







契机
最近一段时间一直在学爬虫,学完 urllib、requests 之后也做了几个爬虫小项目,可是当我想去爬瓜子二手车的网站还有其他几个网站的时候,即使在 headers 中设定了User-agent 的选项,用 requests 依然会出现问题:
import requests
url = 'https://www.guazi.com/jn/?ca_s=pz_baidu&ca_n=pcbiaoti&tk_p_mti=ad.pz_baidu.pcbiaoti.1.106453242419810304'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0'
}
response = requests.get(url,headers=headers)
print(response.text)
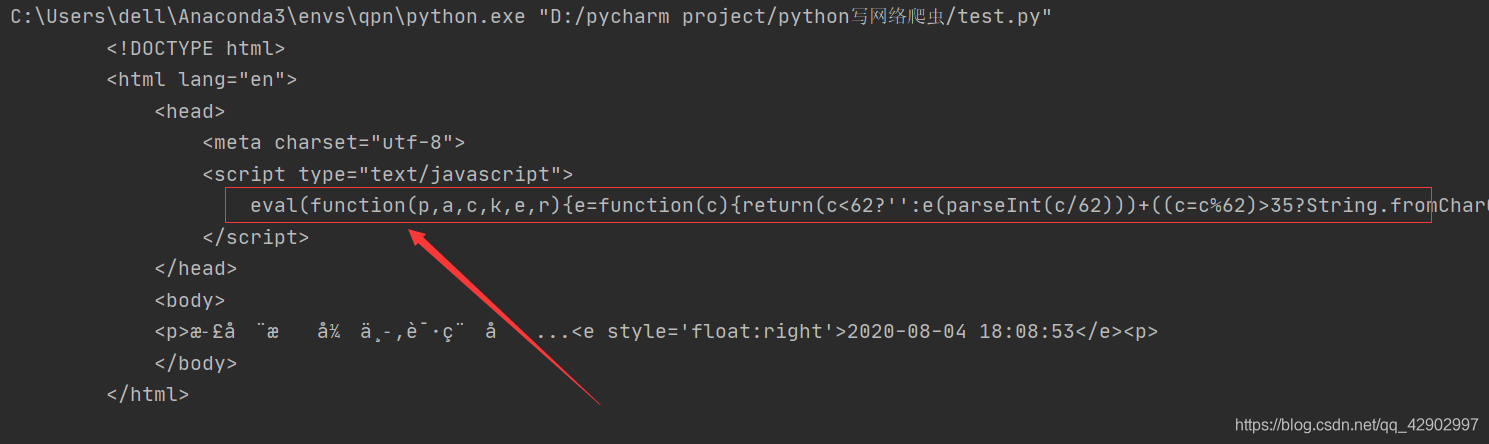
解决方法
使用 Selenium + chromedriver 方法来模拟浏览器发送请求并解析返回的网页源代码
from selenium import webdriver
from lxml import etree
driver_path = r'C:\Users\dell\Anaconda3\Scripts\chromedriver.exe' #chromedriver安装的位置
driver = webdriver.Chrome(driver_path) #使用谷歌浏览器,加载chromedriver驱动的位置
driver.get('https://www.guazi.com/rizhao/dazhong/') #请求和获取页面
page_source = driver.page_source #获得页面的源代码
print(page_source)
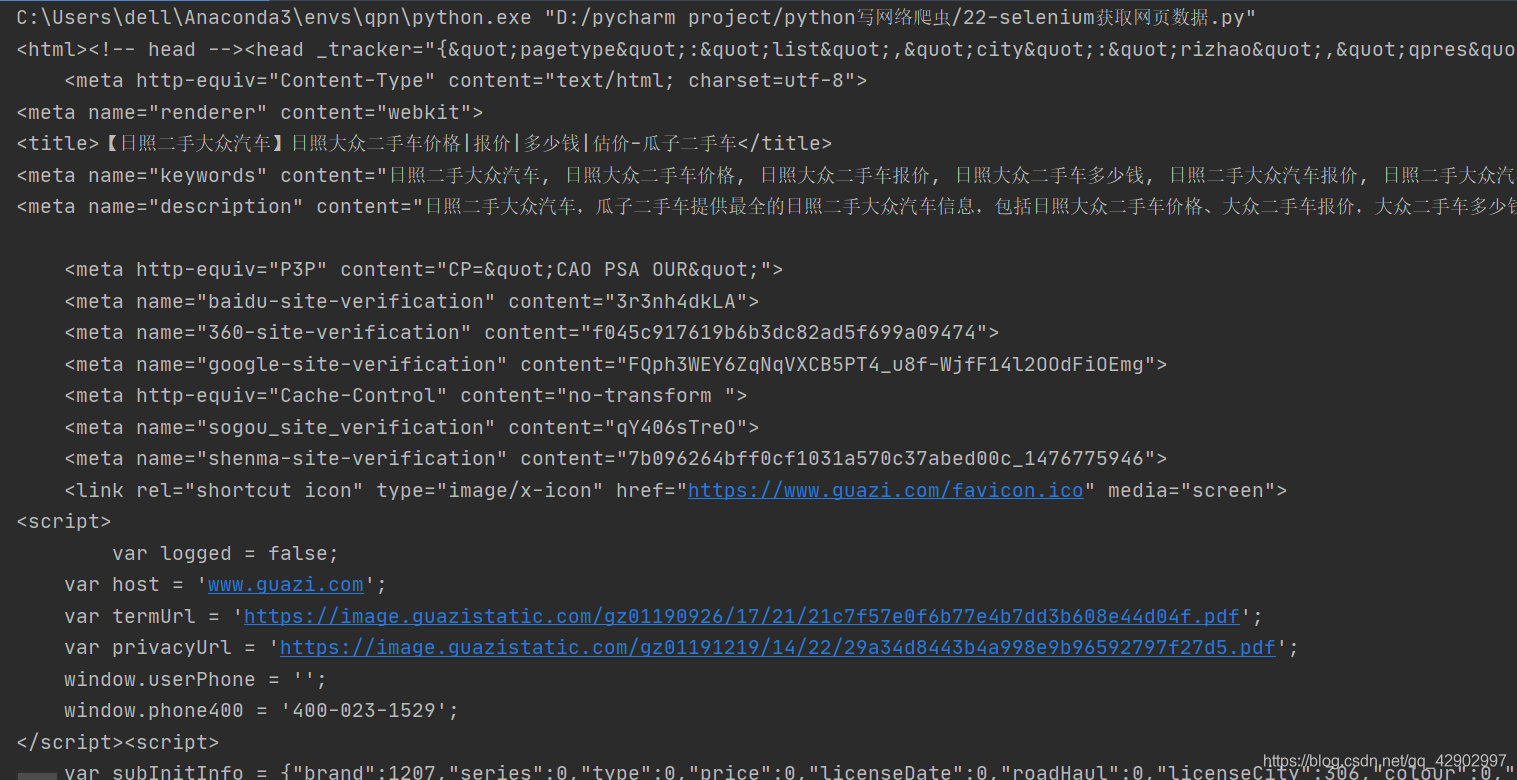
换种方法即可得到网页源代码~~
得到源代码之后如何提取信息就要看诸君喜好啦~~


















 2896
2896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











