







一、使用torchvision加载模型
1.使用说明:
torchvision是PyTorch生态系统中的一个包,专门用于计算机视觉任务。它提供了一系列用于加载、处理和预处理图像和视频数据的工具,以及常用的计算机视觉模型。
torchvision.models模块包含许多常用的预训练计算机视觉模型,例如ResNet、AlexNet、VGG等分类、分割等模型。
2.使用方法:Models and pre-trained weights — Torchvision 0.18 documentation
(1)查看torchvision.models提供的全部模型
from torchvision.models import list_models
all_models = list_models()
classification_models = list_models(module=torchvision.models)
返回值是torchvisoin.models中包含的全部模型名称,是一个字符串组成的列表
(2)torchvision.models中包含的模型如下:
a.分类(classification):
AlexNet,ConvNeXt,DenseNet,EfficientNet,EfficientNetV2,GoogLeNet,Inception-V3, MaxVit, MNASNet,MobileNet-v2,MobileNet-v3,RegNet,ResNet,ResNeXt,VGG,VisionTransformer
b.语义分割(Semantic Segmentation):
DeepLabV3,FCN,LRASPP
c.目标检测(Object Detection):
Faster R-CNN,FCOS,RetinaNet,SSD,SSDlite
(3)不带有预训练权重的模型加载:
在torchvision选择对应的模型,即可查看实例化该模型的方法,以ResNet为例:
| 模型实例方法 | 模型说明 |
| resnet18(*[, weights, progress]) | ResNet-18 from Deep Residual Learning for Image Recognition. |
| resnet34(*[, weights, progress]) | ResNet-34 from Deep Residual Learning for Image Recognition. |
| resnet50(*[, weights, progress]) | ResNet-50 from Deep Residual Learning for Image Recognition. |
| resnet101(*[, weights, progress]) | ResNet-101 from Deep Residual Learning for Image Recognition. |
| resnet152(*[, weights, progress]) | ResNet-152 from Deep Residual Learning for Image Recognition. |
from torchvision.models import resnet50
model = resnet50(weights=None)(4)带有预训练权重的模型加载:
在torchvision手册中可查看每个模型包含的预训练权重,以ResNet为例:
| 权重全称 | 参数量 | GFLOPS |
| ResNet101_Weights.IMAGENET1K_V1 | 44.5M | 7.8 |
| ResNet101_Weights.IMAGENET1K_V2 | 44.5M | 7.8 |
| ResNet152_Weights.IMAGENET1K_V1 | 60.2M | 11.51 |
| ResNet152_Weights.IMAGENET1K_V2 | 60.2M | 11.51 |
| ResNet18_Weights.IMAGENET1K_V1 | 11.7M | 1.81 |
| ResNet34_Weights.IMAGENET1K_V1 | 21.8M | 3.66 |
| ResNet50_Weights.IMAGENET1K_V1 | 25.6M | 4.09 |
| ResNet50_Weights.IMAGENET1K_V2 | 25.6M | 4.09 |
具体使用:
from torchvision.models import resnet50, ResNet50_Weights
# Using pretrained weights:
model1 = resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
model2 = resnet50(weights="IMAGENET1K_V1")
二、使用torch.nn模块
1.torch.nn模块中的Containers
