







多因子与复合分析
假设检验
用于验证某个假设是否成立,核心就是假设和检验两个部分,可以理解成一种反证法
- 建立原假设H0,H0的反命题为H1,也叫做备择假设
- 选择检验统计量
- 根据显著水平(一般为0.05),确定拒绝域
- 计算p值或样本统计值,作出判断
根据选取检验统计量的不同,又分为卡方统计、方差统计等等
相关系数
是衡量两组数据或两组样本一致性程度的因子
- 正相关
- 负相关
- 趋近于0,不相关
线性回归
回归是确定两种或两种以上变量间相互依赖的定量关系的一种统计方法。依赖关系为线性的就是线性回归
主成分分析
PCA,分析出所有维度里主要的成分,及区分度较大的维度,是一种降维的手法
奇异值分解
用于降维算法中的特征分解
复合分析
交叉分析
是在纵向分析法和横向分析法的基础上,从交叉、立体的角度出发,由浅入深、由低级到高级的一种分析方法。常用来分析两个变量之间的关系
例子
- 以一个或几个属性为行,另一个或几个属性为列,做成透视表
- 用假设检验去检验列与列的差异
import pandas as pd
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context(font_scale=2)
df = pd.read_csv("newHR.csv")
dp_indices = df.groupby(by="department").indices
# sales_values = df["left"].iloc[dp_indices["sales"]].values
# technical_values = df["left"].iloc[dp_indices["technical"]].values
# t检测 假设检验法 检验各个部门之间离职率的差异 并画出热力图
# dp_keys = list(dp_indices.keys())
# dp_t_mat = np.zeros([len(dp_keys), len(dp_keys)])
# for i in range(len(dp_keys)):
# for j in range(len(dp_keys)):
# p_value = ss.ttest_ind(df["left"].iloc[dp_indices[dp_keys[i]]].values, df["left"].iloc[dp_indices[dp_keys[j]]].values)[1]
# if p_value <= 0.05: # 认为是有显著差异的
# dp_t_mat[i][j] = -1
# else: # 认为没有显著差异
# dp_t_mat[i][j] = p_value
#
# ax = sns.heatmap(dp_t_mat, xticklabels=dp_keys, yticklabels=dp_keys)
# ax.set_xticklabels(ax.get_xticklabels(), rotation=0)
# ax.figure.set_size_inches(16,6) # 设置图表宽度
# plt.show()
# 透视表
piv_tb = pd.pivot_table(df, values="left", index=["promotion_last_5years", "salary"], columns=["Work_accident"], aggfunc=np.mean)
sns.heatmap(piv_tb, vmin=0, vmax=1, cmap=sns.color_palette("Reds", n_colors=256))
plt.show()
对比分析
常用方法:钻取
钻取是改变维的层次,变换分析的粒度
- 向上钻取
- 已知每个人的分数,再汇总成每个班的平均分,就是向上钻取的过程
- 向下钻取
- 已知每个班的平均分,再详细到每个人的分数,就是向下钻取的过程
连续值的分组
离散值的分组是比较容易的,而连续值分组常常要先离散化
- 分隔、拐点
- 聚类
- 不纯度(Gini)
import pandas as pd
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context(font_scale=2)
df = pd.read_csv("newHR.csv")
# # 横轴为salary 纵轴为left 以department向下钻取分析
# sns.barplot(x="salary", y="left", hue="department", data=df)
# plt.show()
sl_s = df["satisfaction_level"]
sns.barplot(x=list(range(len(sl_s))), y=sl_s.sort_values())
plt.show()
相关分析
相关分析是研究两个或两个以上处于同等地位的随机变量间的相关关系的统计分析方法
连续值分析
- 相关系数计算
离散值分析
