







1、关系代数与火山模型
1)关系代数
基本的关系代数运算有选择、投影、集合并、集合差、笛卡儿积等。
在这些基本运算之外,还有一些集合之间的交集、连接、除和赋值等运算。
连接运算可分为连接、等值连接、自然连接、外连接、左外连接和右外连接。
关系代数优化过程
示例 SQL 语句:
select
t1.id,
t2.name
from
t1
join t2 on t1.id = t2.id
where
t1.score = 90
这是一条标准的SQL语句,其中涉及选择、投影、内连接、谓词等。
每一条SQL语句都会经过解析、校验、逻辑计划、物理计划、物理执行。
其中在解析之后会生成抽象语法树,经过抽象语法树后便会转换为关系代数模型。
转换后的关系代数模型:
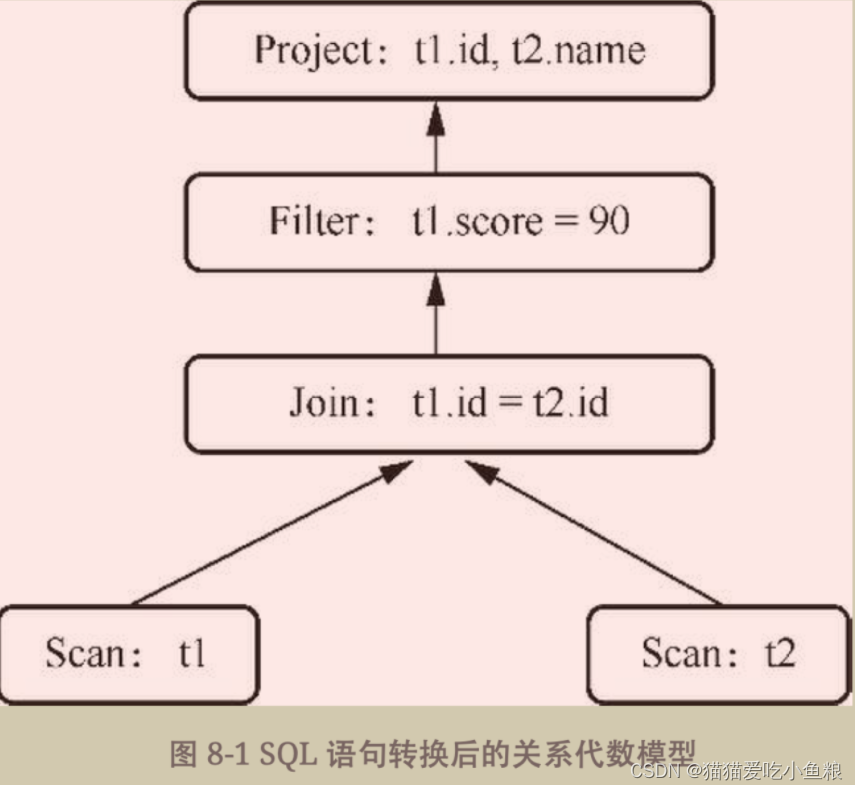
Scan算子:该算子会读取要查询的表数据。因为需要对两张表进行连接,所以示例中出现两个Scan算子分别读取两张表。
Join算子:该算子会把需要读取的表数据根据设定的条件进行连接并筛选出符合条件的数据。示例中会根据两张表的id是否相等进行筛选。
Filter算子:该算子根据条件对数据进行进一步的过滤,抛弃无用数据。示例中会将所有成绩等于90的数据筛选出来。
Project算子:该算子会选取最终需要展示给用户的字段。示例中只需要展示name字段和id字段即可。
该模型将关系代数中每一种操作抽象为一个算子,每个算子内部封装相应的实现逻辑,通过这种方式便将整个数据流转变为自顶向下执行、数据自底向上拉取。该计算模型称为火山模型。
2)火山模型
火山模型又称为迭代器模型,现阶段大部分关系数据库都采用火山模型,如PostgreSQL、Oracle、MySQL等。
火山模型将关系代数每一个操作都抽象成一个迭代器。每个迭代器都带有一个next方法。每次调用都会返回一条计算后的数据。
因此一条SQL语句的计算会从根节点开始不断地调用算子当中的next方法直到最后的叶子节点。
火山模型对每个算子的接口都进行了统一的封装,外部使用时可完全不需要知道算子的内部逻辑,只需要从子节点那里获取想要获取的数据即可。
2、优化器
1)优化器介绍
一条SQL语句大概会经历以下5个步骤:
解析:把SQL语句解析成抽象语法树。
校验:根据元数据信息校验字段、表等信息是否合法。
逻辑计划:生成最初版本的逻辑计划。
逻辑计划优化:对前一阶段生成的逻辑计划进行进一步优化。
物理执行:生成物理计划,执行具体物理计划。
逻辑计划优化 位于 逻辑计划 和 物理执行 之间,生成的 未经优化的逻辑计划 完全是根据 输入的SQL语句 直接转换而来的。
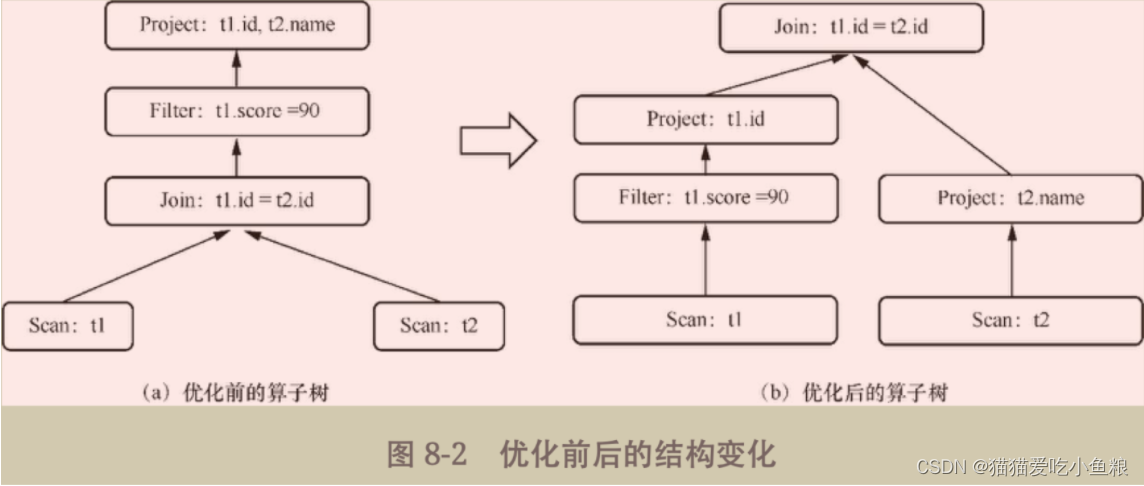
2)优化器的核心
对关系代数模型进行等价转换,通过几步的转换将最初的关系代数模型化为一种更为简单、高效且不影响最终数据结果的关系代数模型。
查询优化主要过程如下:
生成未经优化的逻辑计划,该逻辑计划只是按照最初SQL语句逻辑生成的。
对未经优化的逻辑计划进行等价转换,通过匹配人为设定的规则进行算子的替换,同时必须要保证转换前后返回的结果不变,但执行的成本不同。
通过遍历所有规则寻找执行成本最低的表达式,最终把原始表达式转换为优化后的表达式,将一个SQL语句查询优化得更高效。
3)RBO模型和CBO模型
1.RBO模型
RBO模型核心,根据优化规则对关系表达式进行转换,经过一系列转换后会生成最终的执行计划。
同样一条SQL语句,无论读取的表中数据是怎样的,最后生成的执行计划都是一样的。
在RBO模型中SQL语句写法的不同很有可能会影响最终的执行计划,从而影响执行计划的性能。
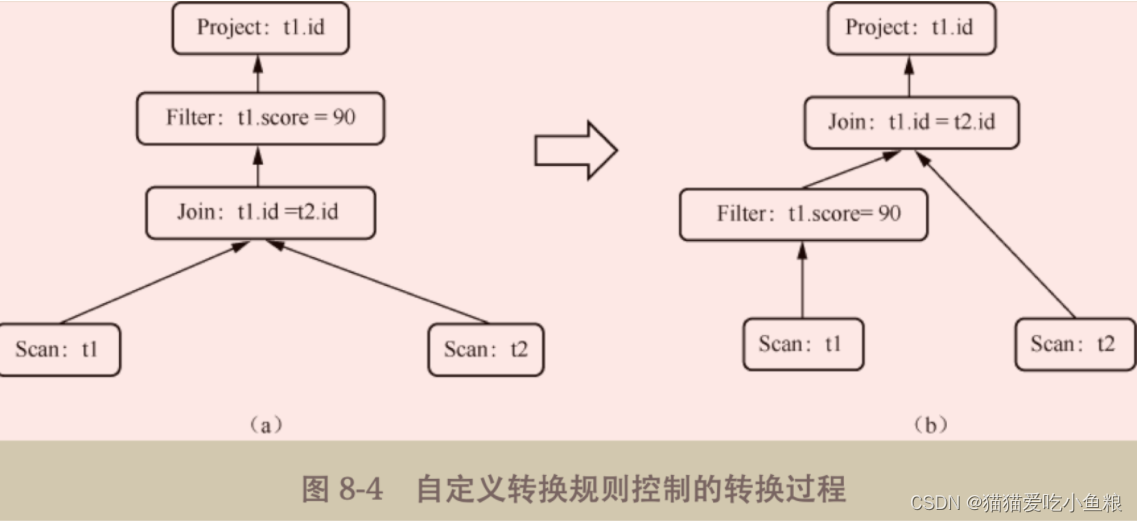
示例 SQL 语句
select t1.id from t1 join t2 on t1.id = t2.id where t1.score=90
设定Filter下推规则
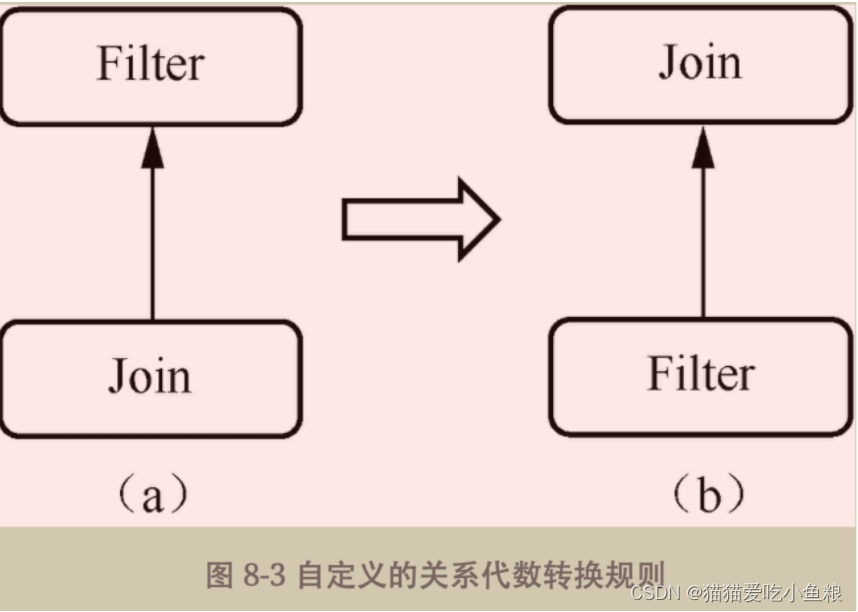
当匹配到关系代数模型中父节点是Filter算子、子节点是Join算子时,就认为结构匹配成功,下推Filter算子到Join算子下方。
**优点:**使用简单。
**缺点:**很有可能一种结构匹配多条规则,这时如何判断使用哪条规则才是最优解呢?
2.CBO模型-基于代价进行更加智能的优化查询
数据的规模会影响一条SQL语句的性能,RBO模型只是定义相关规则而没有考虑数据是变化的,所以RBO模型生成的执行计划往往不一定是最优解。
CBO模型引入了额外的统计信息,包括数据量、CPU、内存、I/O等。
在进行多表 Join 时,底层根据优化器智能选择 Join 的实现方式,其实现方式有3种:Hash Join、Nested Loops和Sort Merge Join。
- Hash Join:将两张表中较小的表利用连接键在内存中建立散列表,将数据存储在散列表当中,然后扫描大表对连接键进行同样的散列操作,这样相同的键会分散到同一个桶当中,从而可以快速找到匹配的行。这种方式适用于可以存储在内存当中的小表。
- Nested loops:用于固定一张表到内存(称为内表),循环从另一张表中读取数据,然后遍历内表。表中的每一行与内表中的相应记录做连接操作。两层for循环,外层for循环访问外表,内层for循环访问内表。此方式同样适用于数据量不是很大的情况。
- Sort Merge Join:先将关联表的关联列各自排序,然后从各自的排序表中抽取数据,到另一张排序表中进行匹配。其排序效率相对较低,因此当其他两者都不适合的时候使用此方式。
选择哪一种实现方式很大程度取决于数据量。
4)寻找关系代数最优解
每一次对 关系代数模型 的转换都是因为 匹配了某个特定的规则,转换后的结果还可以继续匹配规则然后进行转换,直到没有可以匹配的规则。
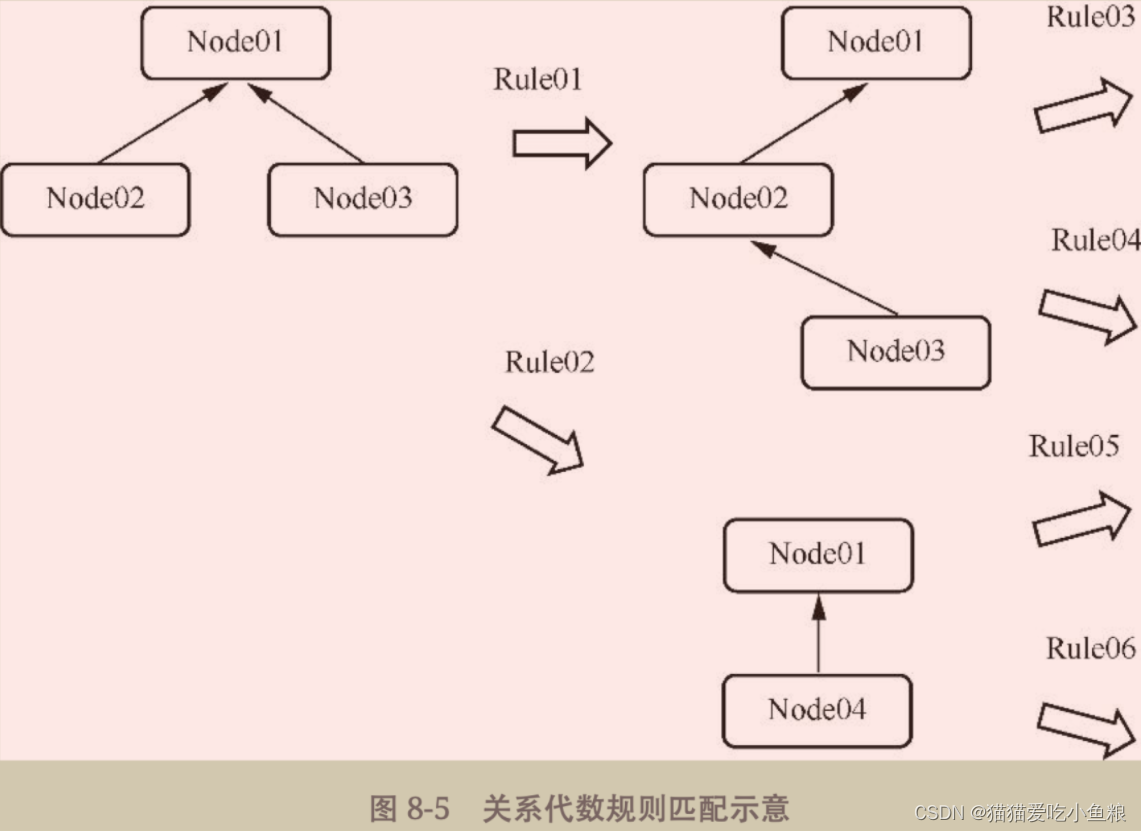
火山优化模型:动态规划和贪心算法(对问题求解时,总是选取当前认为最优的解,而不是从全局的最优角度考虑)。
因此在优化的过程中可以把一棵算子树拆分成几个区域,那么在计算总成本时,只考虑每一个区域得到的最优解,最终所有区域合起来便是整体的最优解。
例如,Cost(sum)=Cost(a)+Cost(b)+Cost©+…。
如果在计算成本的时候a、b、c等的代价都很小,那么整体的代价也不会很大;反之,如果某一个代价非常大,那么整体的代价也会随之上升。
3、Calcite优化器
每一个查询在 Calcite 当中都会转换为算子树,也就是关系代数模型,在 Calcite 当中用户可以通过一条SQL语句进行转换,同时还可以通过官方提供的API构建算子树。
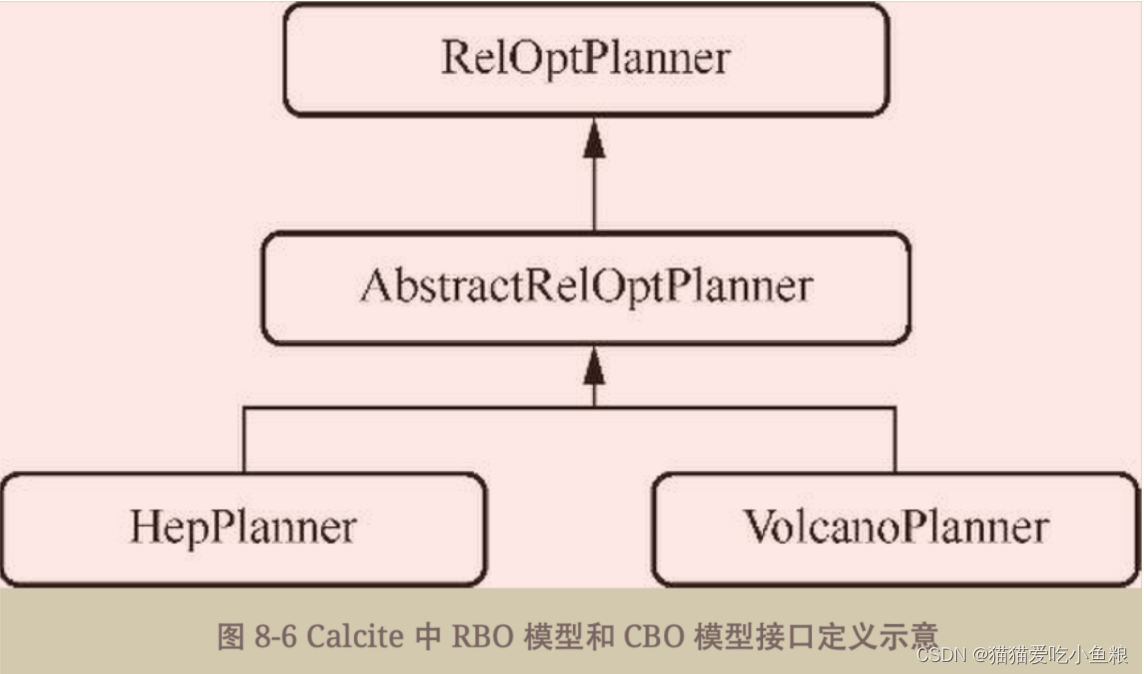
HepPlanner是RBO模型,VolcanoPlanner是CBO模型,官方默认采用的就是CBO模型。
在优化模型方面,Calcite提供了非常灵活的可扩展接口,可以添加属于自己的关系算子、规则、代价模型、统计信息等。
1)构建算子树
在Calcite当中构建算子树是进行优化的前提,因为优化器需要根据算子树的结构来进行规则的匹配,进而实现等价转换。
RelBuilder类用来构建关系表达式,先看该类所提供的方法,如下分别展示了聚合函数和谓词部分列表。
展示了RelBuilder中的部分方法,熟悉的MAX、SUM、AND、CAST、OR等SQL中常见的关键字都在该类中有对应的方法。
每一个方法都对应算子树的一个节点。
例如,通过RelBuilder的create方法创建RelBuilder实例,再构建Scan算子,Scan算子代表扫描的数据源,比如表或视图。
使用create方法构建Scan算子
final FrameworkConfig config = MyRelBuilder.config().build();
final RelBuilder builder = RelBuilder.create(config);
final RelNode node = builder
.scan("data")
.build();
System.out.println(RelOptUtil.toString(node));
输出的执行计划
LogicalTableScan(table=[[csv, data]])
上述代码等同于平常写的SQL语句
Select * from data
继续构建Filter和Project算子,对于字段,使用field方法构建;对于常量值,使用literal方法构建。
构建Filter和Project算子
final FrameworkConfig config = MyRelBuilder.config().build();