(1)torch.nn.Module
a.介绍:
pytorch里面一切自定义操作基本上都是继承nn.Module类来实现的;在定义自已的网络的时候需要继承nn.Module类,并重新实现构造函数__init__构造函数和forward这两个方法;
一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数__init__()中;当然也可以把不具有可学习参数的层也放在里面,但是通常情况下在forward方法里面可以使用nn.functional来代替;
forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心;所有放在构造函数__init__里面的层的都是这个模型的固有属性
b.主要方法和成员变量:
一、成员变量:
1.training(bool):判断当前的模型处于训练(true)还是推断(false)模式
二、成员方法:
1.add_module(name, module):
(1)用法:
将一个子module添加到当前的module中,并赋予相应的名字name,该子module便可以像调用属性一样被调用
(2)参数:
a.name(str):子模型被赋予的名称
b.module(Module):被添加的子模型
2.apply(fn)
(1)用法:
将函数fn作用在该模型的每一个子模型和该模型自己上,常用于参数的初始化
(2)参数:
a.fn(Module -> None):作用于每一个模块的函数名;
用于初始化参数;接受参数类型是一个Module类型的参数;需要提前定义
3.children()
(1)用法:
返回当前Module的子module组成的列表
4.cpu()
(1)用法:
将当前Module和其子Module的参数迁移到CPU上
5.cuda(device=None)
(1)用法:
将当前Module和其子Module的参数迁移到指定的GPU设备上
(2)参数:
a.device(int, optional):指定需要迁移的GPU设备编号
6.eval():
(1)用法:
将模型设置为eval状态;只对某些特定的模块有实际效果;效果等同于self.train(False)
7.forward(*input)
(1)用法:
定义了每次调用时指定的计算方法;应该被每个子类所重写,以代表不同的操作;
调用时直接通过实例名称调用即可,例如:output = model1(input);而不需要通过.forward的方法调用
(2)参数:
a.input(tensor):需要进行操作的张量
8.get_parameter(target)
(1)用法:
获取指定参数target所确定的参数,返回类型为torch.nn.Parameter
(2)参数:
a.target(str):所指定参数的名称,字符串类型
9.get_submodule(target)
(1)用法:
获取指定参数target所确定的子模块,返回类型为torch.nn.Module
(2)参数:
a.target(str):所指定子模块的名称,是字符串类型;
10.load_state_dict(state_dict, strict=True, assign=False)
(1)用法:
将参数state_dict所包含的参数值加载到该模型中;
返回值是可能缺失的参数名称或模型不包含的参数名称组成的列表
(2)参数:
a.state_dict(dict):包含参数的名称和对应状态(值、类型、所属设备)的字典;
b.strict(bool, optional):参数state_dict所包含的键的名称是否需要严格遵守该模型state_dict()返回的值,默认值为True;
11.modules()
(1)用法:
获取该网络模型中的全部module组成的迭代器
12.parameters(recurse=True)
(1)用法:
获取该网络模型中的全部参数组成的迭代器;通常传递给optimizer
(2)参数:
a.recurse(bool):为True时递归的返回该网络模型中的全部参数,包括子模块和本模块;
否则只返回该网络模型中的直接参数而不返回子参数;
13.requires_grad_(requires_grad=True)
(1)用法:
用于修改autograd操作是否记录该module中参数上的梯度
该方法可以用于设置参数的requires_grad属性
可以用于指定梯度更新时变化的参数范围
(2)参数:
a.requires_grad(bool):autograd操作是否记录该module中的参数上的梯度值;默认值为true
14.state_dict(*, prefix: str = '', keep_vars: bool = False)
(1)用法:
返回一个包含该module全部状态的字典;包括该module的参数;其中key为参数的名称;
返回值类型为Dict[str, Any]
(2)主要参数:
a.prefix(str, optional):添加到输出字典的key的前缀字符串,默认值为空字符串.
