







python正则表达式学习笔记
import re包
match方法:
re.match(pattern,string,flag=0)
| 参数 | 功能 |
|---|---|
| patter | 匹配的正则表达式 |
| flags | 需要匹配的字符串 |
| flags |
flag参数
| 修饰符 | 描述 |
|---|---|
| re.I | 不区分大小写 |
| re.L | 做本地化识别匹配 |
| re.M | 多行匹配影响^,$ |
| re.S | 使.匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符,影响\w \W \b \B |
| re.X | 该标志通过给予更灵活的格式将正则表达式写的更容易理解 |
如果匹配成功会返回一个匹配成功的对象,如果没有匹配上则返回None
例:
import re
s='hello python'
pattern1='hello'
pattern2='Hello'
S1=re.match(pattern1,s)
S2=re.match(pattern2,s)
S3=re.match(pattern2,s,flags=re.I)#不区分大小写匹配
print(S1)
print(S2)
print(S3)
print(dir(S1))#查看当对象的方法
print(S1.group())#返回匹配的字符串
print(S1.span())#匹配的范围
print(S1.start())#匹配的首位
常用匹配符
| 符号 | 描述 |
|---|---|
| . | 匹配任意字符,除了\n |
| [] | 匹配列表中字符 |
| \w | 匹配字母、数字、下划线 |
| \W | 匹配不是数字、字母、下划线 |
| \s | 匹配空白字符(\n,\t) |
| \S | 匹配非空白字符 |
| \d | 匹配数字 |
| \D | 匹配非数字 |
例:
import re
print('-----------.的使用-----------')
s1='a'
s2='A'
s3='1'
s4='_'
s5='\n'
pattern='.'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
S5=re.match(pattern,s5)
print('小写字母:',S1,'\n','大写字母',S2,'\n','数字:',S3,'\n','下划线:',S4,'\n','空白字符:',S5)
print('-----------\d的使用-----------')
pattern='\d'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
S5=re.match(pattern,s5)
print('小写字母:',S1,'\n','大写字母',S2,'\n','数字:',S3,'\n','下划线:',S4,'\n','空白字符:',S5)
print('-----------\D的使用-----------')
pattern='\D'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
S5=re.match(pattern,s5)
print('小写字母:',S1,'\n','大写字母',S2,'\n','数字:',S3,'\n','下划线:',S4,'\n','空白字符:',S5)
print('-----------\s的使用-----------')
pattern='\s'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
S5=re.match(pattern,s5)
print('小写字母:',S1,'\n','大写字母',S2,'\n','数字:',S3,'\n','下划线:',S4,'\n','空白字符:',S5)
print('-----------\S的使用-----------')
pattern='\S'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
S5=re.match(pattern,s5)
print('小写字母:',S1,'\n','大写字母',S2,'\n','数字:',S3,'\n','下划线:',S4,'\n','空白字符:',S5)
print('-----------\w的使用-----------')
pattern='\w'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
S5=re.match(pattern,s5)
print('小写字母:',S1,'\n','大写字母',S2,'\n','数字:',S3,'\n','下划线:',S4,'\n','空白字符:',S5)
print('-----------\W的使用-----------')
pattern='\W'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
S5=re.match(pattern,s5)
print('小写字母:',S1,'\n','大写字母',S2,'\n','数字:',S3,'\n','下划线:',S4,'\n','空白字符:',S5)
print('-----------\\[]的使用-----------')
pattern='[2468]'
s2='2'
s6='6'
s9='9'
S2=re.match(pattern,s2)
S6=re.match(pattern,s6)
S9=re.match(pattern,s9)
print('pattern=[2468]\n','2:',S1,'\n','6',S2,'\n','9:',S3)
返回结果:
-----------.的使用-----------
小写字母: <re.Match object; span=(0, 1), match='a'>
大写字母 <re.Match object; span=(0, 1), match='A'>
数字: <re.Match object; span=(0, 1), match='1'>
下划线: <re.Match object; span=(0, 1), match='_'>
空白字符: None
-----------\d的使用-----------
小写字母: None
大写字母 None
数字: <re.Match object; span=(0, 1), match='1'>
下划线: None
空白字符: None
-----------\D的使用-----------
小写字母: <re.Match object; span=(0, 1), match='a'>
