






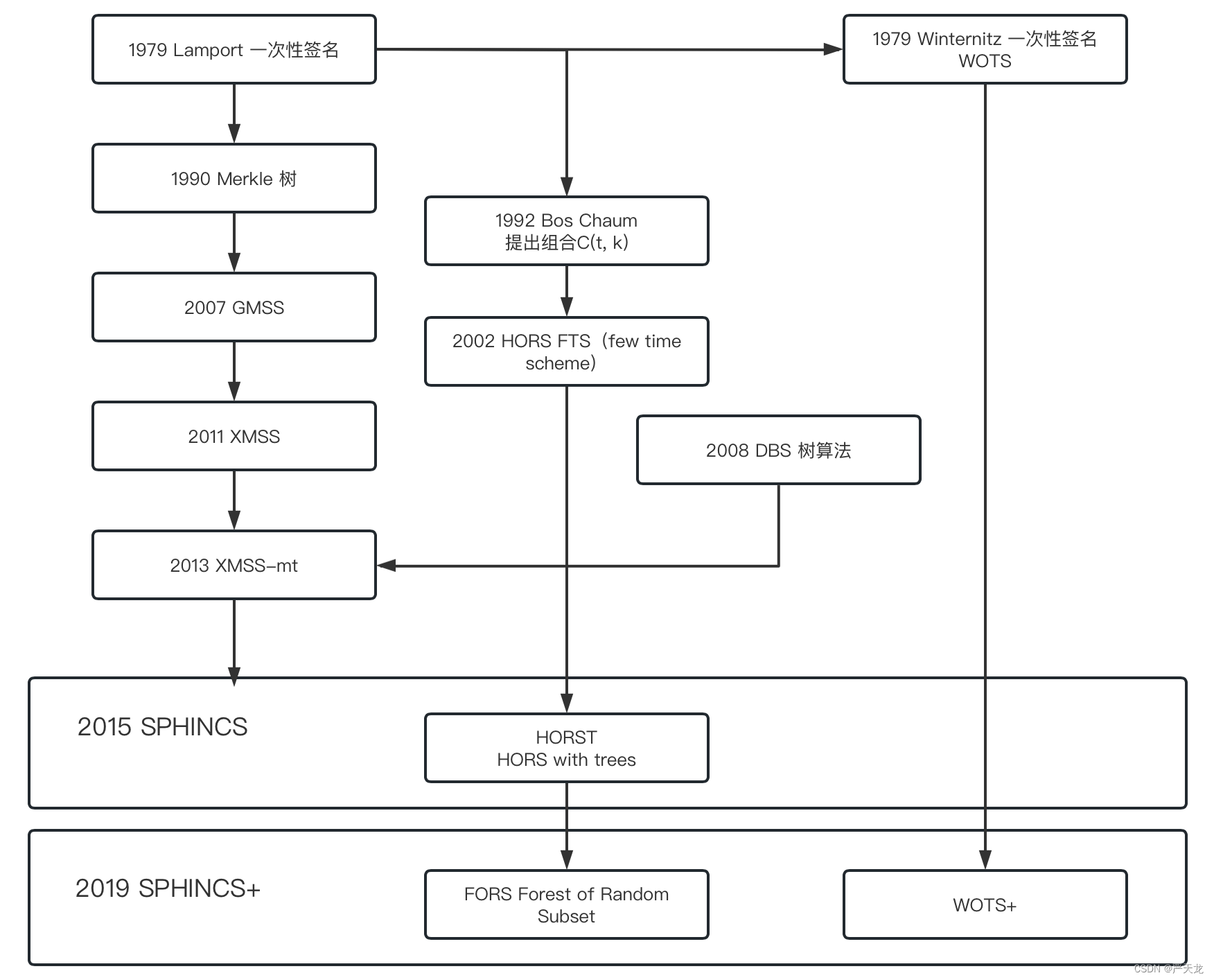
第一集 哈希签名始祖 Lamport 方案及其改进版本(Merkle,Winternitz)
第二集 哈希签名树 Merkle Tree Authentication
第三集 HORS Hash to Obtain Random Subset 2002、DBS算法 2008
第四集 GMSS、XMSS、Multi Tree XMSS
第五集 SPHINCS 2015 SPHINCS+ 2019(完结撒花)
一、SPNICS 2015
Daniel J. Bernstein等人在2015年发布的论文《SPHINCS: practical stateless hash-based
signatures》
其总体框架和XMSS MT区别不大,都是“超树”结构。
SPHINCS 在XMSS MT的基础上创新性的点有两个:
- 提出了HORST(HORS Tree),在HORS的基础上,结合Merkle Tree的树结构思想,可以让公钥从 t ∗ l t*l t∗l 减小到 l l l()。这在第三集的 三、HORS的问题 和 SPHINCS中提出对应的解决方案 中提到过。因为HORS是一种FTS(Few Time Signature),所以也是在SPHINCS中,第一次提到把FTS结合到XMSS MT结构中。大大增加了密钥对的可重用性。
- 使用了“密钥种子”代替密钥,减小了密钥对的大小。
1.1 HORST
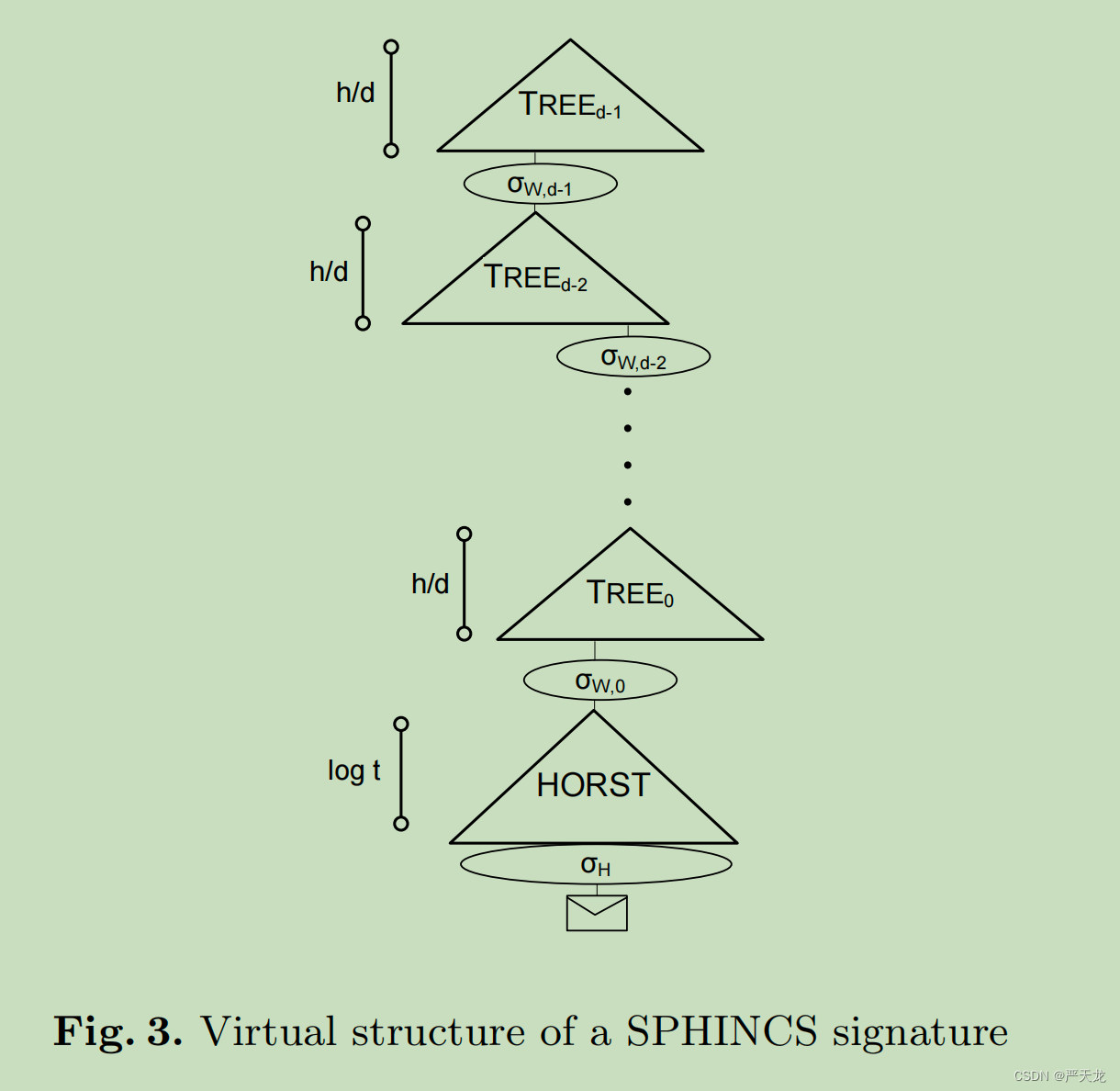
从结构图我们可以看到,SPHINCS的总体架构和XMSS MT是一样的。不同点在于最后一层树
T
R
E
E
0
TREE_0
TREE0的叶子节点,SPHINCS连接的的是HORST的签名,而XMSS MT连接的是WOTS的签名。如下图所示:
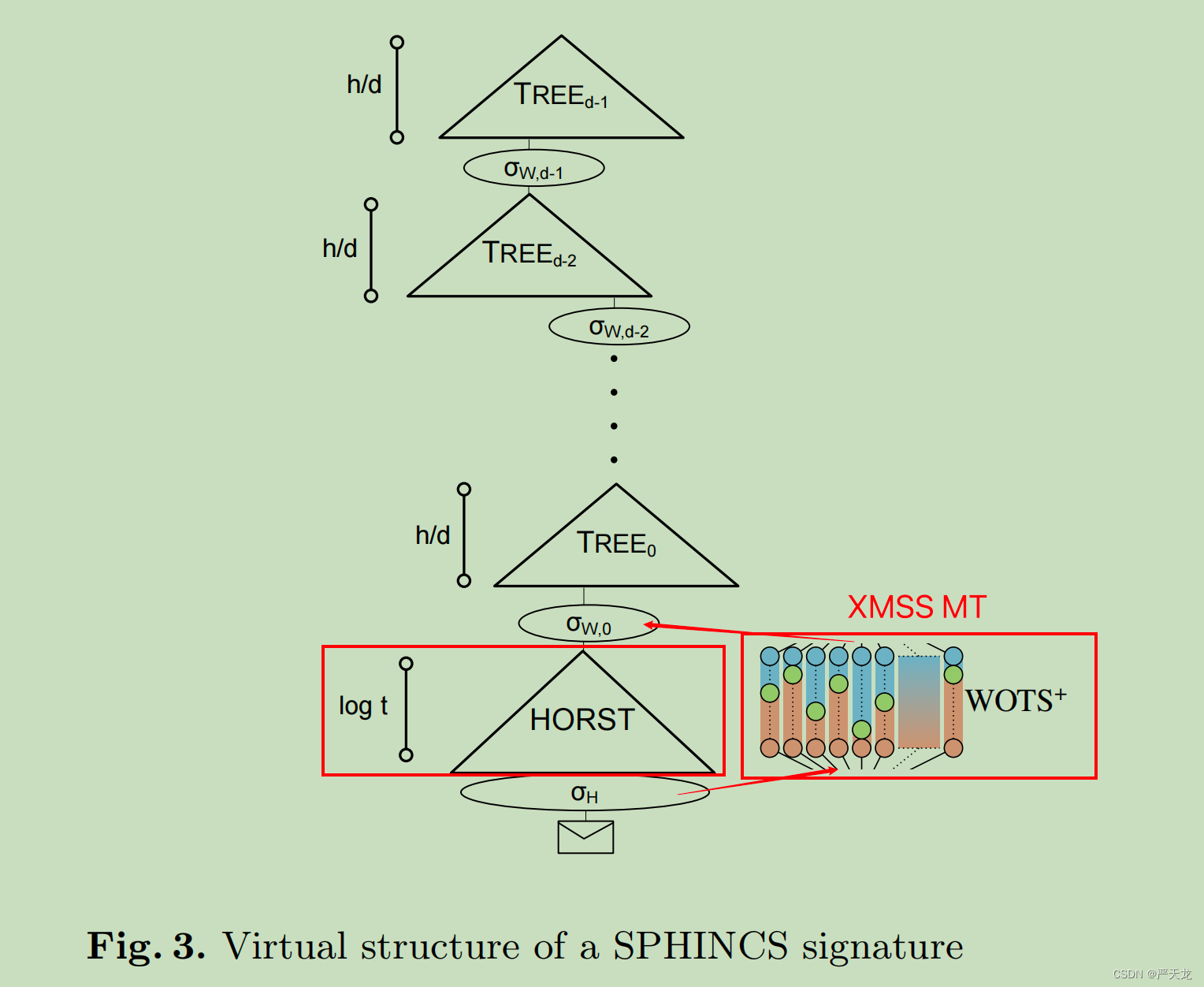
一个是OTS(WOTS),一个FTS(HORST),因此与XMSS MT对比,SPHINCS能够签名的数量大大增加。
1.2 密钥种子