15.to(device, dtype, non_blocking)
(1)用法:
将该module的参数转换为指定的类型并迁移到指定的设备上
(2)主要参数:
a.device(torch.device):需要迁移的设备名称
b.dtype (torch.dtype):需要转换的数据类型;只能接受浮点或复数类型;
16.train(mode=True)
(1)用法:
将模型设置为train状态;只对某些特定的模块有实际效果;
(2)主要参数:
a.mode(bool):是否将模型设置为训练模式c.使用实例:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5) # submodule: Conv2d
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))(2)torch.nn.Sequential
a.介绍:
nn.Sequential是一个有序的容器,该类将按照传入构造器的顺序依次创建相应的函数,并记录在Sequential类对象的数据结构中,同时以神经网络模块为元素的有序字典也可以作为传入参数。因此,Sequential可以看成是有多个函数运算对象串联成的神经网络,其返回的是Module类型的神经网络对象。
torch.nn.Sequential类中的forward()方法接受任何的输入并按照添加的模块顺序依次对输入进行处理,并在最后一个模块得到输出结果。
b.构造方法:
1.torch.nn.Sequential(*args: Module)
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
2.torch.nn.Sequential(arg: OrderedDict[str, Module])
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))c.具体使用:
1.查看结构:通过print()方法打印Sequential对象来查看它的结构
print(net)
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=5, bias=True)
)
2.使用索引来查看其子模块
print(net[0])
Linear(in_features=20, out_features=10, bias=True)
print(net[1])
ReLU()
3.输出长度
print(len(net))
4.通过索引修改子模块:
net[1] = nn.Sigmoid()
print(net)
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): Sigmoid()
(2): Linear(in_features=10, out_features=5, bias=True)
)
5.删除子模块
del net[2]
print(net)
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): Sigmoid()
)
6.在末尾新增子模块
net.append(nn.Linear(10, 2)) # 均会添加到末尾
print(net)
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): Sigmoid()
(2): Linear(in_features=10, out_features=2, bias=True)
)
7.遍历子模块
net = nn.Sequential(
nn.Linear(20, 10),
nn.ReLU(),
nn.Linear(10, 5)
)
for sub_module in net:
print(sub_module)
Linear(in_features=20, out_features=10, bias=True)
ReLU()
Linear(in_features=10, out_features=5, bias=True)
8.sequential对象的嵌套:
'''在一个 Sequential 中嵌套两个 Sequential'''
seq_1 = nn.Sequential(nn.Linear(15, 10), nn.ReLU(), nn.Linear(10, 5))
seq_2 = nn.Sequential(nn.Linear(25, 15), nn.Sigmoid(), nn.Linear(15, 10))
seq_3 = nn.Sequential(seq_1, seq_2)
print(seq_3)
Sequential(
(0): Sequential(
(0): Linear(in_features=15, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=5, bias=True)
)
(1): Sequential(
(0): Linear(in_features=25, out_features=15, bias=True)
(1): Sigmoid()
(2): Linear(in_features=15, out_features=10, bias=True)
)
)
''''使用多级索引进行访问'''
