







浙江省气象数据处理与分析报告
一、题目要求:
(1)从[中央气象台官方网站(http://www.nmc.cn/);浙江气象台(http://zj.weather.com.cn/)]爬取所采用的数据
(2)对最近24小时各个城市的天气数据,包括时间点(整点)、整点气温、整点降水量、风力、整点气压、相对湿度等数据进行处理和分析
(3)使用echarts对数据进行可视化
二、数据爬取
使用工具
(1)Google Chrome
(2)Pycharm 2018.3.3
(3)python语言
爬取目标
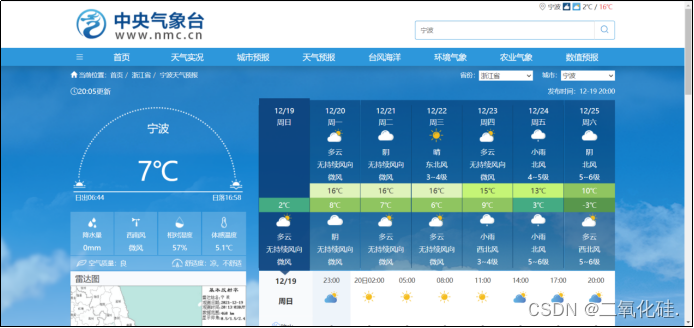
对于这道题目,需要对浙江省最近24个小时内各个城市的天气数据进行收集,当我进入到浙江气象台网站(http://zj.weather.com.cn/),发现每个城市的气象网址的链接、排版都没有统一的格式,是一个个独立的网站,不知道如何下手,但当我再进入中央气象台官方网站(http://www.nmc.cn/),欣喜的发现,通过切换省份,可以发现传回的数据与请求的URL之间具有一定的关系
http://www.nmc.cn/publish/forecast/AZJ/城市编号.html --> 某个浙江省城市的天气数据,其中AZJ为浙江省的三位编码
例如杭州的天气数据为http://www.nmc.cn/publish/forecast/AZJ/hangzhou.html
例如宁波的天气数据为http://www.nmc.cn/publish/forecast/AZJ/ningbo.html
至此,我要爬取数据的网站就已经找到了
但是还有一个问题,在这个网页中,只显示每隔三小时的气象数据,所以对于每一个城市,这里只爬取了一天中8个整点的气象数据。
爬虫方法
我选择的是用requests、BeautifulSoup、json来分析爬取网页,
直接右键->检查 或者按F12调出窗口
选择Network,按ctrl+r 刷新页面
在这里可以找到当前真正的request URL,下图以杭州市的气象数据为例,这个网页的Request URL为http://www.nmc.cn/publish/forecast/AZJ/hangzhou.html,也就是说网页的链接就是它真正的request URL
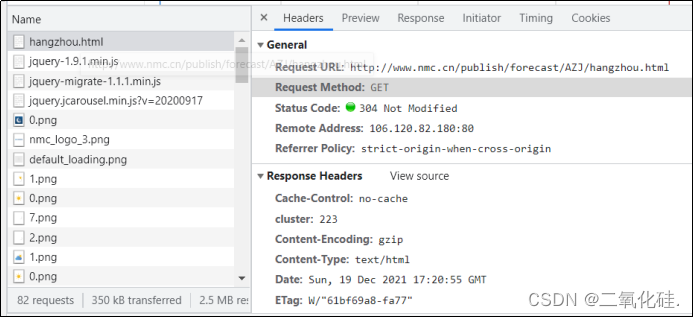
通过上图可以看到,网页是通过get请求来获取内容,所以待会儿可以使用requests.get来获取网页
为了获取浙江省所有城市的天气信息,我需要知道浙江省所有城市所对应城市编码
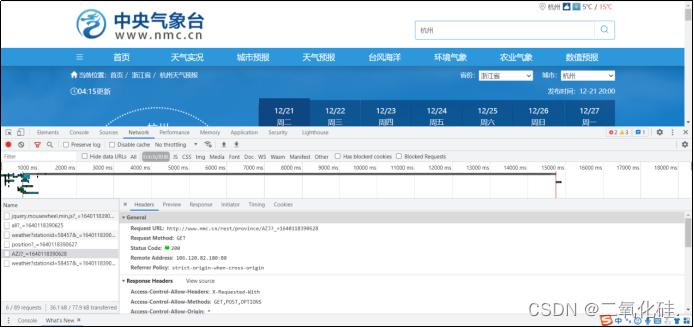
通过查看network中的信息,我发现了一个Request URL:http://www.nmc.cn/rest/province/AZJ

打开这个网页,我发现它将浙江省的所有城市都存放在了以{“code”:“xxxxx”,“province”:“浙江省”,“city:”:“xx”,“url”:“/publish/forecast/AZJ/xxxx.html”}为统一格式的数组中,其中每个城市都对应一个城市编码,例如杭州的气象信息网站则通过http://www.nmc.cn/publish/forecast/AZJ/58457.html获取
通过直接访问请求URL,传回的响应的数据为json格式,一种轻量级的数据交换格式
那我要怎么获取呢?
