






SQL场景题
1. 连续三天登录的用户
-- 建表语句
CREATE TABLE user_login
(
uuid VARCHAR(100) NOT NULL,
date DATE NOT NULL
);
-- 导入数据
INSERT INTO user_login (uuid, date)
VALUES ('1001', '2023-09-01'),
('1001', '2023-09-02'),
('1001', '2023-09-03'),
('1001', '2023-09-04'),
('1002', '2023-09-01'),
('1002', '2023-09-02'),
('1002', '2023-12-04'),
('1003', '2023-12-05'),
('1003', '2023-12-06'),
('1003', '2023-12-08'),
('1003', '2023-12-09'),
('1004', '2023-12-09'),
('1004', '2023-12-10'),
('1004', '2023-12-11');思路一:以uuid为连接条件,将表 inner join 3次,然后筛选 “第2张表比第1张表date多一天” 和 “第3张表比第2张表date多一天” 的数据,即为连续三天登录的用户。
select distinct t1.uuid
from user_login t1
left join user_login t2 on t1.uuid = t2.uuid
left join user_login t3 on t2.uuid = t3.uuid
where t1.date = date_sub(t2.date, interval 1 day)
and t2.date = date_sub(t3.date, interval 1 day);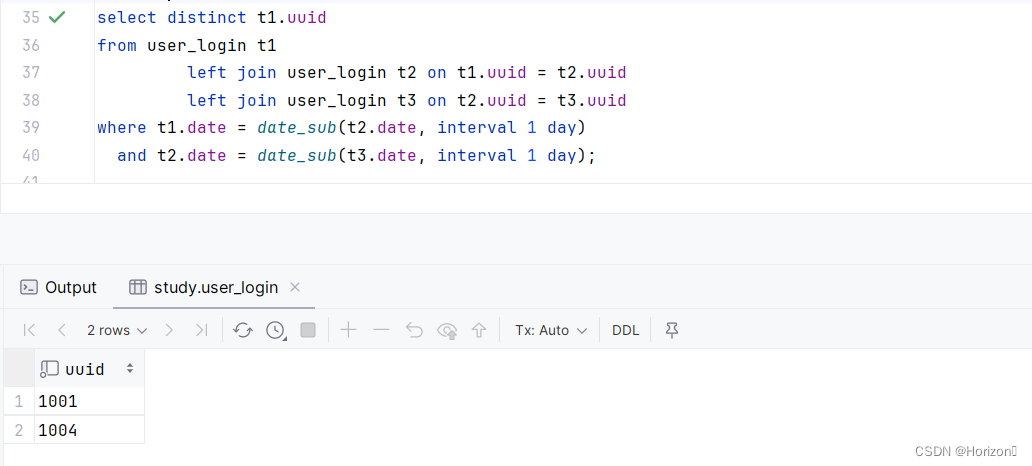
思路二:将每个用户登录数据按date升序排序,并给每个用户的时间排序;然后通过uuid和“date-序号”分组,分组的数据条数>=3的说明是连续三天登录。
select uuid,
count(*)
from (select uuid,
date,
row_number() over (partition by uuid order by date) as num
