







文章目录
一. C++11 背景故事
在 2003 年 C++ 标准委员会曾经提交了一份技术勘误表(简称TC1),使得 C++03 这个名字已经取代了 C++98,成为 C++11之 前的最新 C++ 标准名称。不过由于 TC1 主要是对 C++98 标准中的漏洞进行了修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为 C++98/03 标准。从 C++0x 到 C++11,C++ 标准 10 年磨一剑,第二个真正意义上的标准珊珊来迟。相比于 C++98/03,C++11 则带来了数量可观的变化,其中包含了约 140 个新特性,以及对 C++03 标准中约 600 个缺陷的修正,这使得 C++11 更像是从 C++98/03 中孕育出的一种新语言。相比较而言,C++11 能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率。
背景故事:1998 年是 C++ 标准委员会成立的第一年,本来计划以后每 5 年时间需要更新一次标准,C++ 国际标准委员会在研究 C++03 的下一个版本的时候,一开始计划是 2007 年发布,所以最初这个标准叫 C++ 07。但是到 06 年的时候,官方觉得 2007 年肯定完不成 C++ 07,而且官方觉得 2008 年可能也完不成。最后干脆叫 C++0x。x 的意思是不知道到底能在 07 、08 还是 09 年完成。结果 2010 年的时候也没完成,最后在 2011 年终于完成了 C++ 标准的更新。所以最终定名为 C++11。
C++11 的介绍文档:https://en.cppreference.com/w/cpp/11
二. C++11 中对 { } 功能的扩展
背景:C++98 中的初始化问题
在 C++98 中,标准允许使用花括号 { } 对数组或者结构体元素进行统一的列表初始值设定。比如:
struct Point
{
int _x;
int _y;
};
int main()
{
int array1[] = { 1, 2, 3, 4, 5 };
int array2[5] = { 0 };// 数组元素全部初始化为0
int arr3[5] = {};// 数组元素全部初始化为0
Point p = { 1, 2 };
return 0;
}
但是对于一些非内置数据类型,却无法使用这样的初始化。比如下面对 vector 对象的初始化,在 C++98 中下面的例子就无法通过编译,导致每次使用 vector 时,都需要先把 vector 对象定义出来,然后再使用循环对其赋初始值,非常不方便:
// 在 C++98 中编译不通过
vector<int> v = {1,2,3,4,5};
扩展一:对内置类型和 STL 容器的 { } 初始化和赋值
int main()
{
// 内置类型变量(初始化 + 赋值 都可以用{})
int x1{ 10 };
int x2 = { 10 };
x2 = { x1 };
// error:x2{ x1 };
// STL容器(初始化 + 赋值 都可以用{})
vector<int> v1{ 1,2,3,4,5 };
vector<int> v2 = { 1,2,3,4,5 };
v2 = { 6, 7, 8, 9, 10 };
// error:v2{ 6, 7, 8, 9, 10 };
// 静态数组(初始化时可以用花括号)
int arr1[5]{ 1,2,3,4,5 };
int arr1[5] = { 1,2,3,4,5 };
// 动态数组(初始化时可以用花括号,但不能使用=)
int* arr1 = new int[5]{ 0 };
int* arr2 = new int[5]{ 1,2,3,4,5 };
// error:int* arr2 = new int[5] = {1,2,3,4,5};
return 0;
}
可以看到 C++11 中对 { } 的使用进行了扩展:对内置类型和 STL 容器可以灵活的使用 { } 进行初始化和赋值
扩展二:使用 { } 对自定义类型对象进行初始化和赋值
在 C++11 中,也可以使用 { } 完成自定义类型对象的初始化和赋值:
class Point
{
public:
Point(int x, int y)
: _x(x)
, _y(y)
{}
private:
int _x;
int _y;
};
int main()
{
Point p1 = { 1, 2 };
Point p2 = { 3, 4 };
p1 = { p2 };
return 0;
}
扩展三: initializer_list
有没有注意到 vector 类型的对象在初始化和赋值时 { } 中可以放入任意数量的对象,这个是怎么实现的呢?

{ } 中所有传入的参数其实都是被一个initializer_list类型的对象给接收了:

我们使用的 { } 列表本质上就是一个 initializer_list 对象:
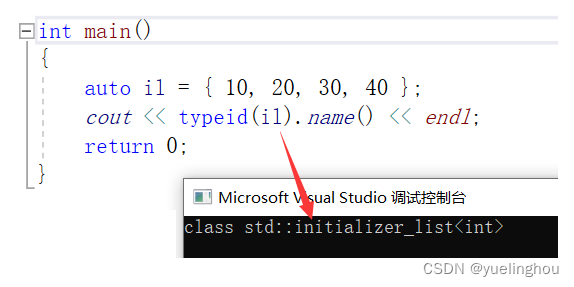
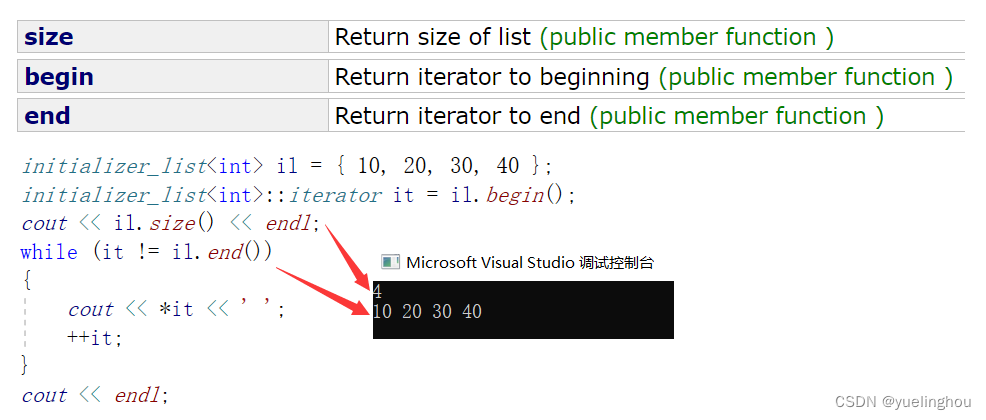
initializer_list 是系统定义的模板类,该模板类中主要有三个方法:begin()、end() 以及获取元素个数的方法 size():
关于构造函数,在文档中只给了一个构造空列表的方法:
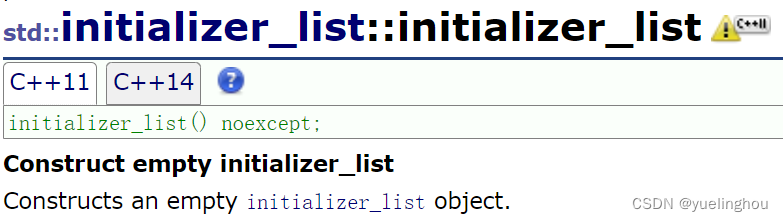
那就奇怪了,initializer_list 没有类似initializer_list(int, int, int, ...)这样去构造无限个元素的构造函数,那么类似于 initializer_list< int > la{10, 20, 30, 40, 50}; 的构造是怎么完成的呢?
initializer_list 初始化原理
下面是 initializer_list 类的实现:
template<class _Elem>
class initializer_list
{ // list of pointers to elements
public:
typedef _Elem value_type;
typedef const _Elem& reference;
typedef const _Elem& const_reference;
typedef size_t size_type;
typedef const _Elem* iterator;
typedef const _Elem* const_iterator;
constexpr initializer_list() noexcept
: _First(nullptr), _Last(nullptr)
{
// empty list
}
constexpr initializer_list(const _Elem *_First_arg,
const _Elem *_Last_arg) noexcept
: _First(_First_arg), _Last(_Last_arg)
{
// construct with pointers
}
_NODISCARD constexpr const _Elem * begin() const noexcept
{
// get beginning of list
return (_First);
}
_NODISCARD constexpr const _Elem * end() const noexcept
{
// get end of list
return (_Last);
}
_NODISCARD constexpr size_t size() const noexcept
{
// get length of list
return (static_cast<size_t>(_Last - _First));
}
private:
const _Elem *_First;
const _Elem *_Last;
};
观察构造函数的实现代码,并不能直接得到我们想要的答案。推测可能是编译器对 initializer_list 模板类的构造函数做了特别的处理,接下来我们去看看 la 对象初始的反汇编代码:
initializer_list<int> la{ 10, 20, 30, 40, 50 };
00007FF75D28188D mov edx,10h
00007FF75D281892 lea rcx,[la]
00007FF75D281896 call std::initializer_list<int>::__autoclassinit2 (07FF75D2811F9h)
00007FF75D28189B mov dword ptr [rbp+38h],0Ah
00007FF75D2818A2 mov dword ptr [rbp+3Ch],14h
00007FF75D2818A9 mov dword ptr [rbp+40h],1Eh
00007FF75D2818B0 mov dword ptr [rbp+44h],28h
00007FF75D2818B7 mov dword ptr [rbp+48h],32h
00007FF75D2818BE lea rax,[rbp+4Ch]
00007FF75D2818C2 mov r8,rax
00007FF75D2818C5 lea rdx,[rbp+38h]
00007FF75D2818C9 lea rcx,[la]
00007FF75D2818CD call std::initializer_list<int>::initializer_list<int> (07FF75D281384h)
推测 initializer_list 底层构造原理为:
- 先在栈上面分配一个数组。
- 取到数组第一个元素和最后一个元素的下一个位置的地址(rbp+38h 和 rbp+4Ch)。
- 通过这两个地址去调用构造函数
initializer_list(const _Elem *_First_arg, const _Elem *_Last_arg) noexcept完成对象的初始化。
initializer_list 的应用
std::initializer_list 一般是作为构造函数的参数去使用的,C++11 对 STL 中的不少容器增加 std::initializer_list 作为参数的构造函数,这样初始化容器对象就更方便了。当然 initializer_list 也可以作为 operator= 的参数,这样就可以通过 { } 列表给已经存在的对象赋值了:

下面我们去模拟实现 std::vector 中,参数为 initializer_list< T > 对象的构造函数和赋值运算负重载函数:
template<class T>
class vector
{
public:
typedef T* iterator;
vector(initializer_list<T> li)
{
_start = new T[li.size()];
_finish = _start + li.size();
_endofstorage = _start + li.size();
iterator vit = _start;
typename initializer_list<T>::iterator lit = li.begin();
while (lit != li.end())
{
*vit++ = *lit++;
}
}
vector<T>& operator=(initializer_list<T> li)
{
// 移动拷贝
std::swap(_start, li._start);
std::swap(_finish, li._finish);
std::swap(_endofstorage, li._endofstorage);
return *this;
}
private:
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _endofstorage = nullptr;
};
三. 变量类型推导
1. auto
为什么需要类型推导?
在 C/C++ 中定义变量时,必须先给出变量的实际类型,然后编译器会根据这个类型去给变量开空间,最后编译器才能把顺利这个变量给定义出来。但有些情况下,我们可能不知道实际需要类型是什么,或者某些类型写起来特别复杂,比如:
#include <map>
#include <string>
int main()
{
// 场景一:如果给成 short,会造成数据丢失
// 如果能够让编译器根据 a+b 的结果推导 c 的实际类型,就不会存在问题
short a = 32670;
short b = 32670;
short c = a + b;
// 场景二:使用迭代器遍历容器, 迭代器类型太复杂
std::map<std::string, std::string> m{{"apple", "苹果"}, {"banana","香蕉"}};
std::map<std::string, std::string>::iterator it = m.begin();
while(it != m.end())
{
cout<< it->first << " " << it->second << endl;
++it;
}
return 0;
}
在 C++98 中,auto 是一个存储类型的说明符,表明变量是局部自动存储类型,但是在局部域中定义的变量默认就是自动存储类型,所以 auto 就没什么价值了。C++11 中废弃了 auto 原来的用法,将其改为自动类型推导,这样就要求 auto 变量必须进行显示初始化,使用 auto 定义的变量会根据初始值自动识别变量的类型,编译器在编译期间会将 auto 替换为变量实际的类型:
#include <iostream>
#include <typeinfo>
using namespace std;
int main()
{
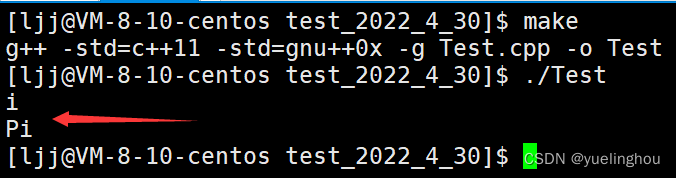
auto i = 10;
auto p = &i;
cout << typeid(i).name() << endl;
cout << typeid(p).name() << endl;
return 0;
}
编译运行:
auto使用注意事项
- 我们可以在 auto 的前面手动加上 const 使变量具有常属性;也可以在 auto 后面手动加上 & 代表引用某个变量。
- auto 会识别出变量的常属性和变量是否是指针类型。
- auto 不能作为形参、函数返回值和数组元素的类型。
- auto 使用的前提是:必须要对 auto 声明的变量进行初始化,否则编译器没有任何依据去推导出 auto 的实际类型。
范围for
auto 在实际中最常见的用法就是搭配 C++11 提供的 “范围for” 一起使用。
对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此 C++11 中引入了基于范围的 for循环(简称范围for)。
for循环括号中的内容由冒号“ :”分为两部分:
- 第一部分是范围内用于迭代的变量
- 第二部分则表示被迭代的范围
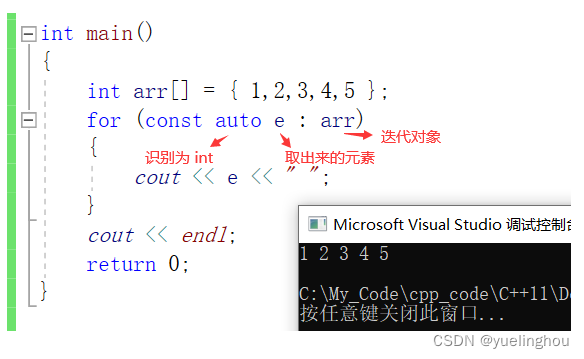
范围for的几点注意事项
- 支持迭代器,且它的元素可以进行 ++、== 操作的类,它实例化出来的对象都可以使用范围for去遍历自己的元素。
- 与普通循环一样,可以用 continue 来结束本次循环直接跳入下一次循环,也可以使用 break 来跳出整个循环。
- 建议如果不修改元素的值的话就在 auto 前面加上 const。
- 如果元素类型是基本类型(int、char 等等)就没必要使用 auto& 去接收元素;但元素类型涉及到深拷贝的类型的话最好还是通过引用来接收,这样可以减少拷贝;另外如果想要修改元素的值也需要传引用。
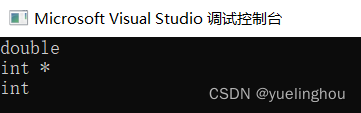
2. decltype
关键字 decltype 可以识别变量或表达式的类型,其返回值可以用来定义变量,且还可以通过 typeid 打印出来。
// decltype 的一些使用使用场景
template<class T1, class T2>
void F(T1 t1, T2 t2)
{
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}
int main()
{
int x = 1;
double y = 2.2;
decltype(x * y) ret;
decltype(&x) p;
cout << typeid(ret).name() << endl;
cout << typeid(p).name() << endl;
F(1, 'a');
return 0;
}
运行结果
四. 继承控制关键字
1. override 关键字
一个派生类可以重载基类的虚函数实现多态,但在重载时可能因为函数名写错或参数、返回值类型不匹配导致重载基类虚函数失败:
比如:
class A
{
public:
virtual void Func(int);
};
class B
{
public:
// 1、返回值类型不匹配导致基类虚函数失败
virtual int Func(int);
// 2、函数名不匹配导致重载基类虚函数失败
virtual void func(int);
// 3、参数类型不匹配导致重载基类虚函数失败
virtual void Func(double);
};
通常,我们在编写时不会注意到这个错误,运行时发现结果不对再回头检查时才可能找到。在 C++11 中,可以给需要实现多态的派生类的函数加上 override 关键字,明确地表示这个函数要对基类中的一个虚函数进行重写,它会检查基类虚函数和派生类中重载函数的签名是否匹配。如果签名不匹配,编译器会发出错误信息。
使用方法:在派生类中给需要重写的虚函数的参数列表后加上 override 关键字,它可以检查该虚函数是否完成了重写,若未完成则会报错:
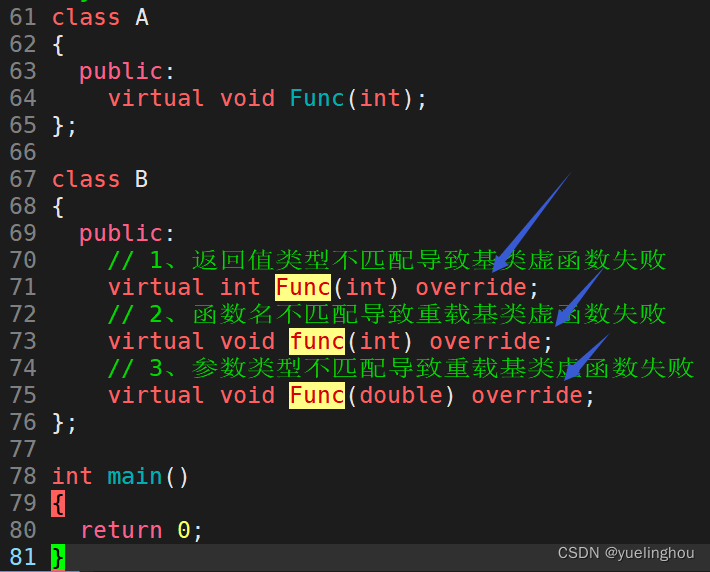
所以养成一个好的习惯,每次重写基类的虚函数时加上 override 关键字,它相当于起到一个断言的作用。
2. final 关键字
作用一:final 用来修饰类时,这个类不能被继承
在 C++98 中,如果不想让一个类被继承,需要把这个类的构造函数声明成私有,但这样做的话,就无法直接在类外创建对象了。
C++11 引入了 final 关键字,可以加在类名后面,表示这个类不能被继承:
class A final
{
public:
A()
{}
};
// error:A类不能被继承
class B : public A
{};
编译报错:

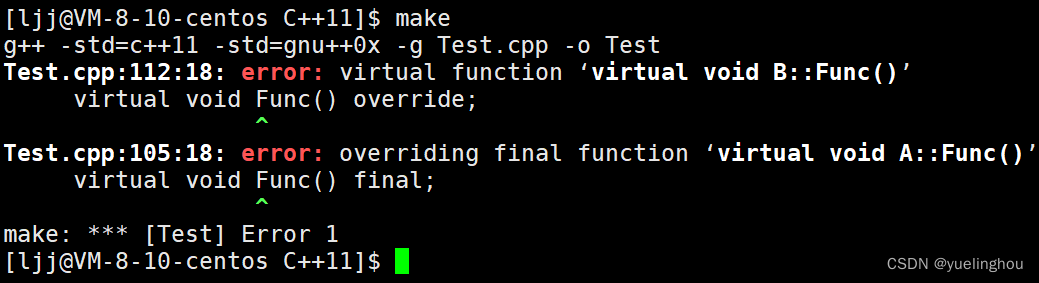
作用二:final 用来修饰虚函数时,这个虚函数不能被派生类重写
用法:在虚函数的参数列表后加 final 关键字:
class A
{
public:
virtual void Func() final;
};
class B : public A
{
public:
// error:基类的Func()函数被final修饰,不派生类允许重写
virtual void Func() override;
};
编译不通过:
五. STL 中的一些变化
用橘色圈起来是 C++11 中增加的几个新容器,但是实际最有用的还是 unordered_map 和 unordered_set:
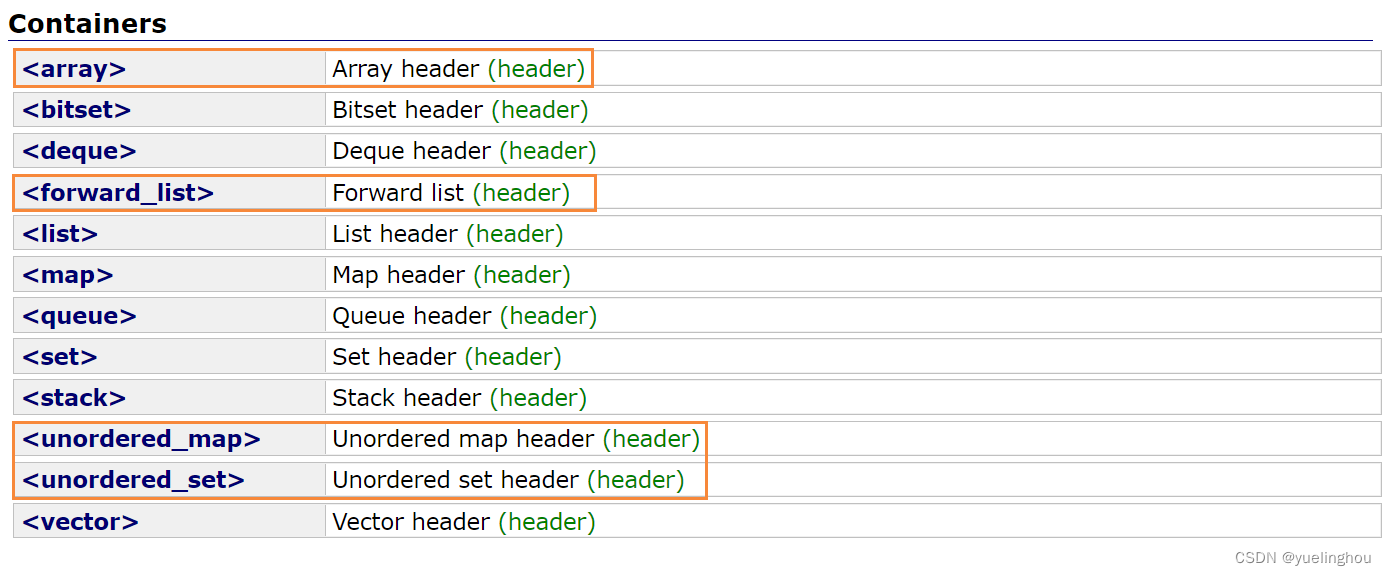
如果我们再仔细去看会发现基本每个容器中都增加了一些 C++11 相关的方法,但是其实很多都是用得比较少的。比如给容器提供了 cbegin() 和 cend() 方法用来返回 const 迭代器,但是实际意义不大,因为 begin() 和 end() 也是可以返回 const 迭代器的,这些都是属于锦上添花的操作,目的是想让我们使用迭代器时可以更加规范一点。
实际上 C++11 更新后,给容器中增加的新方法中最有用的是插入接口函数(insert、push 等)的右值引用版本:

这些接口通过右值引用和移动语义提高了效率,至于它们是如何提高效率的,后面部分讲右值引用会介绍。
1. array 容器
头文件:#include < array >
原型定义:template < class T, size_t N > class array;
容器介绍:
array 的元素是存储在栈上的,这也就决定了 array 对象存不下太多的元素。
相比较于直接用方括号定义的定长数组,array 相当于对数组进行了封装,增加了迭代器和模板以及规定了一系列特定的调用接口。
另外,被封装的 array 相比较于传统数组,它会更严格地去检查数组是否越界:
#include <array>
#include <iostream>
using namespace std;
int main()
{
array<int, 10> a1;
a1[11]; // 断言检查
a1.at(11);// 抛异常检查
int a2[10];
a2[11]; // 不检查
return 0;
}
array更多接口参考下面连接http://cplusplus.com/reference/array/array/?kw=array
2. forward_list 容器
forward_list 容器具有和 list 容器相同的特性,不过前者的结构是单链表,后者是双链表结构。
forward_list 和 list 对比:
-
单链表只能从前向后遍历,而不支持反向遍历,因此 forward_list 只提供前向迭代器,而不是双向迭代器。
-
插入节点时,forward_list 是在 pos 的后面位置插入,list 是在 pos 的前面位置进行插入;删除节点时,forward_list 也只能删除 pos 后面的节点

-
存储相同个数的同类型元素时,forward_list 使用的内存空间更少,因为单链表每个节点内部相较于双链表的节点要少一个指针变量。
-
forward_list 头插和头删的效率要比 list 更高,因为前者结构更简单。
forward_list 的相关接口:http://cplusplus.com/reference/forward_list/forward_list/?kw=forward_list
3. unordered 系列容器
主要是 unordered_set 和 unordered_map 这两个容器。它们的底层是哈希桶,增删查改的效率为 O(1)。
unordered系列容器的相关接口:unordered_map、unordered_set。
六. 默认成员函数控制
在 C++ 中编译器会生成一些默认的成员函数,比如:构造函数、拷贝构造函数、析构函数、赋值运算符重载、取地址运算符重载 和 const 取地址运算符重载。这六个成员函数我们如果在类中自己定义了,那么编译器将不会再提供成默认版本。
1. 恢复默认成员函数的关键字 — default
假如你想使用某个默认的函数,但是因为一些原因这个函数没有默认的版本。比如:我们自定义了拷贝构造,这时编译器就不会再生成默认的构造函数了:

此时我们可以使用 default 关键字去要求编译器恢复它的默认构造函数:

2. 禁用默认成员函数的关键字 — delete
如果能想要限制某些默认函数的生成:
- 在 C++98 中,只需该函数设置成 private,这样只要其他人想要调用就会报错。
- 在 C++11 中则更简单,只需在该函数声明的最后加上 =delete 即可,该语法指示编译器不生成对应函数的默认版本,称“=delete”修饰的函数为被删除函数。
class A
{
public:
// 禁止编译器生成的默认构造函数
A() = delete;
// 禁止编译器生成的默认拷贝构造函数
A(const A& a) = delete;
// 禁止编译器生成的默认赋值重载函数
A& operator=(const A&) = delete;
};
七. 右值引用与移动语义
传统 C++ 语法中就有引用的语法,而 C++11 中则新增了特定对右值进行引用的语法,无论左值引用还是右值引用。
1. 认识左值引用和右值引用
什么是左值?什么是左值引用?
我们自己创建的变量都属于左值。
左值具有如下三个特征:
- 可以取地址
- 一般情况下它的值可以修改(但被 const 修饰的左值不能修改)
- 既可以出现在 = 的左边,也可以出现在 = 的右边
示例:对右值进行引用(类型 + &)
#include <iostream>
using namespace std;
int main()
{
// 以下的 p、b、c 都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 对左值进行左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}
什么是右值?什么是右值引用?
右值分为纯右值和将亡值:
- 纯右值:字面常量、表达式返回值
- 将亡值:临时变量、匿名对象
右值具有以下三个特性:
- 不能取地址
- 不能修改
- 不能出现在 = 的左边,只能出现在右边
示例:对右值进行引用(类型 + &&)
#include <iostream>
using namespace std;
int main()
{
int x = 10, y = 20;
// 1、对纯右值进行右值引用
int&& r1 = 10;
int&& r2 = x + y;
// 2、对将亡值进行右值引用
int&& r3 = Add(x, y);
int&& r4 = int(30);
return 0;
}
需要注意:右值是不能取地址的

