







✨目录
| 项目名称 | 项目名称 | 项目名称 |
|---|---|---|
| 1.口罩佩戴检测系统 | 2.人员抽烟检测系统 | 3.火焰烟雾检测系统 |
| 4.交通车辆检测系统 | 5.人员跌倒检测系统 | 6. 安全帽检测系统 |
| 7.河道漂浮物检测系统 |
一、系统概述和展示🎄
1.1 摘要 🎈
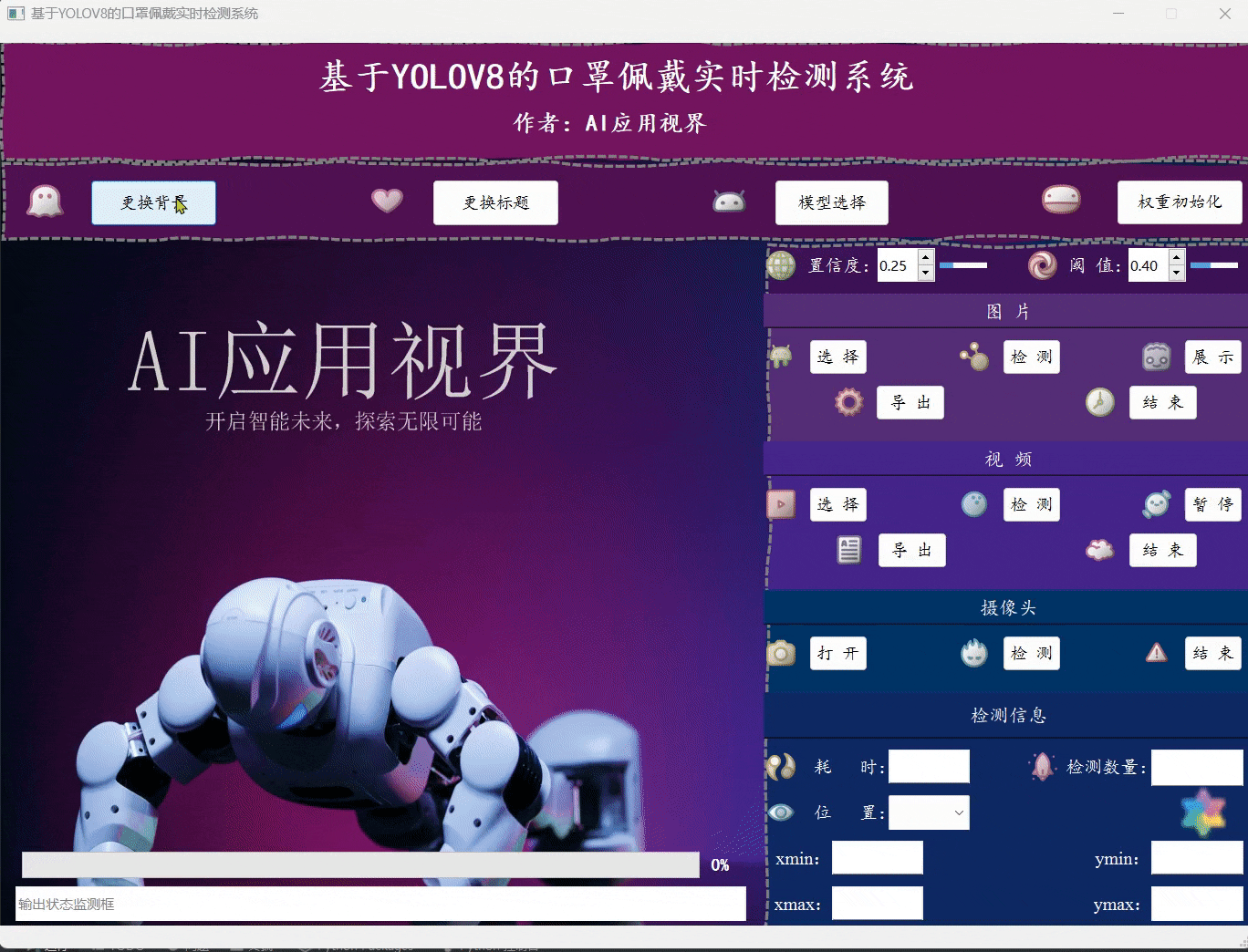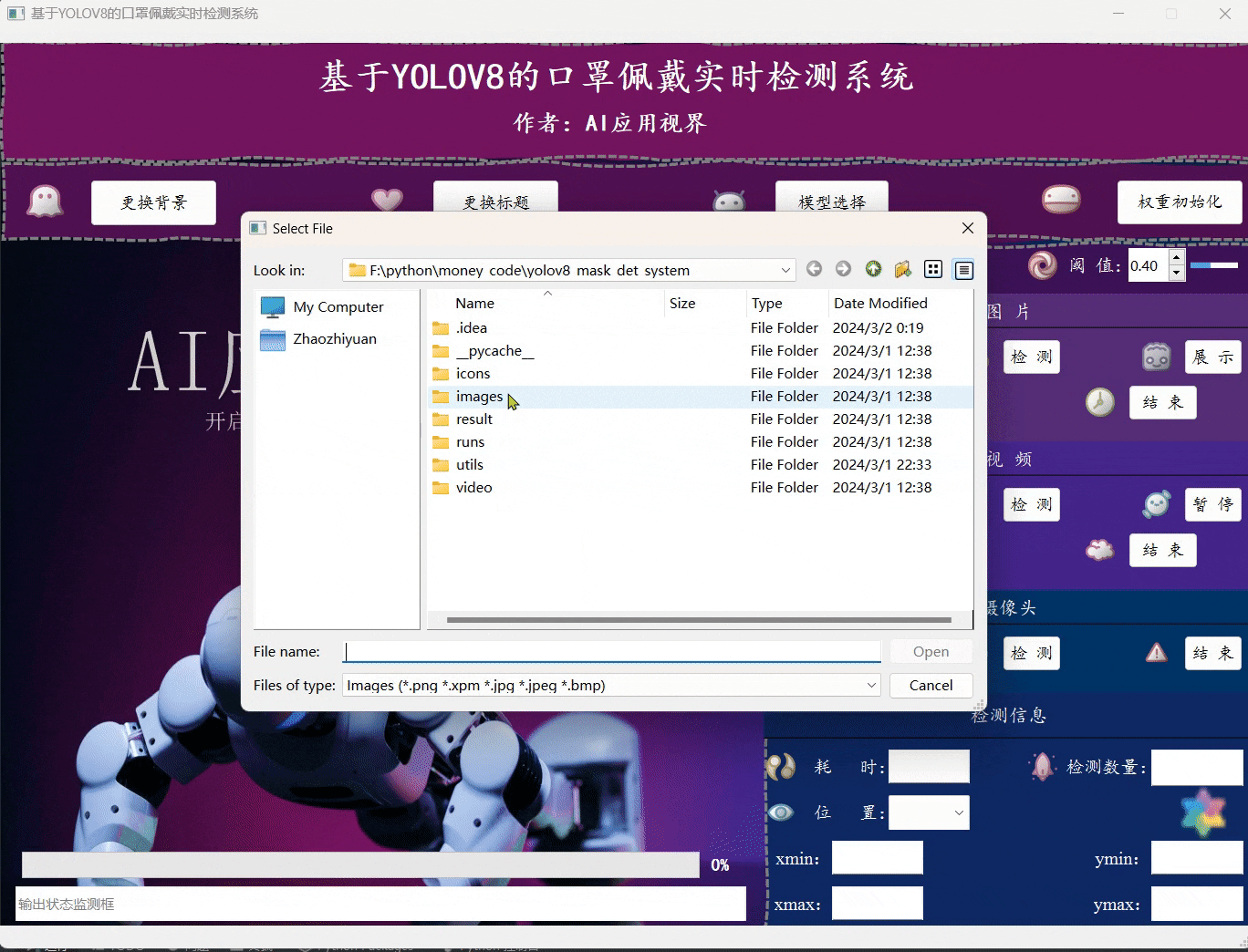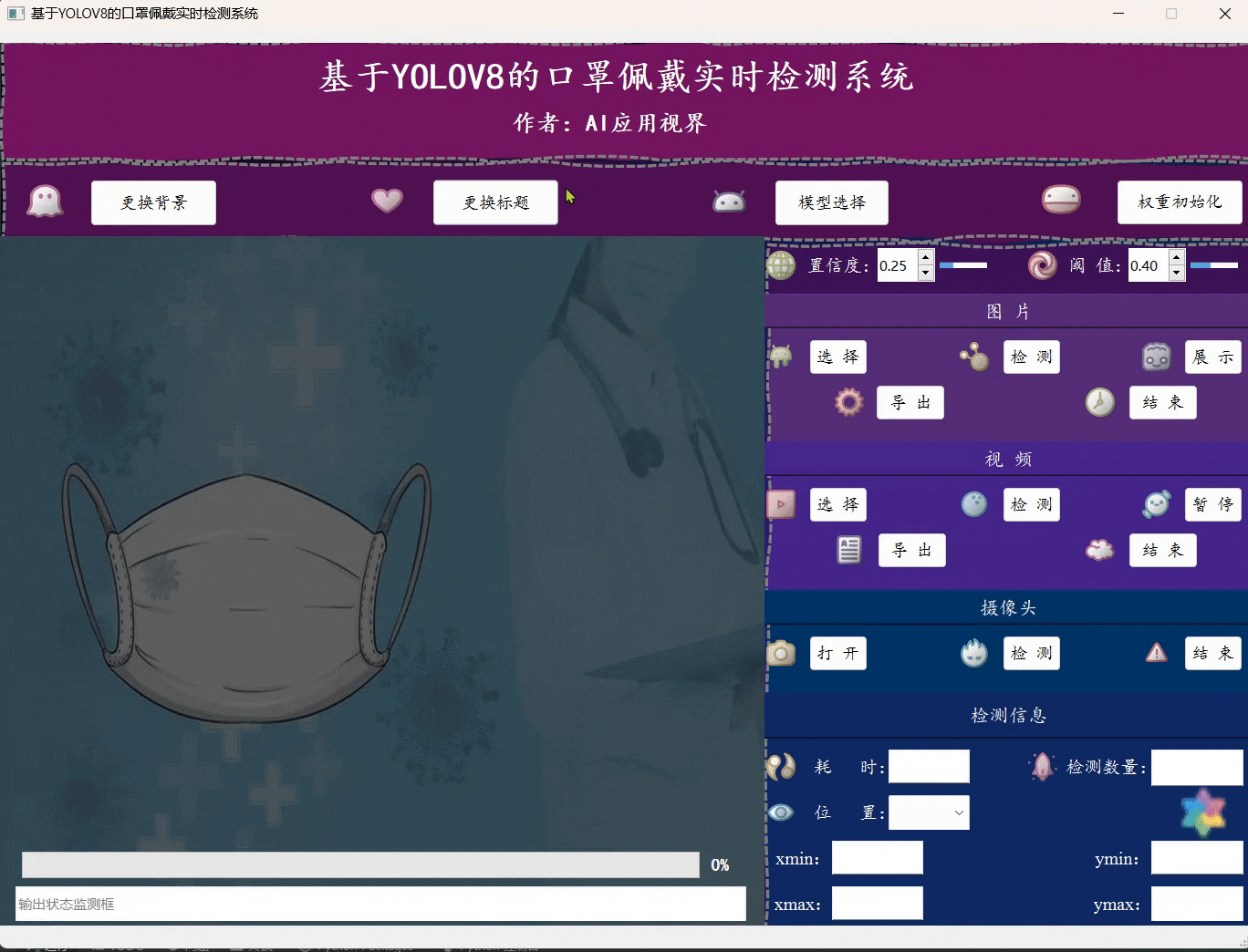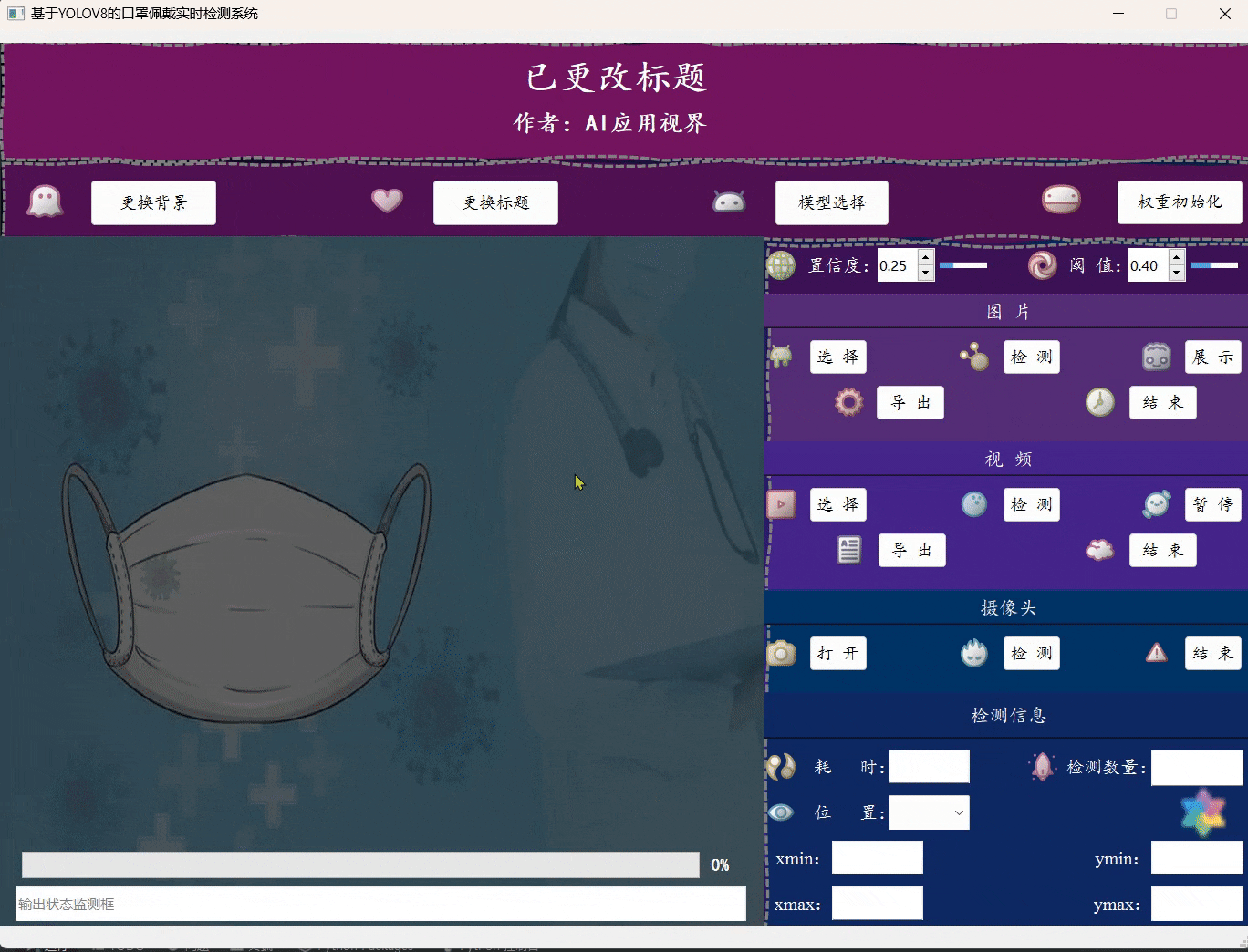
口罩佩戴实时检测系统可以帮助公共安全、医疗卫生等领域的工作人员快速地识别人们是否正确佩戴口罩,提高疫情防控效率,减少病毒传播风险。本文基于YOLOv8算法框架,通过7959张训练图片(其中6367训练集,1592验证集),训练出一个可用于检测人群中口罩佩戴情况的有效识别模型(主要用于公共场所和交通枢纽的检测识别)。此外,为更好地展示算法效果,基于此模型开发了一款带GUI界面的基于YOLOv8的口罩佩戴实时检测系统,可用于实时检测人群中的口罩佩戴情况。该系统是基于Python和Pyside6开发,并支持以下功能特性:
- 系统背景和标题修改
- 模型权重导入和初始化
- 检测置信度和IOU调节
- 检测目标的信息展示
- 检测用时的统计展示
- 图片导入、检测、结果展示、导出和结束
- 视频导入、检测、结果展示、导出和结束