由于SPHINCS中有大量的WOTS和HORST,每一个WOTS和HORST就会有大量的密钥对(即私钥和公钥),如果直接把这些密钥对放在一起当作是整个SPHINCS算法(超树)的的密钥对,会显得很庞杂。所以为了方便以及减小密钥对的大小,SPHINCS提出了“用密钥生成密钥”的思想。
SPHINCS的密钥对组成如下:
私钥:SK,公钥:PK
S
K
=
(
S
K
1
,
S
K
2
,
Q
)
SK = (SK_1,SK_2,Q)
SK=(SK1,SK2,Q)
P
K
=
(
P
K
1
,
Q
)
PK=(PK_1,Q)
PK=(PK1,Q)
1.2.1 私钥
先说一下私钥
S
K
=
(
S
K
1
,
S
K
2
,
Q
)
SK = (SK_1,SK_2,Q)
SK=(SK1,SK2,Q)
S
K
1
SK_1
SK1和
S
K
2
SK_2
SK2,是通过采样得到(随机采样),长度均为
n
n
n
(
S
K
1
,
S
K
2
)
∈
{
0
,
1
}
n
×
{
0
,
1
}
n
(SK_1,SK_2) \in \{0,1\}^n \times \{0,1\}^n
(SK1,SK2)∈{0,1}n×{0,1}n
Q
Q
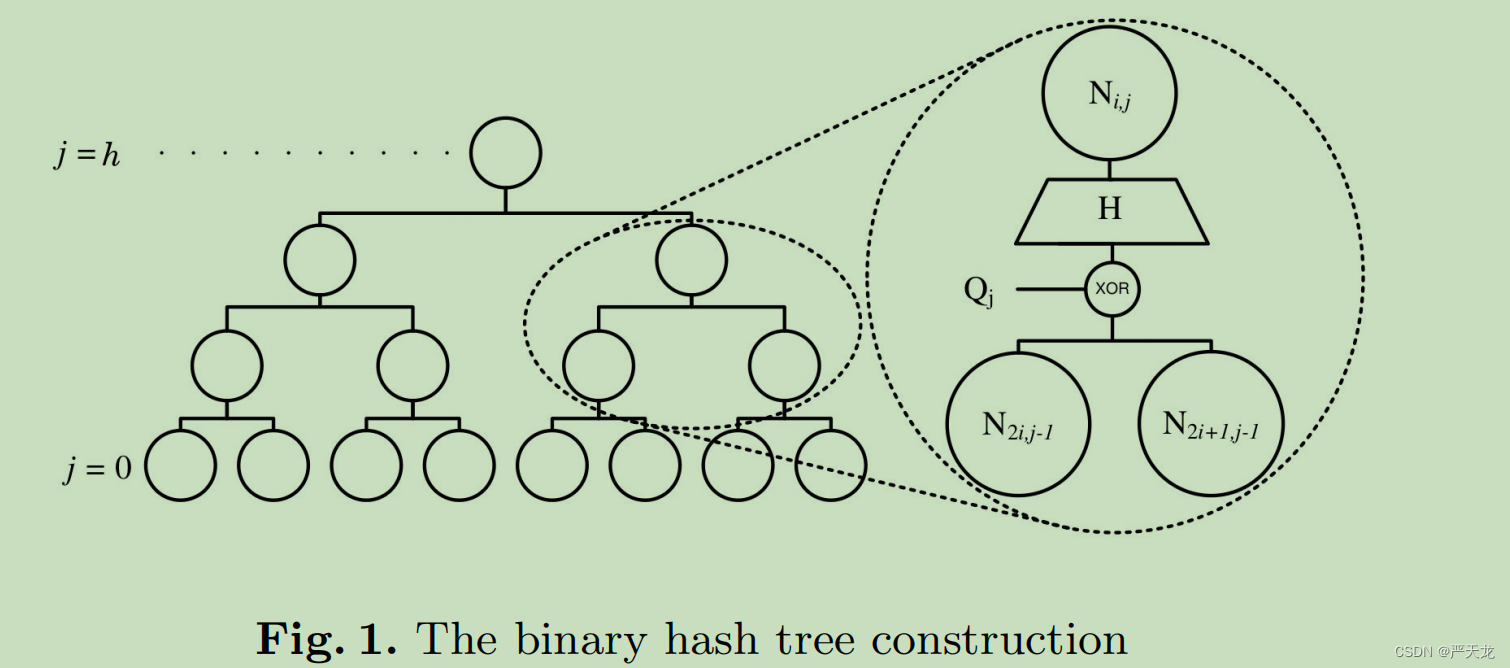
Q是随机掩码,我们之前提到过,比如说在两个字节点结合成一个父节点的时候,会加一个随机掩码。SPHINCS中的随机掩码有很多中,除了有这个作用以外(应用在超树中),还应用于WOTS,HORST中。
Q
Q
Q也是采样得到的,在不同的应用中,
Q
Q
Q的长度也不同。这里放一个原论文的图:
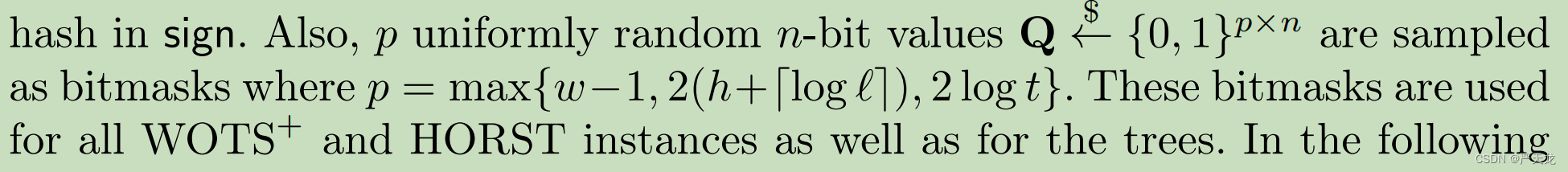
1.2.1.1 SK1的作用
-
生成地址 A = ( d − 1 ∣ ∣ 0 ∣ ∣ i ) , i ∈ [ 2 h / d − 1 ] A = (d-1||0||i),\ i \in [2^{h/d}-1] A=(d−1∣∣0∣∣i), i∈[2h/d−1], A A A指的是节点在子树中的地址(位置)。
首先,计算 2 h / d − 1 2^{h/d}-1 2h/d−1 的值,得到一个整数。然后,将 i i i 从 1 递增到 2 h / d − 1 2^{h/d}-1 2h/d−1,每次取一个整数值,并将其转换为二进制表示形式。
