






tesseract是一个开源的光学字符识别(OCR)引擎,它可以将图像中的文字转换为计算机可读的文本。支持多种语言和书面语言,并且可以在命令行中执行。它是一个流行的开源OCR工具,可以在许多不同的操作系统上运行。
Tess4J是一个基于Tesseract OCR引擎的Java接口,可以用来识别图像中的文本,说白了,就是封装了它的API,让Java可以直接调用。
目录
一、安装 tesseract (OCR)
Index of /tesseract 找到符合自己电脑的安装
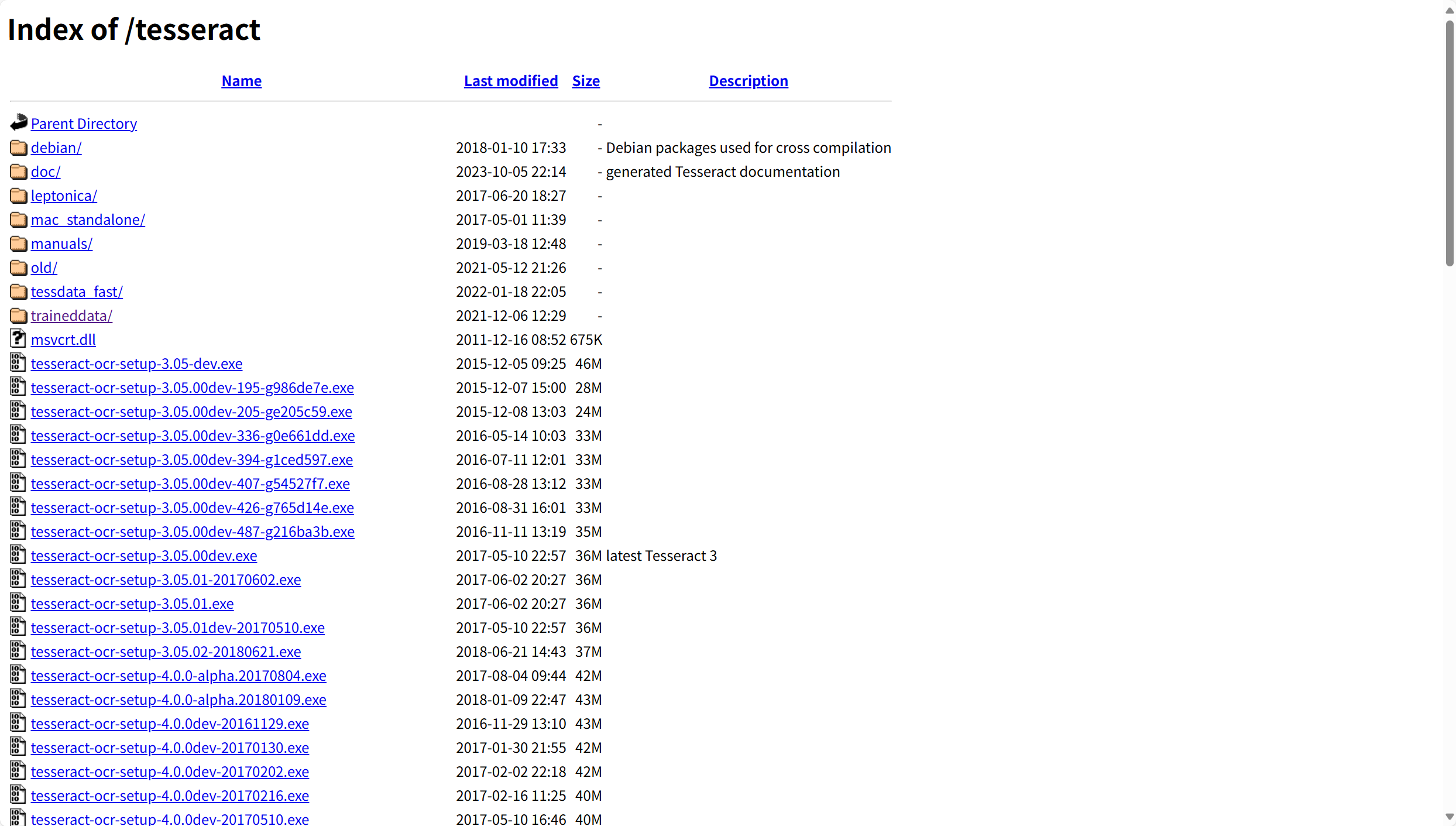
二、下载训练数据
三、创建spring boot 项目
1、导入依赖
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.3.0</version>
</dependency>2、编写配置类
package com.example.config;
import net.sourceforge.tess4j.Tesseract;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class TesseractOcrConfig {
@Value("${tess4j.datapath}")
private String dataPath;
@Bean
public Tesseract tesseract() {
Tesseract tesseract = new Tesseract();
// 设置训练数据文件夹路径
tesseract.setDatapath(dataPath);
// 设置为中文简体
tesseract.setLanguage("chi_sim");
return tesseract;
}
}
3、编写controller
package com.example.controller;
import com.example.service.OcrService;
import lombok.extern.slf4j.Slf4j;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
@RestController
@RequestMapping("/api")
@Slf4j
public class OcrController {
private final OcrService ocrService;
public OcrController(OcrService ocrService) {
this.ocrService = ocrService;
}
