







YOLO(You Only Look Once)系列模型是一类非常高效的目标检测模型。其主要特点是能够在单次前向传播中同时进行目标的定位和分类,实现实时的目标检测。YOLO 系列模型从最初的 YOLOv1 到目前的 YOLOv10,经过了多次迭代和改进,逐渐提高了检测的精度和速度。

YOLO简史
YOLOv1
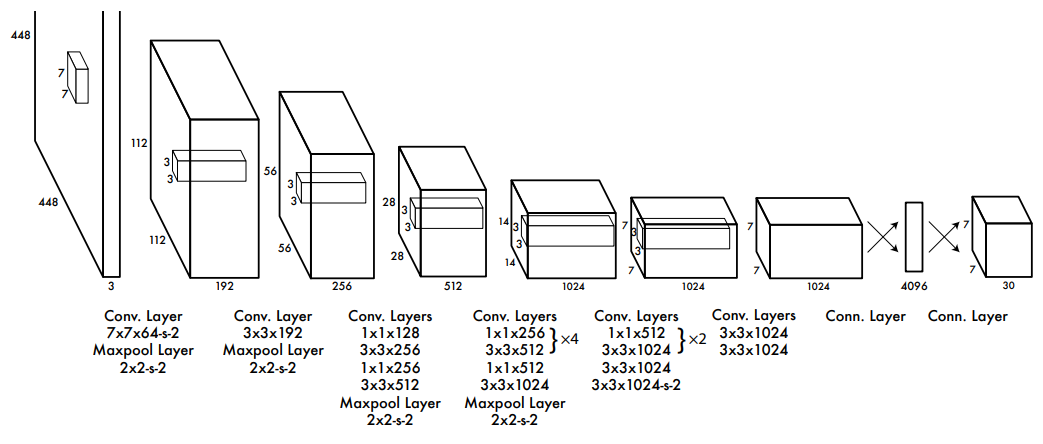
YOLOv1架构图
2015 年,Joseph Redmon 及其团队革命性地推出了 YOLOv1(You Only Look Once version 1),这一里程碑式的实时目标检测模型彻底颠覆了传统检测方法的框架。
YOLOv1 凭借其独特的设计理念——将目标检测任务转化为一个单一的回归问题,仅通过一次前向传播即可同时预测出图像中物体的边界框及其类别概率,极大地提升了检测速度与效率,为后续版本的迭代与优化奠定了坚实的基础。。

定性结果
-
参考论文:You Only Look Once: Unified, Real-Time Object Detection
-
论文链接:https://arxiv.org/abs/1506.02640
-
官方链接:https://pjreddie.com/darknet/yolo/
YOLOv2
次年,原班底提出 YOLO9000,作为 YOLO 系列的第二代力作,在 V1 的基础上做了很多改进,包括使用批量归一化、锚框、维度聚类、多尺度训练和测试等技术来提高模型的精度和鲁棒性。在标准的 VOC 2007 测试集上,YOLOv2 达到了 76.8% 的 mAP,比 YOLOv1 的 63.4% 有了明显提升。

-
参考论文:YOLO9000: Better, Faster, Stronger
-
论文链接:https://arxiv.org/abs/1612.08242
-
官方链接:http://pjreddie.com/yolo9000/
YOLOv3
