











一、TensorFlow 详解
TensorFlow 是由 Google 开发的开源机器学习框架,广泛应用于深度学习、计算机视觉、自然语言处理等领域。它支持 CPU、GPU 和 TPU 运行,并提供了 Python、C++ 和 Java 等多种语言的 API。
1. TensorFlow 本地部署
要在本地安装并使用 TensorFlow,通常可以选择 CPU 版本 或 GPU 版本,下面介绍不同环境下的安装步骤。
1.1 安装 TensorFlow
方式 1:使用 pip 安装
这是最简单的方式,适用于 Python 3.8 及以上版本:
pip install tensorflow
如果需要安装特定版本,例如 2.12.0:
pip install tensorflow==2.12.0
方式 2:安装 GPU 版本
如果你的计算机有 NVIDIA GPU,建议安装 GPU 版本,以提升计算速度:
pip install tensorflow-gpu
要求:
-
CUDA(NVIDIA 的并行计算平台):需要正确安装 CUDA 11.2 或以上
-
cuDNN(NVIDIA 深度学习库):需要正确安装 cuDNN 8.1 或以上
-
NVIDIA 驱动程序:确保 GPU 兼容,并安装 NVIDIA Driver
安装后,可通过以下命令检查 TensorFlow 是否正确使用 GPU:
import tensorflow as tf
print(tf.config.list_physical_devices('GPU'))
如果输出包含 GPU,则说明安装成功。
方式 3:使用 Conda 安装
对于 Anaconda 用户,可以使用 Conda 安装:
conda create --name tf_env python=3.8
conda activate tf_env
conda install tensorflow
2. TensorFlow 基本使用
2.1 导入 TensorFlow
import tensorflow as tf
print(tf.__version__) # 查看 TensorFlow 版本
2.2 创建张量(Tensor)
张量是 TensorFlow 的核心数据结构,与 NumPy 的 ndarray 类似。
# 创建一个 2x2 矩阵
tensor = tf.constant([[1, 2], [3, 4]], dtype=tf.float32)
print(tensor)
2.3 变量(Variable)
var = tf.Variable([[1, 2], [3, 4]], dtype=tf.float32)
print(var)
2.4 使用 GPU
如果安装了 GPU,可以将计算移动到 GPU:
with tf.device('/GPU:0'):
tensor_gpu = tf.constant([[1.0, 2.0], [3.0, 4.0]])
print(tensor_gpu)
3. 构建神经网络
使用 tf.keras 构建一个简单的全连接神经网络(MLP)。
from tensorflow import keras
from tensorflow.keras import layers
# 创建一个简单的神经网络
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(10,)),
layers.Dense(32, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 查看模型结构
model.summary()
4. 训练和评估模型
使用 NumPy 生成一些随机数据进行训练:
import numpy as np
# 生成随机数据
X_train = np.random.rand(1000, 10)
y_train = np.random.randint(0, 2, size=(1000,))
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
# 评估模型
X_test = np.random.rand(200, 10)
y_test = np.random.randint(0, 2, size=(200,))
model.evaluate(X_test, y_test)
5. 使用训练好的模型进行预测
X_new = np.random.rand(5, 10)
predictions = model.predict(X_new)
print(predictions)
6. 保存和加载模型
6.1 保存模型
model.save("my_model.h5") # 保存为 HDF5 格式
6.2 加载模型
new_model = keras.models.load_model("my_model.h5")
二、TensorFlow 深度学习模型
TensorFlow 提供了强大的 tf.keras API,可以轻松实现卷积神经网络(CNN)、循环神经网络(RNN)和 Transformer 等模型。下面分别介绍如何实现它们。
1. 卷积神经网络(CNN)
CNN 主要用于计算机视觉任务,例如图像分类。
1.1 构建 CNN
使用 tf.keras 定义一个简单的 CNN 进行图像分类(以 MNIST 手写数字数据集为例)。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化
# 调整输入数据形状
x_train = x_train[..., tf.newaxis] # 变成 (60000, 28, 28, 1)
x_test = x_test[..., tf.newaxis]
# 构建 CNN 模型
model = keras.Sequential([
layers.Conv2D(32, kernel_size=(3,3), activation='relu', input_shape=(28,28,1)),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Conv2D(64, kernel_size=(3,3), activation='relu'),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax') # 10 类输出
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5, batch_size=64, validation_data=(x_test, y_test))
# 评估模型
model.evaluate(x_test, y_test)
2. 循环神经网络(RNN)
RNN 主要用于处理时间序列数据、文本数据(NLP)、语音信号等。
2.1 构建 RNN(LSTM)
使用 IMDB 电影评论数据集进行情感分类:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 加载 IMDB 数据集
max_words = 10000 # 仅使用前 10,000 个最常见的单词
maxlen = 200 # 句子最大长度
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=max_words)
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
# 构建 LSTM 模型
model = keras.Sequential([
layers.Embedding(max_words, 128, input_length=maxlen), # 词嵌入
layers.LSTM(64, return_sequences=True),
layers.LSTM(32),
layers.Dense(1, activation='sigmoid') # 二分类输出
])
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5, batch_size=64, validation_data=(x_test, y_test))
# 评估模型
model.evaluate(x_test, y_test)
3. Transformer
Transformer 主要用于自然语言处理(NLP),例如机器翻译、文本摘要、问答系统等。
3.1 构建 Transformer
在 TensorFlow 2.x 中,可以使用 tf.keras.layers.MultiHeadAttention 来实现 Transformer。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 定义 Transformer 编码器层
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential([
layers.Dense(ff_dim, activation="relu"),
layers.Dense(embed_dim),
])
