







FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访 问的。 所以C库当中的FILE结构体内部,必定封装了fd。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
const char *msg0="hello printf\n";
const char *msg1="hello fwrite\n";
const char *msg2="hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}运行结果
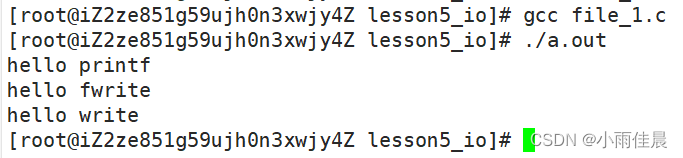
fwrite函数
size_t fwrite(const void *ptr, size, size_t nmemb, FILE *stream);
参数:
ptr -- 这是指向要被写入的元素数组的指针。
size -- 这是要被写入的每个元素的大小,以字节为单位。
nmemb -- 这是元素的个数,每个元素的大小为 size 字节。
stream -- 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输出流。
返回值:
如果成功,该函数返回一个 size_t 对象,表示元素的总数,该对象是一个整型数据类型。如果该数字与 nmemb 参数不同,则会显示一个错误。
write函数
ssize_t write(int fd, const void*buf, size_t count);
参数说明:
fd:是文件描述符(write所对应的是写,即就是1)
buf:通常是一个字符串,需要写入的字符串
count:是每次写入的字节数
返回值:
成功:返回写入的字节数
失败:返回-1并设置errno
ps: 写常规文件时,write的返回值通常等于请求写的字节数count, 而向终端设备或者网络写时则不一定。
但如果对进程实现输出重定向呢? ./hello > file , 我们发现结果变成了:
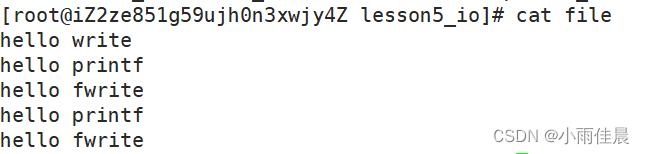
我们发现 printf 和 fwrite (库函数)都输出了2次,而 write 只输出了一次(系统调用)。为什么呢?肯定和 fork有关!
一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据 的缓冲方式由行缓冲变成了全缓冲。
而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
但是进程退出之后,会统一刷新,写入文件当中。
但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的 一份数据,随即产生两份数据。
write 没有变化,说明没有所谓的缓冲。
综上: printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。(另外,我们这里所说的缓冲区, 都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。)
那这个缓冲区谁提供呢?
printf fwrite 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统 调用的“封装”,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是 C,所以由C标准库提供。