print(seq_3[1])
Sequential(
(0): Linear(in_features=25, out_features=15, bias=True)
(1): Sigmoid()
(2): Linear(in_features=15, out_features=10, bias=True)
)
print(seq_3[0][1])
ReLU()
'''使用双重循环进行遍历'''
for seq in seq_3:
for module in seq:
print(module)
Linear(in_features=15, out_features=10, bias=True)
ReLU()
Linear(in_features=10, out_features=5, bias=True)
Linear(in_features=25, out_features=15, bias=True)
Sigmoid()
Linear(in_features=15, out_features=10, bias=True)(3)torch.nn.ModuleList
a.介绍:
ModuleList是一个持有子模块的类,是torch.nn.Module的一个子类。与torch.nn.Sequential 不同之处在于torch.nn.ModuleList不会自动地对添加到其中的模块进行前向传播,需要手动激活。ModuleList主要用于存储多个模块,并且在需要时可以手动地迭代这些模块。
torch.nn.ModuleList将其内部的所有模块存放于一个列表中,可以存储任意数量的nn.Module对象;当将nn.Module实例添加到ModuleList时,这些子模块会自动注册到主模块中,这意味着它们的参数(权重和偏置)将被优化器所跟踪。
b.构造方法:
torch.nn.ModuleList(modules=None)
modules(iterable, optional):一个由需要添加的nn.Module对象所组成的迭代器
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
def forward(self, x):
ModuleList对象可以当做一个迭代器使用或通过int类型的下标索引对其中包含的模块进行访问
for i, l in enumerate(self.linears):
x = self.linears[i // 2](x) + l(x)
return xc.使用场景:
c.1.模块化:当网络由多个独立模块组成,并且这些模块可能需要以非顺序或基于条件的方式执行时
c.2.条件执行:某些模块可能仅在特定条件下被激活,例如,基于输入数据的不同特征或中间层的输出;
c.3.并行处理:如果你的网络设计中需要并行处理输入,比如在多任务学习中,不同的任务可能需要不同的网络分支;
c.4.动态结构:网络结构可能在训练过程中动态变化,例如,某些模块可能根据数据或性能反馈进行添加、移除或替换;
c.5.资源共享:当你希望共享网络中的某些层,但又需要对这些层的输出进行不同的后续处理时;
c.6.复杂循环:在循环网络中,可能需要重复使用相同的模块多次,但每次重复时可能有不同的输入或状态;
c.7.自定义操作:需要在模块之间执行自定义操作或计算,这些操作无法通过简单的顺序或并行结构来实现;
c.8.模块迭代:需要迭代网络中的所有模块以进行特定的操作,如自定义的初始化、正则化或自定义的损失函数计算;
d.内部定义的方法:
1.append(module):添加一个module到指定的ModuleList中
参数说明:
a.module(nn.Module):需要添加的模块
2.extend(modules):在原有的ModuleList后面扩展多个modules
参数说明:
a.modules(iterable):由需要添加的modules组成的迭代器
3.insert(index, module):在原有的ModuleList指定位置index处新插入一个module
参数说明:
a.index(int):需要插入的位置
b.module(nn.Module):需要添加的模块(4)torch.nn.ModuleDict
a.介绍:
torch.nn.ModuleDict将所有的子模块以键值对的形式存放到一个字典中,ModuleDict可以像常规Python字典一样按照子模块的名称(键)对其进行索引,并且其所包含的模块都会被注册,这意味着它们的参数(权重和偏置)将被优化器所跟踪,并且会被所有的Module方法看到。另外,ModuleDict是一个有序字典。
b.构造方法:
torch.nn.ModuleDict(modules=None)
modules(iterable, optional):一个由多个(String:nn.module)映射组成的字典或迭代器
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict([
['lrelu', nn.LeakyReLU()],
['prelu', nn.PReLU()]
])
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return xc.内部定义的方法:
1.clear():清除掉原本ModuleDict中包含的全部内容
2.items():返回ModuleDict中所有键值对组成的迭代器
