







利用自带的jar包运行wordcount程序
参考博客1:https://blog.csdn.net/cai_4399/article/details/78431568
参考博客2:https://www.cnblogs.com/snowbook/p/5712130.html
向HDFS中上传文件
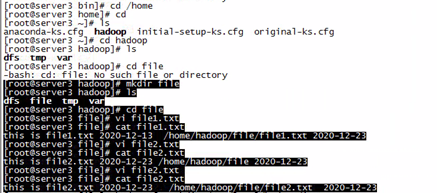
先在server3(一个slave节点)的/home/hadoop/file文件夹下建立两个文本文件:file1.txt、file2.txt
file1的内容:this is file1.txt 2020-12-13 /home/hadoop/file/file1.txt 2020-12-23
file2的内容:this is file2.txt 2020-12-23 /home/hadoop/file/file2.txt 2020-12-23
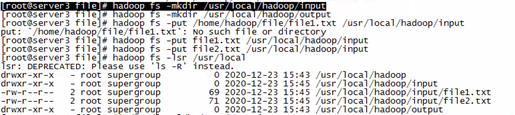
建立HFDS的文件夹:/usr/local/hadoop/input output没啥用
并将两个文件上传到该file文件夹下
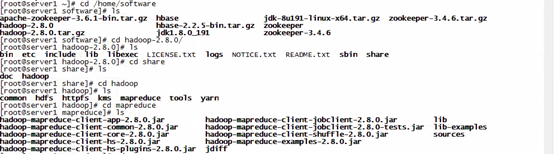
找hadoop自带的jar包
在server1(master节点)中找的,主要在hadoop的安装路径下:
/home/software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar
利用这个jar包运行wordcount程序,格式如下:
执行jar命令 wordcount所在jar包 程序主类名 输入文件夹 输出文件夹
hadoop jar /home/software/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar
wordcount
hdfs://server1:9000/usr/local/hadoop/input/ hdfs://server1:9000/usr/local/hadoop/wordcount_output/
注意:input是我们在hdfs上自己建立的用于输入文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