final RelBuilder builder = RelBuilder.create(config);
final RelNode node = builder
.scan("data")
.project(builder.field("Name"),builder.field("Score"))
.filter(builder.call(SqlStdOperatorTable.GREATER_THAN,
builder.field("Score"),
builder.literal(90)))
.build();
输出的执行计划
LogicalFilter(condition=[>($1, 90)])
LogicalProject(Name=[$1], Score=[$2])
LogicalTableScan(table=[[csv, data]])
生成算子树的过程中会把字段的信息转换为类似$1、$2这种形式,以便后续操作。
上述代码相当于平常写的SQL语句
select name,score from data where score>90
构建的RelNode符合先进后出的规律,和栈具有相同的性质,构造出RelNode之后都会有一个push方法的实现。
构建RelNode后的处理操作
public RelBuilder scan(Iterable<String> tableNames) {
final List<String> names = ImmutableList.copyOf(tableNames);
final RelOptTable relOptTable = relOptSchema.getTableForMember(names);
if (relOptTable == null) {
throw RESOURCE.tableNotFound(String.join(".", names)).ex();
}
//构建scan算子
final RelNode scan =
struct.scanFactory.createScan(
ViewExpanders.toRelContext(viewExpander, cluster),
relOptTable);
//压入栈中
push(scan);
rename(relOptTable.getRowType().getFieldNames());
//对于非TableScan算子添加别名
if (!(scan instanceof TableScan)) {
as(Util.last(ImmutableList.copyOf(tableNames)));
}
return this;
}
push 方法内部是采用栈的方式来构建表达式的
public RelBuilder push(RelNode node) {
stack.push(new Frame(node));
return this;
}
在许多情况下都是调用builder方法来获取表达式的最后一个节点,也就是root节点。
当表达式存在嵌套的时候还可以用另一种方式来构建,使其看上去更加符合逻辑,例如有以下SQL语句,其中不仅有嵌套子查询,还有多个Join操作。
示例 SQL
select
*
from
(
select
*
from
student
join score on student.id = score.id
) t1
join (
select
*
from
school
join city on school.id = city.id
) t2 on t1.id = t2.id
结构示意图
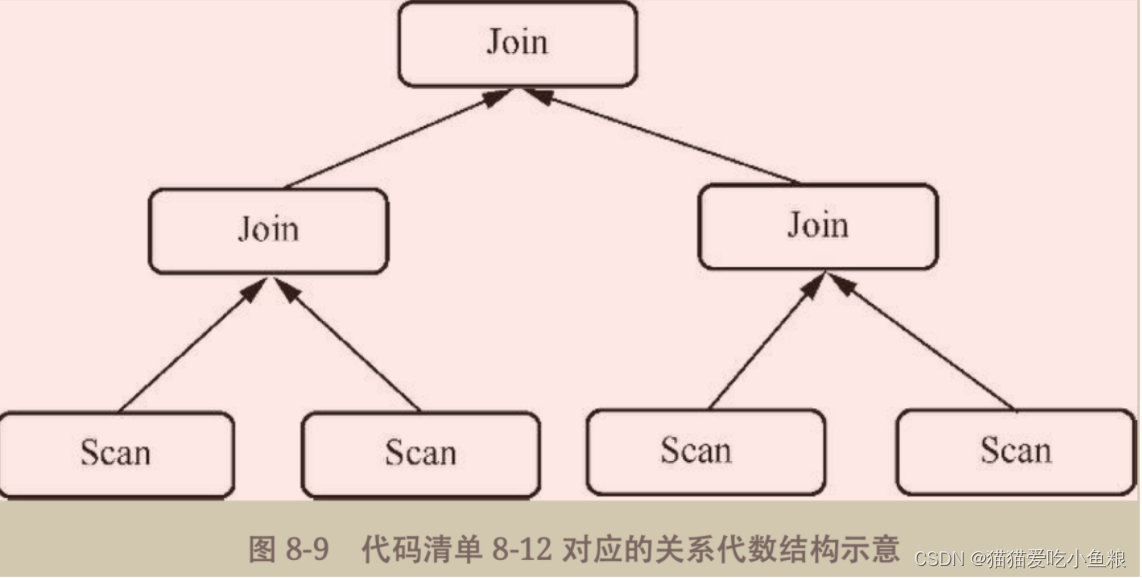
Calcite 当中提供了将每个 Join 分开操作后再汇总。
每个Join分开操作后再汇总示例
private static void joinTest() {
final FrameworkConfig config = MyRelBuilder.config().build();
final RelBuilder builder = RelBuilder.create(config);
final RelNode left = builder
.scan("STUDENT")
.scan("SCORE")
.join(JoinRelType.INNER, "ID")
.build();
final RelNode right = builder
.scan("CITY")
.scan("SCHOOL")
.join(JoinRelType.INNER, "ID")
.build();
final RelNode result = builder
.push(left)
.push(right)
.join(JoinRelType.INNER, "ID")
.build();
}
2)RelNode
在算子树当中每一个节点就是一个RelNode,一条SQL语句经过解析、校验之后便会将SqlNode转换为RelNode做后续的优化。
SqlNode和RelNode在概念上非常相似,都代表对数据做某一种操作,因此名称通常都是用动词来命名的。
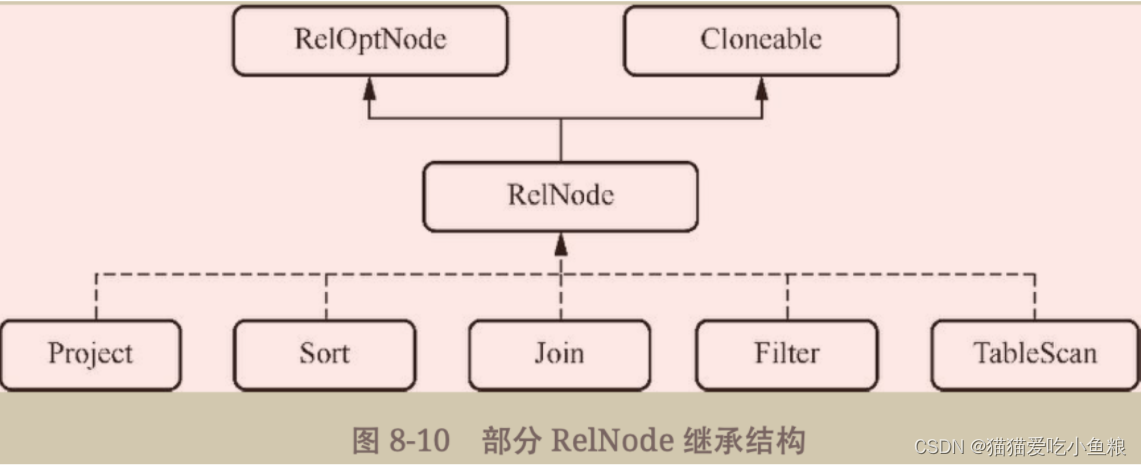
除了RelNode,还有RexNode,它代表的是行表达式,是对字面量、函数等进行的封装。
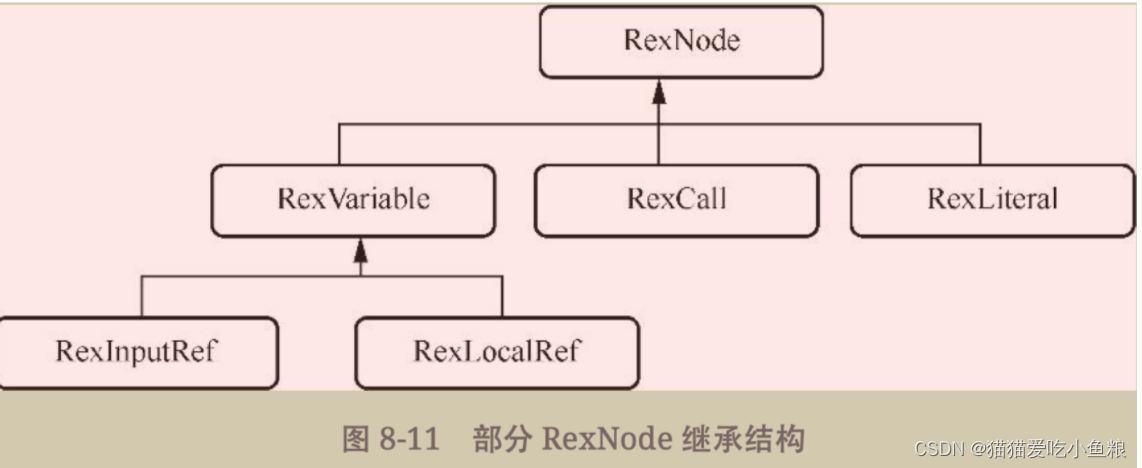
其中RexVariable代表变量表达式,RexCall代表函数等操作,RexLiteral代表常量表达式。
示例 SQL 语句
select * from table where time=to_date('2020-12-12') and name='小明'
