







Standalone模式概述:
Standalone模式是Spark自带的一种集群模式(本地集群,不依赖与外部集群,比如Yarn),可以真实地在多个机器之间搭建Spark集群的环境。
Standalone是完整的Spark运行环境,其中: Master角色以Master进程存在, Worker角色以Worker进程存在 Driver和Executor运行于Worker进程内, 由Worker提供资源供给它们运行。
一、下载、解压、配置环境变量
1、下载spark-3.1.3安装包
华为云镜像站下载:Index of apache-local/spark/spark-3.1.3

2、上传到linux环境中并解压
tar -zxvf spark-3.1.3-bin-hadoop3.2.tgz -C ../
3、修改用户权限(可选)
chown -R root:root spark-3.1.3-bin-hadoop3.2.tgz
4、修改名称(可选,主要为了简洁好看)
mv spark-3.1.3-bin-hadoop3.2.tgz ./spark-3.1.3
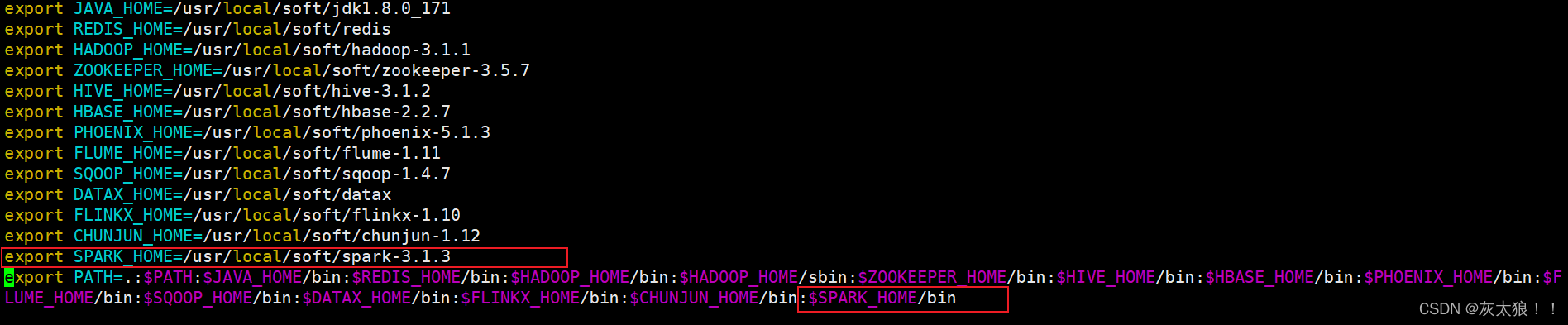
5、配置环境变量
vim /etc/profile
二、修改配置文件
1、进入conf目录
cd conf/
2、复制spark-env.sh.template文件并改名,防止修改错误。
cp spark-env.sh.template spark-env.sh
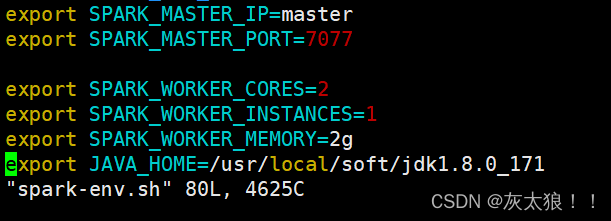
3、 编辑spark-env.sh文件增加以下配置(vim spark-env.sh)
export SPARK_MASTER_IP=master #spark集群主节点
export SPARK_MASTER_PORT=7077 #spark集群主节点对应的端口号
export SPARK_WORKER_CORES=2 #核数,2个核可以同时执行2个task任务
export SPARK_WORKER_INSTANCES=1 #每个节点的worker进程
export SPARK_WORKER_MEMORY=2g #分配的内存
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171 #jdk路径
4、复制workers.template文件并改名
cp workers.template workers
5、 编辑workers文件修改配置(vim workers)
6、复制到其它节点
scp -r spark-3.1.3 node1:`pwd`
scp -r spark-3.1.3 node2:`pwd`
三、启动
1、进入sbin目录下,启动集群,在master中执行
./sbin/start-all.sh (不加./启动的是hadoop中的集群)
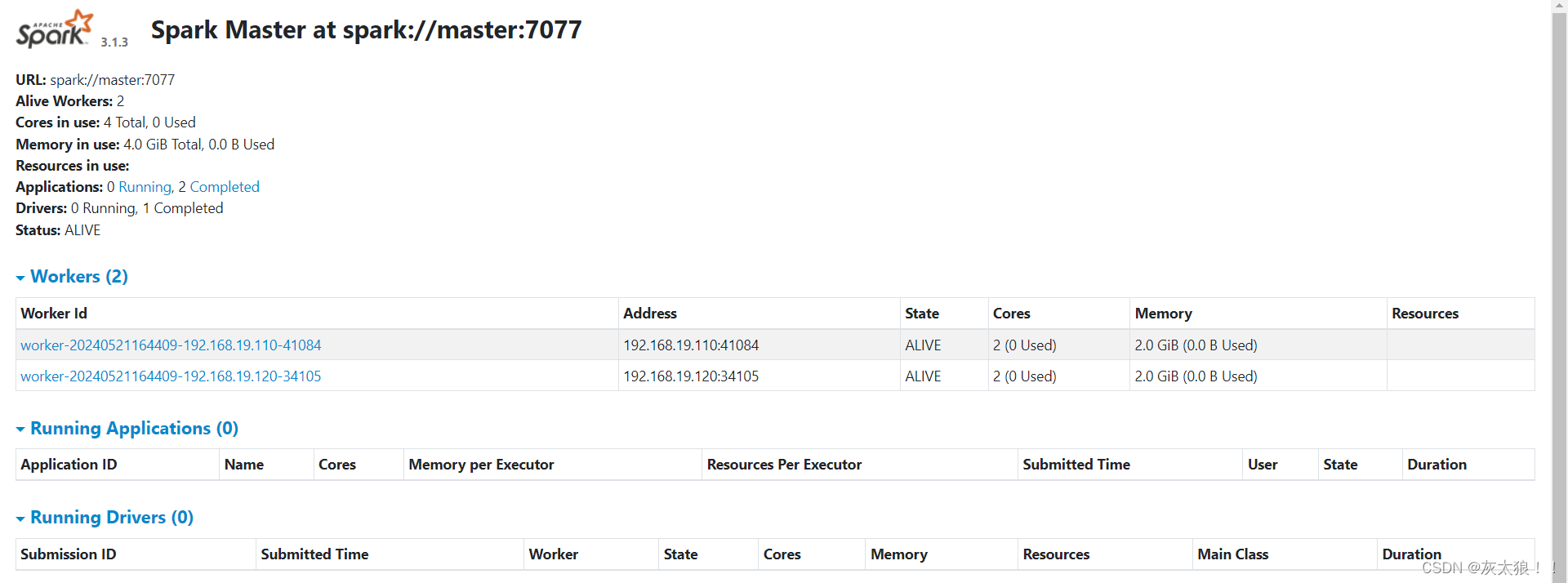
2、访问spark ui
http://master:8080/
四、standalone的两种运行模式
1、standalone client模式 (本地)
日志在本地输出,一般用于上线前测试(bin/下执行)
测试:进入以下目录下执行

spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-examples_2.12-3.1.3.jar 100
2、standalone cluster模式 (集群)
上线使用,不会再本地打印日志
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 1 --deploy-mode cluster spark-examples_2.12-3.1.3.jar 100
五、java编写spark程序在Linux上运行
使用上述四中的两种模式
第一种:standalone client模式
1、编写java程序
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo17SparkStandaloneSubmit {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
/**
* 如果在linux集群中运行,这里就不需要设置setMaster
*/
// conf.setMaster("local")
val sparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sparkContext.parallelize(List("java,hello,world", "hello,scala,spark", "java,hello,spark"))
val wordRDD: RDD[String] = linesRDD.flatMap(_.split(","))
val wordKVRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
val countRDD: RDD[(String, Int)] = wordKVRDD.reduceByKey(_ + _)
countRDD.foreach(println)
/**
* 将项目打包放到spark集群中使用standalone模式运行
* standalone client
* spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-1.0.jar 100
*
* standalone cluster
* spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 --deploy-mode cluster spark-1.0.jar 100
*
*/
}
}2、将java程序打成的jar包上传到linux上
3、执行以下命令
spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-1.0.jar 100
第二种:standalone cluster模式
1、编写java程序
2、将java程序打成的jar包上传到linux上
3、因为是在集群中运行,所以要把jar包复制给node1、node2各一份,因为不清楚具体在哪个节点上运行
4、执行以下命令
spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 --deploy-mode cluster spark-1.0.jar 100















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