from user_login
group by uuid, date) as t1
group by uuid, date_sub(date, interval num day)
having count(*) >= 3;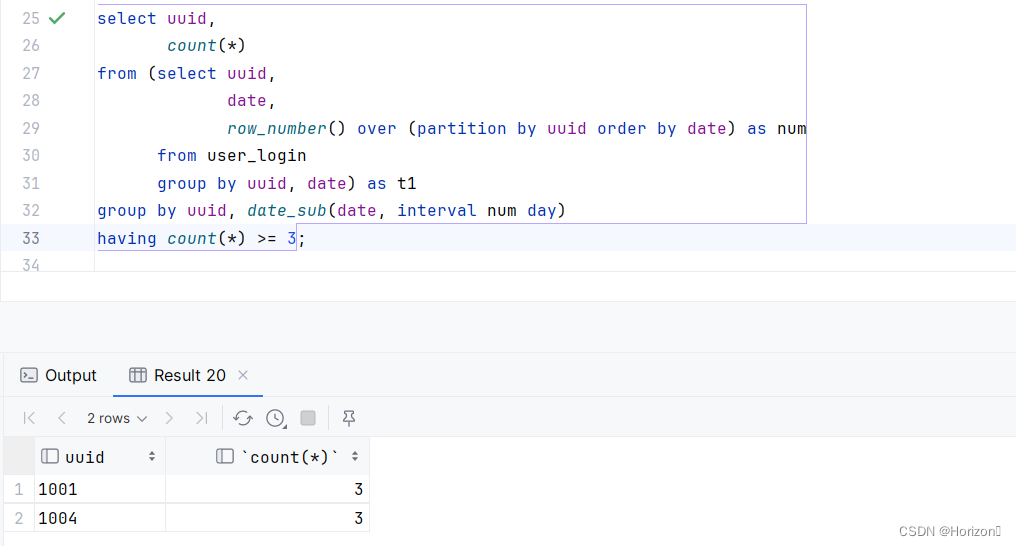
2. 五科都及格的人
少数据的科目为缺考。
-- 建表语句
CREATE TABLE user_grade
(
user VARCHAR(100) NOT NULL,
subject VARCHAR(100) NOT NULL,
grade INT NOT NULL
);
-- 导入测试数据
INSERT INTO user_grade (user, subject, grade)
VALUES ('何小存', '语文', 100),
('何小存', '数学', 90),
('何小存', '英语', 80),
('何小存', '物理', 70),
('何小存', '化学', 60),
('沈小雅', '语文', 100),
('沈小雅', '数学', 90),
('沈小雅', '英语', 80),
('沈小雅', '物理', 70),
('沈小雅', '化学', 50),
('谷小硕', '语文', 100),
('谷小硕', '数学', 90),
('谷小硕', '英语', 80),
('谷小硕', '物理', 70);思路:先筛选成绩及格的人,然后以用户分组,最后再筛选每个用户有合格的5科。主要考察在group by之后的筛选。
select count(*) as num
from (select user
from user_grade
where grade >= 60
group by user
having count(1) = 5) t1;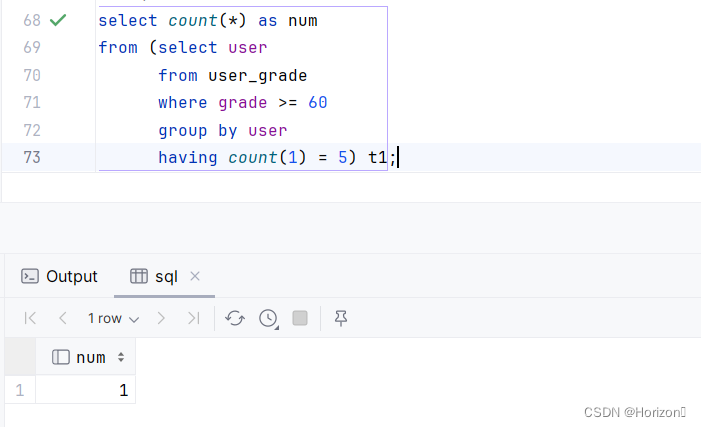
3. 每个班级数学成绩的前三名
-- 建表语句
CREATE TABLE math_grade
(
user VARCHAR(100) NOT NULL,
class VARCHAR(100) NOT NULL,
grade INT NOT NULL
);
-- 导入数据
INSERT INTO math_grade (user, class, grade)