上述 SQL 语句中 to_date 就是一个 RexCall,其内部的 “2020-12-12” 字符串就代表 RexLiteral,表中的字段(如name、time)则代表RexInputRef。
在每一个RelNode当中都保存了RexNode,该RexNode记录了行表达式信息,通过行表达式信息后续便会知道是对哪一个字段、哪一个常量做什么样的操作。
3)Calcite优化模型
通过 RelBuilder 构建一个个由 RelNode 组成的算子树节点,最终的目的都是进行等价转换,将效率不高的算子树节点转换为代价更低但又不影响结果的关系代数模型。
1.HepPlanner
在Calcite当中提供了HepPlanner优化器,实现采用了RBO模型。
HepPlanner 优化器整体执行流程
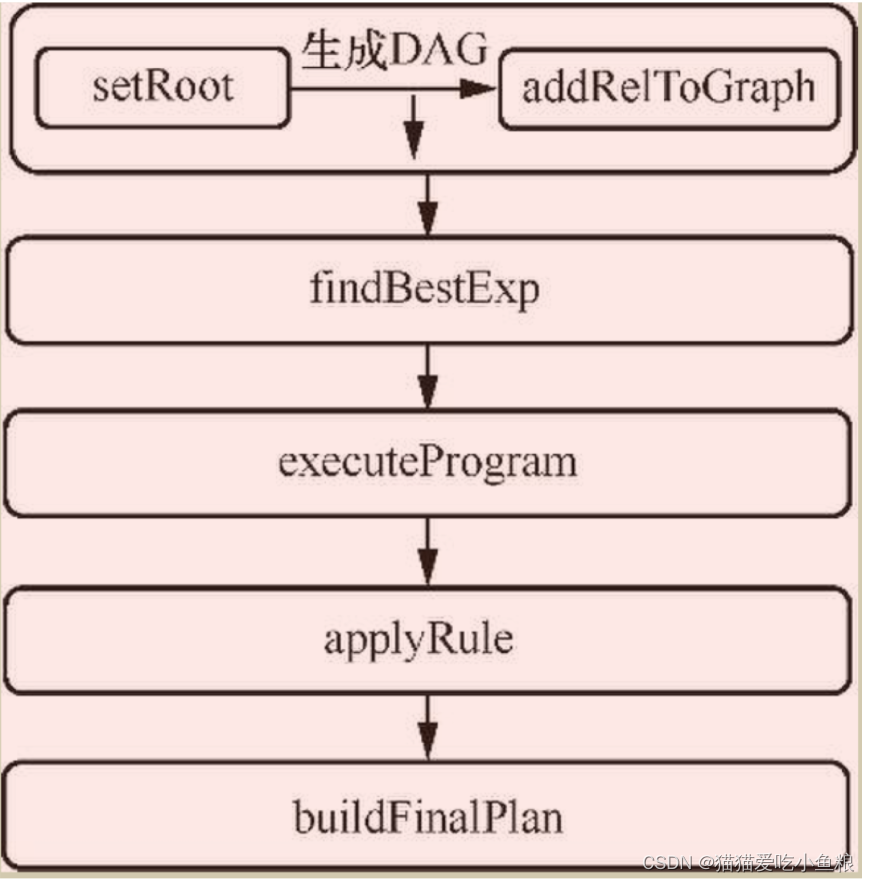
在 Programs 类当中会调用 standard 方法,该方法是优化的入口。
首先调用 setRoot 方法将抽象语法树转换为一个有向无环图(DAG),后续的所有操作便是基于该有向无环图来做相应的操作。
之后便会调用findBestExp方法匹配规则、应用规则。
findBestExp方法
// 实现 RelOptPlanner
public RelNode findBestExp() {
assert root != null;
executeProgram(mainProgram);
collectGarbage();
dumpRuleAttemptsInfo();
return buildFinalPlan(root);
}
在 executeProgram 中会遍历所有注册的规则,然后进行匹配。
观察 Calcite 内部自定义的规则,比如FilterJoinRule,该规则可以将Filter算子下推至Join算子下面。
FilterJoinRule的匹配策略
// 规则匹配
public interface Config extends FilterJoinRule.Config {
Config DEFAULT = EMPTY
.withOperandSupplier(b0 ->
b0.operand(Filter.class).oneInput(b1 ->
b1.operand(Join.class).anyInputs()))
.as(FilterIntoJoinRule.Config.class)
.withSmart(true)
.withPredicate((join, joinType, exp) -> true)
.as(FilterIntoJoinRule.Config.class);
@Override
default FilterIntoJoinRule toRule() {
return new FilterIntoJoinRule(this);
}
}
规则的制定是通过 withOperandSupplier 来实现的,需要传递一个 OperandTransform 类,该类是一个函数式接口,只包含一个抽象方法apply,该 Funciton 需要传递一个 OperandBuilder 参数,返回结果是 Done 类型,代表已经完成。
OperandTransform接口
@FunctionalInterface
public interface OperandTransform extends Function<OperandBuilder, Done> {}
**OperandBuilder 是制定规则的关键。**通过调用 operand(Class)传入相应节点的 RelNode 的 Class 便可以定义该规则。
例如希望制定一条规则为 Project 节点、同时 Project 节点下面没有任何子节点输入就可以这样写。
通过operand定义规则
withOperandSupplier(b0 ->b0.operand(Project.class).noInputs)
如果希望该Project节点的一个输入是Join算子便可以这样写。
withOperandSupplier(b0 ->b0.operand(Project.class).oneInput(b1 ->b1.operand(Join.class).anyInputs()))
再看 FilterJoinRule 的规则。
首先需要匹配到一个算子是Filter算子,在Filter算子下面有一个输入是Join算子,Join算子下面任何输入都可以。
FilterJoinRule规则
.withOperandSupplier(b0 ->
b0.operand(Filter.class).oneInput(b1 ->
b1.operand(Join.class).anyInputs()))
在开始优化之前,Calcite会把RelNode转换为一个有向无环图,该过程发生在优化的第一步——setRoot当中。
未转化为有向无环图的算子树—生成的执行计划
LogicalProject(Id=[$0], Name=[$1], Score=[$2])
LogicalFilter(condition=[=(CAST($0):INTEGER NOT NULL, 1)])
LogicalTableScan(table=[[csv, data]])
在 setRoot 方法中会将每一个 RelNode 节点转化为相应的 HepRelVertex,HepRelVertex 作为有向无环图中的顶点,最终构建出有向无环图。
在有向无环图当中同样也是对逻辑计划的一个描述,只是封装了更多的信息并转化为图而已。
生成的有向无环图—等号左侧展示了封装为HepRelVertex计划,等号右侧为未封装前的计划。
//封装后的节点相当于之前的 LogicalProject