@PostMapping(value = "/recognize", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public String recognizeImage(MultipartFile file) throws TesseractException, IOException {
log.info(ocrService.recognizeText(file));
// 调用OcrService中的方法进行文字识别
return ocrService.recognizeText(file);
}
}
5、编写service
package com.example.service.impl;
import com.example.service.OcrService;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
@Service
public class OcrServiceImpl implements OcrService {
private final Tesseract tesseract;
public OcrServiceImpl(Tesseract tesseract) {
this.tesseract = tesseract;
}
/**
*
* @param imageFile 要识别的图片
* @return
*/
@Override
public String recognizeText(MultipartFile imageFile) throws IOException, TesseractException {
// 转换
InputStream sbs = new ByteArrayInputStream(imageFile.getBytes());
BufferedImage bufferedImage = ImageIO.read(sbs);
// 对图片进行文字识别
return tesseract.doOCR(bufferedImage);
}
}
接口
package com.example.service;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
public interface OcrService {
public String recognizeText(MultipartFile imageFile) throws IOException, TesseractException;
}
5、运行调试

可以看到识别率还是很棒的
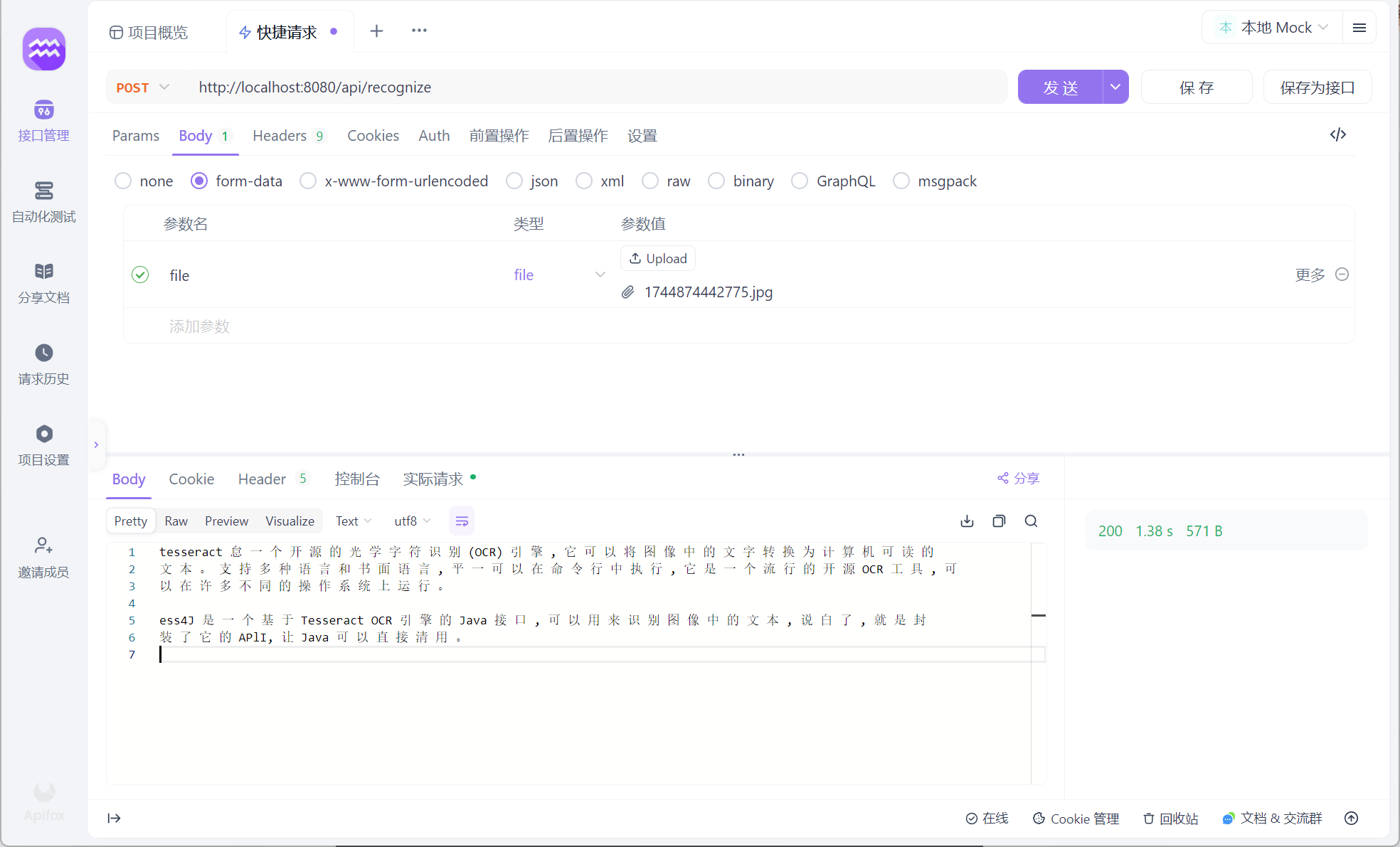
注:图片颜色比较多的时候有有点识别不清楚了以及一些带字体的文本 毕竟是免费的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









