









什么是B树?
对于数据库来说,我们要求查询有较高的效率。实际应用中,数据库往往采用B树(B-tree)格式储存数据。
B-Tree称为平衡多路搜索树,基于二叉搜索树,采用多叉树,再使用平衡二叉树的思想
了解B树之前,要了解什么是二分搜索树
二分搜索树的内容可以参考另一篇博文:
http://t.csdn.cn/kc9aD
二分搜索树的查找有以下特点:
在n个节点中找到目标值,一般只需要log(n)次比较
对于数据库来说,每进入一层,就要从硬盘读取一次数据,因为硬盘的读取时间远远大于数据处理时间,数据库读取硬盘的次数越少越好。
B树是对二叉查找树的改进。它的设计思想是,将相关数据尽量集中在一起,以便一次读取多个数据,减少硬盘操作次数。
B树(B-树)
B-树有如下特点:
1.有一个根节点,根节点只有两个孩子,根节点的值为一个记录
2.所有的叶子结点在同一层
3.每个结点的值为数据库里的键(key),线为指针,叶子结点的指针为null
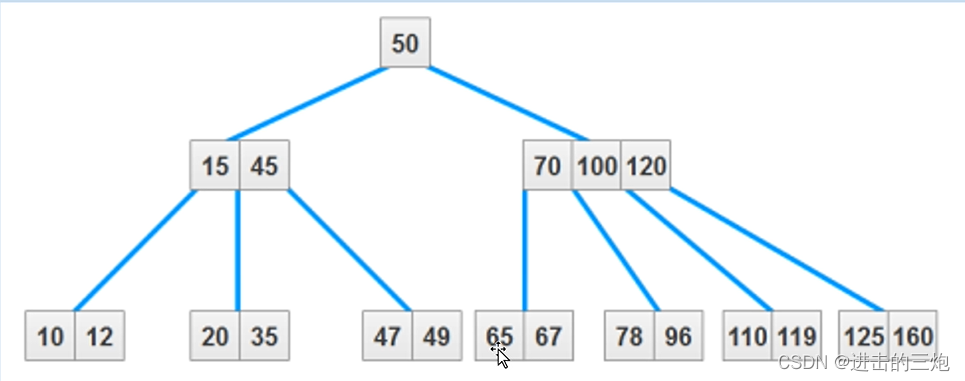
B+Tree非叶子节点指针数量与它的key的数量相同。
(2)B+Tree非叶子节点只存储key,不存储data,叶子节点不存储指针。