rel#8:HepRelVertex(rel#7:LogicalProject.(input=HepRelVertex#6,inputs=0..2)) =
rel#7:LogicalProject.(input=HepRelVertex#6,inputs=0..2), rowcount=15.0, cumulative cost= 130.0
//封装filter节点
rel#6:HepRelVertex(rel#5:LogicalFilter.(input=HepRelVertex#4,condition==(CAST($0):
INTEGER NOT NULL, 1))) =
rel#5:LogicalFilter.(input=HepRelVertex#4,condition==(CAST($0) :INTEGER NOT NULL, 1)), rowcount=15.0, cumulative cost=115.0
//封装scan节点
rel#4:HepRelVertex(rel#1:LogicalTableScan.(table=[csv, data])) =
rel#1:LogicalTableScan.(table=[csv, data]), rowcount=100.0, cumulative cost=100.0
后续在 findBestExp 方法中对规则进行遍历,核心代码在 applyRule 方法中。
对规则进行遍历的代码实现
do {
Iterator<HepRelVertex> iter = getGraphIterator(root);
fixedPoint = true;
while (iter.hasNext()) {
HepRelVertex vertex = iter.next();
for (RelOptRule rule : rules) {
HepRelVertex newVertex =
applyRule(rule, vertex, forceConversions);//应用所有规则
if (newVertex == null || newVertex == vertex) {
continue;
}
++nMatches;//转换次数加1,当转换次数达到最大值就退出循环
if (nMatches >= currentProgram.matchLimit) {
return;
}
// 根据遍历规则,选择遍历方式
if (fullRestartAfterTransformation) {
iter = getGraphIterator(root);
} else {
iter = getGraphIterator(newVertex);
if (currentProgram.matchOrder == HepMatchOrder.DEPTH_FIRST) {
nMatches =
depthFirstApply(iter, rules, forceConversions, nMatches);
if (nMatches >= currentProgram.matchLimit) {
return;
}
}
fixedPoint = false;
}
break;
}
}
} while (!fixedPoint);
核心在do while循环当中,遍历的每一条规则通过applyRule方法判断该规则是否匹配,如果匹配则返回转换后的节点,如果不匹配则继续循环。
判断规则是否匹配
HepRelVertex newVertex = applyRule(rule, vertex,forceConversions);
并不会一直循环匹配下去,Calcite当中设置了一个变量nMatches,当匹配次数达到最大值时就会结束循环。
在一个规则匹配完成后便会根据设定,遍历该有向无环图到下一个节点。
Calcite当中提供了4种遍历方式。
- ARBITRARY:任意匹配方式,该方式和深度优先遍历是一样的,采用的也是深度优先的方式。
- BOTTOM_UP:从叶子节点开始匹配一直到根节点,一种从下到上的方式。
- TOP_DOWN:从根节点开始匹配,一直到叶子节点,一种从上到下的方式。
- DEPTH_FIRS:深度优先遍历。
通过对每个顶点应用applyRule方法,得到优化后的有向无环图。
最后在buildFinalPlane方法中将每一个节点转化为RelNode并返回。
优化前的执行计划与优化后的执行计划对比如下。
示例SQL语句
select a.Id from data as a join data b on a.Id = b.Id where a.Id>1
优化前的执行计划
LogicalProject(ID=[$0])
LogicalFilter(condition=[>(CAST($0):INTEGER NOT NULL, 1)])//Filter算子在最顶层
LogicalJoin(condition=[=($0, $3)], joinType=[inner])
LogicalTableScan(table=[[csv, data]])
LogicalTableScan(table=[[csv, data]])
优化后的执行计划
LogicalProject(ID=[$0])
LogicalJoin(condition=[=($0, $3)], joinType=[inner])
LogicalFilter(condition=[>(CAST($0):INTEGER NOT NULL, 1)]) //下推后的Filter算子
LogicalTableScan(table=[[csv, data]])
LogicalTableScan(table=[[csv, data]])
2.VolcanoPlanner
a)概述
