







基于Python的障碍度模型分析和熵权法-障碍度技术路线讲解
障碍度模型
障碍度模型建立在综合评价模型(如熵权法)的基础上,用来对影响事物发展的障碍因素进行全面挖掘。
计算单一指标对总目标的贡献,一般用指标的全局权重表示,记作 ( F )。
计算原始数据的标准化矩阵 ( X ),一般使用极差法。
计算指标偏离度 ( I ),表示指标实际值与最优值之间的差距。
I = 1 - X
计算指标障碍度 ( O )。
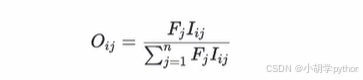
根据指标层级关系,将底层指标的障碍度向上求和汇总,得到上层指标的障碍度。
提示:
-
第 1、2 步计算标准化矩阵和全局权重,一般直接使用熵权法即可全部得到。
-
障碍度模型一般配合熵权topsis使用,当基于topsis给对象排序之后,可以继续用障碍度模型计算每个对象的待优化项,障碍度越高越亟需优化。
-
可能存在障碍度为 0 的情况,当对象的某个指标是所有对象中最高的,极差法之后结果是 1,偏离度为 0,最后的障碍度也为 0,即该指标已经满分,没有障碍,无需优化。
import numpy as np
import pandas as pd
#标准化矩阵
file_path = '文件名.xlsx'
sheet_name = 'Sheet1' # 工作表名称
df = pd.read_excel(file_path, sheet_name=sheet_name,header=None)
# 确保读取的数据行数和列数符合预期
assert df.shape == (208 , 21), "Data does not match the expected shape of 208 rows and 21 columns."
# 将DataFrame转换为NumPy数组
X = df.to_numpy()
#首先有一个用极差法计算得到的矩阵
# X = np.array([
# [0.2835013, 0.9216583, 0.1357502, 0.2696966, 0.1911899, 0.5042552, 0.4455268, 0.0446062, 0.080618, 0.0215951, 0.6167125, 0.7370561, 0.5658954, 0.2464479, 0.1660301, 0.0383544, 0.2709993, 0.0943038, 0.0934634, 0.6083947, 0.4031866],
# [0.3429626, 0.9442306, 0.1747543, 0.342364, 0.2674248, 0.4812831, 0.6512116, 0.0564887, 0.1394019, 0.068576, 0.6256481, 0.8221366, 0.67814, 0.3091549, 0.2386168, 0.0863749, 0.5192316, 0.1791601, 0.2478428, 0.5179415, 0.460207],
# [0.39398, 0.9560464, 0.2295412, 0.3920892, 0.3192727, 0.4473767, 0.7453613, 0.06325, 0.1982095, 0.1038404, 0.6376473, 0.9199029, 0.7804101, 0.1673392, 0.3093962, 0.1146463, 0.313949, 0.279514, 0.4820148, 0.3732162, 0.5590423],
# [0.4701261, 0.9640699, 0.2800824, 0.4417462, 0.3717403, 0.4322799, 0.7408783, 0.0777833, 0.2468215, 0.1408661, 0.6493806, 1, 0.6603302, 0.199325, 0.3643284, 0.1572093, 0.3691904, 0.4184557, 0.05857, 0.4214579, 0.5742477],
# [0.6008152, 0.9724883, 0.2742403, 0.4970875, 0.4295354, 0.4016962, 0.8409867, 0.0935376, 0.2962379, 0.1790405, 0.6745646, 0.382003, 0.6646169, 0.4805927, 0.3849443, 0.2768577, 0.3772132, 0.6120465, 0.7925256, 0.7953315, 0.6996926],
# [0.6008152, 0.9820725, 0.4395747, 0.5462081, 0.4787779, 0.4015739, 0.9428628, 0.0924099, 0.3457252, 0.217904, 0.7474627, 0.3451351, 0.7126439, 0.4217177, 0.4496958, 0.3291448, 0.3360375, 0.3684072, 0.689775, 0.8496035, 0.7186994],
# [0.7934578, 0.9889113, 0.4828586, 0.6149434, 0.5504979, 0.4024907, 0.9748437, 0.117768, 0.4018124, 0.257878, 