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
# 创建 Transformer 模型
def build_transformer_model():
embed_dim = 32 # 词嵌入维度
num_heads = 2 # 注意力头数
ff_dim = 32 # 前馈神经网络维度
inputs = layers.Input(shape=(20, embed_dim))
transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
x = transformer_block(inputs)
x = layers.GlobalAveragePooling1D()(x)
x = layers.Dense(32, activation="relu")(x)
x = layers.Dropout(0.1)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
return keras.Model(inputs=inputs, outputs=outputs)
# 编译并训练 Transformer
model = build_transformer_model()
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
# 生成随机数据进行训练
import numpy as np
X_train = np.random.rand(1000, 20, 32)
y_train = np.random.randint(0, 2, size=(1000,))
model.fit(X_train, y_train, epochs=5, batch_size=32)
总结
-
CNN 主要用于图像任务,如分类、检测、分割等。
-
RNN(LSTM) 主要用于时间序列数据,如文本、语音、金融预测等。
-
Transformer 是当前最先进的 NLP 结构,应用于机器翻译、文本生成、语义理解等。
三、TensorFlow 数据处理(tf.data)
在深度学习中,数据预处理是至关重要的一环。TensorFlow 提供了 tf.data API,帮助高效地加载、转换和处理数据。它可以处理:
-
结构化数据(CSV、数据库)
-
非结构化数据(图像、文本)
-
大规模数据(TFRecord、流式数据)
1. 使用 tf.data.Dataset 处理数据
tf.data.Dataset 是 TensorFlow 的核心数据处理组件,可以从 NumPy 数组、CSV 文件、TFRecord 文件等创建数据集。
1.1 从 NumPy 数组创建数据集
如果你的数据是 NumPy 数组,可以直接使用 from_tensor_slices():
import tensorflow as tf
import numpy as np
# 生成随机数据
x = np.random.rand(10, 3) # 10 行 3 列
y = np.random.randint(0, 2, size=(10,)) # 10 个二分类标签
# 创建数据集
dataset = tf.data.Dataset.from_tensor_slices((x, y))
# 迭代数据集
for feature, label in dataset:
print("Feature:", feature.numpy(), "Label:", label.numpy())
2. 数据集操作
tf.data.Dataset 提供了多种操作,如 shuffle()、batch()、map() 等。
2.1 批处理(Batch)
深度学习训练时,通常不会一次性处理整个数据集,而是分批(batch)输入:
batch_size = 4
dataset = dataset.batch(batch_size)
for batch in dataset:
print(batch)
2.2 随机打乱(Shuffle)
打乱数据有助于防止模型过拟合:
dataset = dataset.shuffle(buffer_size=10).batch(batch_size)
buffer_size 决定了打乱的范围,值越大,随机性越强。
2.3 预取(Prefetch)
prefetch() 让数据加载和模型计算并行执行,提高训练速度:
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
3. 从 CSV 文件加载数据
如果数据存储在 CSV 文件中,可以使用 tf.data.experimental.make_csv_dataset():
dataset = tf.data.experimental.make_csv_dataset(
"data.csv", batch_size=4, label_name="target", num_epochs=1
)
4. 处理图片数据
4.1 从文件夹加载图片
TensorFlow 提供 image_dataset_from_directory() 方法,可直接从目录中加载图片:
dataset = tf.keras.preprocessing.image_dataset_from_directory(
"image_folder", batch_size=32, image_size=(224, 224)
)
4.2 数据增强
def augment(image, label):
image = tf.image.random_flip_left_right(image) # 水平翻转
image = tf.image.random_brightness(image, max_delta=0.2) # 亮度调整
return image, label
dataset = dataset.map(augment)
5. TFRecord 格式(高效存储大规模数据)
5.1 写入 TFRecord
with tf.io.TFRecordWriter("data.tfrecord") as writer:
for i in range(10):
example = tf.train.Example(features=tf.train.Features(
feature={"value": tf.train.Feature(float_list=tf.train.FloatList(value=[i]))}
))
writer.write(example.SerializeToString())
5.2 读取 TFRecord
raw_dataset = tf.data.TFRecordDataset("data.tfrecord")
# 解析 TFRecord
def _parse_function(proto):
feature_description = {"value": tf.io.FixedLenFeature([], tf.float32)}
return tf.io.parse_single_example(proto, feature_description)
parsed_dataset = raw_dataset.map(_parse_function)
for record in parsed_dataset:
print(record)
总结
-
tf.data.Dataset.from_tensor_slices()适用于小规模数据(NumPy、列表)。 -
make_csv_dataset()适用于结构化数据(CSV)。 -
image_dataset_from_directory()适用于图像数据(图片分类)。 -
TFRecord适用于大规模数据(高效存储、加载)。
四、Transformer 模型深入讲解
Transformer 是 Google 在 2017 年提出的一种深度学习架构,主要用于自然语言处理(NLP),但也被广泛应用于计算机视觉(ViT)、语音处理等领域。它摒弃了传统的 RNN 结构,而是使用 自注意力机制(Self-Attention) 和 前馈神经网络(Feedforward Network),实现了高效并行计算。
1. Transformer 的核心结构
Transformer 由 编码器(Encoder) 和 解码器(Decoder) 组成:
-
编码器:输入句子 → 词嵌入(Embedding)→ 自注意力(Self-Attention)→ 前馈神经网络(Feedforward Network)
-
解码器:解码目标句子 → 词嵌入 → 自注意力 → 编码器-解码器注意力 → 前馈网络
Transformer 主要由以下几个组件组成:
-
词嵌入(Embedding):将输入序列转换为向量表示。
-
位置编码(Positional Encoding):保留序列信息,使 Transformer 适用于 NLP 任务。
-
多头自注意力(Multi-Head Self-Attention):计算输入序列中不同词之间的关系。
-
前馈神经网络(Feedforward Network, FFN):用于特征变换。
-