VolcanoPlanner,会根据实际的查询代价来选择合适的规则进行应用。
Calcite当中默认提供了数据行数、CPU代价、I/O代价,通过这3个方面来影响一个规则的好坏。
b)RelSet和RelSubset 类
RelSet和RelSubset,这两个类在优化阶段起到了至关重要的作用。
CBO模型在计算过程中使用了贪心算法来寻找最优解,因此在计算的过程中可以把已经计算的子问题保存下来,当之后使用到该子问题时就可以直接使用而不需要重新计算。
这其实就是动态规划的思想,将大问题拆分成子问题再对子问题求解,每个子问题并不是独立的,最后将子问题合并成最终结果。
由于每一棵子树有多种等价转换,因此将所有的等价转换保存在RelSet的rels列表中。
定义新的关系表达式列表
// 存储所有的等价转换
final List<RelNode> rels = new ArrayList<>();
// 记录有相同物理属性的关系表达式的最优RelNode
final List<RelSubset> subsets = new ArrayList<>();
在RelSet中还有一个列表是subsets,它代表的是RelSubset集合,用于记录有相同物理属性的关系表达式的最优RelNode。
其中物理属性用于描述该RelNode是否具有分布或者排序等特征。
设想如果某些数据在存储的时候就已经是有序的,那么就可以将其物理属性标注为已排序,这样后续的排序算子就可以省略。
优化后的算子结构
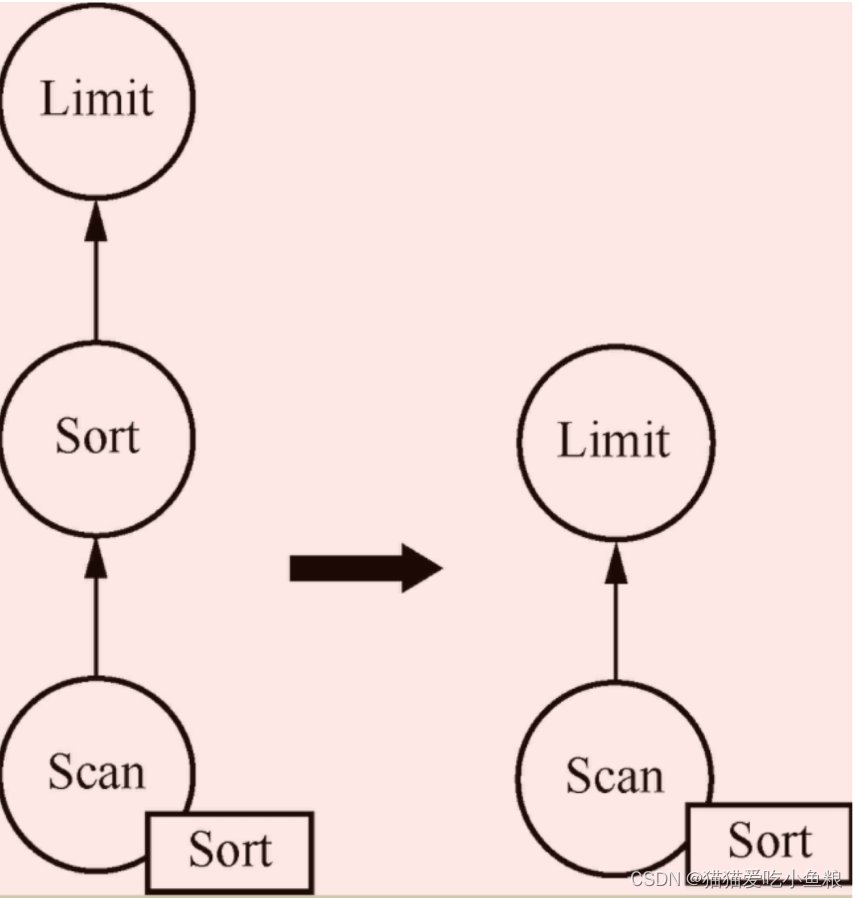
c)setRoot 方法 和 registerImpl方法
和HepPlanner一样VolcanoPlanner同样从setRoot开始,不过不同的是在VolcanoPlanner中并不是将逻辑计划转化为图结构,而是做了一些初始化和将RelNode转换为RelSubset。
其中,registerImpl方法是整个方法的核心。
setRoot方法
public void setRoot(RelNode rel) {
registerMetadataRels();
this.root = registerImpl(rel, null);
if (this.originalRoot == null) {
this.originalRoot = rel;
}
rootConvention = this.root.getConvention();
ensureRootConverters();
}
在 registerImpl 方法中会遍历逻辑计划的子节点以保证每个节点都会进行注册,通过getInputs方法获取其子节点,之后在ensureRegistered方法中递归地再去遍历其子节点,以确保每个节点都会遍历到。
registerImpl方法
// 获取其子节点
List<RelNode> oldInputs = getInputs();
List<RelNode> inputs = new ArrayList<>(oldInputs.size());
for (final RelNode input : oldInputs) {
// 递归地再去遍历其子节点
RelNode e = planner.ensureRegistered(input, null);
assert e == input || RelOptUtil.equal("rowtype of rel before registration",
input.getRowType(),
"rowtype of rel after registration",
e.getRowType(),
Litmus.THROW);
inputs.add(e);
}
RBO模型和CBO模型关键在于会对CPU和数据量做统计和通过计算选择代价最小的节点,因此遍历的每一个节点都会调用registerImpl的addRelToSet方法,在该方法中计算并记录每一个节点的代价,如果有等价表达式同时它的代价更小,便会更新这个RelSubset。
节点调用addRelToSet方法
final int subsetBeforeCount = set.subsets.size();
// 计算并记录每一个节点的代价,如果有等价表达式同时它的代价更小,便会更新这个RelSubset
RelSubset subset = addRelToSet(rel, set);
上述准备工作都做好之后就可以开始对规则进行匹配和筛选,根据“1.HepPlanner”部分所讲的规则匹配方式去匹配关系代数模型中的顺序和算子。
如果匹配就把该条规则加入队列当中,这些队列中的规则将在后续优化过程中起到作用。
fireRules方法
void fireRules(RelNode rel) {
for (RelOptRuleOperand operand : classOperands.get(rel.getClass())) {
if (operand.matches(rel)) {
//规则匹配是否成功
final VolcanoRuleCall ruleCall;
ruleCall = new DeferringRuleCall(this, operand);
ruleCall.match(rel);
}
}
}
将所有能匹配的规则加入队列后,就要开始寻找一个最佳的查询计划,即在Volcano Planner的findBestExp方法中开始寻找最优解。
findBestExp方法
public RelNode findBestExp() {
ensureRootConverters();
registerMaterializations();
//寻找最优解的核心方法
ruleDriver.drive();
}