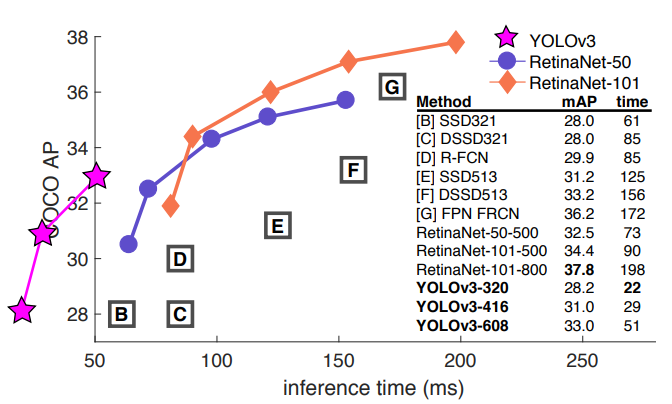
YOLOv3 是 YOLO 系列目标检测模型的第三个版本,由 Joseph Redmon和Ali Farhadi 于 2018 年提出。YOLOv3 在继承前两代 YOLO 模型优点的基础上,进行了多项改进,包括使用更高效的骨干网络、多锚和空间金字塔池,使其在检测精度和速度上达到了更高的平衡。
-
参考论文:YOLOv3: An Incremental Improvement
-
论文链接:https://arxiv.org/abs/1804.02767
-
官方链接:https://pjreddie.com/darknet/yolo/
YOLOv4
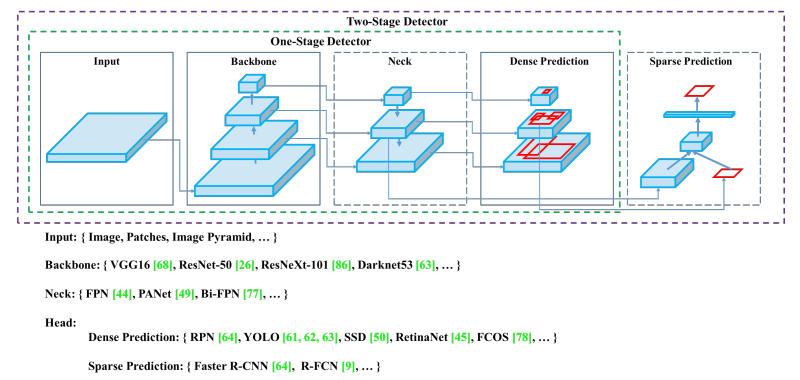
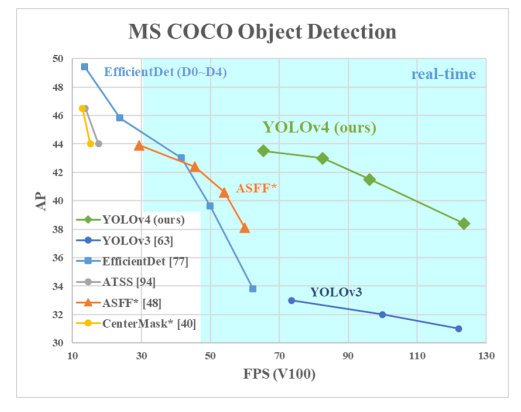
YOLOv4(开发团队:Institute of Information Science, Academia Sinica, Taiwan)于 2020 年发布,引入 Mosaic 数据增强、新的无锚检测头和新的损失函数等创新技术。
-
开发了一个速度更快、精度更高的检测模型,仅需单张1080Ti或2080Ti即可完成训练。
-
验证了目前 SOTA 的Bag-ofFreebies(不增加推理成本的trick)和Bag-of-Specials(增加推理成本的trick)的有效性。
-
修改了现有的最新方法,使其更高效且更适合单GPU训练,包括CBN、PAN、SAM等。
-
参考论文:YOLOv4: Optimal Speed and Accuracy of Object Detection
-
论文链接:https://arxiv.org/abs/2004.10934
-
开源链接:https://github.com/AlexeyAB/darknet
YOLOv5
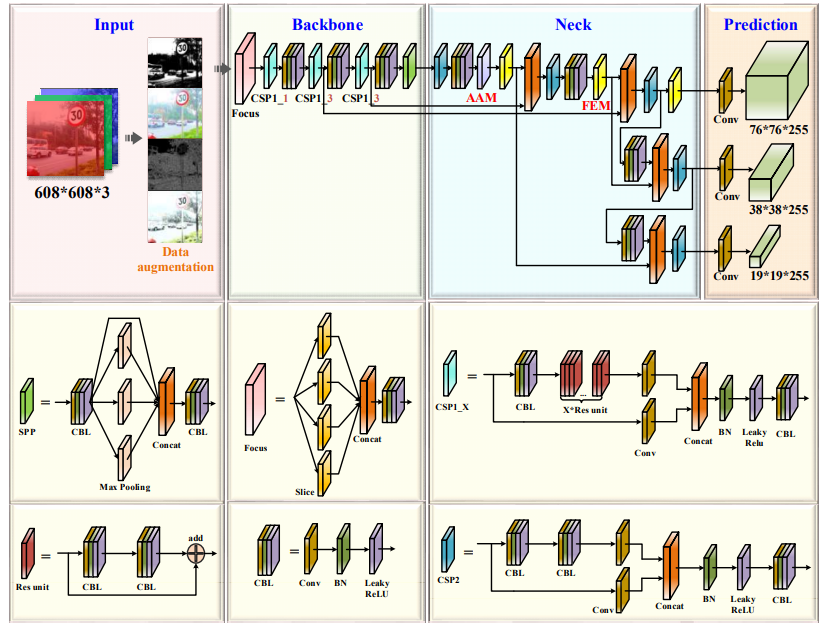