- 摄像头导入、检测、结果展示、导出和结束


- 用户可通过点击更换背景,选择想要更换背景的图片,系统便会自动更换壁纸;
- 用户可通过点击更换标题,然后在文字输入栏中输入想要更换的标题,然后点击确定,即可更改系统标题。
- 用户可通过点击模型选择,选择想要加载的系统模型;然后点击权重初始化即可完成模型的准备工作。
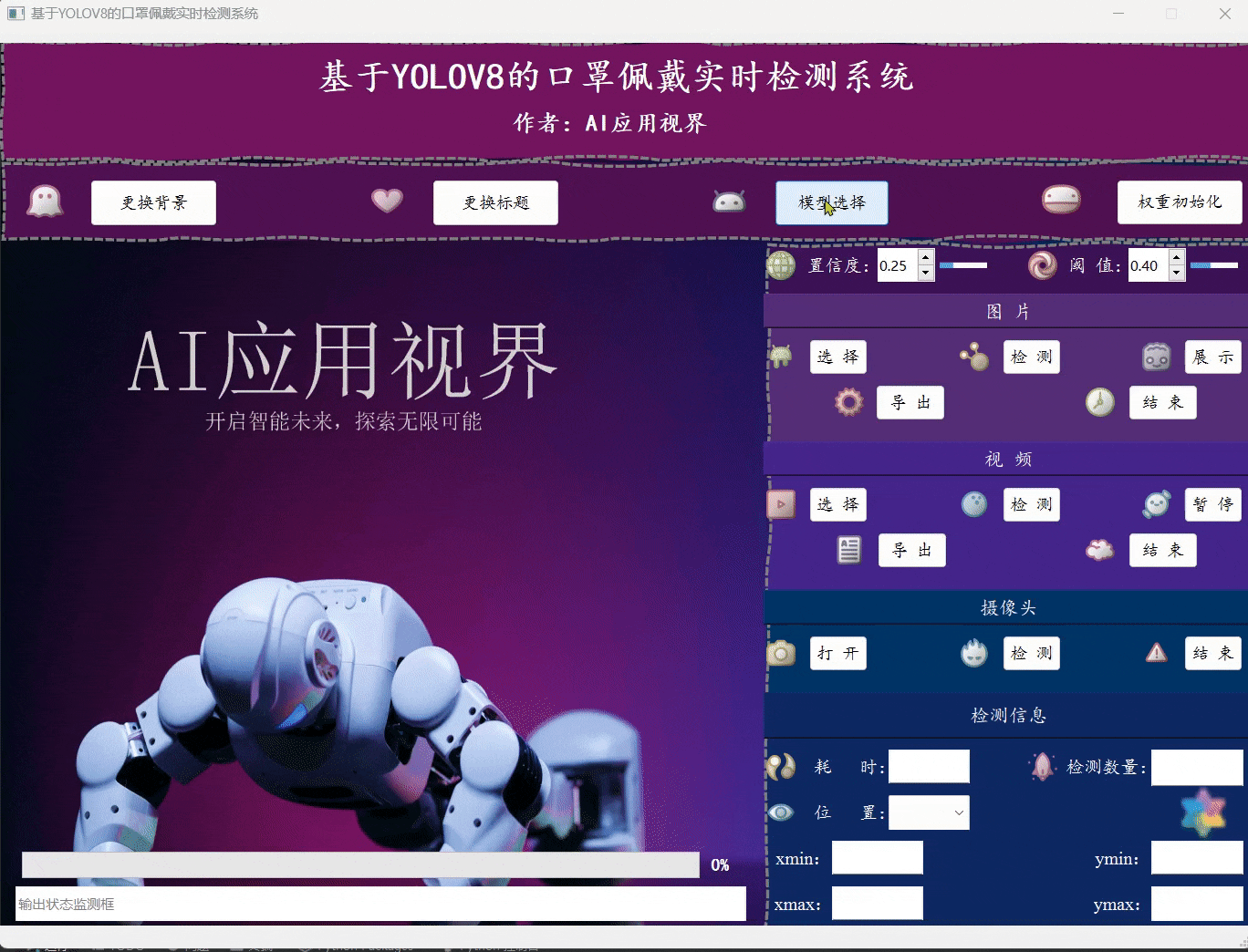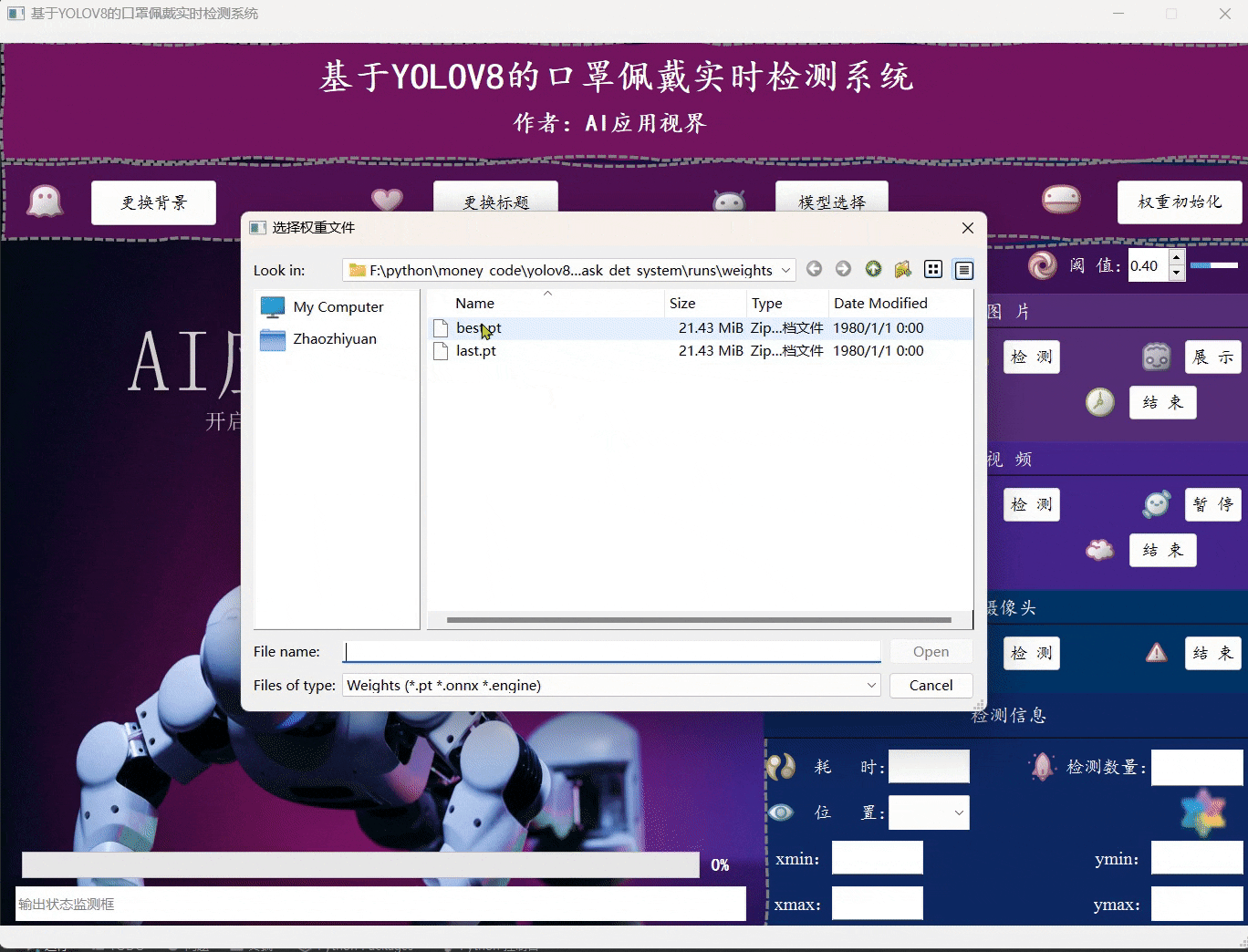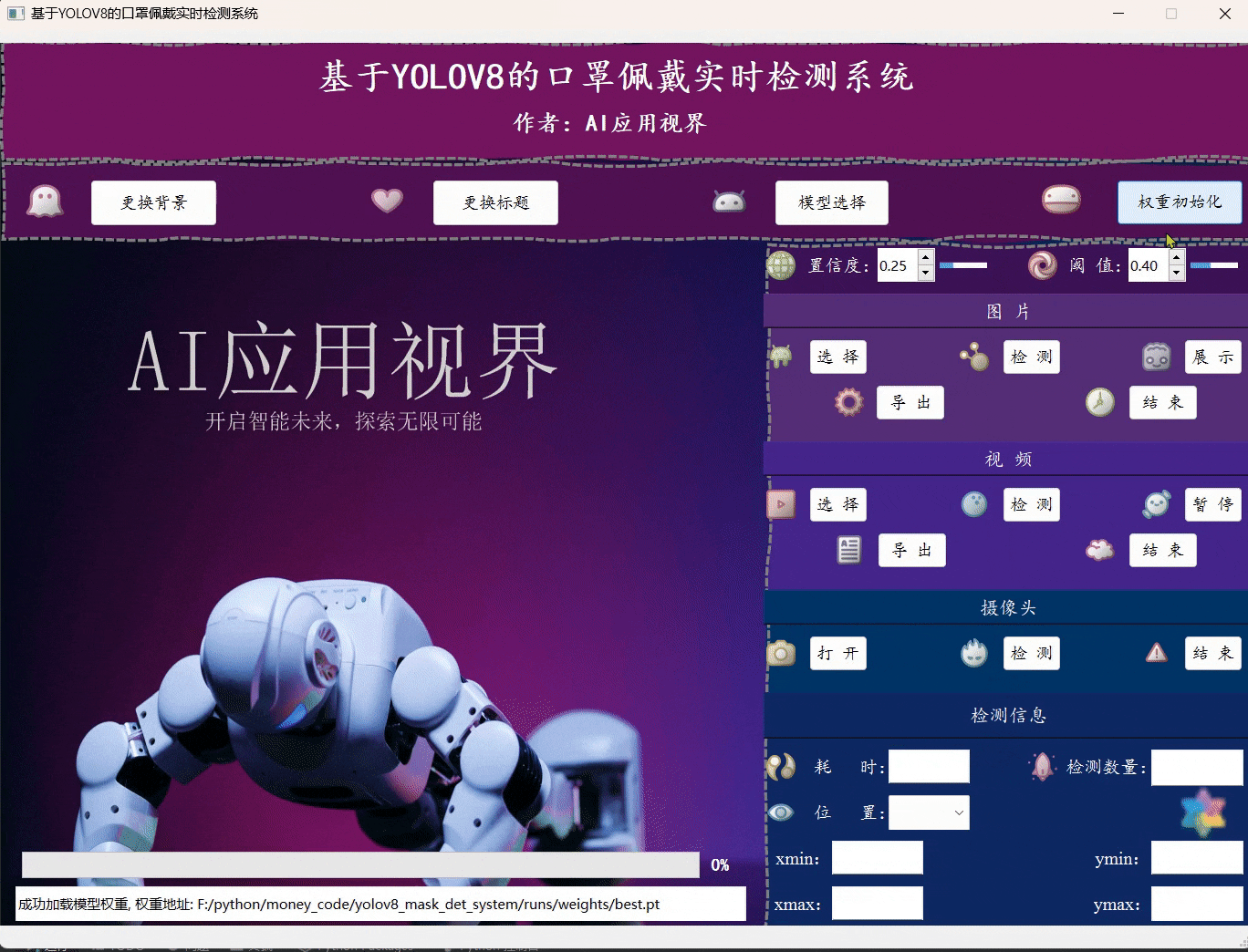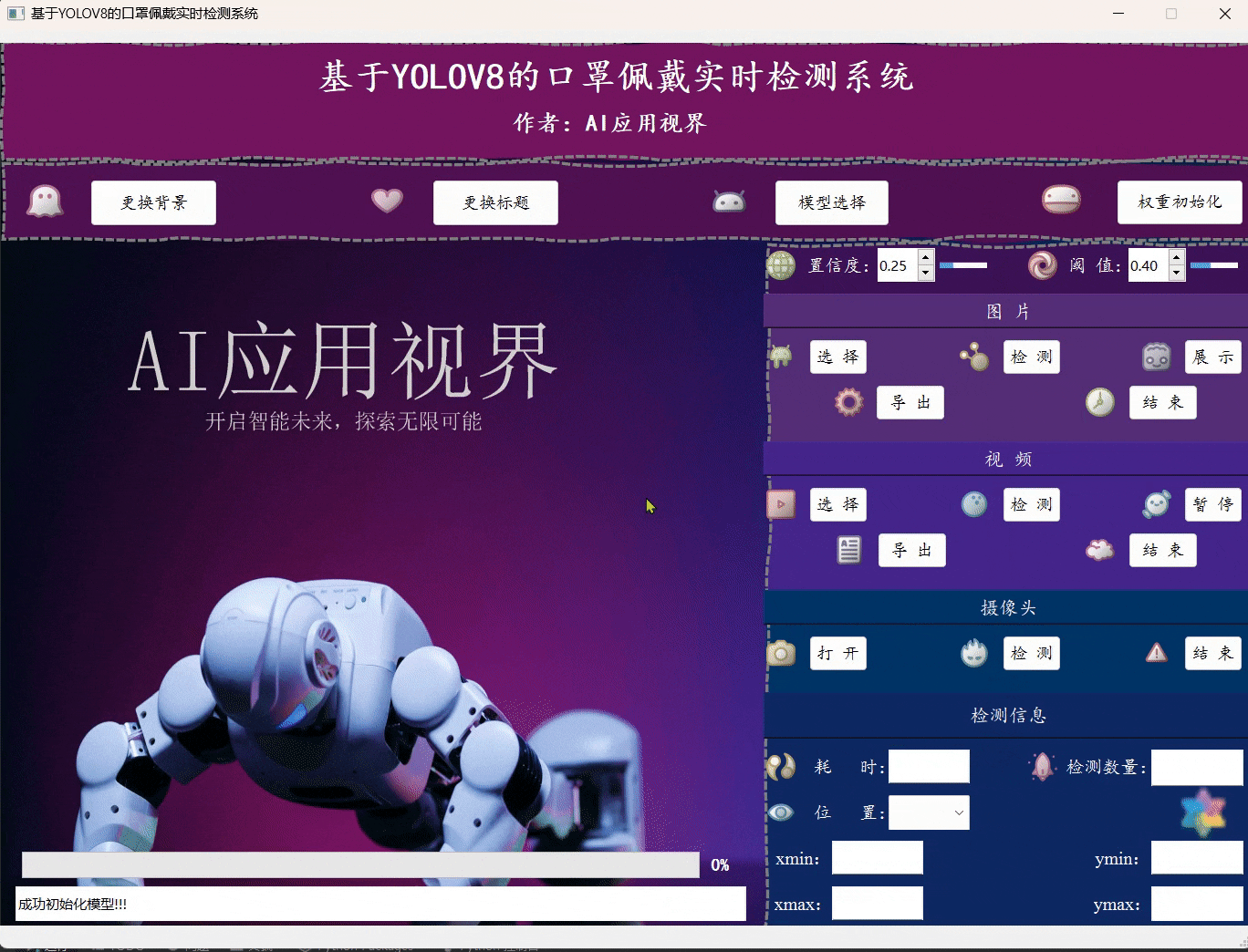
- 用户可通过点击图片中的选择,选择想要加载的图片文件;然后点击检测,等待弹出图片检测完成的提示框,再点击展示即可将对应的目标框展示在原始图片上,完成展示后,用户可手动点击导出将图片保存到指定位置,最后点击结束关闭图片展示区域。
- 相关展示信息,如耗时、检测目标数量、位置信息等可在检测信息一栏查看。
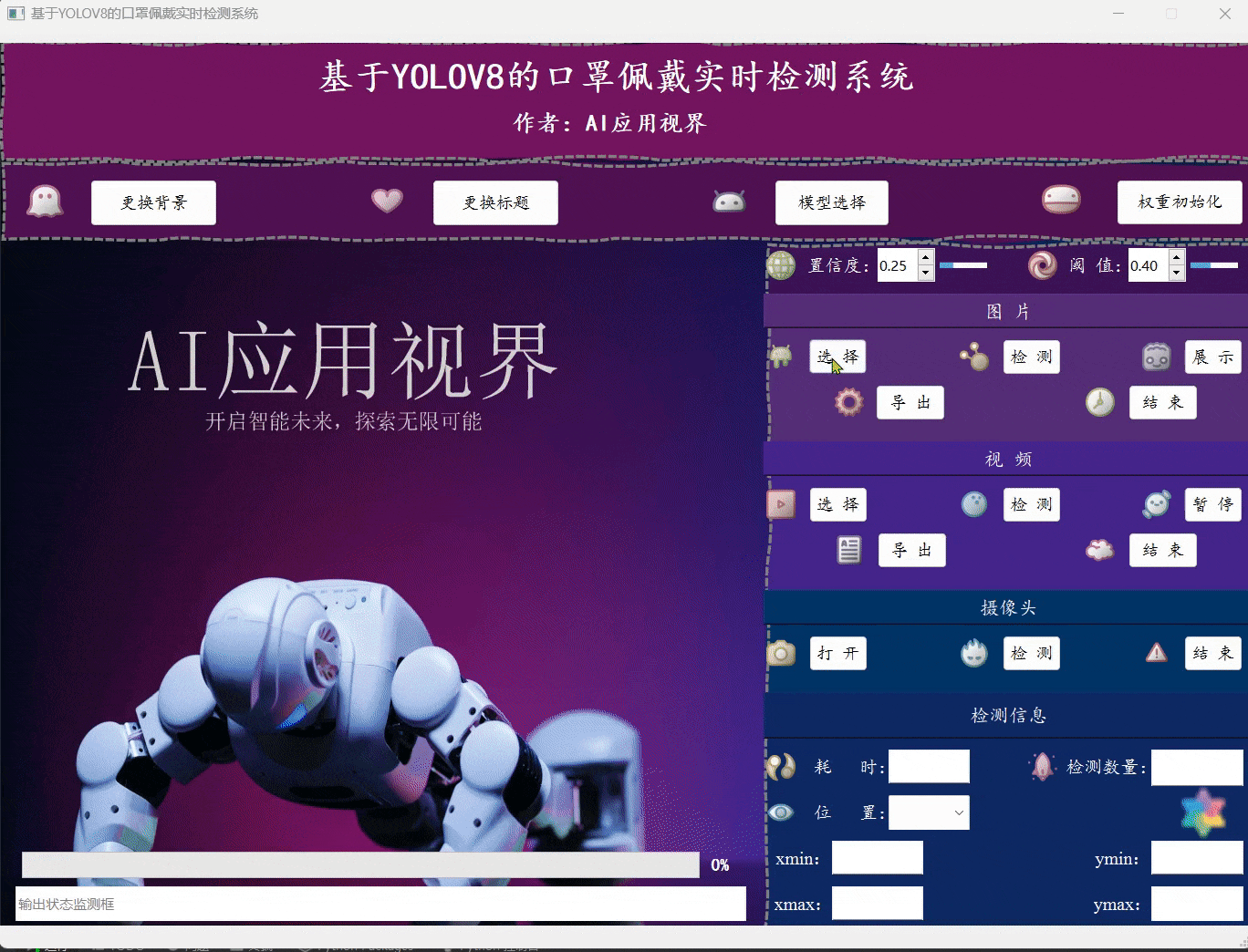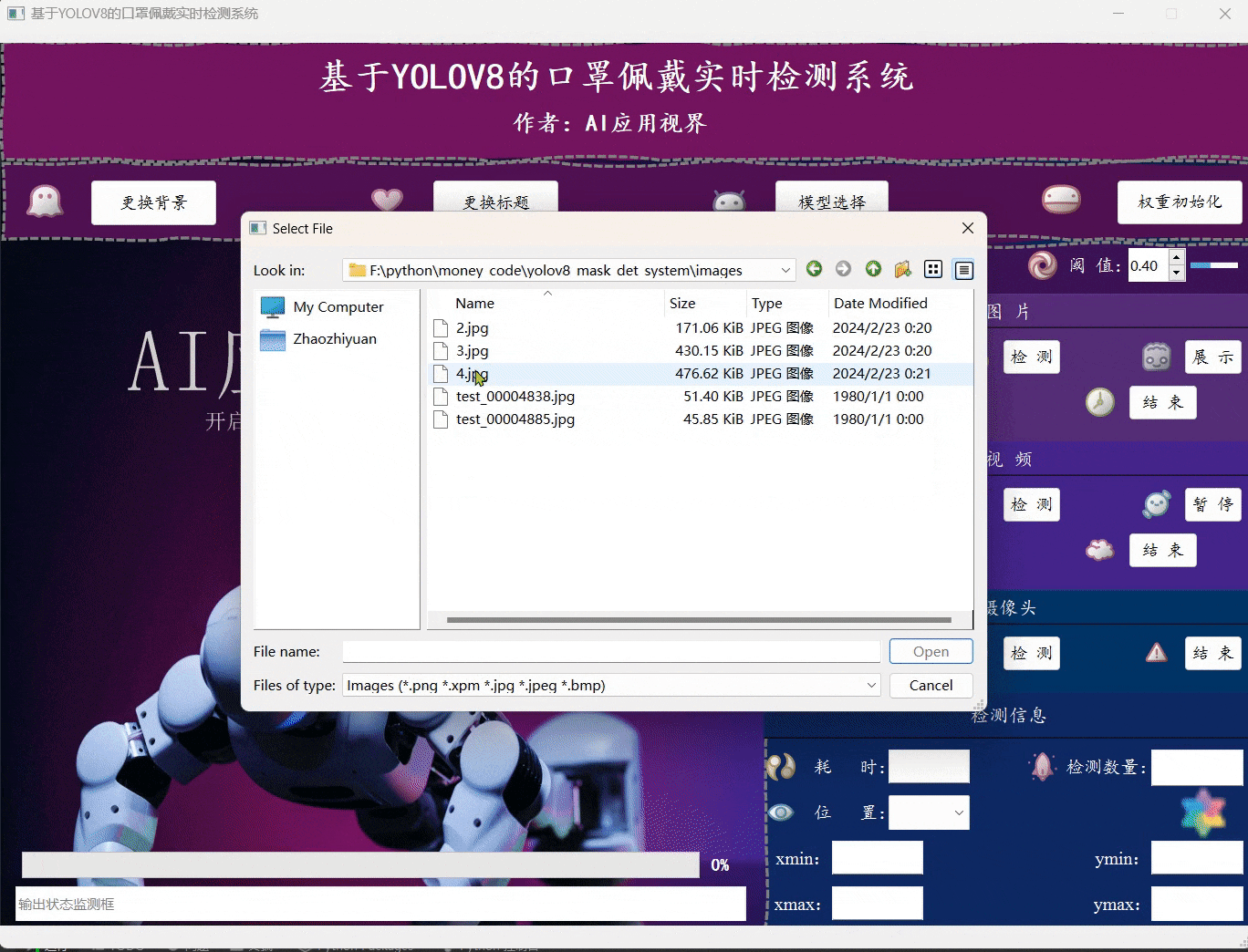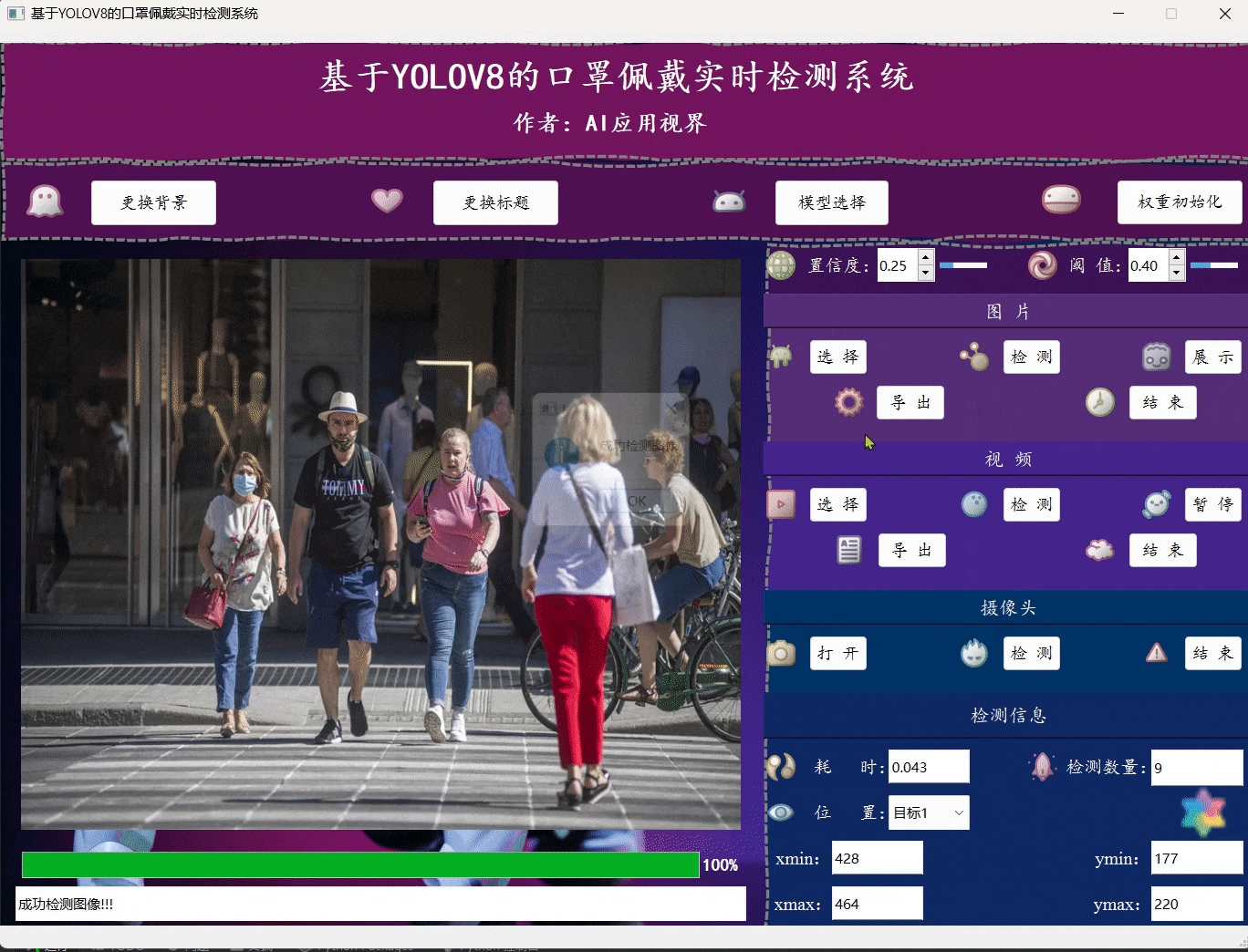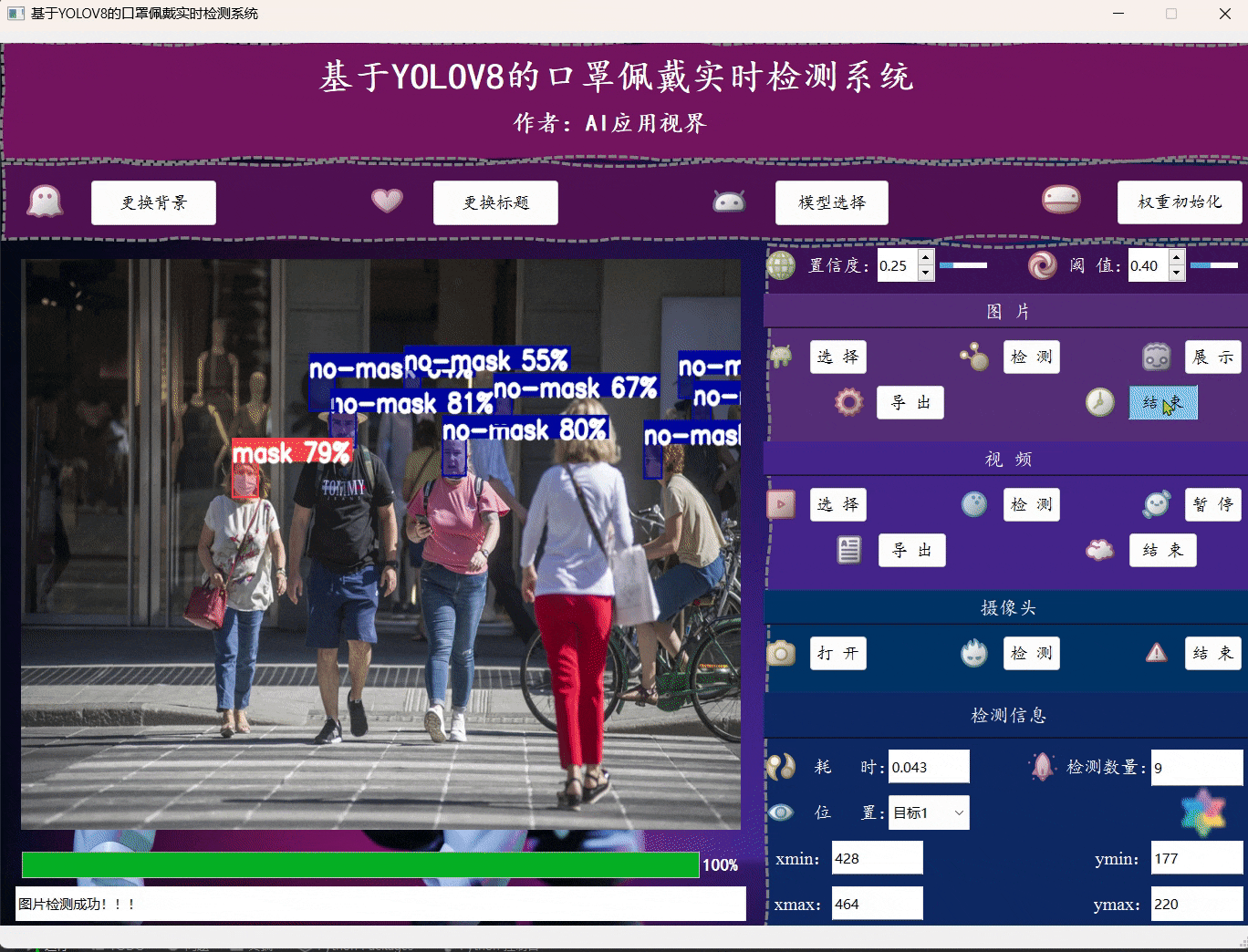
- 用户可通过点击图片中的选择,选择想要加载的图片文件;然后点击检测,等待弹出图片检测完成的提示框,再点击展示即可将对应的目标框展示在原始图片上,完成展示后,用户可手动点击导出将图片保存到指定位置,最后点击结束关闭图片展示区域。