但是给右值取别名后,会导致右值被存储到特定位置,这时这个右值可以被取到地址,并且可以被修改,如果不想让被引用的右值被修改,可以用 const 修饰右值引用。

2. 左值引用和右值引用的联系
左值引用总结
- 左值引用只能引用左值,不能引用右值。
- 但是 const 左值引用既可以引用左值,也可以引用右值。
int main()
{
// 通常情况:左值引用只能引用左值,不能引用右值
int a = 10;
int& ra1 = a; // 编译通过,ra1为左值a的引用
int& ra2 = 10; // 编译失败,不能引用右值
// 特殊情况:const左值引用既可引用左值,也可引用右值。
const int& ra3 = 10; // 编译通过
const int& ra4 = a; // 编译通过
return 0;
}
补充:const 左值引用之所以能引用右值是因为:权限只能缩小不能放大
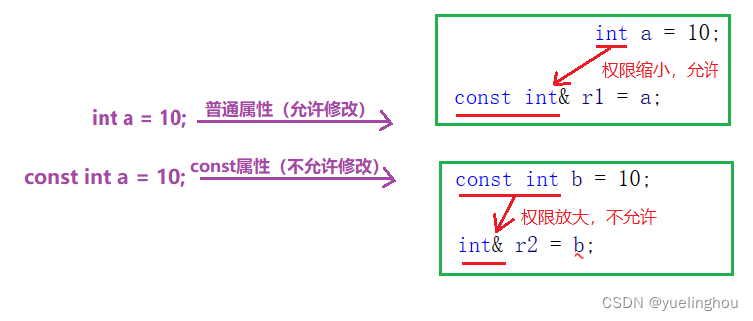
右值引用总结
- 右值引用只能引用右值,不能引用左值。
- 但是右值引用可以引用 move 以后的左值。
int main()
{
// 通常情况:右值引用只能引用右值,不能引用左值
int a = 10;
int&& r1 = 10;// 编译通过,r1为纯右值 10 的引用
int&& r2 = a; // 编译失败,无法引用左值
// 特殊情况:右值引用可以引用 move 以后的左值
int&& r3 = std::move(a);
return 0;
}
补充:当需要用右值引用引用一个左值时,可以通过 move 函数将左值转化为右值。C++11 中,std::move() 函数位于头文件"utility"中。该函数的名字具有迷惑性,它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义。
3. 右值引用使用场景
前面我们可以看到左值引用既可以引用左值和又可以引用右值,那为什么 C++11 还要提出右值引用呢?
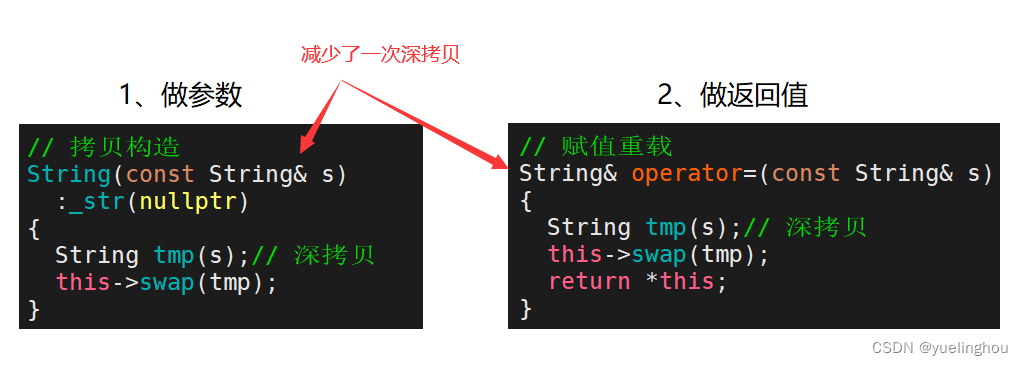
3.1 左值引用使用场景:作为形参和返回值
在传参或传返回值时减少一次拷贝
3.2 右值引用使用场景一:提供移动构造
对于有些函数,它的返回值必须是传值返回,这样外部调用该函数时,通过拷贝构造一个对象来接收返回值,整个返回和接收的过程难免要进行深拷贝,这是左值引用无能为力的:

这里有没有什么办法能够避免拷贝构造里的深拷贝呢?如果我们要拷贝的对象是个右值,那么它在拷贝完成后会被自动销毁,能否不去深拷贝这个将亡的右值,而是直接把它的内存空间交换过来,达到一个移动拷贝的效果,来提高拷贝的效率:
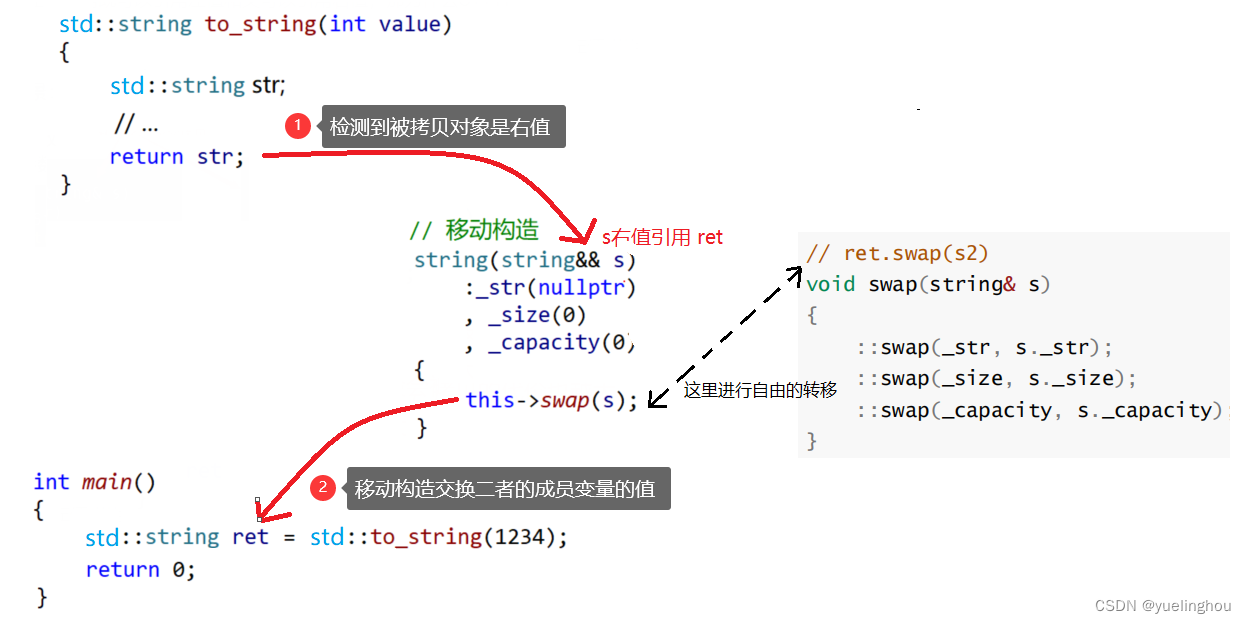
PS:拷贝构造定义一个新对象时,如果被拷贝对象是左值则调用拷贝构造函数;如果该被拷贝对象是右值,则调用移动构造函数。移动构造不用进行深拷贝,效率比起拷贝构造函数高得多。
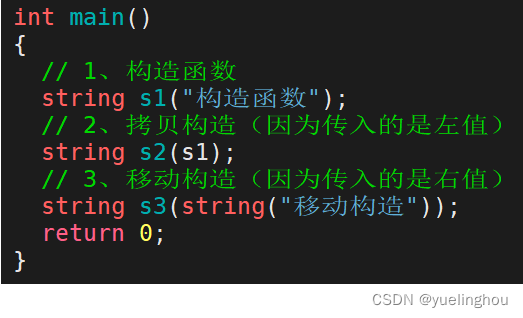
在 C++11 中,部分STL容器增加了移动构造: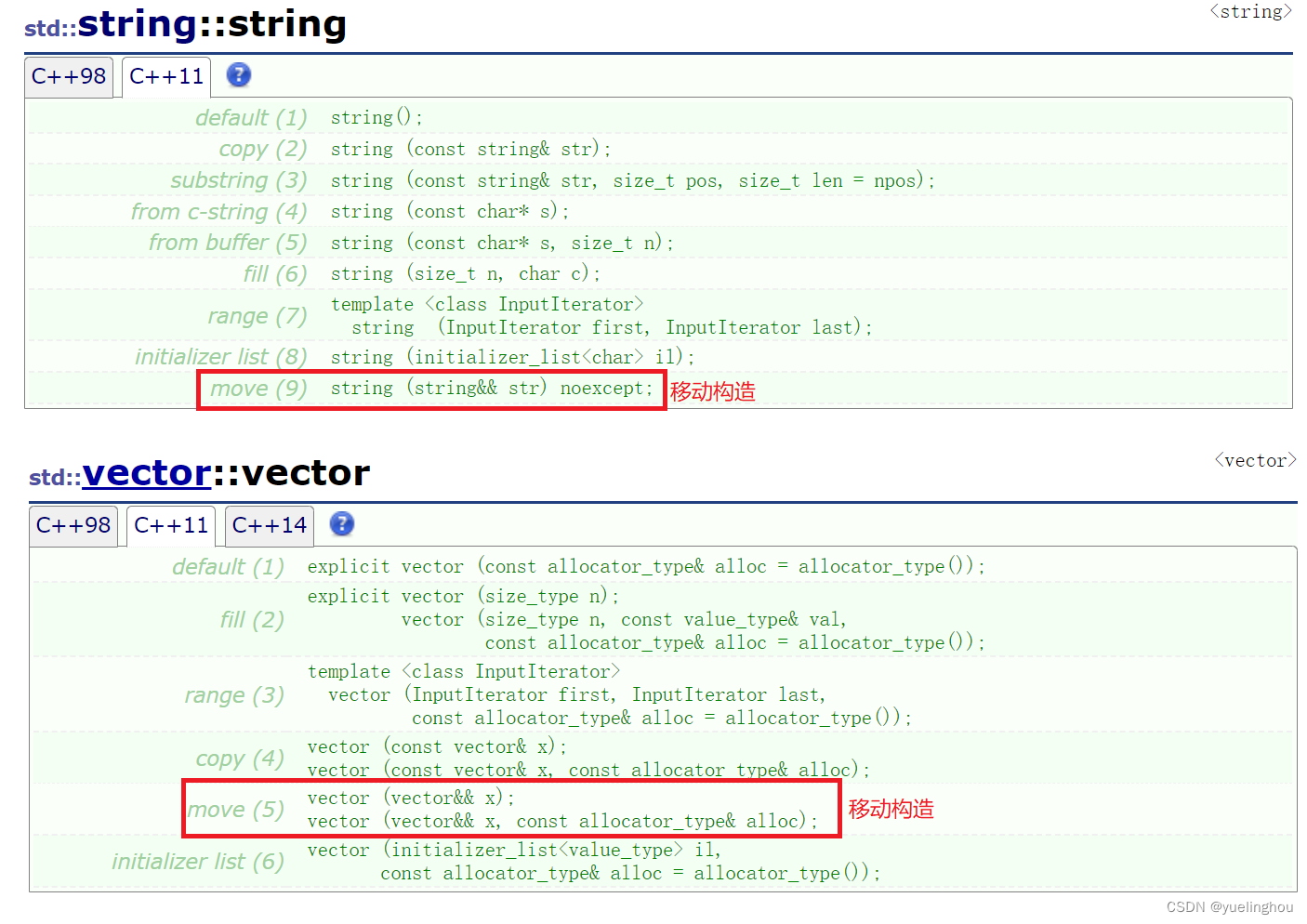
3.3 右值引用使用场景二:提供移动赋值
- 前面说过,在一次函数调用中,如果出现连续构造,编译器会优化为只进行一次构造。
- 如果我们不是用右值去构造一个新对象,而是用右值去赋值一个已经存在的对象,那么在赋值过程中也有深拷贝,这个深拷贝能否被优化呢?
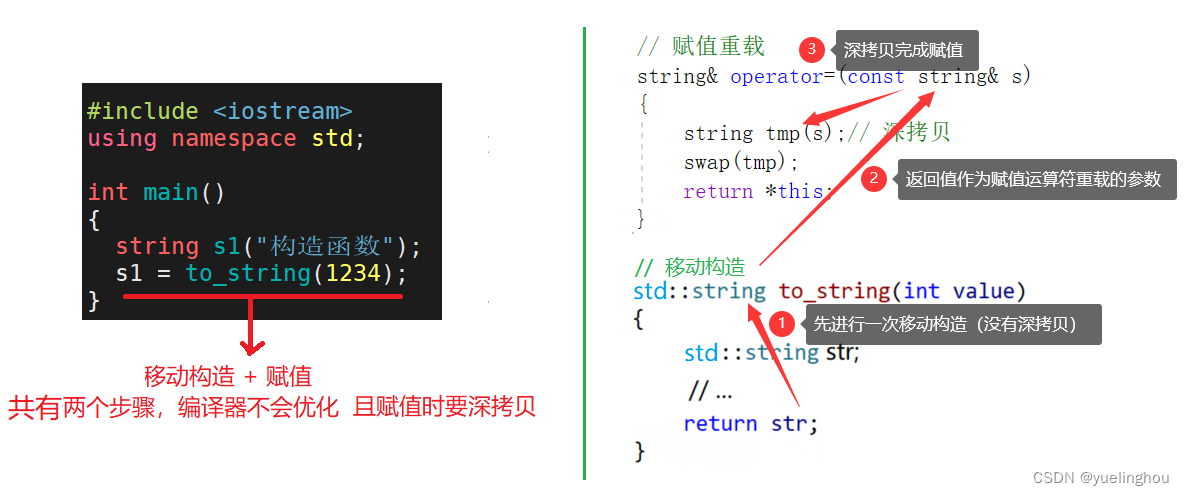
借鉴前面移动拷贝的思路,实现一个针对参数为右值的移动赋值:

PS:在对象进行赋值操作时,如果等号右边是左值(即已经定义出来的对象),则需进行深拷贝来完成赋值操作;如果等号右边是右值的话,就调用资源转移的移动赋值函数,避免深拷贝,提高效率。