YOLOv5s网络架构
YOLOv5 是由 Ultralytics 推出的一个版本,虽然并非 YOLO 创始团队推出,但因其更易用、部署简单且性能卓越,迅速在业界赢得广泛赞誉与普及。YOLOv5 继续优化了检测速度和精度,并支持导出为多种格式(如TFLite、ONNX、CoreML和TensorRT)。
YOLOv5 相较于第四版,在网络结构、数据预处理、损失函数、激活函数、优化器和学习率调整、运行效率方面都有改进,提高了模型精度、速度,在实际应用中更有效。
其缺点是对于小目标、密集物体检测方面还有待提升。
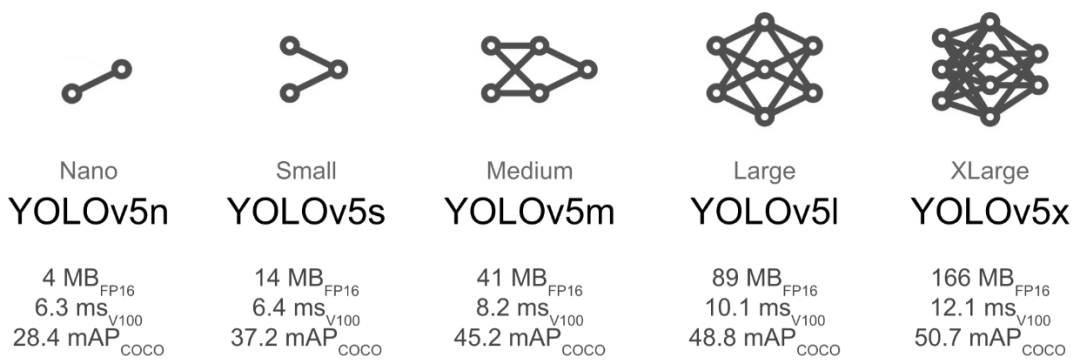
模型变体:YOLOv5 有几种尺寸(n、s、m、l、x),以适应不同的计算需求:
-
YOLOv5n(纳米版):适合在计算能力有限的设备上部署,如微控制器和低功耗的物联网设备。体积虽小,但保持了合理的准确度。
-
YOLOv5s(小型):适合许多边缘应用,包括移动设备和嵌入式系统。相较于纳米版,准确度提升的同时仍然保持较低的计算占用。
-
YOLOv5m(中型):适合于需要更高精度但仍然需要在边缘设备限制下运行的应用。
-
YOLOv5l(大型):专为需要高准确度的更复杂任务设计。
-
YOLOv5x(超大型):适用于需要最高精度且计算资源丰富的场景,如:高分辨率视频分析和复杂的目标检测任务。
图源网络
-
参考论文:Improved YOLOv5 network for real-time multi-scale traffic sign detection
-
论文链接:https://arxiv.org/abs/2112.08782
-
开源链接:https://github.com/ultralytics/yolov5
-
更多解析:https://zhuanlan.zhihu.com/p/674636784
YOLOv6
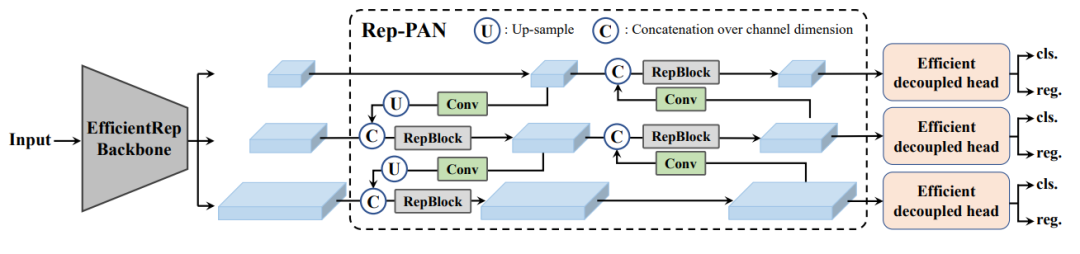