- 相关展示信息,如耗时、检测目标数量、位置信息等可在检测信息一栏查看。
- 对于摄像头检测模块和视频检测模块原理类似。
- 注意:摄像头检测会自动调用电脑摄像头来进行检测任务。
二、一站式使用教程🎄
第一步:安装Anaconda Prompt、Pycharm(或者vscode),参考:anaconda点击 pycharm点击
第二步:创建python环境
conda create -n YOLOv8_My python=3.8.1
第三步:激活环境
conda activate YOLOv8_My
第四步:安装ultralytics和pytorch
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install ultralytics==8.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
第五步:安装图形化界面库
pip install pyside6==6.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
第六步:打开系统界面
python base_camera.py
注意:此环境可同时满足YOLOv8的训练以及系统的运行
三、YOLOv8原理剖析🎄
3.1 YOLOv8背景和技术原理🎈
权重链接: 点击
项目地址: 点击
论文地址:(目前还在火速撰写中)
YOLOv8是Ultralytics团队基于先前成功的YOLO系列模型推出的最新版本,适用于目标检测、分割、分类任务,以及处理大规模数据集的学习。这个模型不仅能够在多种硬件设备上运行,包括CPU和GPU,而且设计上追求快速、准确且用户友好。YOLOv8引入了一系列创新,包括新的骨干网络、无锚点(Ancher-Free)检测头和损失函数,旨在提升性能和灵活性。此外,该模型支持与早期YOLO版本的兼容,便于用户根据需求切换和比较不同版本。YOLOv8提供了五个不同规模的预训练模型,从n到x,每个模型在参数数量和精度之间取得了不同的平衡,其中较大的模型l和x在减少参数的同时显著提升了精度✅
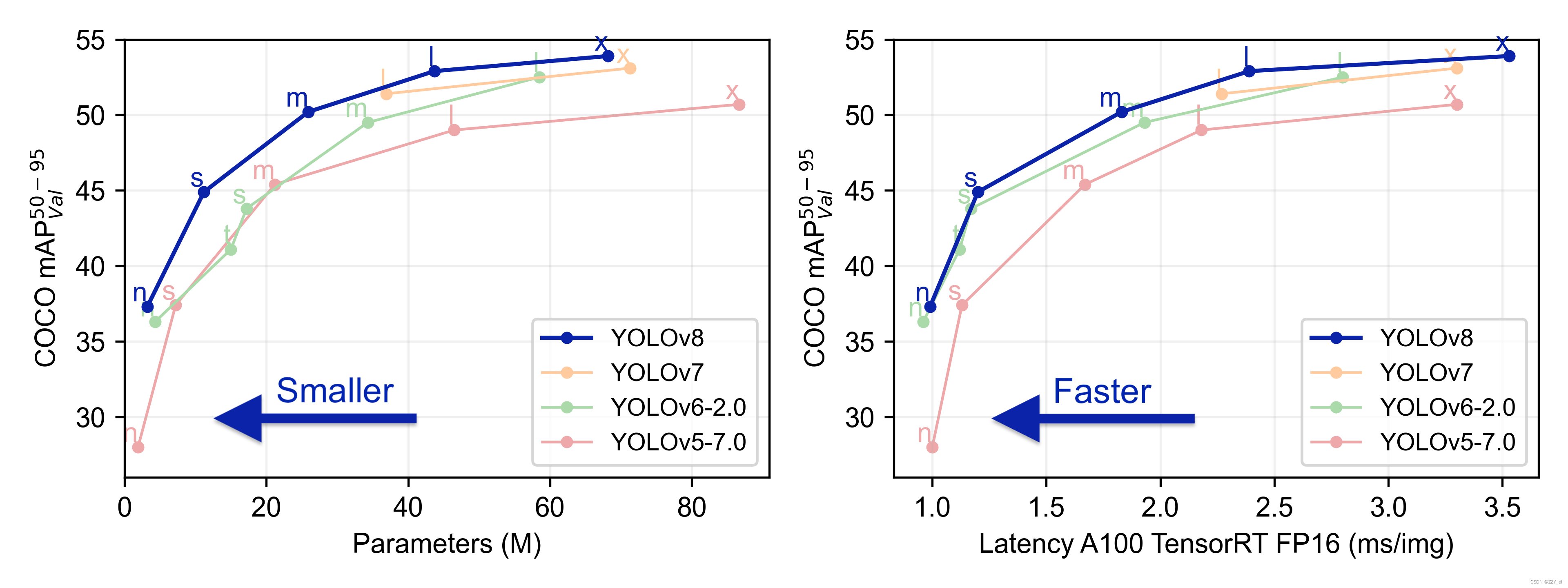
YOLOv5架构特点:
- Backbone:YOLOv5使用CSPDarknet作为主干网络,它是一种轻量级的Darknet架构,具有更高的速度和更好的性能。
- PAN/FPN:YOLOv5使用PAN(Path Aggregation Network)来融合不同尺度的特征图,以提高检测性能。
- Head:YOLOv5的检测头部由多个卷积层组成,用于预测目标的边界框和类别。
- 样本分配策略:YOLOv5使用IoU阈值来分配正负样本,以平衡正负样本的数量。
- Loss:包含分类损失(BCEWithLogitsLoss)、定位损失(BCEWithLogitsLoss)、置信度损失(GIOU)。

YOLOv8架构特点:
- Backbone:
- 相同:CSP的思想(/梯度分流);并且使用SPPF模块
- 不同:将C3模块替换为C2f模块
- PAN/FPN:
- 相同:PAN的思想