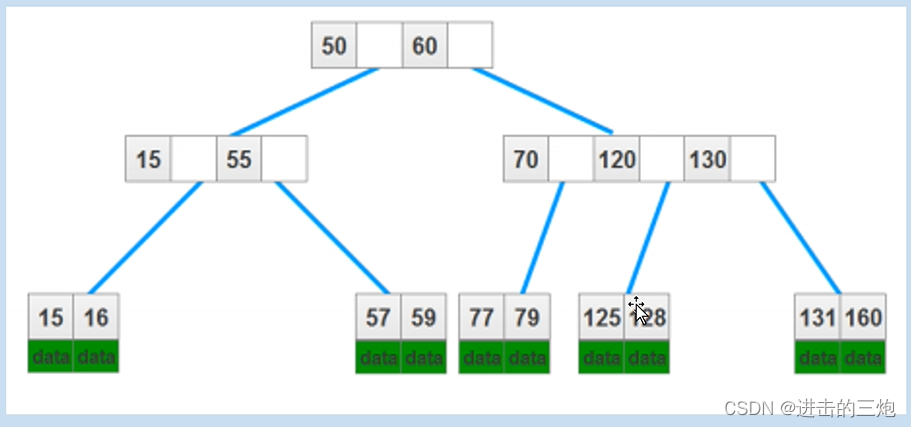
B+Tree B-Tree的查询区别
B-Tree:
B-树需要单行查询到3,再中序遍历到11
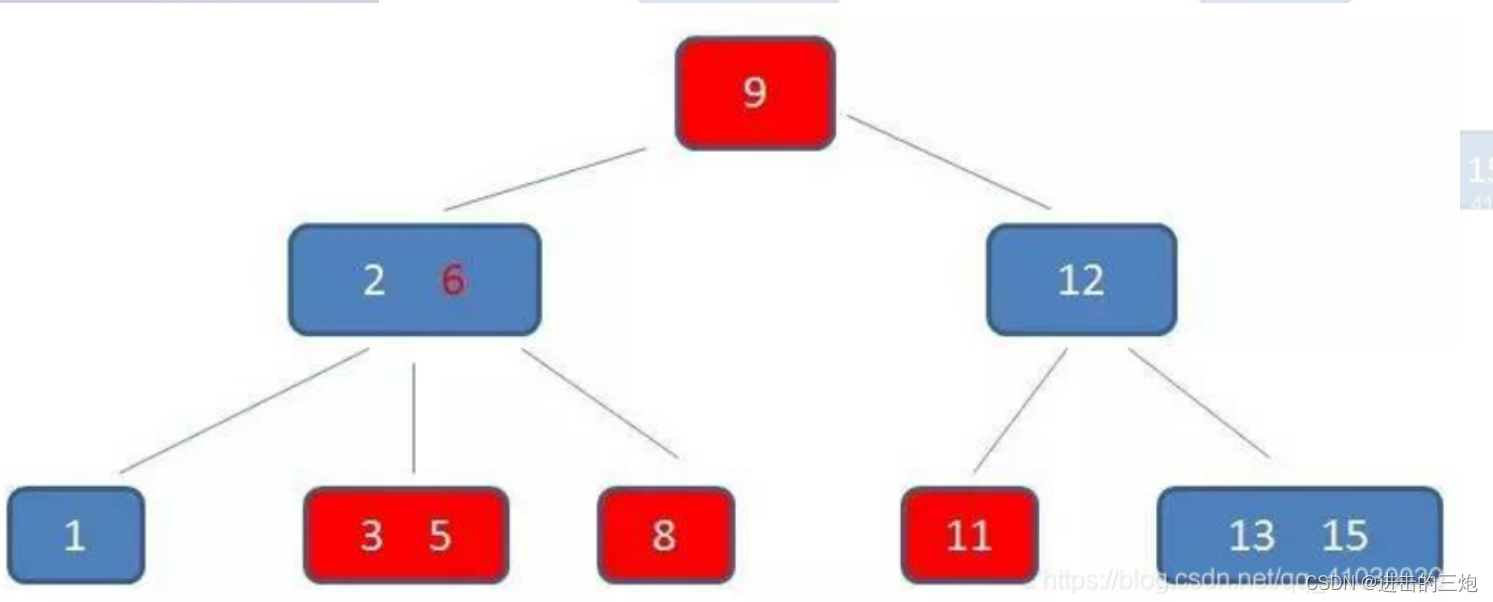
B+Tree:
B+树只要自顶向下找到3,然后通过链表指针,向右遍历到11即可。
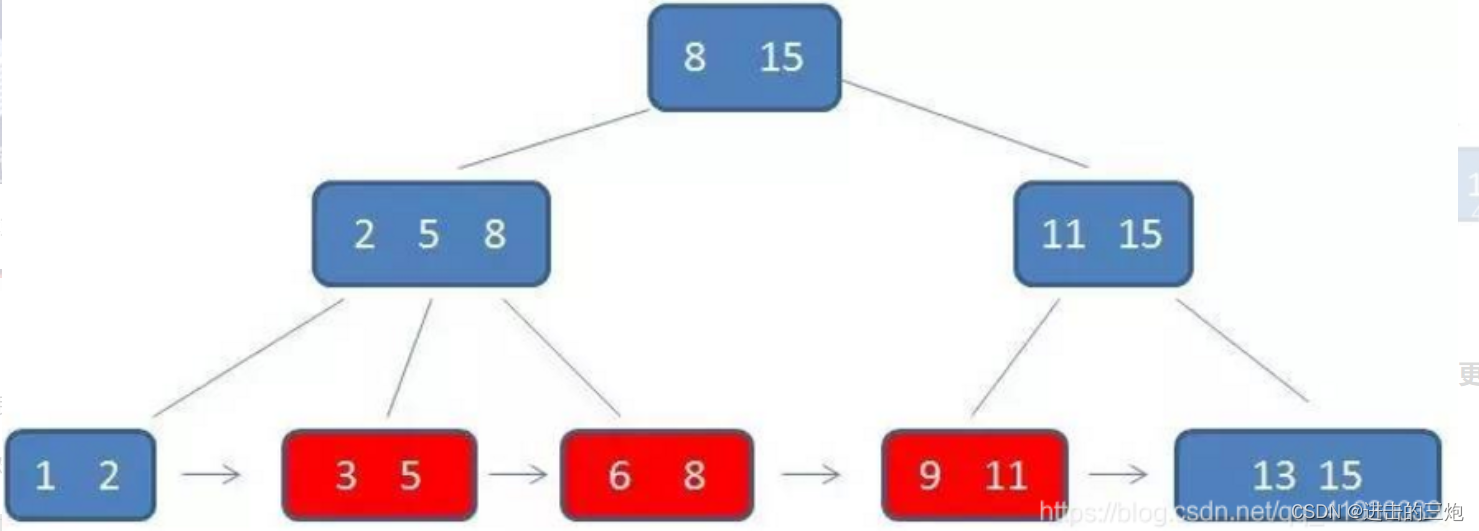
总结:
数据库使用的是B+Tree的存储结构
使用B+Tree的存储结构是为了提高查询效率,相对于AVL树来说,在数据相同的情况下,使用B+Tree数据结构的方式减少了层数,这样,在查询的时候,大大提高了效率
B-Tree和B+Tree的区别在于B-树的所有结点都包含卫星数据(卫星数据,指的是索引元素所指向的数据记录,比如数据库中的某一行),而B+Tree只是叶子结点包含卫星数据,叶子结点不包含指针,中间的结点是指针















 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