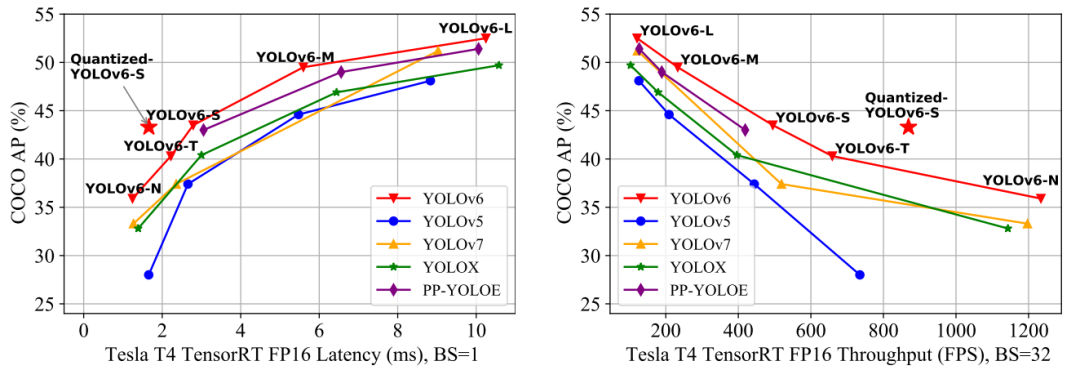
YOLOv6 是美团研发的一款目标检测框架,致力于工业应用。
主要贡献:
-
为不同的工业应用场景重新设计一系列不同尺寸的网络,兼顾精度与速度。其中,小模型为单分支,大模型为多分支。
-
引入自蒸馏策略,在分类任务和回归任务上均进行自蒸馏。动态调整教师模型和标签,便于学生模型的训练。
-
广泛验证标签分配、损失函数和数据增强技术,选择合适的策略进一步提升性能。
-
基于 RepOptimizer和通道级蒸馏技术,对量化方式做了改进。
-
参考论文:YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
-
论文链接:https://arxiv.org/abs/2209.02976
-
开源链接:https://github.com/meituan/YOLOv6
YOLOv7
YOLOv7 与 YOLOv4 出自同一个团队,该版本增加了额外的任务,如 COCO 关键点数据集的姿势估计。
另外,该版本在 5FPS 到 160FPS 的范围内,在速度和精度上都超过了所有(此版本以前)已知的目标检测器,在 GPU V100 上以 30 FPS 或更高的速度在所有已知的实时目标检测器中具有最高的精度 56.8%AP。
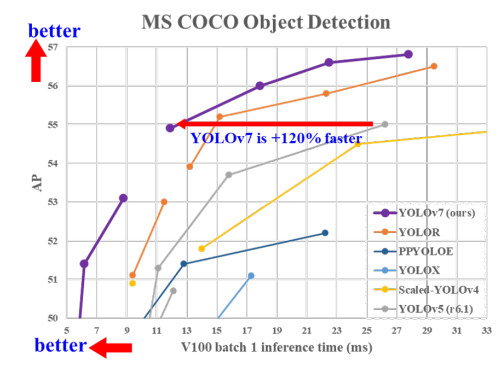
-
参考论文:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
-
论文链接:https://arxiv.org/abs/2207.02696
-
开源链接:https://github.com/WongKinYiu/yolov7
YOLOv8

YOLOv8 与 YOLOv5 出自同一个团队,该版本支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。这种多功能性使用户能够在各种应用和领域中利用 YOLOv8 的功能。