例如,假设 h = 6 h=6 h=6, d = 2 d=2 d=2,那么 2 h / d − 1 = 7 2^{h/d}-1 = 7 2h/d−1=7。(高为3层的树,一共有1+2+4=7个节点)在此示例中,我们需要计算 A A A 的所有可能取值,即 A A A 应包含从 1 到 7 的所有整数值,并将它们转换为二进制表示形式。
最终,我们可以得到 A A A 的计算结果如下:
A = { ( 0 ∣ ∣ 0 ∣ ∣ 1 ) , ( 0 ∣ ∣ 1 ∣ ∣ 0 ) , ( 0 ∣ ∣ 1 ∣ ∣ 1 ) , ( 1 ∣ ∣ 0 ∣ ∣ 0 ) , ( 1 ∣ ∣ 0 ∣ ∣ 1 ) , ( 1 ∣ ∣ 1 ∣ ∣ 0 ) , ( 1 ∣ ∣ 1 ∣ ∣ 1 ) } A = \{(0||0||1),\ (0||1||0),\ (0||1||1),\ (1||0||0),\ (1||0||1),\\\ (1||1||0),\ (1||1||1)\} A={(0∣∣0∣∣1), (0∣∣1∣∣0), (0∣∣1∣∣1), (1∣∣0∣∣0), (1∣∣0∣∣1), (1∣∣1∣∣0), (1∣∣1∣∣1)}
其中, ∣ ∣ || ∣∣ 是分隔符号,并且使用了二进制表示形式来表示 i i i 的值。请注意, i i i 的取值范围是 [ 2 h / d − 1 ] [2^{h/d}-1] [2h/d−1],即由 1 1 1 到 2 h / d − 1 2^{h/d}-1 2h/d−1 的整数值。 -
生成种子 S A ← F a ( A , S K 1 ) \mathcal S_A \leftarrow \mathcal F_a(A,SK_1) SA←Fa(A,SK1)
F \mathcal F F是PRF(Pseudorandom Random Function 伪随机函数) -
生成WOTS+的公钥 p k A ← W O T S . k g ( S A , Q W O T S + ) \mathrm {pk}_A \leftarrow \mathrm{WOTS.kg}(\mathcal S_A,Q_{\mathrm {WOTS+}}) pkA←WOTS.kg(SA,QWOTS+)
1.2.1.2 SK2的作用
- 与message
M
M
M进过一个函数
F
\mathcal F
F得到一个数
R
R