大写字母 <re.Match object; span=(0, 1), match='A'>
数字: None
下划线: <re.Match object; span=(0, 1), match='_'>
空白字符: <re.Match object; span=(0, 1), match='\n'>
-----------\s的使用-----------
小写字母: None
大写字母 None
数字: None
下划线: None
空白字符: <re.Match object; span=(0, 1), match='\n'>
-----------\S的使用-----------
小写字母: <re.Match object; span=(0, 1), match='a'>
大写字母 <re.Match object; span=(0, 1), match='A'>
数字: <re.Match object; span=(0, 1), match='1'>
下划线: <re.Match object; span=(0, 1), match='_'>
空白字符: None
-----------\w的使用-----------
小写字母: <re.Match object; span=(0, 1), match='a'>
大写字母 <re.Match object; span=(0, 1), match='A'>
数字: <re.Match object; span=(0, 1), match='1'>
下划线: <re.Match object; span=(0, 1), match='_'>
空白字符: None
-----------\W的使用-----------
小写字母: None
大写字母 None
数字: None
下划线: None
空白字符: <re.Match object; span=(0, 1), match='\n'>
-----------\[]的使用-----------
pattern=[2468]
2: None
6 <re.Match object; span=(0, 1), match='2'>
9: None
***Repl Closed***
匹配多个字符:
| 符号 | 描述 | 符号 | 描述 |
|---|---|---|---|
| * | 匹配零次或多次 | {m} | 重复m次 |
| + | 匹配一次或多次 | {m,n} | 重复m~n任意次 |
| ? | 匹配一次或零次 | {m,} | 重复至少m次 |
例1:
匹配手机号码
import re
#匹配手机号码
#pattern_phone_number='\d\d\d\d\d\d\d\d\d\d'#笨办法
#pattern_phone_number='1[25789]\d\d\d\d\d\d\d\d'#聪明一兜兜
pattern_phone_number='1[25789]\d{9}'#机智``
phone_number='18756578254'#放心这不是我手机号☺
result=re.match(pattern_phone_number,phone_number)
print(result)
#输出
#<re.Match object; span=(0, 11), match='18756578254'>
#[Finished in 0.5s]
例2:
匹配首字符是大写字符后面都是小写字符,并且小写字符可有可无。
import re
text="Hello guy,my name is k_i_k_i what's your name?"
pattern='[A-Z][a-z]*'
o=re.match(pattern,text)
print(o)
#<re.Match object; span=(0, 5), match='Hello'>
#[Finished in 0.2s]
例3:
匹配符合要求的变量名(字母、数字、下划线,且数字不能开头)
import re
s1="1name"
s2="name1"
s3="_name1"
pattern='[A-Za-z_]\w*'#='[A-Za-z_][a-zA-Z_0-9]]*'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
print(S1,'\n',S2,'\n',S3,'\n')
#None
#<re.Match object; span=(0, 5), match='name1'>
#<re.Match object; span=(0, 6), match='_name1'>
#[Finished in 0.2s]
例3:
匹配1-99的数字
import re
s1="0"
s2="09"
s3="105"
s4="6"
pattern='[1-9]\d?'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
print(S1,'\n',S2,'\n',S3,'\n',S4,'\n')
例3:
匹配8-20位的随机密码
import re
s1="12347sdabf#"
s2="fnsd24_3284df"
s3="fdslkndskfkdsjnvfsangvsagffesf"
s4="afes"
pattern='\w{8,20}'
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
S3=re.match(pattern,s3)
S4=re.match(pattern,s4)
print(S1,'\n',S2,'\n',S3,'\n',S4,'\n')
原生字符的使用:
import re
s1="\\\\t123"
s2="\\\\\\\\t123"
pattern=r'\\\\\\\\t\d*'#转换成原生字符串
S1=re.match(pattern,s1)
S2=re.match(pattern,s2)
print(S1,'\n',S2)
边界字符
$表示结束
例:
匹配QQ邮箱5-10位
错误示范:
import re
qq1="12345678@qq.com"
qq2="12345678@qq.com13214"
pattern="[1-9]\d{4,9}@qq.com"
o1=re.match(pattern,qq1)
o2=re.match(pattern,qq2)
print(o1,'\n',o2)
#<re.Match object; span=(0, 15), match='12345678@qq.com'>
#<re.Match object; span=(0, 15), match='12345678@qq.com'>
#[Finished in 0.2s]
qq2明显不是但还是匹配成功,这时就需要划分好匹配的结尾
这时便需要使用**$**来划分正则表达式的结尾。
pattern="[1-9]\d{4,9}@qq.com$"#修改