在drive方法当中使用了一个死循环,不断地从ruleQueue中取出规则有两个条件可以打破循环:
规则队列中弹出的规则为null则退出循环,或者抛出VolcanoTimeoutException异常的时候就会打破循环。
通过不断地匹配规则把关系代数模型转变为等价的新关系代数模型。
当然对于新生成的模型同样需要计算其代价并和之前的做对比,看其代价是否更小,如果更小便会替换该结构。
drive方法:
@Override
public void drive() {
while (true) {
VolcanoRuleMatch match = ruleQueue.popMatch();
if (match == null) {
//没有规则可以匹配退出
break;
}
assert match.getRule().matches(match);
try {
match.onMatch();
} catch (VolcanoTimeoutException e) {
//超时退出
LOGGER.warn("Volcano planning times out, cancels the subsequent optimization.");
planner.canonize();
break;
}
planner.canonize();
}
}
CBO模型在计算的时候使用了贪心算法,为了让整体结构的代价达到最小,它会为每个节点找到最优解,这样最终的解便也是最优的。
因此通过上述计算获取了每个节点的最小代价之后,只要把每个节点组合起来便是最优解。
在RelSubset的buildCheapestPlan方法中递归地组装每一个节点的最优解,最终返回的cheapest便是优化后的结果。
buildCheapestPlan方法
RelNode buildCheapestPlan(VolcanoPlanner planner) {
CheapestPlanReplacer replacer = new CheapestPlanReplacer(planner);
final RelNode cheapest = replacer.visit(this, -1, null);//利用访问者模式去遍历
if (planner.getListener() != null) {
RelOptListener.RelChosenEvent event =
new RelOptListener.RelChosenEvent(
planner,
null);
planner.getListener().relChosen(event);
}
return cheapest;
}
4、自定义优化规则
对于自定义的优化规则,只要规定好需要匹配的节点和想要的转换方式,并将其加入规则当中就大功告成了。
1)CSV规则
将所有的LogicalProject算子转换为CSVProject算子。
1.创建CSVProject算子
CSVProject算子属于RelNode,应该实现RelNode接口,Calcite当中专门提供了Project抽象类,可以直接继承该抽象类,其中computeSelfCost方法定义了该算子最终的代价。
这里为了在做代价计算的时候让该算子变成最优,所以代价值设置为0。
/**
* 创建CSVProject算子
*/
public class CSVProject extends Project {
/**
* 构造方法
*/
public CSVProject(RelOptCluster cluster,
RelTraitSet traits,
RelNode input, List<? extends RexNode> projects,
RelDataType rowType) {
super(cluster,traits, ImmutableList.of(),input,projects,rowType);
}
/**
* 复制投影算子
*/
@Override
public Project copy(RelTraitSet traitSet,
RelNode input,
List<RexNode> projects,
RelDataType rowType) {
return new CSVProject(getCluster(),traitSet,input,projects,rowType);
}
/**
* 计算自身的计算代价
*/
@Override
public RelOptCost computeSelfCost(RelOptPlanner planner, RelMetadataQuery mq) {
return planner.getCostFactory().makeZeroCost();
}
2.制定规则
制定规则的时候需要指定 CSVProject 算子的 Class 和 输入。
规则:将LogicalProject算子转换为CSVProjcet算子,只需要指定LogicalProject算子的Class,将其后续输入设置为anyInputs即可。
在convert方法中需要将LogicalProject算子转换为目标算子,在示例中会将LogicalProject算子转换为CSVProject算子。
定义投影算子匹配逻辑
/**
* 定义投影算子匹配逻辑
*/
public interface Config extends RelRule.Config {
// 匹配规则
Config DEFAULT = EMPTY
.withOperandSupplier(b0 ->
b0.operand(LogicalProject.class).anyInputs())
.as(Config.class);
@Override
default CSVProjectRule toRule() {