同样,C++11 对STL中的部分容器也增加了移动赋值:
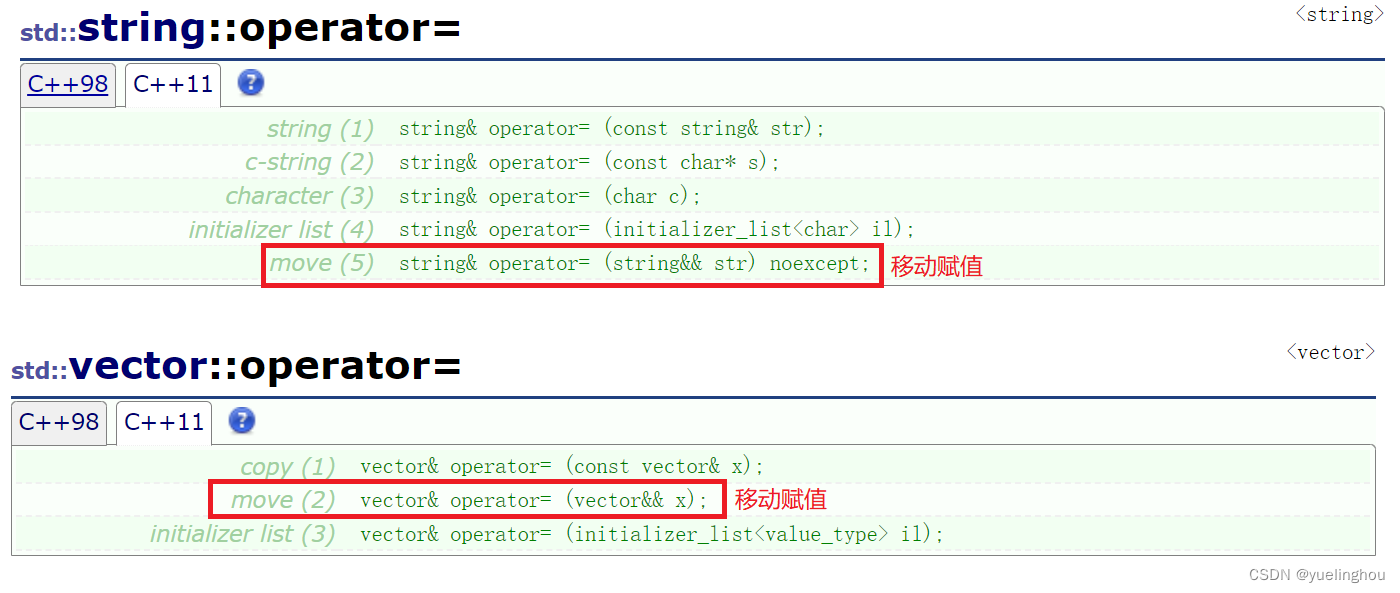
3.4 右值引用使用场景二:提供插入右值的接口函数
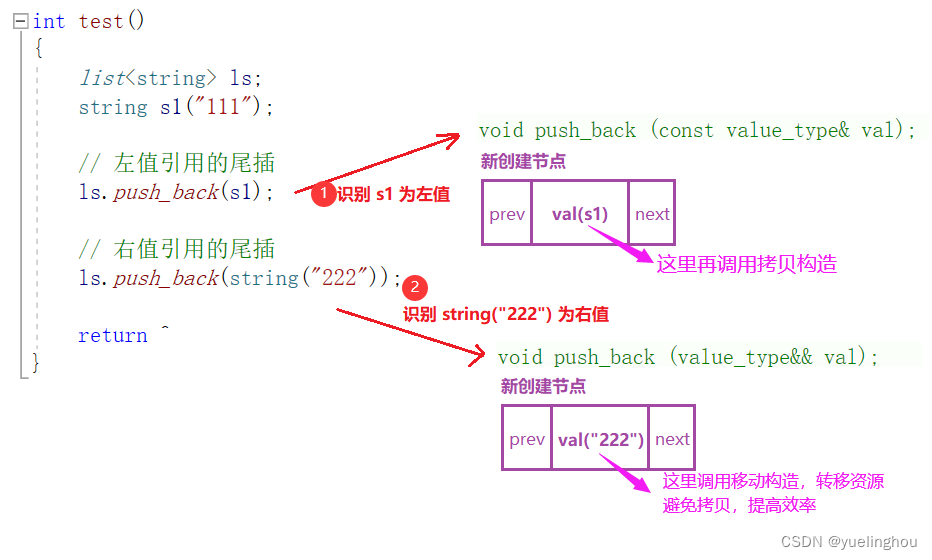
除了移动拷贝和移动赋值外,右值引用还可以使用在容器插入数据的接口函数中,如果插入的参数是右值,则可以转移它的资源,避免深拷贝,提高效率。

示例:
4. 右值引用总结
右值引用本质:把右值的资源进行转移,避免深拷贝,提高效率
右值引用的使用场景:移动构造、移动赋值、为容器提供右值引用的插入接口
else:

5. move 实现左值的资源转移
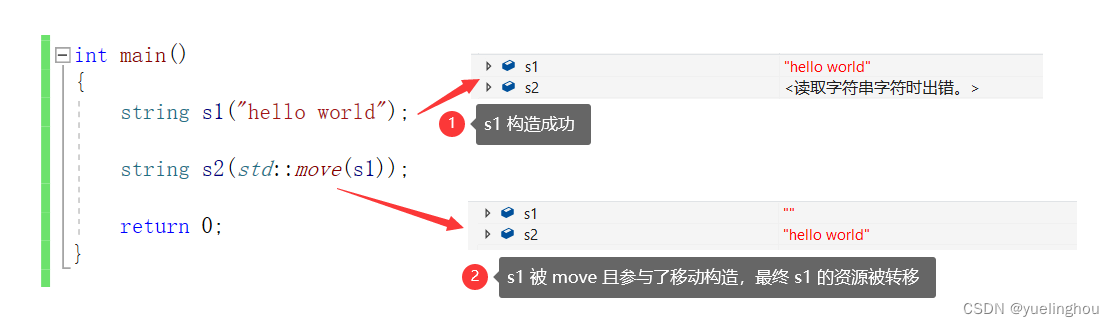
按照语法,右值引用只能引用右值,但右值引用一定不能引用左值吗?有些场景下,可能真的需要用右值去引用左值实现移动语义。当需要用右值引用引用一个左值时,可以通过std::move(左值对象),将左值转化为右值。