- 有序离散值、二类离散值可以编码成0 1 2来进行皮尔逊相关系数计算,或者用不纯度计算,但又失真
- 用熵来进行相关度计算
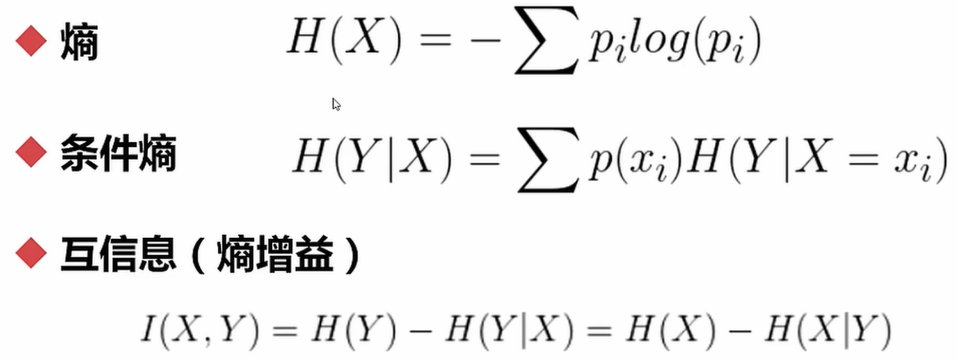
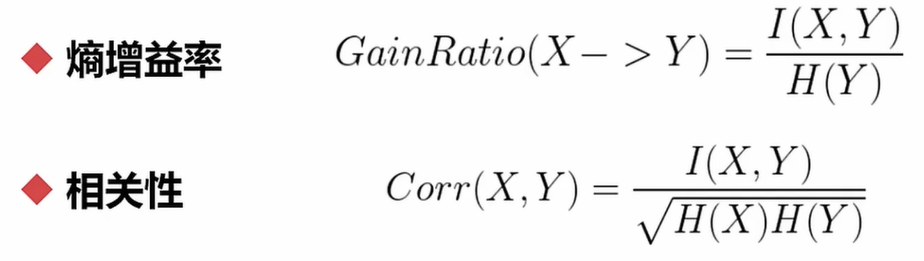
import pandas as pd
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context(font_scale=2)
# df = pd.read_csv("newHR.csv")
#
# ax = sns.heatmap(df.corr(), vmin=-1, vmax=1)
# ax.figure.set_size_inches(16,6)
# ax.set_xticklabels(ax.get_xticklabels(), rotation=0)
# plt.show()
s1 = pd.Series(["X1", "X1", "X2", "X2", "X2", "X2"])
s2 = pd.Series(["Y1", "Y1", "Y1", "Y2", "Y2", "Y2"])
def getEntropy(s):
prt_ary = pd.Series(s).groupby(by=s).count().values / float(len(s))
return -(np.log2(prt_ary) * prt_ary).sum()
def getCondEntropy(s1, s2):
'''
H(s2|s1)
:param s1:
:param s2:
:return:
'''
d = dict()
for i in range(len(s1)):
d[s1[i]] = d.get(s1[i], []) + [s2[i]]
return sum([getEntropy(d[k]) * len(d[k]) / float(len(s1)) for k in d])
def getEntropyGain(s1, s2):
return getEntropy(s1) - getCondEntropy(s2, s1)
def getEntropyGainRatio(s1, s2):
return getEntropyGain(s1, s2) / getEntropy(s2)
import math
def getDiscreteCorr(s1, s2):
return getEntropyGain(s1, s2) / math.sqrt(getEntropy(s1) * getEntropy(s2))
print(getEntropy(s1))
print(getEntropy(s2))
print(getCondEntropy(s1, s2))
print(getCondEntropy(s2, s1))
print(getEntropyGain(s1, s2))
print(getDiscreteCorr(s1, s2))
因子分析
探索性因子分析
为了得到影响目标的主要因子
- 主成分分析
验证性因子分析
是验证一个因子与我们关注的属性之间是否有关联,有什么关联,是否符合预期
- 相关分析
- 卡方检验
- 熵
- F值
- 等等其他方法
例子
用户对产品是否满意?
| 编号 | 年龄 | 性别 | 学历 | … | 生活习惯 | 行为习惯 |
|---|---|---|---|---|---|---|
- 探索性分析
- 进行主成分分析,将全部的因子进行降维
- 降维后与满意度进行对比分析
- 验证性分析
- 验证某个属性与满意度是否有关,得到如相关性、一致性等指标
- 主观判断出某个属性可能和满意度有关系,用回归方法去拟合属性与满意度的关联,去应验自己的假设
import pandas as pd
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context(font_scale=2)
df = pd.read_csv("newHR.csv")
from sklearn.decomposition import PCA
my_pca = PCA(n_components=7)
lower_mat = my_pca.fit_transform(df.drop(labels=["salary", "department", "left"], axis=1))
print("Ratio: ", my_pca.explained_variance_ratio_)
sns.heatmap(pd.DataFrame(lower_mat).corr(), vmin=-1, vmax=1, cmap=sns.color_palette("RdBu", n_colors=256))
plt.show()















 1089
1089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