3.keys():返回ModuleDict中所有的键组成的迭代器
4.pop(key):删除掉ModuleDict中键为key的键值对,并返回该键对应的Module值对象
参数说明:
key(String):需要删除的键,为字符串类型
5.values():返回ModuleDict中所有的Module对象值组成的迭代器
6.update(modules):根据传入的modules键值对更新原ModuleDict中对应的键值对
如果modules是OrderedDict,ModuleDict,或可迭代的键值对则保留其中新元素的顺序
参数说明:
modules(iterable):从字符串(String)到模块(module)的映射(字典)或类型为(String,Module)的键值对的迭代器(4)torch.nn.ParameterList
a.介绍:
torch.nn.ParameterList可以将模型中的参数存放于同一个列表之中,并且通过索引的方式进行调用。torch.nn.ParameterList中的元素类型都是torch.nn.Parameter类型的,如果存放其他类型的元素则会报错。与之前的类似,torch.nn.ParameterList同样会把其中的参数自动注册,这意味着它们的参数(权重和偏置)将被优化器所跟踪,并且会被所有的Module方法看到。
b.构造方法:
torch.nn.ParameterList(values=None)
其中values是一个由torch.nn.Parameter类型的元素组成的列表
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(10, 10)) for i in range(10)])
def forward(self, x):
# ParameterList can act as an iterable, or be indexed using ints
for i, p in enumerate(self.params):
x = self.params[i // 2].mm(x) + p.mm(x)
return xc.内部定义的方法:
1.append(value):在原有ParameterList后添加一个新的Parameter类型的对象
参数说明:
value(torch.nn.Paramter):新添加的Parameter对象
2.extend(values):在原有ParameterList后增加values中的内容
参数说明:
values(torch.nn.ParameterList):新添加的ParameterList类型的对象(5)torch.nn.ParameterDict
a.介绍:
torch.nn.ParameterDict将所有的参数以键值对的形式存放到一个字典中,ParameterDict可以像常规Python字典一样按照参数的名称(键)对其进行索引。ParameterDict值的类型都是torch.nn.Parameter而不能是其他的类型。ParameterDict所包含的参数都会被注册,这意味着它们将被优化器所跟踪,并且会被所有的Module方法看到。
另外,ParameterDict是一个有序字典。当通过update()方法更新时,如果传入的参数是一个无序的Python字典,那么原先的键值对顺序会被修改;而如果传入的参数是一个有序的字典OrderedDict或另一个ParameterDict时,将会保存原先的顺序。
b.构造方法:
torch.nn.ParameterDict(parameters=None)
其中parameters是一个字典,通常情况下其键的类型为String而值的类型为torch.nn.Parameter
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.params = nn.ParameterDict({
'left': nn.Parameter(torch.randn(5, 10)),
'right': nn.Parameter(torch.randn(5, 10))
})
def forward(self, x, choice):
x = self.params[choice].mm(x)
return xc.内部定义的方法:
1.clear():清除掉原有ParameterDict中的全部内容
2.copy():返回一个ParameterDict的复制实例
3.fromkeys(keys, default=None):返回一个带有提供的键组成的ParameterDict
参数说明:
a.keys(iterable, string):在原有ParameterDict新增的键组成的集合
b.default(Parameter, optional):为每个键所设置的默认值,其类型为torch.nn.Parameter
4.get(key, default=None):获取ParameterDict中key所对应的值,如果该key不存在则返回default
参数说明:
a.key(str):需要获取值所对应的key
b.default(Parameter, optional):如果键key不存在返回的值
5.items():返回ParameterDict中所有键值对组成的迭代器