-
参考文档:https://docs.ultralytics.com/models/yolov8/
-
开源链接:https://github.com/ultralytics/ultralytics
YOLOv9
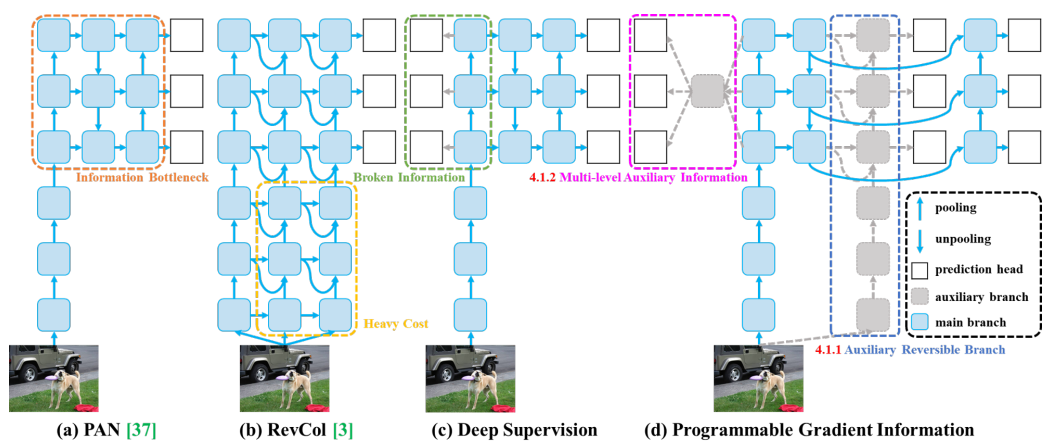
PGI
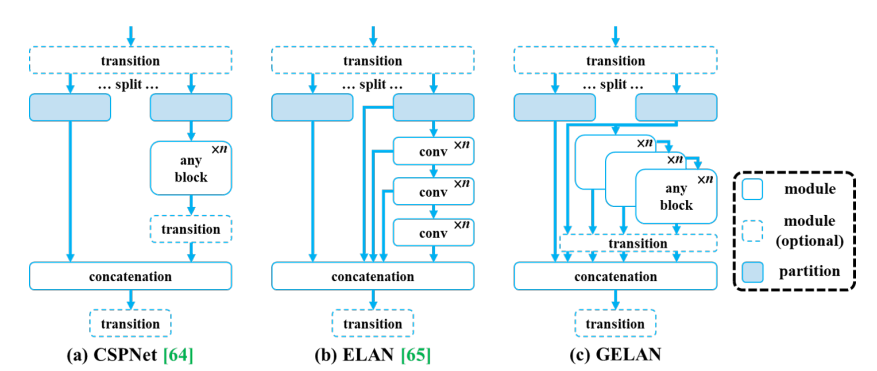
GELAN
YOLOv9 由中国台湾 Academia Sinica、台北科技大学等机构联合开发,基于 YOLOv7 进行改进,引入了可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 等创新方法。
与 YOLOv8 相比,两者的结合设计使深度模型的参数数量减少了 49%,计算量减少了 43%,但在 MS COCO 数据集上仍有 0.6% 的 AP 改进。
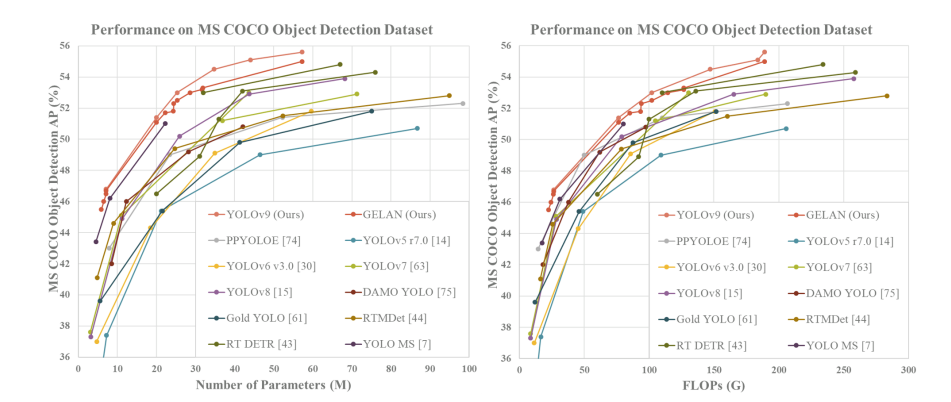
-
参考论文:YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
-
论文链接:https://arxiv.org/abs/2402.13616
-
开源链接:https://github.com/WongKinYiu/yolov9
YOLOv10
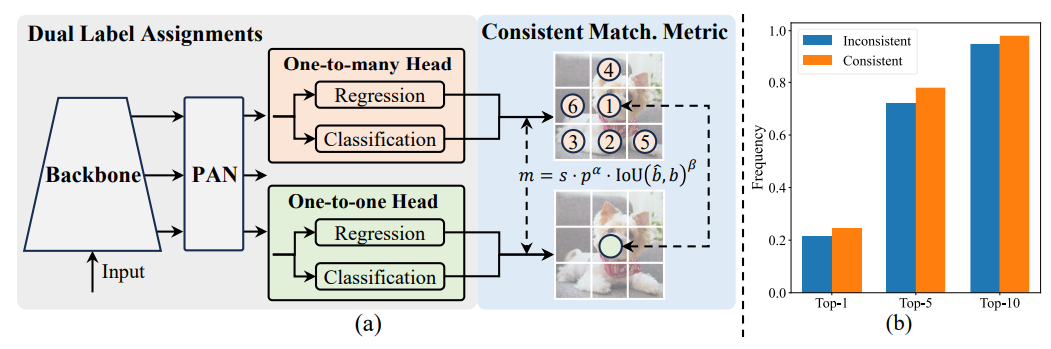
NMS-free
YOLOv10 是 YOLO 系列目前最新版,由清华大学开源,其中两大改进是:
-
后处理改进:提出NMSfree(非极大值抑制)训练的一致双分配,实现了高效的端到端检测。
-
引入了整体效率精度驱动的模型设计策略,改善了性能效率的权衡。
YOLOv10 在各种模型规模上都达到了最先进的性能和效率。例如,在 COCO 上类似的 AP 下,YOLOv10-S 比 RT-DETR-R18 快 1.8 倍,同时参数和 FLOP 数量减少 2.8 倍。与 YOLOv9-C 相比,在相同的性能下,YOLOv10-B 的延迟减少了 46%,参数减少了 25%。