R,长度为
2
n
2n
2n,前n bit为
R
1
R_1
R1,后n bit为
R
2
R_2
R2
R ← F ( M , S K 2 ) , R = ( R 1 , R 2 ) ∈ { 0 , 1 } n × { 0 , 1 } n R \leftarrow \mathcal F(M,SK_2),\ \ R=(R_1,R_2) \in \{0,1\}^n \times \{0,1\}^n R←F(M,SK2), R=(R1,R2)∈{0,1}n×{0,1}n -
R
1
R_1
R1与message
M
M
M进过一个函数
H
\mathcal H
H得到摘要Digest
D
D
D
D ← H ( R 1 , M ) D \leftarrow \mathcal H(R_1,M) D←H(R1,M) -
R
2
R_2
R2用于确定用哪一棵HORTS树,在超树的最底层(超树的叶子节点),就是一颗颗的HORS Trees(HORSTs),取
R
2
R_2
R2的前
h
h
h bit作为HORST的 index索引
i
i
i(从左到右数,所以刚好是
2
h
2^h
2h颗HORSTs,h是超树的层数)
i ← C H O P ( R 2 , h ) i \leftarrow \mathrm{CHOP}(R_2,h) i←CHOP(R2,h)
1.2.2 公钥
这里说的公钥是整一个SPHINCS的公钥 P K 1 PK_1 PK1,也就是整个超树的根节点。
1.3 总结
SPHINCS的其余细节我就不再多说了,因为在SPHINCS+中,会对其做出一些改变,大家只需要理解其整体框架即可。
二、SPHINCS+
SPHINCS+也是Daniel J. Bernstein发布的,是在SPHINCS的基础上完善而成的。
Daniel J. Bernstein在2019年发布的论文《The SPHINCS+ Signature Framework》
SPHINCS+与SPHINCS的不同之处就是,SPHINCS+将HORST换成了FORS(Forest of Random Subsets),在总体框架上,没有其他的改变,还是使用超树结构。当然,在上有一些改动,使得整个算法更加完善。
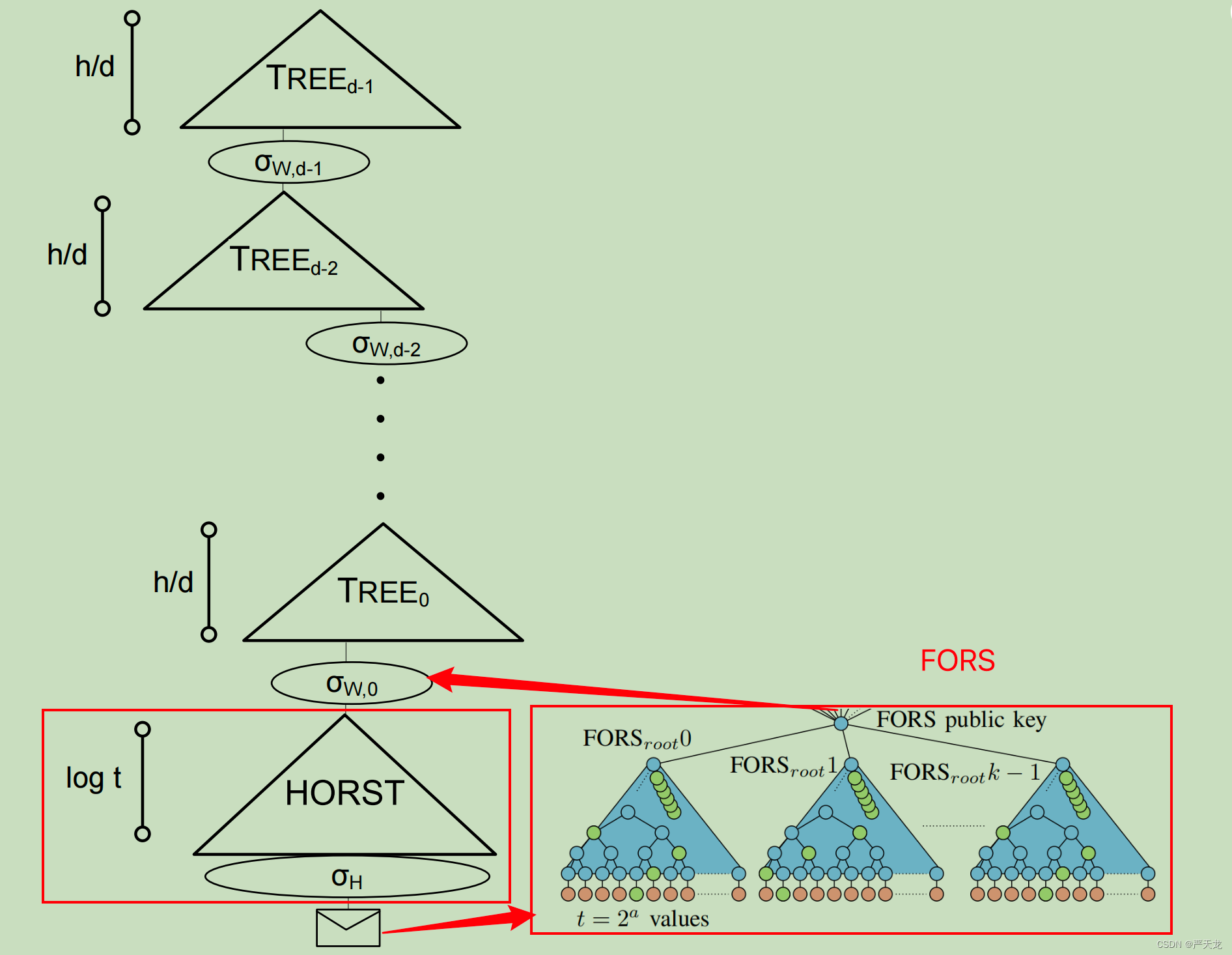