层归一化(Layer Normalization)和残差连接(Residual Connection):加速训练并稳定梯度传播。
-
解码器额外的 Mask 机制:确保模型不会看到未来的单词。
2. Transformer 关键机制
2.1 词嵌入(Word Embedding)
Transformer 不能直接处理文本,需要将其转换为数字向量,通常使用 嵌入层(Embedding Layer):
import tensorflow as tf
from tensorflow.keras.layers import Embedding
embedding_layer = Embedding(input_dim=10000, output_dim=512) # 词表大小 10000,嵌入维度 512
如果 input_dim=10000,表示有 10,000 个不同的单词,每个单词被映射到一个 512 维向量。
2.2 位置编码(Positional Encoding)
Transformer 没有循环结构,因此需要位置编码(Positional Encoding)来表示词序信息:
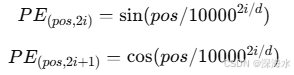
TensorFlow 代码:
import numpy as np
def positional_encoding(seq_length, d_model):
pos = np.arange(seq_length)[:, np.newaxis]
i = np.arange(d_model)[np.newaxis, :]
angles = pos / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
pos_encoding = np.zeros_like(angles)
pos_encoding[:, 0::2] = np.sin(angles[:, 0::2])
pos_encoding[:, 1::2] = np.cos(angles[:, 1::2])
return tf.constant(pos_encoding, dtype=tf.float32)
pe = positional_encoding(50, 512) # 50 个 token,每个 512 维
2.3 自注意力机制(Self-Attention)
核心思想:
-
计算每个单词对句子中其他单词的重要程度。
-
通过
Query(查询)、Key(键)和Value(值)计算注意力权重:
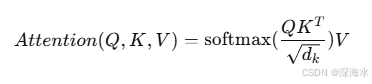
-
这里
Q、K、V都是从输入X变换得到的:
import tensorflow as tf
from tensorflow.keras.layers import Dense
def scaled_dot_product_attention(Q, K, V):
d_k = tf.cast(tf.shape(K)[-1], tf.float32)
scores = tf.matmul(Q, K, transpose_b=True) / tf.math.sqrt(d_k) # 计算 QK^T / sqrt(d_k)
attention_weights = tf.nn.softmax(scores, axis=-1) # 归一化
return tf.matmul(attention_weights, V) # 计算注意力加权值
2.4 多头注意力(Multi-Head Attention)
单头注意力可能无法捕获不同子空间的信息,Transformer 采用 多头注意力:
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, num_heads, d_model):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0 # 确保可以平均分割
self.depth = d_model // num_heads
self.WQ = Dense(d_model)
self.WK = Dense(d_model)
self.WV = Dense(d_model)
self.dense = Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3]) # 重新排列维度
def call(self, Q, K, V):
batch_size = tf.shape(Q)[0]
Q = self.split_heads(self.WQ(Q), batch_size)
K = self.split_heads(self.WK(K), batch_size)
V = self.split_heads(self.WV(V), batch_size)
attention = scaled_dot_product_attention(Q, K, V)
attention = tf.transpose(attention, perm=[0, 2, 1, 3]) # 还原维度
concat_attention = tf.reshape(attention, (batch_size, -1, self.d_model))
return self.dense(concat_attention)
3. Transformer 编码器
class TransformerEncoder(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, ff_dim, rate=0.1):
super(TransformerEncoder, self).__init__()
self.attention = MultiHeadAttention(num_heads, d_model)
self.ffn = tf.keras.Sequential([
Dense(ff_dim, activation="relu"),
Dense(d_model),
])
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.attention(inputs, inputs, inputs)
out1 = self.layernorm1(inputs + self.dropout1(attn_output, training=training))
ffn_output = self.ffn(out1)
return self.layernorm2(out1 + self.dropout2(ffn_output, training=training))
4. 构建完整 Transformer
inputs = tf.keras.Input(shape=(50, 512))
x = TransformerEncoder(512, 8, 2048)(inputs)
x = tf.keras.layers.GlobalAveragePooling1D()(x)
x = tf.keras.layers.Dense(10, activation="softmax")(x)
model = tf.keras.Model(inputs, x)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
总结
-
自注意力机制 计算句子内部的词关联。
-
多头注意力 让模型关注不同特征子空间。
-
Transformer 编码器 通过层归一化和前馈网络提高模型能力。
五、Transformer 在 NLP 任务中的应用
Transformer 在 NLP 任务中最主要的应用包括:
-
文本分类(Sentiment Analysis, Topic Classification)
-
机器翻译(Machine Translation,如英译法)
-
文本生成(Text Generation,如 ChatGPT、BERT)
-
问答系统(Question Answering,如 BERT-SQuAD)
-
命名实体识别(NER, Named Entity Recognition)
下面将详细讲解 Transformer 在 NLP 任务中的实现,包括 数据预处理、模型构建、训练及推理。
1. 数据预处理
在 NLP 任务中,数据通常是文本格式,需要经过 Tokenization(分词) 和 Embedding(词向量化)。
1.1 使用 Tokenizer 进行文本分词
Transformer 不能直接处理字符串,需要将其转换成 token(索引序列)。
使用 TensorFlow 内置 TextVectorization
import tensorflow as tf
from tensorflow.keras.layers import TextVectorization
# 假设有一些文本数据
texts = [
"TensorFlow is a great deep learning framework.",
"Transformer models are powerful for NLP tasks.",
"Attention is all you need."