在 C++11 中,std::move(…) 函数位于头文件 < utility > 中,该函数名字具有迷惑性,它其实并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用。如果 move 后的左值参与了移动拷贝或移动赋值的话,这个左值的资源将会被转移出去。
6. 完美转发
6.1 万能引用
- 在模板中
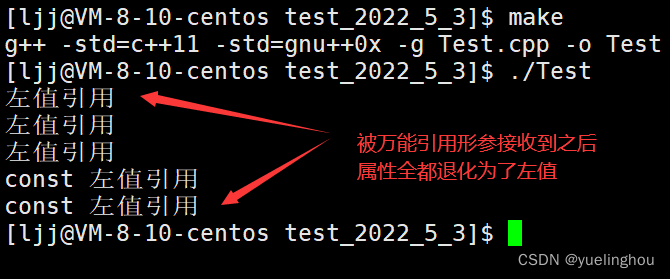
类型&&不再代表右值引用,而是万能引用,其既能接收左值又能接收右值。 - 模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值。
#include <iostream>
using namespace std;
void Fun(int &x){ cout << "左值引用" << endl; }
void Fun(const int &x){ cout << "const 左值引用" << endl; }
void Fun(int &&x){ cout << "右值引用" << endl; }
void Fun(const int &&x){ cout << "const 右值引用" << endl; }
// 函数模板
template<typename T>
void PerfectForward(T&& t)
{
// t是万能引用,它即能够接收左值引用和右值引用
// t实际接收到了实参之后统一都退化成了左值引用
Fun(t);
}
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
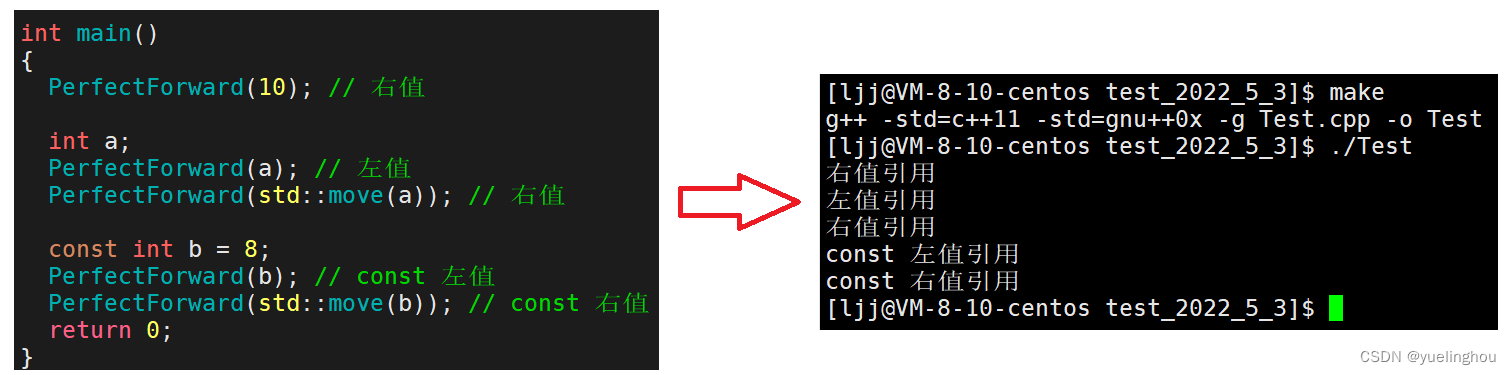
编译运行,发现各种不同属性的实参传入模板函数void PerfectForward(T&& t)后,能够被万能引用的形参 t 接受到,但是接收到之后它们都退化成了左值,原本的属性被丢失:
外面实参的右值属性传给万能引用形参后,属性被丢失。因为万能引用接收到右值后,系统会为万能引用对象在内存上开辟一块空间来存储它的值,这时万能引用对象也就可以取到地址,右值属性被丢失。
我们希望能够在传递过程中保持它的左值或者右值的属性, 就需要用我们下面学习的完美转发。
6.2 完美转发
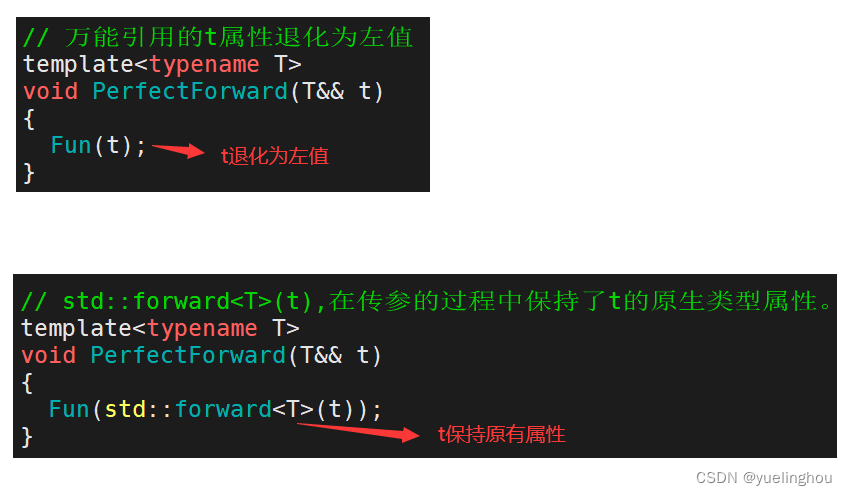
为了解决上面的问题,C++11 提供了一个叫做完美转发的函数模板forward,,其定义如下:
我们只需把万能引用对象传入到 forward 中,即可实现完美转发:
接下来我们让 PerfectForward 函数中的万能引用对象 t 通过完美转发传给 Fun() 函数,看 t 的属性是否还正确保留:
#include <iostream>
using namespace std;
void Fun(int &x){ cout << "左值引用" << endl; }
void Fun(const int &x){ cout << "const 左值引用" << endl; }
void Fun(int &&x){ cout << "右值引用" << endl; }
void Fun(const int &&x){ cout << "const 右值引用" << endl; }
// std::forward<T>(t),在传参的过程中保持了t的原生类型属性。
template<typename T>
void PerfectForward(T&& t)
{
Fun(std::forward<T>(t));
}
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
编译运行,结果正确:
八. 新的类功能
1. 新增默认成员函数
原来 C++ 类中,有6个默认成员函数(默认成员函数就是我们不写编译器会自己生成一个默认的):
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
PS:这六个默认成员函数中,最重要的是前4个,后两个用处不大。
在 C++11 中又新增了两个默认成员函数:移动构造函数和移动赋值重载,它们默认生成的规则如下:
- 如果你没有自己实现移动构造函数,且析构函数 、拷贝构造、拷贝赋值重载也都没有实现。那么编译器会自动生成一个默认移动构造函数。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
- 如果你没有自己实现移动赋值重载函数,且析构函数 、拷贝构造、拷贝赋值重载也都没有实现,那么编译器会自动生成一个默认的移动赋值重载。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)。
- 如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值
2. 给成员变量设置缺省值
C++11 允许在类中给成员变量设置缺省值,默认构造函数会优先使用这些缺省值去初始化这个成员变量,然后再进行初始化列表的初始化。
class Date
{
public:
// 默认构造函数
Date()
:_day(10)
{}
// 打印成员变量的值
void Print()
{
cout << _year << '.' << _month << '.' << _day << endl;
}
// 成员变量声明时给缺省值
int _year = 2023;
int _month = 5;
int _day = 5;
};
int main()
{
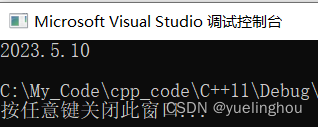
Date d;
d.Print();
return 0;
}
编译运行
:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