6.keys():返回ParameterDict中所有键组成的迭代器
7.pop(key):从ParameterDict中删除掉key并返回其对应的值
参数说明:
a.key(str):需要删除的键
8.popitem():从原有的ParameterDict中删除并返回最后插入的键值对
9.values():返回ParameterDict中所有值组成的迭代器
10.update(parameters):根据parameters更新原有ParameterDict中的内容
如果parameters中的键在原有的ParameterDict中已经存在,那么就会更改对应的值
参数说明:
a.parameters(iterable):需要更新的键值对组成的迭代器,可以是字典、有序字典或另外一个ParameterDict
11.setdefault(key, default=None):为原有的ParameterDict中的key设置默认值,如果key不存在那么在ParameterDict中新增键值对时如果没有指定值那么该键对应的值为默认值default
参数说明:
a.key(str):需要设置默认值的键
b.default(Any):需要设置的默认值2.torch.nn模块中的卷积层Convolution Layers
(1)torch.nn.Conv1d
a.介绍:
torch.nn.Conv1d用于对由几个输入平面组成的输入信号进行1D卷积的操作。一维卷积不代表卷积核只有一维,也不代表被卷积的feature也是一维,而是说卷积的方向是一维的,也就是只在输入的最后一个维度上利用卷积核进行卷积操作,卷积核移动的方向是一维的。
计算方法:

输入和输出张量形状的变化:

b.构造方法:
torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
参数说明:
a.in_channels(int):输入信号的通道数目;
b.out_channels(int):卷积输出内容的通道数目;
c.kernel_size(int or tuple):用于控制卷积核的尺寸;
经测试后卷积核的大小应为in_channels(行)*kernel_size(列)
e.stride(int or tuple, optional):卷积操作的步长
f.padding(int tuple or str, optional):输入的每一条边补充0的层数
默认值为0表示不进行padding操作
如果为int类型,则表示每条边padding的大小相同
如果为tuple类型,则表示每条边padding的大小与tuple中的具体内容有关
如果为'valid',则表示不进行padding操作
如果为'same',则表示通过padding操作使得输出和输入的维度相同,但是该模式仅支持stride=1
g.dilation(int or tuple, optional):卷积核元素之间的间距,默认值为1
h.groups(int, optional):从输入通道到输出通道的阻塞连接数,默认值为1
i.bias(bool, optional):如果bias = True则添加偏置,默认值为true
使用实例:
m = nn.Conv1d(16, 33, 3, stride=2)
input = torch.randn(20, 16, 50)
output = m(input)c.内部变量:
1.weight(Tensor):该卷积层可学习的权重参数
该参数的维度为(out_channels,groups/in_channels,kernel_size)
2.bias(Tensor):该卷积层可学习的偏置参数
该参数的维度为(out_channels)d.使用实例:详解torch.nn.conv1d-CSDN博客
input1 = torch.randn(20, 16, 50)
m = nn.Conv1d(16, 33, 3, stride=2)
output = m(input1) # torch.Size([20, 33, 24])

m = nn.Conv1d(4, 2, 3, stride=2)
# 第一个参数理解为batch的大小,输入是4 * 9格式
input = torch.randn(1, 4, 9)
print(input)
output = m(input)
print(output)
print(output.size())
(2)torch.nn.Conv2d
a.介绍:
torch.nn.Conv2d用于对由几个输入平面组成的输入信号进行2D卷积的操作。二维卷积不代表卷积核只有二维,也不代表被卷积的feature也是二维,而是说卷积的方向是二维的,也就是只在输入的最后两个维度上利用卷积核进行卷积操作,卷积核移动的方向是二维的。
计算方法:
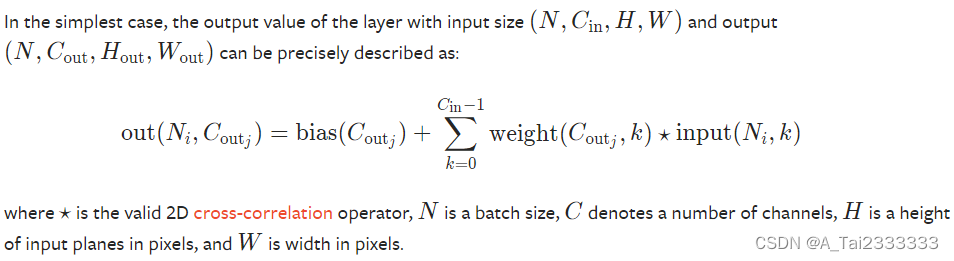 输入和输出张量形状的变化:
输入和输出张量形状的变化:

b.构造方法:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
参数说明:
a.in_channels(int):输入信号的通道数目;
b.out_channels(int):卷积输出内容的通道数目,也就是卷积产生的通道数
c.kernel_size(int or tuple):用于控制卷积核的尺寸;
经测试后卷积核的大小应为in_channels(行)*kernel_size(列)