return new CSVProjectRule(this);
}
}
/**
* 转换关系代数算子对象
*/
public RelNode convert(RelNode rel) {
final LogicalProject project = (LogicalProject) rel;
final RelTraitSet traitSet = project.getTraitSet();
return new CSVProject(project.getCluster(), traitSet,
project.getInput(), project.getProjects(),
project.getRowType());
}
3.注册规则
在构建HepPlanner或者VolcanoPlanner的时候直接进行规则的注册。
// 启发式模型
HepPlanner hepPlanner =
new HepPlanner(
programBuilder.addRuleInstance(CSVProjectRule.Config.DEFAULT.toRule())
.build());
// 火山模型
RelOptPlanner relOptPlanner = relNode.getCluster().getPlanner();
// 默认获取为VolcanoPlanner
relOptPlanner.addRule(CSVProjectRule.Config.DEFAULT.toRule());
2)RBO模型与CBO模型的对比
定义一个规则,通过调节其计算的代价来直观地对RBO模型和CBO模型进行对比。
新建一个 CSVProjectWithCost 算子,设置相同的优化规则,但是将查询代价设置为无限大。
通过这种方式来对比CBO模型和RBO模型会选择哪一个规则进行优化。
1.RBO
计算自身的代价
public RelOptCost computeSelfCost(RelOptPlanner planner, RelMetadataQuery mq) {
return planner.getCostFactory().makeInfiniteCost();
}
在RBO模型的优化规则下同时注册两个优化规则——CSVProjectRuleWithCost 和 CSVProjectRule
注册优化规则
HepPlanner hepPlanner = new HepPlanner(
programBuilder
.addRuleInstance(CSVProjectRuleWithCost.Config.DEFAULT.toRule())
.addRuleInstance(CSVProjectRule.Config.DEFAULT.toRule()).build());
最终产生的执行计划
CSVProjectWithCost(ID=[$0])
LogicalTableScan(table=[[csv, data]])
对两个优化规则的顺序进行调整
HepPlanner hepPlanner =
new HepPlanner(
programBuilder
.addRuleInstance(CSVProjectRule.Config.DEFAULT.toRule())
.addRuleInstance(CSVProjectRuleWithCost.Config.DEFAULT.toRule())
.build());
此时形成的执行计划
CSVProject(ID=[$0])
LogicalTableScan(table=[[csv, data]])
优化后的算子结构发生了变化,这是因为在遍历规则的时候如果 CSVProjectRule 注册顺序在前,则会直接进行匹配转换,之后CSVProjectRuleWithCost 会因为没有能匹配的节点而结束优化流程。
RBO模型只是遍历规则然后匹配,并没有考虑任何其他信息。
2.CBO
换成VolcanoPlanner优化器,同样注册两个一模一样的规则,但是CSVProjectRuleWithCost算子的代价已经配置到了无限大。
切换优化器代码实现
RelOptPlanner relOptPlanner = relNode.getCluster().getPlanner();
relOptPlanner.addRule(CSVProjectRule.Config.DEFAULT.toRule());
relOptPlanner.addRule(CSVProjectRuleWithCost.Config.DEFAULT.toRule());
relOptPlanner.setRoot(relNode);
RelNode exp = relOptPlanner.findBestExp();
最终优化的结果是 CSVProject,CBO 模型会考虑相关因素(包括查询代价)再进行规则的匹配。
最终的执行计划
CSVProject(ID=[$0])
LogicalTableScan(table=[[csv, data]])
Calcite 中叶子节点也就是TableScan算子的行数默认为100,CPU默认为行数加1。
后续的算子的查询代价全都是基于该代价模型计算的。因此如果没有人为地设置行数,其优化效果也不会非常理想。
查询代价的封装逻辑
//如果没有设置则默认为100行
double dRows = table.getRowCount();
double dCpu = dRows + 1;
double dIo = 0;
return planner.getCostFactory().makeCost(dRows, dCpu, dIo);

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