]
# 创建分词器
max_tokens = 10000 # 词汇表大小
sequence_length = 10 # 句子最大长度
vectorizer = TextVectorization(max_tokens=max_tokens, output_mode="int", output_sequence_length=sequence_length)
# 适配数据
vectorizer.adapt(texts)
# 测试分词
sample_text = ["Transformer models are great"]
tokenized_text = vectorizer(sample_text)
print(tokenized_text.numpy()) # 转换为 token 序列
1.2 词嵌入(Word Embedding)
Transformer 需要词向量表示输入数据,通常使用预训练的嵌入,如 GloVe、Word2Vec 或 BERT。
embedding_dim = 512 # 嵌入维度
embedding_layer = tf.keras.layers.Embedding(input_dim=max_tokens, output_dim=embedding_dim)
如果使用预训练的嵌入(如 GloVe),可以加载权重:
embedding_matrix = ... # 预训练词向量
embedding_layer = tf.keras.layers.Embedding(input_dim=max_tokens, output_dim=embedding_dim, weights=[embedding_matrix], trainable=False)
2. 构建 Transformer 模型
Transformer 的关键组件:
-
自注意力(Self-Attention)
-
多头注意力(Multi-Head Attention)
-
前馈神经网络(Feedforward Network, FFN)
-
位置编码(Positional Encoding)
-
残差连接 + 层归一化
2.1 位置编码(Positional Encoding)
import numpy as np
def positional_encoding(seq_length, d_model):
pos = np.arange(seq_length)[:, np.newaxis]
i = np.arange(d_model)[np.newaxis, :]
angles = pos / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
pos_encoding = np.zeros_like(angles)
pos_encoding[:, 0::2] = np.sin(angles[:, 0::2])
pos_encoding[:, 1::2] = np.cos(angles[:, 1::2])
return tf.constant(pos_encoding, dtype=tf.float32)
2.2 自注意力机制(Self-Attention)
def scaled_dot_product_attention(Q, K, V):
d_k = tf.cast(tf.shape(K)[-1], tf.float32)
scores = tf.matmul(Q, K, transpose_b=True) / tf.math.sqrt(d_k)
attention_weights = tf.nn.softmax(scores, axis=-1)
return tf.matmul(attention_weights, V)
2.3 多头注意力(Multi-Head Attention)
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, num_heads, d_model):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0
self.depth = d_model // num_heads
self.WQ = tf.keras.layers.Dense(d_model)
self.WK = tf.keras.layers.Dense(d_model)
self.WV = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, Q, K, V):
batch_size = tf.shape(Q)[0]
Q = self.split_heads(self.WQ(Q), batch_size)
K = self.split_heads(self.WK(K), batch_size)
V = self.split_heads(self.WV(V), batch_size)
attention = scaled_dot_product_attention(Q, K, V)
attention = tf.transpose(attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(attention, (batch_size, -1, self.d_model))
return self.dense(concat_attention)
2.4 Transformer 编码器(Encoder)
class TransformerEncoder(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, ff_dim, rate=0.1):
super(TransformerEncoder, self).__init__()
self.attention = MultiHeadAttention(num_heads, d_model)
self.ffn = tf.keras.Sequential([
tf.keras.layers.Dense(ff_dim, activation="relu"),
tf.keras.layers.Dense(d_model),
])
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.attention(inputs, inputs, inputs)
out1 = self.layernorm1(inputs + self.dropout1(attn_output, training=training))
ffn_output = self.ffn(out1)
return self.layernorm2(out1 + self.dropout2(ffn_output, training=training))
3. 构建 Transformer 文本分类模型
inputs = tf.keras.Input(shape=(sequence_length,))
x = vectorizer(inputs) # Tokenization
x = embedding_layer(x) # 词嵌入
x = positional_encoding(sequence_length, embedding_dim) + x
x = TransformerEncoder(embedding_dim, 8, 2048)(x)
x = tf.keras.layers.GlobalAveragePooling1D()(x)
x = tf.keras.layers.Dense(10, activation="softmax")(x)
model = tf.keras.Model(inputs, x)
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
# 打印模型结构
model.summary()
4. 训练 Transformer NLP 模型
model.fit(train_texts, train_labels, validation_data=(val_texts, val_labels), epochs=5, batch_size=32)