如果
e.stride(int or tuple, optional):卷积操作的步长,默认为1
f.padding(int tuple or str, optional):输入的每一条边补充0的层数
默认值为0表示不进行padding操作
如果为int类型,则表示每条边padding的大小相同
如果为tuple类型,则表示每条边padding的大小与tuple中的具体内容有关
如果为'valid',则表示不进行padding操作
如果为'same',则表示通过padding操作使得输出和输入的维度相同,但是该模式仅支持stride=1
g.dilation(int or tuple, optional):卷积核元素之间的间距,默认值为1
h.groups(int, optional):从输入通道到输出通道的阻塞连接数,默认值为1
i.bias(bool, optional):如果bias = True则添加偏置,默认值为true
参数kernel_size,stride,padding,dilation可以为一个整数或一个由两个整数组成的元组
当是一个整数时:对width和height两个维度进行相同的操作
当是一个由两个整数组成的元组时:第一个整数用于对height维度进行操作,第二个维度用于给width维度进行操作
使用实例:
With square kernels and equal stride
m = nn.Conv2d(16, 33, 3, stride=2)
non-square kernels and unequal stride and with padding
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
non-square kernels and unequal stride and with padding and dilation
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
input = torch.randn(20, 16, 50, 100)
output = m(input)c.内部变量:
1.weight(Tensor):该卷积层可学习的权重参数
该参数的维度为(out_channels, in_channels/groups,kernel_size[0],kernel_size[1])
2.bias(Tensor):该卷积层可学习的偏置参数
该参数的维度为(out_channels)d.实例参考: pytorch中的torch.nn.Conv2d()函数图文详解_python_脚本之家
3.torch.nn模块中的池化层Pooling Layers
(1)torch.nn.MaxPool1dtorch.nn.MaxPool1d各参数分析-CSDN博客
a.介绍
torch.nn.MaxPool1d用于对由几个输入平面组成的输入信号进行1D最大池化操作。一维池化不代表卷积核只有一维,也不代表被卷积的feature也是一维,而是只在输入的最后一个维度上进行最大池化操作。


b.构造方法
torch.nn.MaxPool1d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数说明:
kernel_size(int或Tuple[int]):
池化窗口大小,必须大于0,如果为int类型则表示池化层的核大小为(1,kernel_size)
stride(int或Tuple[int],optional):
池化窗口的移动步长大小,必须大于0,默认值是kernel_size
如果为int类型则表示池化窗口在最后一个维度上的移动步长,其余维度移动步长均为1
首先会沿着最后一个维度移动;当最后一个维度移动到头后才会在倒数第二个维度上重复上述过程
直到所有的维度都处理过为止
padding(int或Tuple[int],optional):
输入的每一条边补充0的层数,每个值必须在[0,kernel_size/2]的范围内,默认不填充
dilation(int或Tuple[int],optional):
一个控制池化窗口中元素之间的距离,默认值为1,必须大于0
return_indices(bool,optional):
如果等于True会返回输出最大值的序号,对于上采样操作会有帮助,默认值为False
ceil_mode(bool,optional):
如果等于True,在计算输出信号大小的时候会使用向上取整,代替默认的向下取整的操作,默认值为False
m = nn.MaxPool1d(3, stride=2)
input = torch.randn(20, 16, 50)
output = m(input)c.使用示例
import torch
import torch.nn as nun
m = nn.MaxPool1d(3, stride=2)
input = torch.randn(2, 4, 5)
output = m(input)
print(input)
print(output)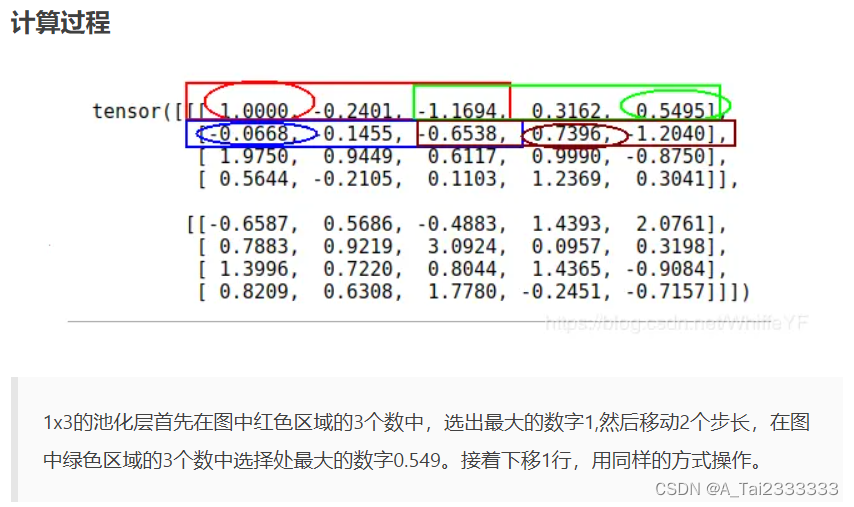















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









