







python小知识--创建scrapy工程步骤
前言
python中的scrapy框架是我们在平时使用爬虫使用比较多的框架首先第一步就是创建scrapy工程,下面通过pycharm软件来演示
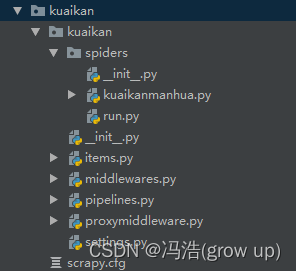
效果图
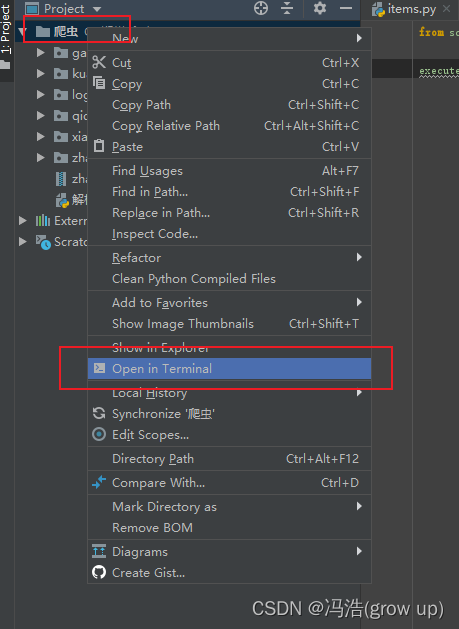
1、右击文件名称选择open in terminal打开终端cmd
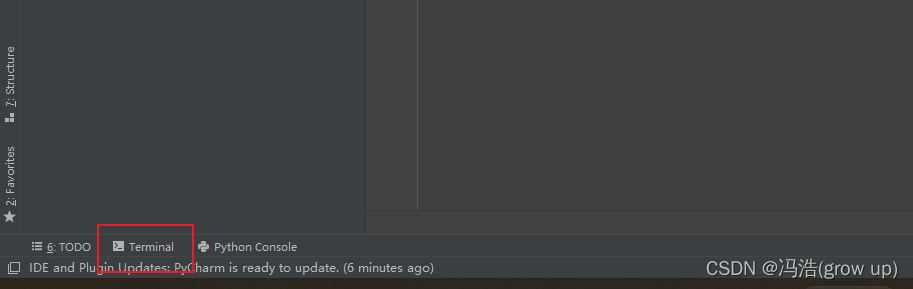
或者选择pycharm左下角的terminal
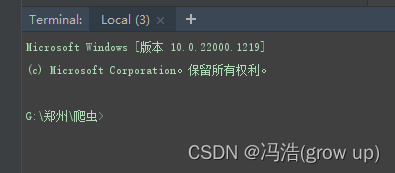
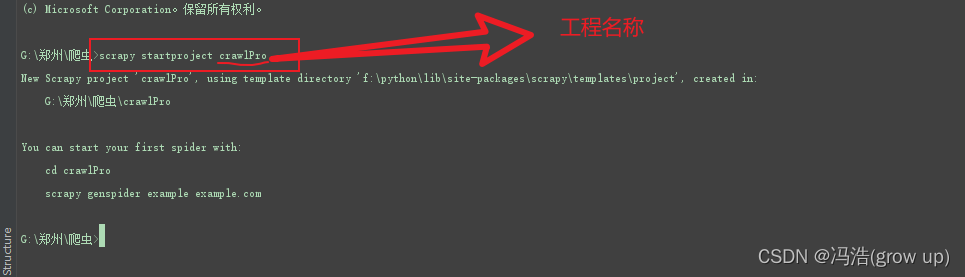
2、在终端控制台输入scrapy startproject kuaikan
kuaikan:工程名称
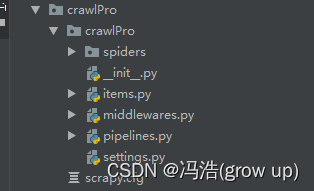
3、创建完成文件夹下有程序文件
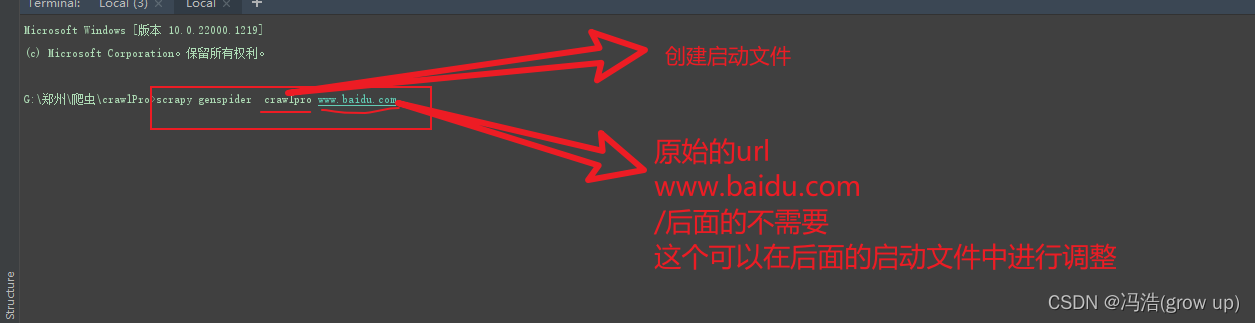
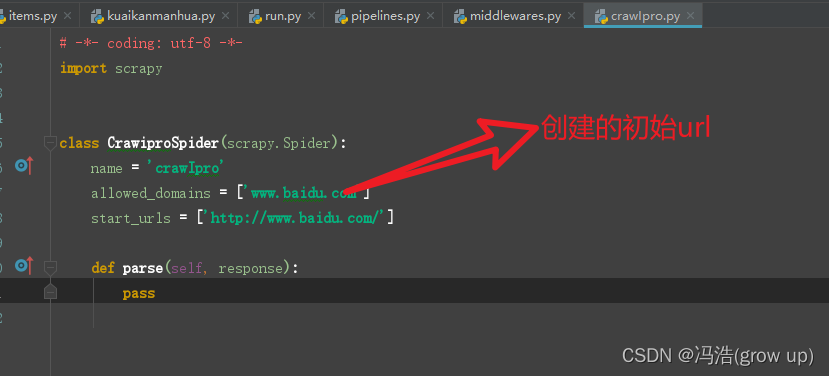
4、创建启动文件scrapy genspider crawIpro www.baidu.com
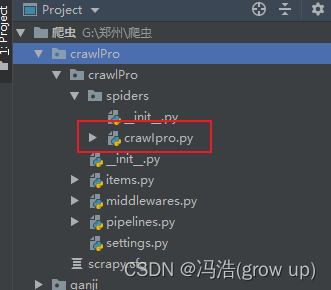
5、创建启动文件后在项目的spiders文件中就会出现启动文件















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