我找到了一个博客,在其中发现了提取方法
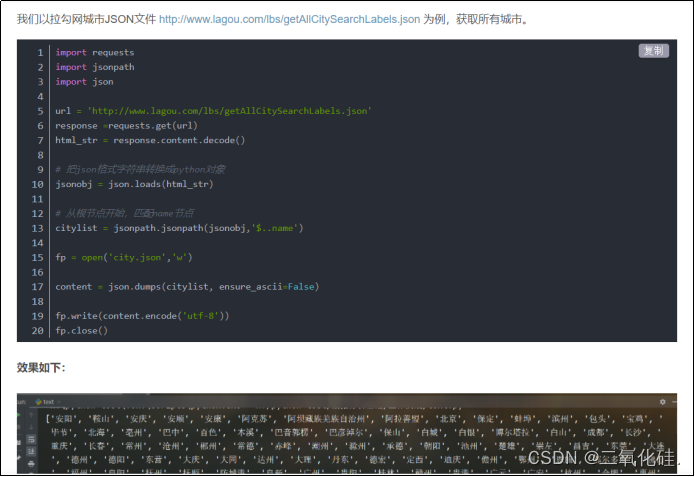
仿照着它的方法,我编写了获取浙江省城市编码的爬虫代码
至此,爬取数据的方法总结为以下:
1.在http://www.nmc.cn/rest/province/AZJ中将浙江省的所有城市编码获取下来
2.根据城市编码生成要访问城市气象数据的url
3.获取需要的气象信息
4.写入文档
爬虫过程
当我在pycharm中导入requests包时,问题又出现了,发现提示报错ModuleNotFoundError: No module named requests,但是我已经使用pip install requests安装了pip,然后我查阅了百度以后,去我pycharm下载的目录找到C:\Users\lenovo\AppData\Local\Programs\Python\Python37\Lib\site-packages,发现在这个目录下已经有了requests,如果一切顺利的话,在pycharm中的lib的site-packages文件夹里应该也有requests

但当我打开pycharm,并没有requests加入,同时import requests仍然报错。直到我看到一篇博客,才解决了这个问题,具体方法是直接file->settings->project interpreter->latest右侧的+号->搜索requests->install package 成功!有可能是因为我原先装有多个版本的Python,与pycharm中的python版本不存在导致的,不过通过上面的方法直接在python里面真的是太方便了
使用同样的方法下载BeautifulSoup4和jsonpath
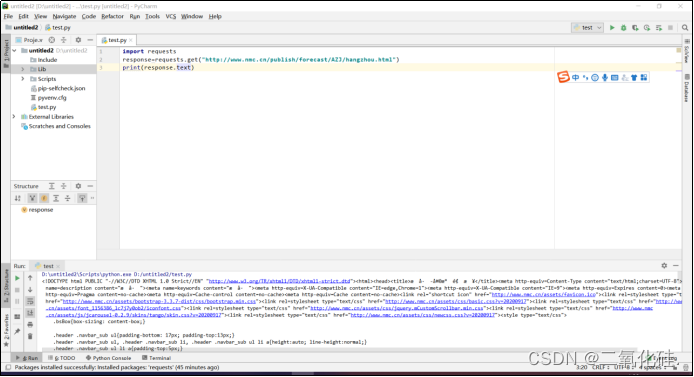
当我试着通过requests.get获取网页,用print去打印网页内容时发现有乱码,加上这一行代码就好啦response.encoding = ‘utf-8’
