






8月15日,国家信息安全漏洞库(CNNVD)发布关于微软多个安全漏洞的通告。
其中微软产品本身漏洞123个,影响到微软产品的其他厂商漏洞0个。

包括Microsoft Windows Point-to-Point Tunneling Protocol 安全漏洞(CNNVD-202208-2560、CVE-2022-30133)、Microsoft Windows Network File System 安全漏洞(CNNVD-202208-2542、CVE-2022-34715)等多个漏洞。
CNNVD对其危害等级进行了评价,其中超危漏洞2个,高危漏洞54个,中危漏洞67个,微软多个产品和系统版本均受到影响,成功利用这些漏洞的攻击者可以在目标系统上执行任意代码、获取用户数据,提升操作权限等。
具体影响范围可访问以下网址查询:
https://portal.msrc.microsoft.com/zh-cn/security-guidance
目前,微软已发布了对上述安全更新,共123个漏洞的补丁程序。
CNNVD对这些漏洞进行了收录,主要涵盖Microsoft Windows 和 Windows 组件、Microsoft .NET Framework、Microsoft Windows Hello、Microsoft Windows Defender、Microsoft Windows Storage Spaces Controller、Microsoft Excel等。
其中新增漏洞的补丁程序有121个:

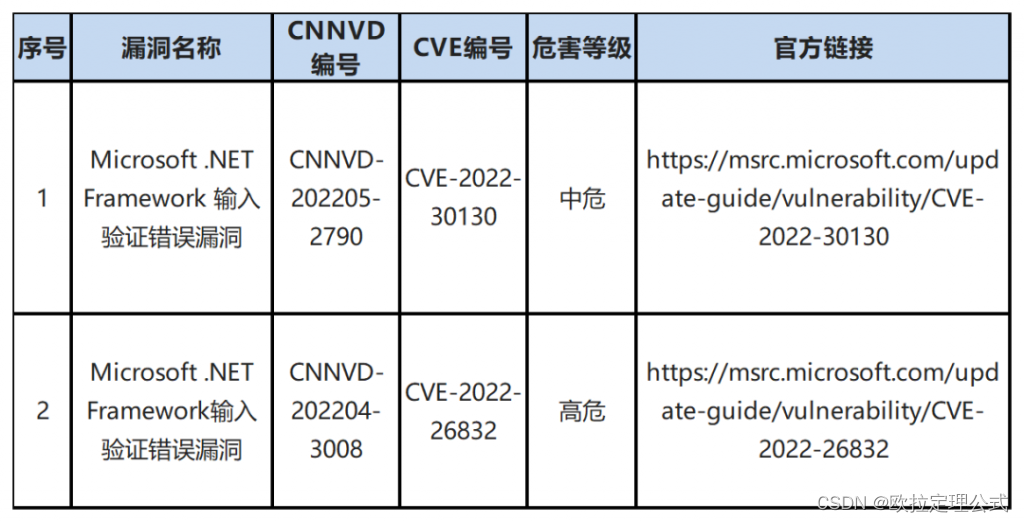
此次更新中还包含2个更新漏洞的补丁程序:
修复建议
目前,微软官方已经发布补丁修复了上述漏洞,建议用户及时确认漏洞影响,尽快采取修补措施。微软官方补丁下载地址:
https://msrc.microsoft.com/update-guide/en-us
资料来源:CNNVD















 5202
5202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