- 不同:删除了YOLOv5中PAN-FPN上采样的CBS 1*1,将C3模块替换为C2f模块
- Head:Decoupled head + Anchor-free
- 样本分配策略:采用了TAL(Task Alignment Learning)动态匹配
- Loss:
- 相同:分类损失依然采用 BCE Los
- 不同:1)舍去物体的置信度损失;2)回归分支loss: CIOU loss+Distribution Focal Loss
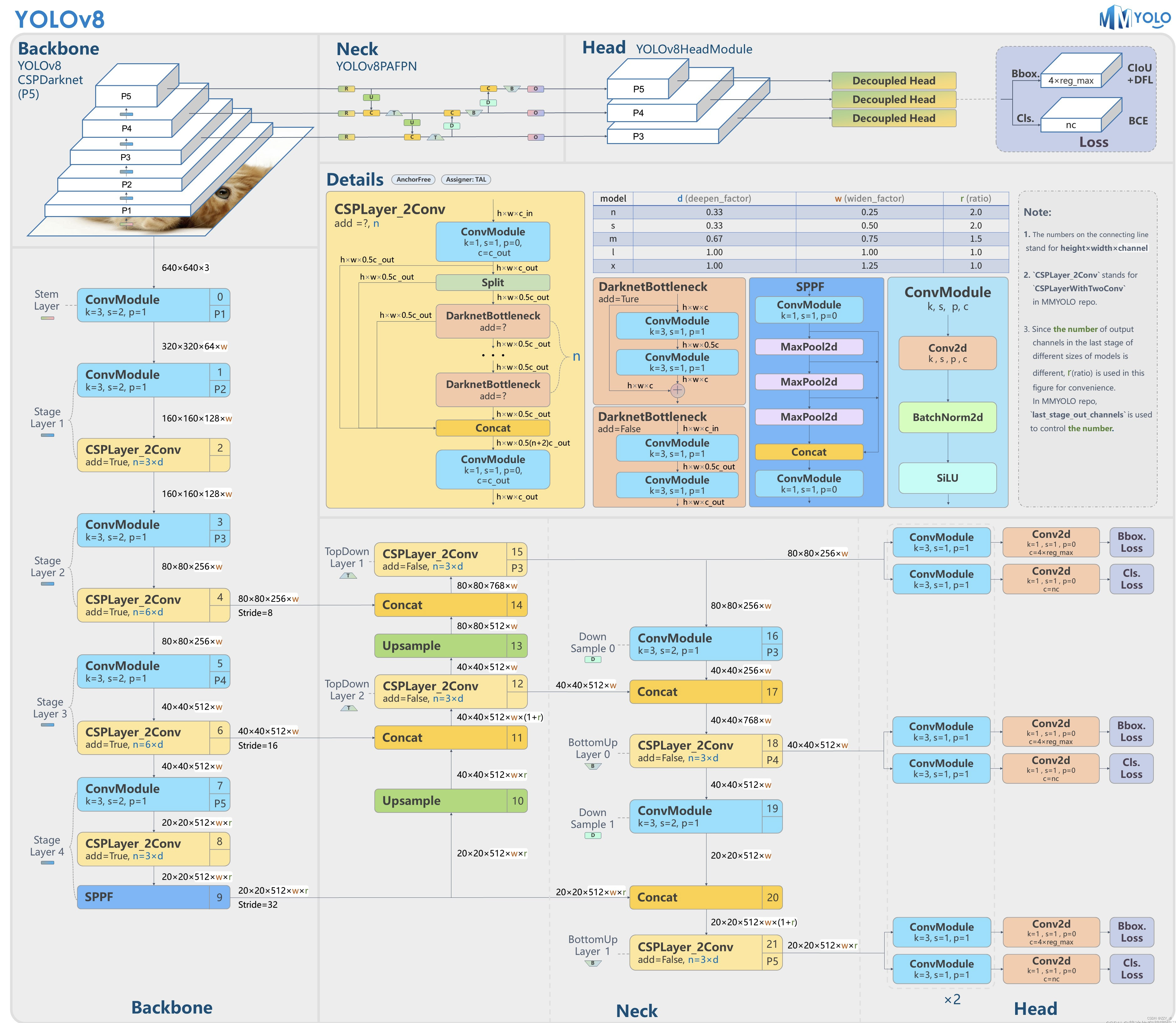
两者推理过程的区别:在推理过程中,YOLOv5和YOLOv8的主要差异在于coupled head和decoupled head的使用。coupled head是YOLOv5中的一种推理方式,它将Distribution Focal Loss中的积分表示bbox形式进行解码,变成常规的4维度bbox,然后进行后续计算。而decoupled head是YOLOv8中的一种推理方式,它直接使用Distribution Focal Loss中的积分表示bbox形式进行计算,不需要解码过程。
总结起来,YOLOv5和YOLOv8在架构和推理过程上有一些差异,包括主干网络、特征融合、检测头部、正负样本分配策略和损失函数等方面的差异。其中,在推理过程中,YOLOv5使用coupled head进行bbox解码,而YOLOv8使用decoupled head直接计算积分表示bbox。
四、模型训练、评估和推理🎄
4.1 数据集介绍🎈