总结
-
数据预处理:
-
使用
TextVectorization进行分词 -
词嵌入(Word Embedding)
-
-
Transformer 关键组件:
-
位置编码
-
自注意力
-
多头注意力
-
Transformer 编码器
-
-
构建 NLP 任务(如文本分类)
-
使用 Transformer 进行 NLP 任务的训练和推理
-
六、Transformer 在机器翻译中的应用
机器翻译(Machine Translation, MT)是 NLP 任务的重要分支,典型的任务是将 源语言(Source Language) 翻译成 目标语言(Target Language),如 英文 → 法文、中文 → 英文。Transformer 是当前最强大的机器翻译架构之一,Google 的 "Attention is All You Need" 论文提出了 Transformer 模型,使得神经机器翻译(NMT, Neural Machine Translation)取得突破性进展。
1. 机器翻译任务介绍
机器翻译通常是 Seq2Seq(序列到序列) 任务:
-
输入(源语言):
I love deep learning -
输出(目标语言):
J'adore l'apprentissage profond
1.1 机器翻译的核心
-
Encoder-Decoder 结构:编码器(Encoder)处理源语言,解码器(Decoder)生成目标语言。
-
自注意力机制(Self-Attention):编码输入序列内部的依赖关系。
-
交叉注意力(Cross-Attention):解码器关注编码器的输出。
Transformer 架构如下:
2. 数据预处理
机器翻译需要 双语数据集,如:
-
WMT(Workshop on Machine Translation):英法、英德等数据集
-
IWSLT(International Workshop on Spoken Language Translation)
-
Multi30k(用于图像字幕翻译)
2.1 加载英法数据集
使用 TensorFlow Datasets (tensorflow_datasets) 加载 ted_hrlr_translate:
import tensorflow_datasets as tfds
# 加载英-法数据集
dataset_name = "ted_hrlr_translate/pt_to_en"
dataset, info = tfds.load(dataset_name, with_info=True, as_supervised=True)
train_data, val_data = dataset['train'], dataset['validation']
2.2 分词(Tokenization)
机器翻译需要分词,可以使用 TensorFlow TextVectorization 或 SentencePiece(BPE 编码):
import tensorflow as tf
from tensorflow.keras.layers import TextVectorization
# 设定词汇表大小
vocab_size = 10000
sequence_length = 50
# 创建源语言(葡萄牙语)和目标语言(英语)的 Tokenizer
source_vectorizer = TextVectorization(max_tokens=vocab_size, output_mode="int", output_sequence_length=sequence_length)
target_vectorizer = TextVectorization(max_tokens=vocab_size, output_mode="int", output_sequence_length=sequence_length)
# 适配训练数据
source_texts = [src.numpy().decode('utf-8') for src, tgt in train_data]
target_texts = [tgt.numpy().decode('utf-8') for src, tgt in train_data]
source_vectorizer.adapt(source_texts)
target_vectorizer.adapt(target_texts)
3. Transformer 机器翻译模型
Transformer 采用 Encoder-Decoder 结构:
-
Encoder:将源语言转换为上下文向量
-
Decoder:
-
使用 Masked Self-Attention 防止看到未来词
-
交叉注意力 (Cross-Attention) 连接编码器和解码器
-
逐步生成目标语言
-
3.1 位置编码(Positional Encoding)
import numpy as np
def positional_encoding(seq_length, d_model):
pos = np.arange(seq_length)[:, np.newaxis]
i = np.arange(d_model)[np.newaxis, :]
angles = pos / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
pos_encoding = np.zeros_like(angles)
pos_encoding[:, 0::2] = np.sin(angles[:, 0::2])
pos_encoding[:, 1::2] = np.cos(angles[:, 1::2])
return tf.constant(pos_encoding, dtype=tf.float32)
3.2 自注意力(Self-Attention)
def scaled_dot_product_attention(Q, K, V, mask=None):
d_k = tf.cast(tf.shape(K)[-1], tf.float32)
scores = tf.matmul(Q, K, transpose_b=True) / tf.math.sqrt(d_k)
if mask is not None:
scores += (mask * -1e9) # 用 -inf 屏蔽
attention_weights = tf.nn.softmax(scores, axis=-1)
return tf.matmul(attention_weights, V)
3.3 多头注意力(Multi-Head Attention)
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, num_heads, d_model):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.depth = d_model // num_heads
self.WQ = tf.keras.layers.Dense(d_model)
self.WK = tf.keras.layers.Dense(d_model)
self.WV = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, Q, K, V, mask=None):
batch_size = tf.shape(Q)[0]
Q = self.split_heads(self.WQ(Q), batch_size)
K = self.split_heads(self.WK(K), batch_size)
V = self.split_heads(self.WV(V), batch_size)
attention = scaled_dot_product_attention(Q, K, V, mask)