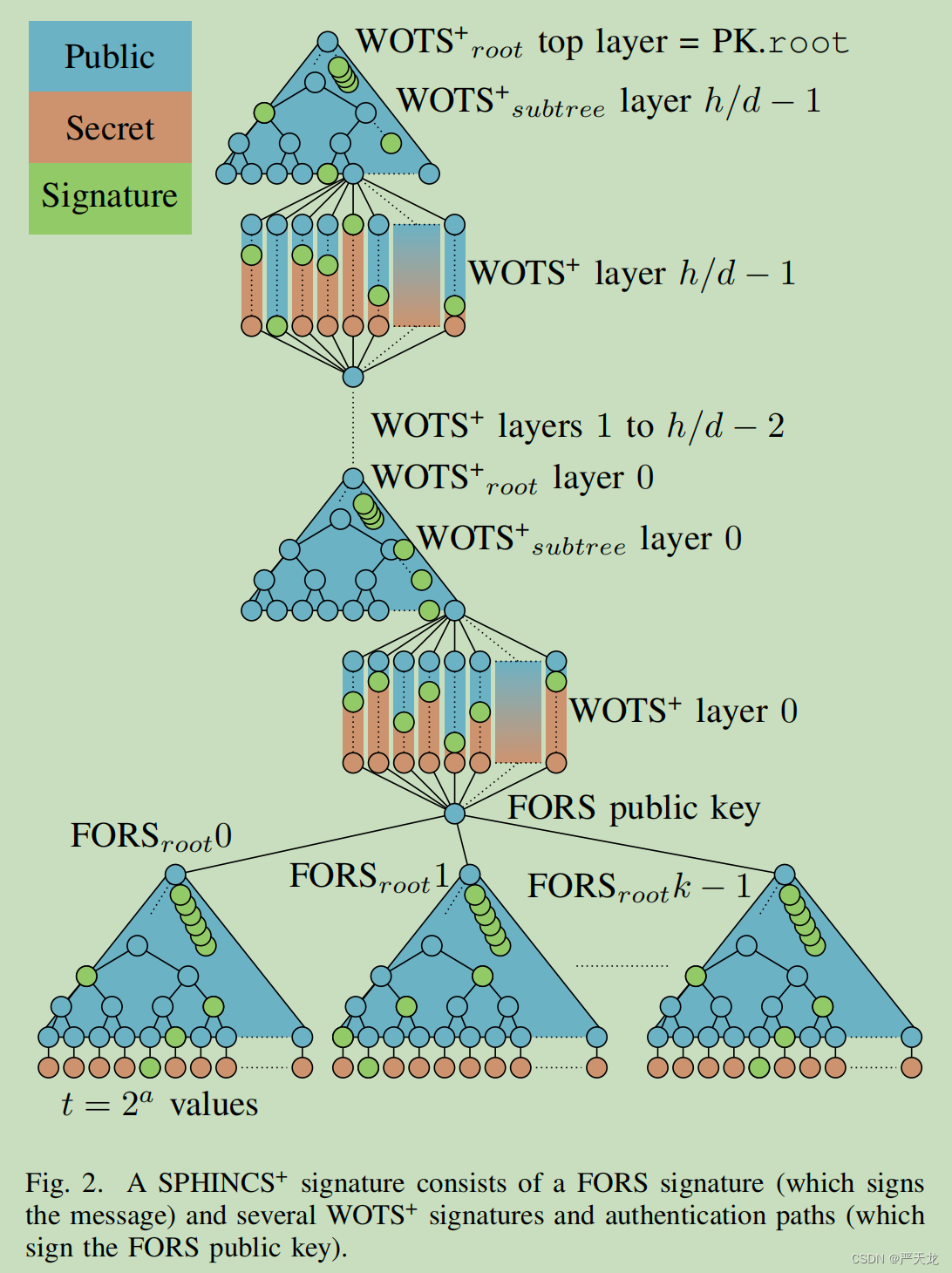
2.1 FORS
2.1.1 复习一下HORST
回顾一下之前的HORST,就是在HORS的基础上,将许多公钥用树结构 串起来。
首先是HORS,这里放一段第三集中的原文:
我们先确定参数,这里用 l = 80 , k = 20 , t = 256 l=80, k=20, t=256 l=80,k=20,t=256。 k k k和 t t t我们之前已经解释过了,就是全集有 t t t个元素,从中取出 k k k个元素作为子集。这里的 l l l是每个元素的长度,即每个元素长 l l l
bit
先确定message,原文没有强调message的长度,只要求message m m m在经过哈希函数 H a s h ( m ) = h Hash(m)=h Hash(m)=h之后的输出 h h h的长度不超过 k ∗ l o g 2 t = 20 ∗ l o g 2 256 = 20 ∗ 8 = 160 k*log_2t=20*log_2256=20*8=160 k∗log2t=20∗log2256=20∗8=160
bits。如果长度不足,可以在后面补0随机生成密钥对(私钥和公钥):在确定了参数之后,我们马上就可以生产私钥和公钥了。私钥就是随机生成整一个全集,包含了 256 256 256个元素,每个元素长 80 80 80
bit 。即有私钥: S K = ( k , s 1 , s 2 , … , s 256 ) SK=(k, s_1,s_2,\dots,s_{256}) SK=(k,s1,s2,…,s256)。然后让私钥经过一个“One Way Function”
f f f,就是一个单向函数,得到公钥 P K = ( k , v 1 , v 2 , … , v 256 ) PK=(k,v_1,v_2,\dots,v_{256}) PK=(k,v1,v2,…,v256)。这里产生公钥的方法和之前我们提到的所有的哈希签名方案是一样的。签名信息:让message m m m经过哈希函数 H a s h ( m ) = h Hash(m)=h Hash(m)=h之后的得到 h h h。将h分成20块 h 1 , h 2 , … , h 20 h_1,h_2,\dots,h_{20} h1,h2,…,h20,每一块为8