本文使用的口罩数据集共包含7959张图片,分为两大类别,分别是**[no_mask, mask],本文实验训练集6367张,验证集1592张**。部分数据集及标注可视化信息如下:

图片数据集的存放格式如下,在项目目录中新建datasets目录,同时将YOLO格式数据集images和labels放入指定目录下,然后修改”yolov8\my_file\object_detection\dataset_cfg”下的mask.yaml文件中的path路径指向datasets文件夹(绝对路径)。
datasets:
- images
- train(此文件夹全是图片)
- val(此文件夹全是图片)
- labels
- train(此文件夹全是txt文件)
- val(此文件夹全是txt文件)
4.2 模型训练🎈
数据准备完成后,通过调用detection_train.py文件进行模型训练,data参数用于加载数据集的配置文件,epochs参数用于调整训练的轮数,workers参数用于调整系统的并发能力,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
import os
from ultralytics import YOLO
current_path = os.path.dirname(os.path.realpath(__file__))
root_path = os.path.abspath(os.path.join(current_path, "../..")) + "/"
# Load a mode
model = YOLO(root_path + 'ultralytics/cfg/models/v8/yolov8s.yaml').load(
root_path + 'weights/det/yolov8s.pt')
if __name__ == '__main__':
results = model.train(data=root_path + 'my_file/object_detection/dataset_cfg/mask.yaml', epochs=100, imgsz=416, batch=32, workers=16, lr0=0.01, amp=False, project=root_path+"runs/det")
4.3 结果评估🎈
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况,避免过拟合和欠拟合现象。YOLOv8训练过程及结果文件保存在runs/det/目录下,我们可以在训练结束后进行查看,结果如下所示:


4.4 模型推理🎈
模型训练结束后,我们可在runs/det/目录下可以得到一个最新且最佳的训练结果模型best.pt文件,在runs/det/train/weights目录下。我们可使用该文件进行后续的推理检测。

图片推理代码如下:
import os
from ultralytics import YOLO
current_path = os.path.dirname(os.path.realpath(__file__))
root_path = os.path.abspath(os.path.join(current_path, "../.."))+"/"
model = YOLO(root_path + 'runs/det/train/weights/best.pt') # load a custom trained# Export the model
if __name__ == '__main__':
# 可自行选择想要检测的图片,如这里的bus.jpg
model.predict(root_path + 'ultralytics/assets/bus.jpg', save=True, imgsz=416, conf=0.5)

五、项目完整目录及获取方式介绍🎄
5.1 项目完整目录🎈
本文涉及到的完整的程序文件:包括环境配置文档说明(训练和系统环境都适用)、模型训练源码、数据集、系统完整代码、系统UI文件、测试图片视频等,获取方式见文末。


5.2 项目获取方式🎈
面包多获取链接:https://mbd.pub/o/bread/ZZualZZx
5.3 作者介绍🎈
哈喽大家好, AI应用视界工作室致力于深入探索人工智能算法与应用开发的交互,涵盖目标分类、检测、分割、跟踪、人脸识别等关键领域,以及系统架构的创新设计与实现。我们的目标是为广大人工智能研究者提供一个丰富、权威的参考资源,同时也期待与您共同交流,推动人工智能技术的进步。如有相关算法交流学习和技术需求,请关注下方公众号(或者搜索 AI-designer66)可与我们取得联系。



















 2576
2576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