attention = tf.transpose(attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(attention, (batch_size, -1, self.d_model))
return self.dense(concat_attention)
3.4 Transformer 编码器(Encoder)
class TransformerEncoder(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, ff_dim, rate=0.1):
super(TransformerEncoder, self).__init__()
self.attention = MultiHeadAttention(num_heads, d_model)
self.ffn = tf.keras.Sequential([
tf.keras.layers.Dense(ff_dim, activation="relu"),
tf.keras.layers.Dense(d_model),
])
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.attention(inputs, inputs, inputs)
out1 = self.layernorm1(inputs + self.dropout1(attn_output, training=training))
ffn_output = self.ffn(out1)
return self.layernorm2(out1 + self.dropout2(ffn_output, training=training))
4. 训练 Transformer 机器翻译模型
inputs = tf.keras.Input(shape=(sequence_length,))
x = source_vectorizer(inputs) # 源语言 Tokenization
x = embedding_layer(x) # 词嵌入
x = positional_encoding(sequence_length, embedding_dim) + x
x = TransformerEncoder(embedding_dim, 8, 2048)(x)
x = tf.keras.layers.GlobalAveragePooling1D()(x)
x = tf.keras.layers.Dense(vocab_size, activation="softmax")(x)
model = tf.keras.Model(inputs, x)
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
model.fit(train_data, epochs=10, validation_data=val_data)
总结
-
数据预处理(加载数据、分词)
-
Transformer Encoder-Decoder 结构
-
训练机器翻译模型
七、Transformer 机器翻译模型的推理(Inference)
训练好的 Transformer 模型可以用于翻译新句子。推理的核心挑战在于:
-
输入处理:将原始文本转换为 token 序列。
-
逐步解码:使用 Teacher Forcing 训练的模型,在推理时需要 自回归(Autoregressive) 生成翻译。
-
翻译策略:
-
贪心解码(Greedy Decoding):每次选择最高概率的 token。
-
束搜索(Beam Search):选择多个候选翻译,提高质量。
-
温度采样(Temperature Sampling):增加翻译的随机性。
-
1. 预处理推理输入
在推理时,我们需要对输入句子进行 分词(Tokenization) 并转换为 ID。
def preprocess_input(sentence):
sentence = tf.expand_dims(source_vectorizer(sentence), axis=0) # 添加批次维度
return sentence
2. 逐步解码(Autoregressive Decoding)
Transformer 采用 自回归解码,即:
-
给定源句子,初始化目标句子为
[SOS](起始符号) -
逐步预测下一个 token,直到
[EOS](结束符号) -
将新 token 追加到目标句子
-
重复上述过程,直到达到最大长度或遇到
[EOS]
def greedy_decode(input_sentence, max_length=50):
input_tensor = preprocess_input(input_sentence) # 处理输入
decoded_sentence = "[SOS]" # 目标序列起始
for _ in range(max_length):
target_tensor = target_vectorizer([decoded_sentence]) # 转换目标句子
predictions = model([input_tensor, target_tensor], training=False) # 预测
next_token = tf.argmax(predictions[:, -1, :], axis=-1).numpy()[0] # 选取最大概率单词
next_word = target_vectorizer.get_vocabulary()[next_token]
if next_word == "[EOS]":
break
decoded_sentence += " " + next_word
return decoded_sentence.replace("[SOS] ", "")
3. 束搜索(Beam Search)
相比于贪心解码,束搜索(Beam Search) 维护多个翻译路径,选择最优翻译:
import heapq
def beam_search_decode(input_sentence, beam_width=3, max_length=50):
input_tensor = preprocess_input(input_sentence)
# 初始化候选序列
candidates = [(0, "[SOS]")] # (累积概率, 句子)
for _ in range(max_length):
new_candidates = []
for score, seq in candidates:
target_tensor = target_vectorizer([seq])
predictions = model([input_tensor, target_tensor], training=False)
# 获取 top-k 最高概率的单词
top_k = tf.math.top_k(predictions[:, -1, :], k=beam_width)
for i in range(beam_width):
next_token = top_k.indices.numpy()[0, i]
next_word = target_vectorizer.get_vocabulary()[next_token]
new_candidates.append((score + top_k.values.numpy()[0, i], seq + " " + next_word))
# 选择前 beam_width 个最优路径
candidates = heapq.nlargest(beam_width, new_candidates, key=lambda x: x[0])
# 如果最优路径以 [EOS] 结尾,则终止
if any(seq.endswith(" [EOS]") for _, seq in candidates):
break
# 返回最优翻译
return candidates[0][1].replace("[SOS] ", "").replace(" [EOS]", "")
4. 运行推理
source_sentence = "O aprendizado profundo é incrível."