bits,可以表示0到255之间的数。 比如 h 1 = 148 , h 2 = 33 , … , h 20 = 106 h_1=148,h_2=33,\dots,h_{20}=106 h1=148,h2=33,…,h20=106
这里的十进制数,刚好对应上了私钥 S K SK SK中的1到256个 s s s元素,我们选出私钥中对应的元素作为签名。签名为:
σ = ( s 148 , s 33 , … , s 106 ) \sigma=(s_{148},s_{33},\dots,s_{106}) σ=(s148,s33,…,s106)
这就是从256个元素中选出20个元素当作子集,同时由于可能存在message长度不足的情况, h h h会在后面补0以满足160
bit,因此后面的 h h h就表示为0,没有对应的私钥 s 0 s_0 s0,导致可能最终只是选出了十几个元素。这时候就利用上了“最多为k(20)个元素的子集”这个改进点了。(仔细观察你会发现,虽然没有 s 0 s_0 s0,但是有 s 256 s_{256} s256,所以0对应的私钥可以是 s 256 s_{256} s256,加上这个私钥可以看作是在签名的后面补0的操作)验证:Receiver收到 m , σ = ( s 1 ′ , … , s k ′ ) , P K = ( k , v 1 , v 2 , … , v 256 ) m, \sigma=(s_1',\dots ,s_k'),PK=(k,v_1,v_2,\dots,v_{256}) m,σ=(s1′,…,sk′),PK=(k,v1,v2,…,v256) 。让message
m m m经过哈希函数 H a s h ( m ) = h Hash(m)=h Hash(m)=h之后的得到 h h h。将h分成20块 h 1 , h 2 , … , h 20 h_1,h_2,\dots,h_{20} h1,h2,…,h20,每一块为8
bits,可以表示0到255之间的数。比如 h 1 = 148 , h 2 = 33 , … , h 20 = 106 h_1=148,h_2=33,\dots,h_{20}=106 h1=148,h2=33,…,h20=106 将签名经过函数 f f f,