爬取城市编码:
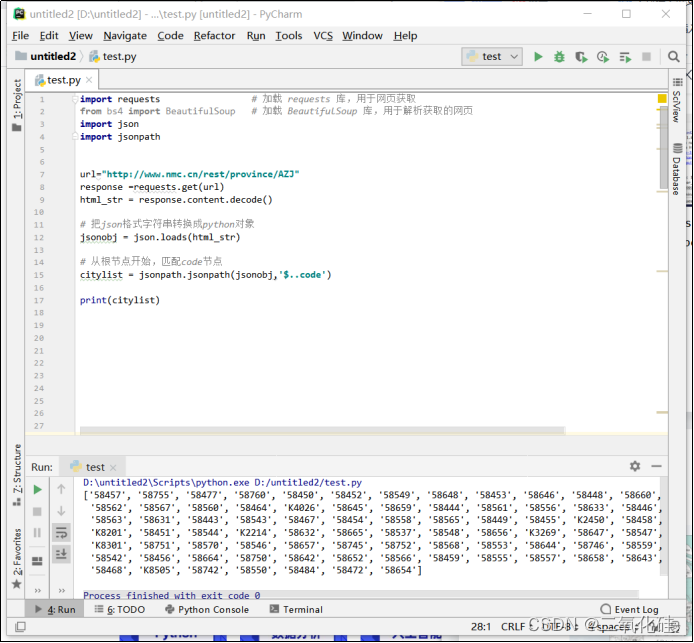
可以看到此时citylist中存放的就是城市编码
这里用到的是json提取数据,本来是想用BeautifulSoup来提取数据的,但是url返回的是json格式的数据,用这个方法更合适
Python注释快捷键是ctrl+/ 写代码的时候还忘记特意百度的
爬取每个城市的气象数据
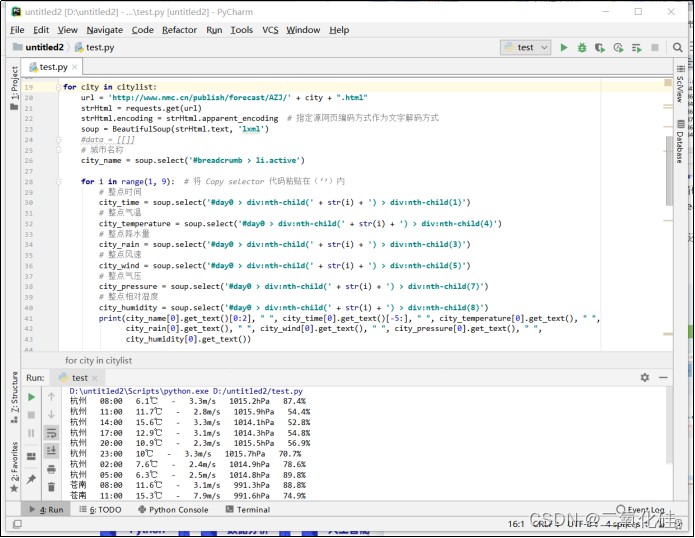
以提取杭州市周日5:00的气压为例
在要提取的数据上点击右键->检查->此时会显示出开发者见面,高亮处标示元素即为检查元素(1015.8hPa),对其右键->Copy->Copy selector
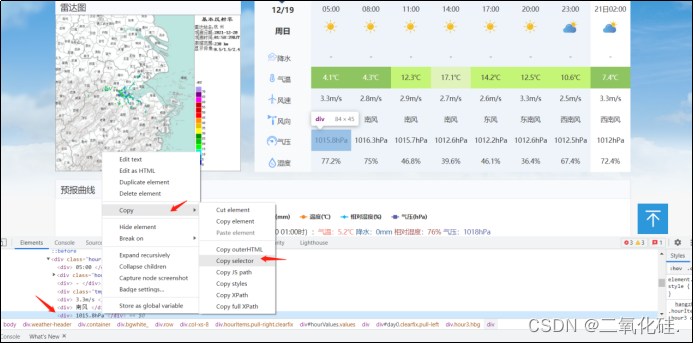
将copy的代码粘贴到soup.select(‘’)的引号中即可
至此会发现提取的不仅仅是气压的数据,而是一段目标元素的 HTML 代码
可以通过以下的办法提取我需要的数据

这样我就能通过遍历citylist中的城市编码,将所有页面中的气象信息全部提取到
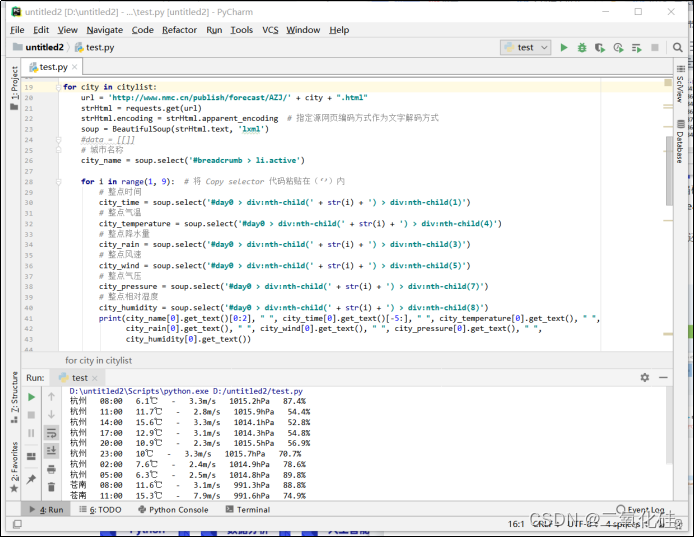
写入文件
写入文件则是python中的一个基本操作,就不在赘述了
但是对我的数据需要注意的是当我查询到玉环这个城市的时候发现报错了,我打开了它的网页发现数据是有缺失的
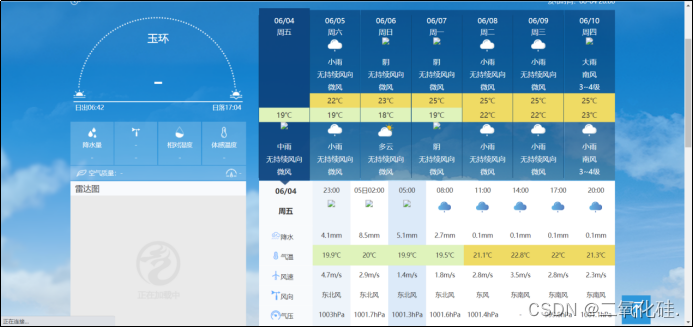
这就需要在存入文件的时候判断一下是否取到数据,如果没有取到数据,则将数据改为null
有些城市的整点降水为0,在页面中则会显示“-”,所以当提取到“-”时,则把存入的整点降水数据改为0.0mm

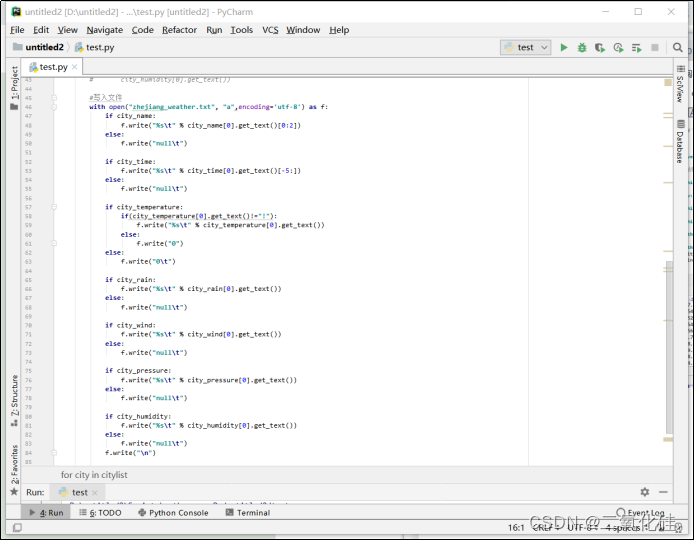
完整代码
import requests # 加载 requests 库,用于网页获取
from bs4 import BeautifulSoup # 加载 BeautifulSoup 库,用于解析获取的网页
import json
import jsonpath
url="http://www.nmc.cn/rest/province/AZJ"
response =requests.get(url)
html_str = response.content.decode()
# 把json格式字符串转换成python对象
jsonobj = json.loads(html_str)
# 从根节点开始,匹配code节点
citylist = jsonpath.jsonpath(jsonobj,'$..code')
# print(citylist)
for city in citylist:
url = 'http://www.nmc.cn/publish/forecast/AZJ/' + city + ".html"
strHtml = requests.get(url)
strHtml.encoding = strHtml.apparent_encoding # 指定源网页编码方式作为文字解码方式
soup = BeautifulSoup(strHtml.text, 'lxml')
#data = [[]]
# 城市名称
city_name = soup.select('#breadcrumb > li.active')
for i in range(1, 9): # 将 Copy selector 代码粘贴在(‘’)内
# 整点时间
city_time = soup.select('#day0 > div:nth-child(' + str(i) + ') > div:nth-child(1)')
# 整点气温
city_temperature = soup.select( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7777
7777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