print("贪心解码:", greedy_decode(source_sentence))
print("束搜索解码:", beam_search_decode(source_sentence, beam_width=5))
总结
✅ 贪心解码:每步选择最高概率的单词,速度快但容易陷入局部最优。
✅ 束搜索解码:维护多个候选句子,提高翻译质量。
✅ 批量推理:可以使用 tf.data.Dataset.batch() 进行并行推理,提高效率。
八、高级推理优化方法
在 Transformer 机器翻译的推理过程中,除了 贪心解码 和 束搜索,还可以使用更高级的优化方法,如:
-
Top-k 采样:随机选择前 k 个最高概率的单词,增加多样性。
-
Top-p(核采样):动态选择累积概率达到 p 的单词子集,提高流畅度。
-
Alpha Length 归一化:避免翻译句子过短的问题,提高 BLEU 评分。
1. Top-k 采样
Top-k 采样通过限制候选词汇的数量,使得模型在较高概率单词中随机选择,提高翻译的多样性。
实现步骤
-
获取模型预测的概率分布
-
取前 k 个最高概率的单词
-
按照归一化概率进行随机采样
-
不断扩展序列,直到遇到
[EOS]
import numpy as np
def top_k_sampling(input_sentence, k=5, max_length=50):
input_tensor = preprocess_input(input_sentence)
decoded_sentence = "[SOS]"
for _ in range(max_length):
target_tensor = target_vectorizer([decoded_sentence])
predictions = model([input_tensor, target_tensor], training=False)
# 取出最后一个时间步的预测分布
logits = predictions[:, -1, :].numpy()
# 选取 top-k 最高概率的 token
top_k_indices = np.argsort(logits[0])[-k:]
top_k_probs = np.exp(logits[0][top_k_indices]) / np.sum(np.exp(logits[0][top_k_indices]))
# 按照概率进行随机采样
next_token = np.random.choice(top_k_indices, p=top_k_probs)
next_word = target_vectorizer.get_vocabulary()[next_token]
if next_word == "[EOS]":
break
decoded_sentence += " " + next_word
return decoded_sentence.replace("[SOS] ", "")
2. Top-p(核采样)
Top-p 采样(Nucleus Sampling)比 Top-k 更进一步,它不是选取固定数量的高概率单词,而是:
-
累积概率 > p 的单词子集
-
在该子集中随机选择下一个 token
-
可以动态调整候选单词的数量
def top_p_sampling(input_sentence, p=0.9, max_length=50):
input_tensor = preprocess_input(input_sentence)
decoded_sentence = "[SOS]"
for _ in range(max_length):
target_tensor = target_vectorizer([decoded_sentence])
predictions = model([input_tensor, target_tensor], training=False)
# 获取概率分布
logits = predictions[:, -1, :].numpy()
sorted_indices = np.argsort(logits[0])[::-1]
sorted_probs = np.exp(logits[0][sorted_indices]) / np.sum(np.exp(logits[0][sorted_indices]))
# 累积概率超过 p 的单词子集
cumulative_probs = np.cumsum(sorted_probs)
top_p_indices = sorted_indices[cumulative_probs <= p]
if len(top_p_indices) == 0:
top_p_indices = sorted_indices[:1] # 确保至少有一个候选词
# 按概率进行随机采样
next_token = np.random.choice(top_p_indices)
next_word = target_vectorizer.get_vocabulary()[next_token]
if next_word == "[EOS]":
break
decoded_sentence += " " + next_word
return decoded_sentence.replace("[SOS] ", "")
3. Alpha Length 归一化
在束搜索(Beam Search)中,长句子的累积概率通常会变小,从而导致 模型更倾向于生成短句。
Alpha Length 归一化 通过对累积得分进行归一化,使得长句子不会被过度惩罚:
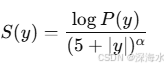
其中:
-
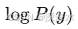 是序列的总概率
是序列的总概率 -
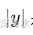 是翻译句子的长度
是翻译句子的长度 -
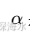 是长度惩罚系数(一般为 0.6)
是长度惩罚系数(一般为 0.6)
束搜索 + Alpha Length 归一化
def length_normalized_beam_search(input_sentence, beam_width=5, alpha=0.6, max_length=50):
input_tensor = preprocess_input(input_sentence)
candidates = [(0, "[SOS]")] # (累积概率, 句子)
for _ in range(max_length):
new_candidates = []
for score, seq in candidates:
target_tensor = target_vectorizer([seq])
predictions = model([input_tensor, target_tensor], training=False)
# 获取 top-k 最高概率的单词
top_k = tf.math.top_k(predictions[:, -1, :], k=beam_width)
for i in range(beam_width):
next_token = top_k.indices.numpy()[0, i]
next_word = target_vectorizer.get_vocabulary()[next_token]
new_seq = seq + " " + next_word
new_score = (score + np.log(top_k.values.numpy()[0, i])) / ((5 + len(new_seq.split())) ** alpha)
new_candidates.append((new_score, new_seq))
# 选择前 beam_width 个最优路径
candidates = heapq.nlargest(beam_width, new_candidates, key=lambda x: x[0])
# 如果最优路径以 [EOS] 结尾,则终止
if any(seq.endswith(" [EOS]") for _, seq in candidates):
break
return candidates[0][1].replace("[SOS] ", "").replace(" [EOS]", "")
4. 运行推理
source_sentence = "O aprendizado profundo é incrível."