第一个元素得到 f ( s 1 ′ ) f(s_1') f(s1′),将 f ( s 1 ′ ) f(s_1') f(s1′)与公钥 P K PK PK中对应位置的元素 v 148 v_{148} v148进行对比,如果相等 f ( s 1 ′ ) = v 148 f(s_1')= v_{148} f(s1′)=v148。签名的第一个元素 s 1 ′ s_1' s1′验证为“真”。 将签名经过函数 f f f,
第二个元素得到 f ( s 2 ′ ) f(s_2') f(s2′),将 f ( s 2 ′ ) f(s_2') f(s2′)与公钥 P K PK PK中对应位置的元素 v 33 v_{33} v33进行对比,如果相等 f ( s 2 ′ ) = v 33 f(s_2')= v_{33} f(s2′)=v33。签名的第二个元素 s 2 ′ s_2' s2′验证为“真”。 后面的20个元素用同样的方法验证即可。
2.1.2 FORS的改变
在HORST中,不同块 h i h_i hi 之间的私钥和公钥是共用的,都是从一个公共的密钥池 S K SK SK中取密钥。而在FORS中,不同块 h i h_i hi 都有自己私自的密钥池 S K i SK_i SKi
举个例子,参数 k = 6 , a = 3 , t = 8 = 2 a k=6,a=3,t=8=2^a k=6,a=3,t=8=2a,即从8个元素中取出6个元素作为子集。
- 按照HORST的方法,随机生成私钥 S K = ( k , s 1 , s 2 , … , s 8 ) SK=(k, s_1,s_2,\dots,s_{8}) SK=(k,s1,s2,…,s8),让message m m m经过哈希函数 H a s h ( m ) = h Hash(m)=h Hash(m)=h之后的得到 h h h。将h分成6块: h 1 = 4 , h 2 = 2 , … , h 6 = 7 h_1=4,h_2=2,\dots,h_{6}=7 h1=4,h2=2,…,h6=7,最后得到签名 σ = ( s 4 , s 2 , … , s 7 ) \sigma=(s_{4},s_2,\dots,s_{7}) σ=(s4,s2,…,s7)
- FORS:因为要选6个元素作为子集,于是随机生成6个私钥池
