







一、笔记前言
本笔记主要解决RDD编程相关的基本问题。发布此篇博客,一方面整理、巩固所学内容,另一方面是为了分享知识,向大家学习。由于本人水平有限,错误之处在所难免,烦请读者多多指教。
二、RDD简要概念
下面这一部分展示了RDD相关的几个概念,都是RDD编程的基础。很不全面,但仍希望对读者有益。
首先,我们要了解RDD的基本概念。结合维基百科,我们可以了解到:Apache Spark has its architectural foundation in the resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way.(参考链接:https://en.wikipedia.org/wiki/Apache_Spark)通过维基百科的说明,我们得知RDD本质上是数据集,而且是有弹性的、分布式的数据集。
其次,我们要了解RDD的相关运算。在Apache Spark中,工作流程实际上是一个有向无环图。图中,节点代表RDD,边代表RDD的运算,RDD的运算具有惰性。RDDs are immutable and their operations are lazy; fault-tolerance is achieved by keeping track of the "lineage" of each RDD (the sequence of operations that produced it) so that it can be reconstructed in the case of data loss. 取并集、洗牌、映射等都是RDD的运算,更多的RDD运算将在后续的笔记中进行介绍。
然后,我们还需要理解RDD的依赖关系。这里的依赖关系主要分成两类,一类是窄依赖,一类是宽依赖。窄依赖可以大致理解为父RDD的每一个分区至多被一个子RDD的分区使用。When each partition at the parent RDD is used by at most one partition of the child RDD, then we have a narrow dependency. 而宽依赖与窄依赖不同,父RDD的分区可以被多个子RDD的分区依赖。When each partition of the parent RDD may be depended on by multiple child partitions (wide dependency), then the computation speed might be significantly affected as we might need to shuffle data around different nodes when creating new partitions.(参考链接:https://medium.com/@dvcanton/wide-and-narrow-dependencies-in-apache-spark-21acf2faf031)
三、搭建编程环境
RDD编程可以涉及多种语言,最推荐的语言或许是Scala,因为Spark本身就是用Scala编写的。Python与Spark结合也十分紧密,借助PySpark也可以进行RDD编程。网络上许多教程是借助Scala或者Python实现RDD编程的,然而使用Java进行RDD编程的教程目前或许较少。下面结合实例,主要讲解利用Java进行RDD编程,并与一些传统方法进行比较。
环境配置这一部分是有一定挑战性的,将细节全部展示篇幅过长,这里仅介绍最核心的部分。
【版本说明】
编程软件 本教程使用IntelliJ IDEA 2022.3.3 (Ultimate Edition) 是当下的最新版,搭配JetBrains Client 2022.3.3进行远程开发。
操作系统 服务器使用的系统为Ubuntu 22.04.2 LTS,内核为5.15.0-67-generic;本地设备的操作系统为macOS 13.2.1,内核为Darwin Kernel Version 22.3.0。
Spark以及Hadoop Hadoop版本为3.3.4,Spark版本为3.3.2,Scala版本为2.12.15。我将Hadoop安装在/usr/local/hadoop目录下,将Spark安装在/usr/local/spark目录下。
【启动程序】
启动Hadoop 我们先将Hadoop启动。那如何验证是否已经启动成功呢?可以借助下面两个方法:首先,可以在终端中输入下面命并回车,检查NameNode、DataNode是否显示出来。注意:即使显示有DataNode,也不能保证DataNode完全正常运行,可以查看日志进行判断。下面是我的服务器的情况,由于运行了hbase等其他服务,所以显示出的进程要多一些。
jps
其次,可以通过可视化的网页来验证。在浏览器中输入URL:
http://<您服务器的IP地址>:<您配置时指定的端口号,一般是50070>/dfshealth.html#tab-overview
启动Intellij IDEA 在Hadoop启动之后,我们启动Intellij IDEA,进行远程开发,如图:

注意:尽可能选择网络好的环境,否则编程时延迟较高,甚至导致频繁与服务器重连,体验一般。
进入JetBrains Client后,我们建立新的Java项目,最好基于Maven构建,如图:

注意:这里最好选择JDK 1.8,经过尝试,如果使用JDK 11以及17,则在运行时可能会出现Illegal Access等问题。
【配置环境】
配置SDK等 下面的教程使用的Language Level是Java 8,而不是目前最新的LTS版本Java 17。配置SDK以及Language Level,如图所示。
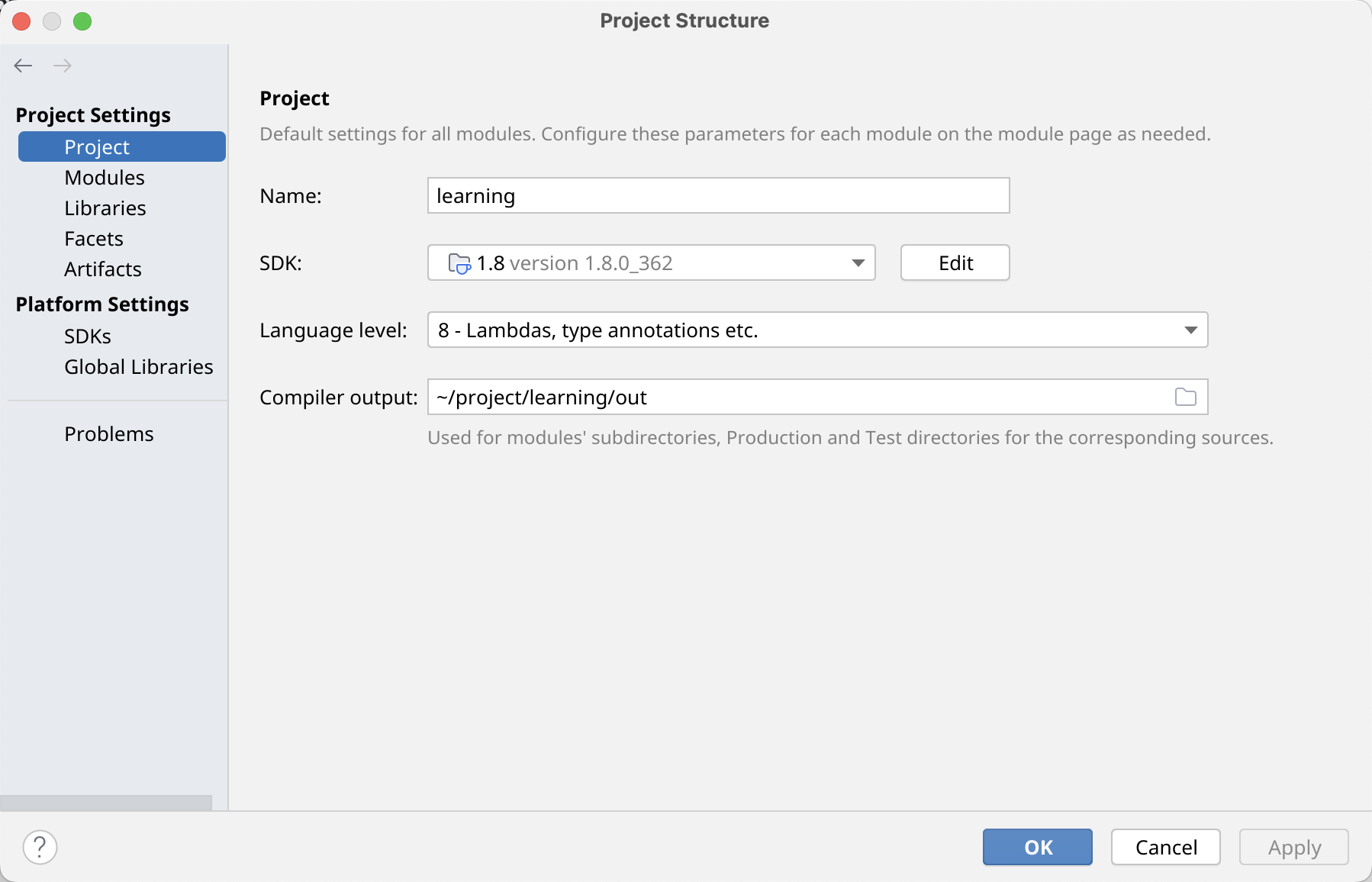
这样创建的工程,在某些情况下,甚至不能运行简单的“Hello World”程序,这非常非常令人沮丧。如果我们版本相同,那么你的报错很可能与我一样:
java: Cannot run program "/usr/lib/jvm/java-1.8.0-openjdk-amd64/bin/java"
(in directory "/home/hadoop/.cache/JetBrains/RemoteDev-IU/_home_hadoop_project_learning/compile-server"):
error=0, Failed to exec spawn helper: pid: 1636425, exit value: 1对于这个报错,可以浏览JetBrains官方网站上的帖子来获取更多信息(链接:https://youtrack.jetbrains.com/issue/IDEA-304440)。
注意:下面是我的解决方法,非常离谱,不保证对您有效。我将SDK设置为JDK 17,然后发现可以正常运行程序,我再将SDK改成JDK 1.8,报错也消失了。
添加依赖库 现在Hadoop以及编程软件已经启动,不过遗憾的是,我们现在还不能直接编写并运行Spark程序,因为还没有添加Spark相关的许多类等等。我们首先要添加Spark相关的库,如图:

现在直接运行,下面的报错会向你重拳出击。这表明,我们还需要添加Hadoop相关的库才可以,这一步如法炮制就可以啦 ~ 下面的图片仅展示了部分类的添加,限于篇幅,未能完全展示。
java.lang.NoClassDefFoundError: org/apache/hadoop/fs/FSDataInputStream

遗憾的是,现在还不能正常运行Spark程序……再来看一下报错叭:
java.lang.NoClassDefFoundError: org/slf4j/LoggerFactory这看来是日志的问题,经过几个小时的疯狂Google、Stackoverflow、CSDN(真的是很长很长的时间呐),我大致理解了问题所在。
注意:解决方法为在pom.xml中加入相关依赖。鉴于很多读者可能不清楚pom.xml的结构,这里我直接贴出来全部内容,仅供参考。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>LearnRDD</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.26</version>
</dependency>
</dependencies>
</project>四、RDD的创建
这一部分主要介绍RDD的创建以及SparkContext的基本概念。说到RDD编程,不得不提及SparkContext。
【SparkContext】
它是什么呢?Spark官方的解释对我们来说,是极好的参考:A SparkContext represents the connection to a Spark cluster, and can be used to create RDD and broadcast variables on that cluster.(链接:https://spark.apache.org/docs/3.3.2/api/python/reference/api/pyspark.SparkContext.html)
如何创建呢?When you create a new SparkContext, at least the master and app name should be set, either through the named parameters here or through conf.(链接同上)
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
public class Main {
public static void main(String[] args) {
SparkConf config = new SparkConf()
.setAppName("Simple App") // 设置 App 名称
.setMaster("local[2]"); // 设置 Master
try (JavaSparkContext sparkContext = new JavaSparkContext(config)) {
// 进行一些操作
}
}
}注意:我们需要注意,在Java环境中,我们可以写JavaSparkContext,以及注意try-with-resources statement的使用。另外,在某些环境中定义了sc,即为SparkContext,可以直接使用。但是用Java进行RDD编程时却没有,需要我们自行定义。
【RDD的创建】
RDD有多种创建方法,利用parallelize从List中创建;从文本文件中创建;通过另一个RDD创建;在Python中通过DataFrame创建等等。下面先来介绍前两种方法。
利用parallelize从List中创建 Java代码示例如下:
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.List;
public class TestRDD2 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf()
.setAppName("Create RDD")
.setMaster("local[*]");
try (JavaSparkContext sparkContext = new JavaSparkContext(sparkConf)) {
List<Integer> list = Arrays.asList(1, 3, 5, 7, 9); // 创建 List
JavaRDD<Integer> rdd = sparkContext.parallelize(list); // 通过 List 创建 JavaRDD
rdd.collect().forEach(System.out::println); // 输出 1 3 5 7 9 (每个数字之间有换行)
}
}
}从文本文件中创建 Java代码示例如下:
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class TestRDD2 {
public static final String TEXT_FILE_PATH = "/home/hadoop/project/week6/test1/src/main/resources/textfile.txt";
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf()
.setAppName("Create RDD")
.setMaster("local[*]");
try (JavaSparkContext sparkContext = new JavaSparkContext(sparkConf)) {
JavaRDD<String> RDD = sparkContext.textFile(TEXT_FILE_PATH); // 创建 JavaRDD
RDD.collect().forEach(System.out::println);
JavaPairRDD<String, String> pairRDD = sparkContext.wholeTextFiles(TEXT_FILE_PATH); // 创建 JavaPairRDD
pairRDD.collectAsMap().forEach((filename, content)
-> System.out.println("filename: " + filename + "\n; content = " + content));
}
}
}文本文件内容如下:
I love Java
I love Python
He likes C++
She loves Scala
He likes C注意:通过textFile() 方法创建的是JavaRDD<String>;通过wholeTextFiles() 方法创建的是JavaPairRDD<String, String>。前者是将每一行作为一条记录,形成一个RDD;后者类似于创建一个键值对,键是文件名,值是文件内容。更详细内容,请参见:https://sparkbyexamples.com/spark/different-ways-to-create-spark-rdd/ 等网页。
五、写在最后
以上就是本文的全部内容了,主要介绍了RDD以及RDD编程的基本概念,环境的搭建等等。后续将介绍RDD的更多操作以及编程技巧等。欢迎一键三连嗷 ~














 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









