {
System.out.println("===================1、整数拓展===========================");
//整数拓展 进制问题
//二进制0b 十进制 八进制0 十六进制0x
int i = 0b10; //二进制0b
int i1 = 10;
int i2 = 010; //八进制0
int i3 = 0x10; //十六进制0x 0~9 A~F
int i4 = 0x1A;
System.out.println(i);
System.out.println(i1);
System.out.println(i2);
System.out.println(i3);
System.out.println(i4);
System.out.println("===================2、浮点数拓展===========================");
//浮点数拓展 银行业务怎么表示?钱
//使用BigDecimal 数学工具类
//float和double是有问题的
//float 浮点数能表现的字长是有限的 也是离散的 浮点数会舍入误差 结果是个大约数 接近但不等于
//结论:最好完全避免使用浮点数进行比较
//例1
float f = 0.1f; //0.1
double d = 1.0/10; //0.1
System.out.println(f==d); //false
System.out.println(f);
System.out.println(d);
//例2
float f1 = 829714821892748f; //任意一个数
float f2 = f1 + 1;
System.out.println(f1==f2); //true
System.out.println("===================3、字符拓展===========================");
//字符拓展
char c1 = 'a';
char c2 = '中';
System.out.println(c1);
System.out.println((int)c1); //强制转换
System.out.println(c2);
System.out.println((int)c2); //强制转换
//所有的字符本质还是数字
//编码 Unicode编码 占2字节 最多可以表示65536个字符 0~65535
//Unicode编码 有一个ASCII表(97=a 65=A) 区间范围是U0000 ~ UFFFF (16进制)
//最早的Excel表格只有2^16=65536这么长
char c3 = '\u0061'; //61是十进制97的16位进制的表示,Unicode是16进制的
System.out.println(c3); //a
//转义字符
// \t 制表符
// \n 换行符
System.out.println("Hello\tworld");
System.out.println("Hello\nworld");
System.out.println("===================4、内存拓展===========================");
String sa = new String("hello world");
String sb = new String("hello world");
System.out.println(sa==sb); //false
String sc = "hello world";
String sd = "hello world";
System.out.println(sc==sd); //true
//对像 从内存分析
System.out.println("===================5、布尔值拓展===========================");
boolean flag = true;
if(flag==true){ } //新手
if(flag){ } //老手
//Less is More! 代码要精简易读
}
}
3、类型转换
由于Java是强类型语言,所以要进行有些运算的时候,需要用到类型转换。

低到高是它的字节大小
为什么32字节的float的要排在64字节的long前面
小数的优先级一定大于整数
运算时,不同类型的数据先转换为同一类型的,然后进行计算
强制类型转换和自动类型转换
public class Demo05 {
public static void main(String[] args) {
System.out.println("=====强制转换、内存溢出=====");
int i = 128;
byte b = (byte)i; //内存溢出
System.out.println(i);
System.out.println(b);
//强制转换 (类型)变量名 高-->低、
System.out.println("=====自动转换=====");
int i2 = 128;
double b2 = i;
System.out.println(i2);
System.out.println(b2);
//自动转换 低-->高
System.out.println("=====精度问题=====");
System.out.println((int)67.43); //67
System.out.println((int)-547.96f); //-547
/*
* 注意点
* 1、不能对布尔值进行转换
* 2、不能把对象类型转换为不相干类型
* 3、在把高容量转换为低容量的时候,强制转换;反之则不用
* 4、转换的时候可能存在内存溢出,或者精度问题
* */
System.out.println("=====ll=====");
char c = 'a';
int d = c+1;
System.out.println(d); //98
System.out.println((char)d); //b
}
}
- 强制转换 (类型)变量名 高–>低、
- 自动转换 低–>高
注意点
- 不能对布尔值进行转换
- 不能把对象类型转换为不相干类型
- 在把高容量转换为低容量的时候,强制转换;反之则不用
- 转换的时候可能存在内存溢出,或者精度问题
拓展
public class Demo06 {
public static void main(String[] args) {
//操作比较大的数的时候,注意溢出问题
//JDK7新特性:数字之间可以用下划线来分割,_不会被输出。
int money = 10_0000_0000;
System.out.println(money);
int year = 20;
int total = money * year;
System.out.println("total="+total); //-1474836480,计算的时候溢出了
//可不可以用long来接收
long total2 = money * year;
System.out.println("total2="+total2); //-1474836480转换了但是没用
//分析:money和year是int,运算完之后再转换成long,转换之前已经存在问题了
//正解
long total3 = money*(long)year;
System.out.println("total3="+total3);
//long类型后面的L 大写的L和小写的l都可以,但是一般为L,因为l很容易被认成1.
}
}
知识点
- 整数溢出:
- 当整数的值超过了其数据类型的最大值或小于了最小值时,就会发生溢出。在Java中,
int类型的范围是-2,147,483,648到2,147,483,647。如果尝试将一个大于int最大值的值存储在int变量中,将会导致溢出。
- 当整数的值超过了其数据类型的最大值或小于了最小值时,就会发生溢出。在Java中,
- 隐式类型转换和溢出:
- 当进行算术运算时,如果操作数是不同数据类型的,Java会尝试将它们转换为同一类型以执行运算。这通常是通过隐式类型转换(也称为自动类型转换)完成的。但是,如果隐式类型转换的结果超出了目标类型的范围,就会导致溢出。
- 在示例代码中,
money和year都是int类型。它们的乘积超过了int类型的最大值,导致了溢出。尽管最后尝试将结果存储在long类型的变量中,但溢出已经发生,因此结果是不正确的。
- 显式类型转换:
- 为了避免溢出,可以在运算之前进行显式类型转换(也称为强制类型转换)。这可以确保运算以较大的数据类型进行,从而避免溢出。
- 在示例代码中,通过将
year转换为long类型,然后再与money相乘,可以确保运算在long类型中进行,从而避免了溢出。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