-
参考论文:YOLOv10: Real-Time End-to-End Object Detection
-
论文链接:https://arxiv.org/abs/2405.14458
-
开源链接:https://github.com/THU-MIG/yolov10
YOLOv10 绝非技术的终点,继续期待新的突破与创新!
智汇全球,趋动未来
『社区项目』汇聚全球智慧,促进技术交流的宝贵平台,期待每一位AI爱好者体验一键部署功能的强大魅力。
目前,YOLO 系列已有部分版本上线『社区项目』,欢迎前来体验。
趋动云『社区项目』体验入口:
-
使用【yolov8】监控交通流:https://open.virtaicloud.com/web/project/detail/460827655878262784
-
yolov5:https://open.virtaicloud.com/web/project/detail/461488886511030272
-
YOLOv8-deepsort 实现智能车辆目标检测+车辆跟踪+车辆计数:https://open.virtaicloud.com/web/project/detail/478090481285230592
趋动云是面向企业、科研机构和个人 AI 开发者构建的开发和推理训练服务,也是全球首个基于 GPU 算力池化云的服务。
趋动云的使命是连接算力·连接人:
📍通过连接全球算力,趋动云可以为用户提供便宜、好用的 AI 算力。
📍通过为AI算法开发全流程提供优化服务、构建全球开发者项目和数据社区,趋动云可以帮助AI开发者接入丰富的生态,快速实现最佳实践。
















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