#<re.Match object; span=(0, 15), match='12345678@qq.com'>
# None
#[Finished in 0.2s]
^表示开始
import re
word1="hello.py"
word2="python.py"
pattern=r"^hello.*"
o1=re.match(pattern,word1)
o2=re.match(pattern,word2)
print(o1,'\n',o2)
#<re.Match object; span=(0, 8), match='hello.py'>
# None
#[Finished in 0.2s]
\b表示单词边界
import re
word1="123 python1"
word2="123 python"
pattern=r".*python\b"#匹配\B位置不是单词的边界
o1=re.match(pattern,word1)
o2=re.match(pattern,word2)
print(o1)
print(o2)
#None
#<re.Match object; span=(0, 10), match='123 python'>
#[Finished in 0.2s]
\B表示非单词边界
import re
word1="123 python1"
word2="123 python"
pattern=r".*python\B"#匹配\B位置不是单词的边界
o1=re.match(pattern,word1)
o2=re.match(pattern,word2)
print(o1)
print(o2)
#<re.Match object; span=(0, 10), match='123 python'>
#None
#[Finished in 0.2s]
search方法:
re.search(pattern,string,flag=0)
| 参数 | 功能 |
|---|---|
| patter | 匹配的正则表达式 |
| flags | 需要匹配的字符串 |
| flags |
search与match的区别
match会从字符串开头开始比较,如果没有则返回失败None
search会搜索整个字符串,直到搜到或搜完为止
import re
centence="My name is kiki."
partten="kiki"
match_centence=re.match(partten,centence)
search_centence=re.search(partten,centence)
print("match:",match_centence)
print("search:",search_centence)
#match: None
#search: <re.Match object; span=(11, 15), match='kiki'>
#[Finished in 0.2s]
匹配多个字符串:
使用 **|**相当于或
import re
centence1="My name is kiki."
centence2="Her name is yoki."
centence3="Her name is niki."
partten="kiki|yoki|niki|biki"
search_centence1=re.search(partten,centence1)
search_centence2=re.search(partten,centence2)
search_centence3=re.search(partten,centence3)
print("search1:",search_centence1)
print("search2:",search_centence2)
print("search3:",search_centence3)
'''
search1: <re.Match object; span=(11, 15), match='kiki'>
search2: <re.Match object; span=(12, 16), match='yoki'>
search3: <re.Match object; span=(12, 16), match='niki'>
[Finished in 0.2s]'''
例:
匹配0-100之间的所有数字
import re
num1='100'
num2='0'
num3='10000'
num4='06'
pattern=r'[1-9]?\d$|100$'
match_num1=re.match(pattern,num1)
match_num2=re.match(pattern,num2)
match_num3=re.match(pattern,num3)
match_num4=re.match(pattern,num4)
print(match_num1)
print(match_num2)
print(match_num3)
print(match_num4)
#<re.Match object; span=(0, 3), match='100'>
#<re.Match object; span=(0, 1), match='0'>
#None
#None
#[Finished in 0.3s]
|与[]的差异
import re
kiki='kiki'
yoki='yoki'
yiki='yiki'
pattern1=r'[ky][io]ki'
pattern2=r'kiki|yoki'
o1=re.match(pattern1,kiki)
o2=re.match(pattern1,yoki)
o3=re.match(pattern1,yiki)
o4=re.match(pattern2,kiki)
o5=re.match(pattern2,yoki)
o6=re.match(pattern2,yiki)#匹配不了yiki
print(o1)
print(o2)
print(o3)
print(o4)
print(o5)
print(o6)
'''
<re.Match object; span=(0, 4), match='kiki'>
<re.Match object; span=(0, 4), match='yoki'>
<re.Match object; span=(0, 4), match='yiki'>
<re.Match object; span=(0, 4), match='kiki'>
<re.Match object; span=(0, 4), match='yoki'>
None
[Finished in 0.3s]
'''
分组
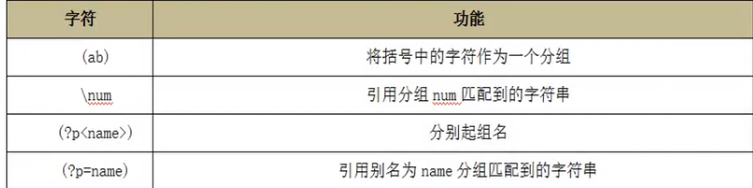
例:
匹配座机号码(010-233333,0432-5205201 (3-4)-(5-8))