print("Top-k 采样:", top_k_sampling(source_sentence, k=5))
print("Top-p 采样:", top_p_sampling(source_sentence, p=0.9))
print("Alpha 长度归一化束搜索:", length_normalized_beam_search(source_sentence, beam_width=5, alpha=0.6))
总结
✅ Top-k 采样:固定选择前 k 个高概率单词,增加翻译的多样性。
✅ Top-p(核采样):动态调整候选单词的数量,提高翻译的流畅度。
✅ Alpha Length 归一化:在束搜索中平衡短句和长句的得分,提高翻译质量。
这些方法在实际应用中可以 结合使用,例如:
-
Top-k + Temperature(控制随机性)
-
Top-p + Beam Search(更高质量翻译)
-
Beam Search + Alpha Normalization(优化 BLEU 评分)
九、Transformer 机器翻译的模型压缩:蒸馏 & 量化
在实际应用中,Transformer 模型通常 参数量大、计算开销高,导致推理速度慢,尤其是在移动设备或边缘计算场景下。
模型压缩技术可以减少计算成本,提高推理速度,同时尽可能保持翻译质量。
1. 模型蒸馏(Knowledge Distillation)
知识蒸馏(KD) 是一种训练小模型(Student)模仿大模型(Teacher)的技术,通过让小模型学习大模型的“知识”,可以 大幅减少模型大小,而翻译质量损失较小。
(1) 蒸馏训练思路
-
先训练一个 大模型(Teacher)
-
用 Teacher 预测软标签(Soft Labels) 作为监督信号
-
训练一个 小模型(Student) 来模仿大模型
软标签(Soft Labels):不像普通的 one-hot 标签,软标签是概率分布,如:
传统 one-hot:
[0, 0, 1, 0, 0]软标签(更丰富的知识):
[0.1, 0.3, 0.5, 0.05, 0.05]
(2) 知识蒸馏的实现
import tensorflow as tf
import tensorflow.keras.backend as K
# 定义蒸馏损失函数
def distillation_loss(y_true, y_pred, teacher_pred, temperature=5.0):
# 计算 Soft Labels
teacher_softmax = tf.nn.softmax(teacher_pred / temperature)
student_softmax = tf.nn.softmax(y_pred / temperature)
# 使用 KL 散度(Kullback-Leibler Divergence)作为损失
loss = K.sum(teacher_softmax * K.log(teacher_softmax / student_softmax))
return loss
# 训练小模型(Student)
def train_student(student_model, teacher_model, dataset, epochs=10, temperature=5.0, alpha=0.5):
optimizer = tf.keras.optimizers.Adam()
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
for epoch in range(epochs):
for x, y in dataset:
with tf.GradientTape() as tape:
teacher_pred = teacher_model(x, training=False)
student_pred = student_model(x, training=True)
# 计算普通交叉熵损失(Ground Truth)
ce_loss = loss_fn(y, student_pred)
# 计算蒸馏损失
kd_loss = distillation_loss(y, student_pred, teacher_pred, temperature)
# 综合两种损失
loss = alpha * ce_loss + (1 - alpha) * kd_loss
grads = tape.gradient(loss, student_model.trainable_variables)
optimizer.apply_gradients(zip(grads, student_model.trainable_variables))
print(f"Epoch {epoch+1}: Loss = {loss.numpy()}")
2. 量化(Quantization)
量化(Quantization) 通过 降低数值精度(例如从 float32 变成 int8),减少存储空间和计算开销。
(1) 动态范围量化(Post-Training Quantization, PTQ)
适用于 已经训练好的模型,对部分权重进行 float32 → int8 转换:
import tensorflow.lite as tflite
# 加载训练好的模型
model = tf.keras.models.load_model("transformer_model.h5")
# 转换为 TFLite 格式,并量化
converter = tflite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tflite.Optimize.DEFAULT]
tflite_model = converter.convert()
# 保存量化后的模型
with open("quantized_transformer.tflite", "wb") as f:
f.write(tflite_model)
✅ 优势:模型体积变小,推理速度更快。
❌ 缺点:可能影响翻译质量(因为精度降低)。
(2) 训练时量化(Quantization-Aware Training, QAT)
QAT 在训练时就考虑量化的影响,避免 PTQ 可能带来的质量损失:
import tensorflow_model_optimization as tfmot
# 给 Transformer 添加量化层
quantized_model = tfmot.quantization.keras.quantize_model(model)
# 编译量化模型
quantized_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
# 重新训练,使其适应量化
quantized_model.fit(train_dataset, epochs=5)
✅ 优势:量化后的翻译质量更接近原模型。
❌ 缺点:需要重新训练,耗时较长。
3. 低秩分解(Low-Rank Decomposition)
Transformer 的计算主要在 注意力层(Self-Attention) 和 前馈层(FFN),我们可以用 低秩近似(SVD, Tucker 分解) 降低计算复杂度。
(1) 使用 SVD 进行矩阵分解
import numpy as np
from scipy.linalg import svd
# 假设权重矩阵 W 的形状为 (d_model, d_model)
W = np.random.rand(512, 512)
# 进行 SVD 分解
U, S, Vt = svd(W)
# 只保留前 r 个奇异值
r = 64
W_approx = U[:, :r] @ np.diag(S[:r]) @ Vt[:r, :]
print("原始大小:", W.nbytes, "字节")
print("压缩后大小:", W_approx.nbytes, "字节")
✅ 优势:减少计算量,提高推理速度。
❌ 缺点:可能会降低模型的翻译质量,需要 finetune 调优。
4. 综合优化方案
最佳实践通常是 结合多种方法:
-
模型蒸馏(KD) + 量化(QAT/PTQ)
-
低秩分解(SVD) + 蒸馏
-
量化 Transformer + 蒸馏 + 精调
5. 量化 & 蒸馏后模型的推理
# 加载量化后的 TFLite 模型
interpreter = tflite.Interpreter(model_path="quantized_transformer.tflite")
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# 运行推理
def tflite_infer(input_sentence):
input_data = preprocess_input(input_sentence)
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
return decode_output(output_data)
print(tflite_infer("O aprendizado profundo é incrível."))
总结
✅ 模型蒸馏(KD):用小模型学习大模型知识,减少参数量。
✅ 量化(Quantization):降低精度(float32 → int8),提高推理速度。
✅ 低秩分解(SVD):减少计算量,加速注意力机制计算。
✅ 综合优化:蒸馏 + 量化 + 精调,提高推理速度,同时保持翻译质量。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