S
K
i
=
(
k
,
s
1
i
,
s
2
i
,
…
,
s
8
i
)
,
i
∈
[
0
,
5
]
SK_i=(k, s_1^i,s_2^i,\dots,s_{8}^i),\ i \in[0,5]
SKi=(k,s1i,s2i,…,s8i), i∈[0,5],让message
m
m
m经过哈希函数
H
a
s
h
(
m
)
=
h
Hash(m)=h
Hash(m)=h之后的得到
h
h
h。将h分成6块:
h
1
=
4
,
h
2
=
2
,
…
,
h
6
=
7
h_1=4,h_2=2,\dots,h_{6}=7
h1=4,h2=2,…,h6=7,最后得到签名
σ
=
(
s
4
0
,
s
2
1
,
…
,
s
7
5
)
\sigma=(s_{4}^0,s_2^1,\dots,s_{7}^5)
σ=(s40,s21,…,s75)。如下图所示:
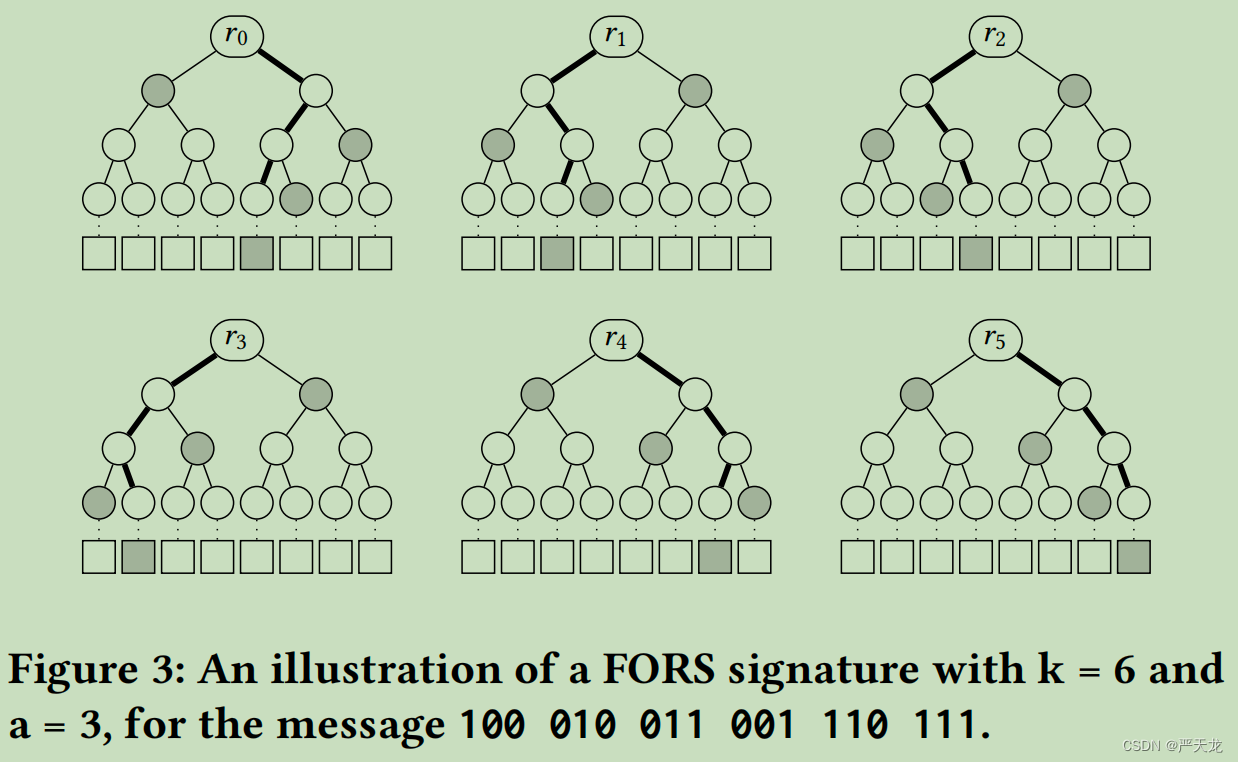
FORS的优点:
对比HORST,FORS能够更充分地利用密钥对,也就是同一个密钥对,能够签名更多的消息。
密钥对大小增大了 k k k倍,能够签名的数量从 2 t k π \frac{2^t}{\sqrt{k\pi}} kπ2t 增加到了 2 t ∗ k 2^t*k 2t∗k,也就是增加了 k π ∗ k \sqrt k\pi *k kπ∗k倍,所以变向减小了密钥对的大小。在同等的签名次数下,FORS使用的密钥对更小了。
三、总结
SPHINCS+的总体框架我们已经讲完了,就是在SPHINCS的基础上,将HORST变成FORS。
到目前为止,你已经完全了解SPHINCS+基本原理是怎么运作的了。
最后再放一下SPHINCS+的总体框架图
四、One More Thing
之后我还会写几篇文章,来讲一下SPHINCS+的各种细节,包括官方提交到GitHub上的源代码怎么在Windows和Mac上跑通(目前我已经在这两个平台上跑通了),以及我们一直提到的哈希函数到底具体是怎么运算的,等等关于SPHINCS+的一切。

















 2972
2972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