0.7605921, 0.3332261, 0.733264, 0.26796, 0.5067655, 0.3847484, 0.2484988, 0.4217125, 0.5119387, 0.9038755, 0.7681171],
# [0.7934578, 0.9895444, 0.3927585, 0.6857851, 0.6281338, 0.3926339, 0.9855502, 0.1041041, 0.4629146, 0.299575, 0.7880695, 0.3193445, 0.7804939, 0.5458182, 0.5832807, 0.4384967, 0.1976297, 0.4585388, 0.5323758, 0.9400568, 0.8517469],
# [0.8500431, 0.9919891, 0.5162583, 0.7385722, 0.6843621, 0.377506, 0.9913104, 0.0985378, 0.5266898, 0.3433396, 0.8412626, 0.3123217, 0.8815392, 0.6222936, 0.6450347, 0.4954521, 0.289521, 0.5284179, 0.6421108, 0.9762381, 0.9125687],
# [0.8993451, 0.9950793, 0.495675, 0.8085027, 0.7585739, 0.3732981, 0.934157, 0.1054977, 0.598839, 0.3951066, 0.9343368, 0.3052807, 0.7380961, 0.3065621, 0.7172464, 0.5575793, 0.2105849, 0.5762148, 0.6723859, 0.9943288, 0.9125687],
# [0.9350008, 1, 0.6259567, 0.8582786, 0.8086711, 0.3457431, 0.916619, 1, 0.647735, 0.4421258, 0.970412, 0.1866768, 0.8195866, 0.6973401, 0.7473087, 0.6138396, 0.1870292, 0.6427401, 0.7565145, 0.9099057, 0.8441442],
# [0.992945, 0.9951483, 0.8617816, 0.9571809, 0.9214544, 0.3518167, 1, 0.1348223, 0.7304347, 0.5087108, 0.9887487, 0.1514598, 1, 0.3495012, 0.8972221, 0.7208875, 0.199038, 0.8371831, 1, 0.946087, 0.8479456],
# [0.9999999, 0.980167, 0.7515171, 1, 0.9844676, 0.3622758, 0.9203586, 0.1327282, 0.7779112, 0.5551556, 1, 0.0833809, 0.9222342, 0.3901131, 0.9292768, 0.7554208, 0.1652885, 0.8355486, 0.9885366, 0.8857848, 0.8517469]
# ])
# 打印数组以验证
# print(X)
# 计算指标偏离度 I
I = 1 - X
# print(I)
# # 权重 W (转换为NumPy数组)
W = np.array([
0.04887063, 0.07357905, 0.043032109, 0.045568075, 0.049896581,
0.025789161, 0.071404499, 0.007450655, 0.052654926, 0.047108596,
0.046146325, 0.027241739, 0.04570499, 0.043462798, 0.055210652,
0.061466709, 0.052430037, 0.054506581, 0.045543672, 0.048785412,
0.054146803
])
# 将 W 转换为列向量,并进行广播
W = W.reshape(1, -1)
# 计算加权指标偏离度 o
# 这里使用广播运算,使得每列的 I 值与 W 对应位置相乘
o = I * W
print(o)
# # 打印结果
# size = W.shape
# print(size)
#下一步将o每一行加总=U,
U= np.sum(o, axis=1)
print(U)
# #最后障碍度P等于o中的每行指标数据都除以U,比如o中第一行数据,除以U中的第一个,以此类推....
P = o / U[:, np.newaxis]
print(P)
#将障碍度的矩阵写入excel中
dp=pd.DataFrame(P)
output_file_path = 'output_data.xlsx' # 你想要保存的Excel文件名
dp.to_excel(output_file_path) # index=False表示不保存行索引到文件中

















 2392
2392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