import re
phone_num1='011-233520'
phone_num2='011233520'
pattern=r'(\d{2,3})-(\d{5,8})'
o1=re.match(pattern,phone_num1)
o2=re.match(pattern,phone_num2)
print(o1.groups())
print(o1.group(1))
print(o1.group(2))
print(o1.groups()[0])
print(o1.groups()[1])
print(o2)
'''
('011', '233520')
011
233520
011
233520
None
[Finished in 0.2s]'''
例:
匹配网页数据(分组)
import re
ht='<html><head>网页标题</head></html>'
ht_flase='<html><head>网页标题</head></body>'
pattern=r'<(.+)><(.+)>.+</\2></\1>'
o1=re.match(pattern,ht)
o2=re.match(pattern,ht_flase)
print(o1)
print(o2)
'''<re.Match object; span=(0, 30), match='<html><head>网页标题</head></html>'>
None
[Finished in 0.2s]'''
取别名
import re
ht='<html><head>网页标题</head></html>'
ht_flase='<html><head>网页标题</head></body>'
pattern=r'<(?P<kiki_html>.+)><(?P<kiki_head>.+)>.+</(?P=kiki_head)></(?P=kiki_html)>'
o1=re.match(pattern,ht)
o2=re.match(pattern,ht_flase)
print(o1)
print(o2)
'''<re.Match object; span=(0, 30), match='<html><head>网页标题</head></html>'>
None
[Finished in 0.2s]'''
sub和subn搜索与替换
re.sub(pattern,repl,string,count=0,flags=0)
re.subn(pattern,repl,string,count=0,flags=0)
例
将外国电话转换成中国的“111-111-111-111#这是外国的字符串”->“111111111111”
import re
print("----------sub---------")
phone="111-111-111-111#这是外国的字符串"
#①将#----替换
pattern="#.*$"
phone=re.sub(pattern,"",phone)
print(phone)
pattern=r"\D"
phone=re.sub(pattern,"",phone)
print(phone)
print("----------subn---------")
phone="111-111-111-111#这是外国的字符串"
#subn返回了一个元组第一项是替换后的数值,第二项是替换的次
#①将#----替换
pattern="#.*$"
phone=re.subn(pattern,"",phone)
print(phone)
pattern=r"\D"
phone=re.subn(pattern,"",phone[0])
print(phone)数
'''----------sub---------
111-111-111-111
111111111111
----------subn---------
('111-111-111-111', 1)
('111111111111', 3)
[Finished in 0.2s]'''
comple:
import re
s='my name is kiki233'
pattern=r'\D+'
regex=re.compile(pattern)
o=regex.match(s)
print(o)
'''<re.Match object; span=(0, 15), match='my name is kiki'>
[Finished in 0.2s]'''
findall:
返回列表
import re
s='my name is kiki233'
pattern=r'\w+'
o=re.findall(pattern,s)
print(o)
'''['my', 'name', 'is', 'kiki233']
[Finished in 0.3s]'''
finditer:
返回迭代器
import re
s='my name is kiki233'
pattern=r'\w+'
o=re.finditer(pattern,s)
print(o)
for i in o:
print(i.group())
'''<callable_iterator object at 0x0000026CBCD16550>
my
name
is
kiki233
[Finished in 0.3s]'''
split:
re.split(patter,string,maxsplit,flags)

import re
s='id1id2id3id4'
pattern=r'[a-z]+'
o=re.split(pattern,s)
print(o)
"""['', '1', '2', '3', '4']
[Finished in 0.3s]"""
贪婪模式和非贪婪模式
贪婪模式,尽可能匹配多的字符
非贪婪模式,尽可能少
默认贪婪
import re
o1=re.match(r'(.+)(\d+-\d+-\d+)','This is kiki\'s phone number: 111-222-333-444')
o2=re.match(r'(.+?)(\d+-\d+-\d+)','This is kiki\'s phone number: 111-222-333-444')
print("贪婪:",o1.groups())
print("非贪婪:",o2.groups())
'''贪婪: ("This is kiki's phone number: 111-22", '2-333-444')
非贪婪: ("This is kiki's phone number: ", '111-222-333')
[Finished in 0.3s]'''
一下午学完了这个,相信明天就忘了☹☹☹















 8756
8756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