理解文件系统
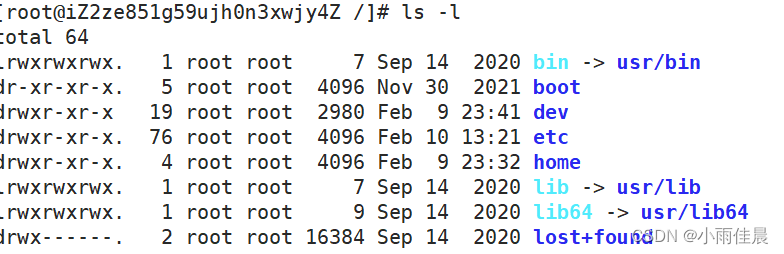
我们使用ls -l的时候看到的除了看到文件名,还看到了文件元数据。
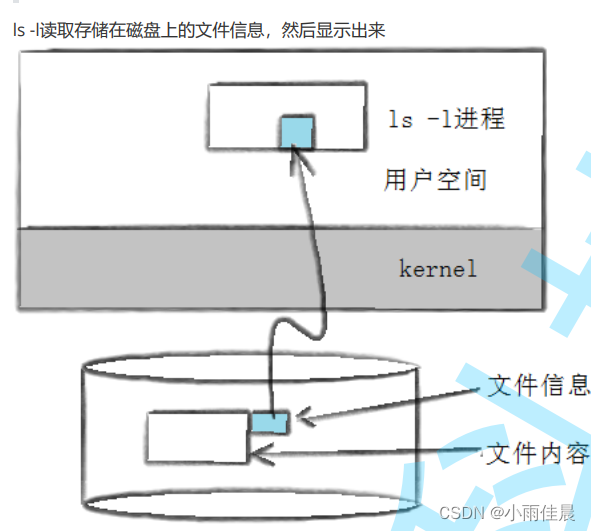
进程退出的时候,会刷新FILE内部的数据到OS缓冲区
用户 ---> OS:
刷新策略:
1.立即刷新(不缓冲)
2.行刷新(行缓冲\n)比如,显示器打印
3.缓冲区满了,才刷新(全缓冲)比如,往磁盘文件中写入
注:OS ---> 硬件 同样适用
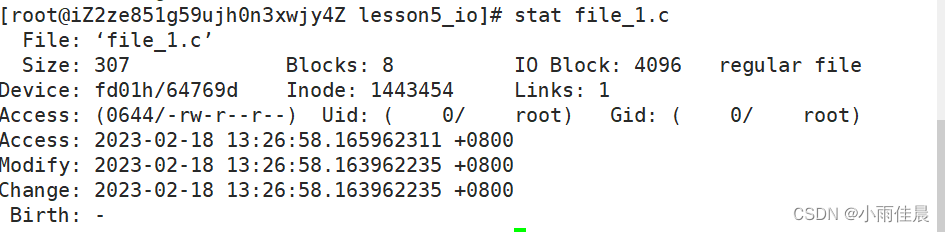
stat命令
信息解释:
inode:为了能解释清楚inode我们先简单了解一下文件系统
Linux 文件名在系统层面没有意义 是给用户使用的
Linux中 真正标识一个文件 是通过文件的inode编号
一个文件一个inode
struct inode{ //文件所以的属性 文件的大小 文件的类型 文件的权限等 //数据 int inode_number int blocks[32]; //当有硬链接增加时 ref++ int ref; } //根据映射关系获得数据块 //如果空间不够 可以在上一个数据块中放入下一个数据块的地址形成数据链表结构
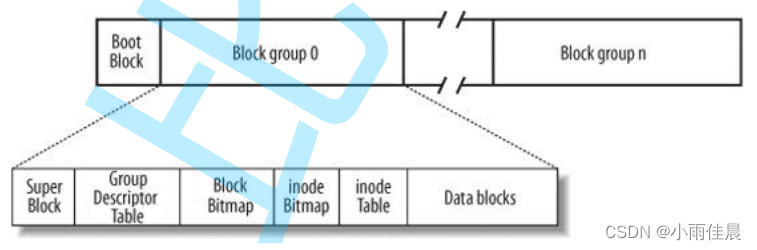
如何查找数据块是否被使用 / 数据块如何分配?
inode Bitmap 位图 0000 1010
从右向左
比特位的位置含义:inode编号
比特位的内容含义:inode是否被占用
Block Bitmap 文件中的各种块的使用情况
Group Descriptor Table 描述这个组的块使用情况
Super Block 描述整个分区的块使用情况

目录是文件吗? 是的 //一切皆文件
目录有自己的inode 放置目录的 大小 创建时间等
目录有数据吗? 有的
所创建的所有文件都存放在一个特定的目录下
文件名 --------映射------> inode编号
创建/打印文件 过程:
cat hello.c ---> 先查看文件夹 ---> data block ---> 12345 : hello.c ---> inode table ---> inode ---> blocks[] ---> 打印文件内容
删除文件 过程:
修改 inode Bitmap
将所有用到的数据块属性进行修改 数据不用删除被后面数据进行覆盖
软/硬链接
//建立软链接 特别像windows下的快捷方式
ln -s log.txt log.s
//建立硬链接
ln log.txt log.s
//软链接有自己独立的inode 软连接是一个独立的文件
//有自己的inode属性 也有自己的数据块(保存的是指向文件所在的路径+文件名)
//硬链接本质不是一个独立的文件 而是一个文件名和inode编号的映射关系
//没有自己的inode 创建硬链接本质是在特定的目录下 填写一对文件名和inode的映射关系
文件对应的硬链接数 保存位置:inode结构体中 ref
目录的硬链接数默认为 2
















 1869
1869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