VALUES ('A同学', '1班', 93),
('B同学', '1班', 92),
('C同学', '1班', 88),
('D同学', '1班', 91),
('H同学', '2班', 88),
('I同学', '2班', 86),
('J同学', '2班', 85),
('K同学', '2班', 85),
('L同学', '2班', 77),
('X同学', '3班', 99),
('Y同学', '3班', 98);思路:先按照班级对数学成绩降序,并给出排名;然后过滤取排名小于4的数据。
select user,
class,
grade,
row_num
from (select user,
class,
grade,
row_number() over (partition by class order by grade desc) row_num
from math_grade
group by user, class) t1
where row_num < 4;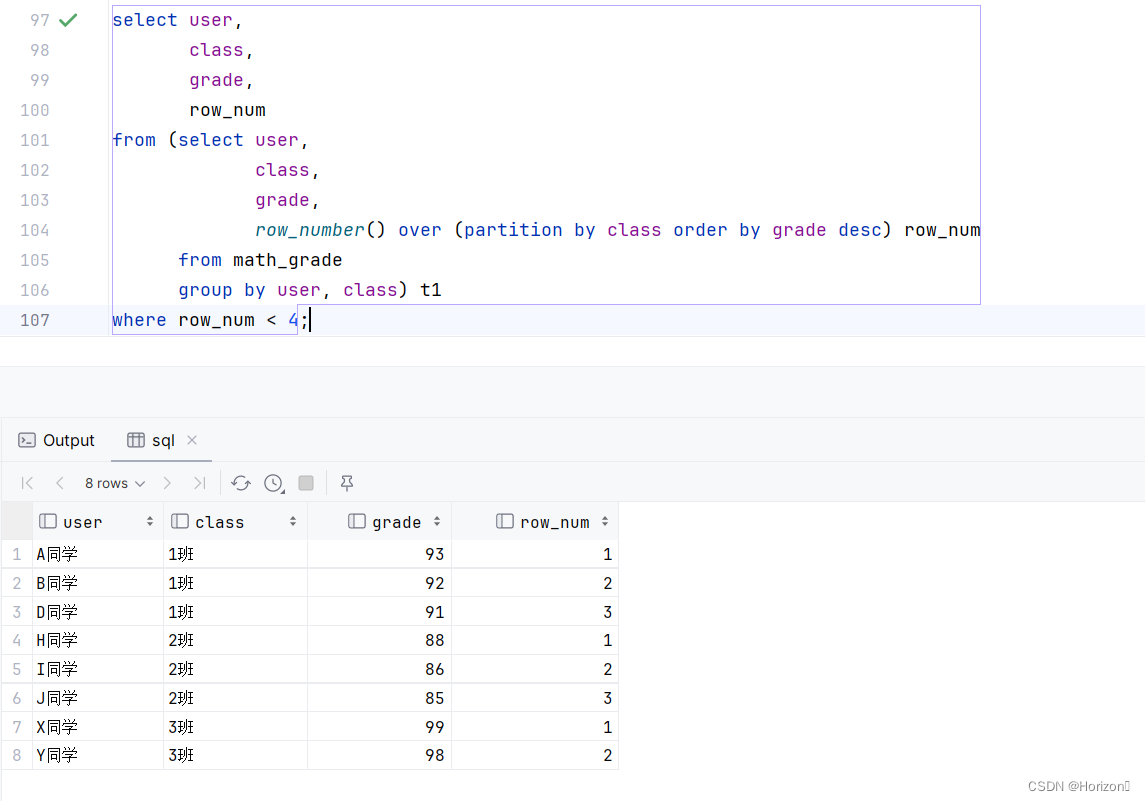
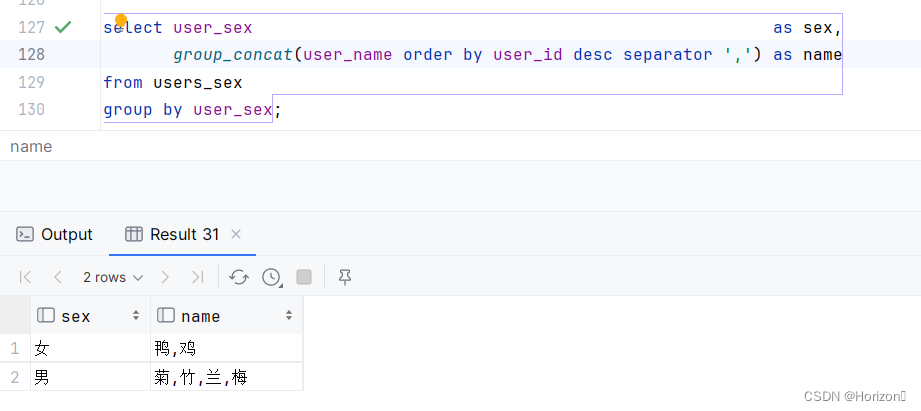
4. 基于性别字段分组,然后ID排序,最后显示各组中的所有姓名,每个姓名之间用,隔开。
-- 建表语句
CREATE TABLE users_sex
(
user_id INT PRIMARY KEY not null,
user_name VARCHAR(100),
user_sex VARCHAR(10),
password VARCHAR(100),
create_time DATETIME
);
-- 插入数据
INSERT INTO users_sex (user_id, user_name, user_sex, password, create_time)
VALUES (1, '鸡', '女', '6666', '2023-10-14 15:05:01'),
(2, '梅', '男', '1234', '2023-10-14 16:05:04'),
(3, '兰', '男', '4321', '2023-10-16 07:05:01'),
(4, '竹', '男', '8888', '2023-10-17 23:05:09'),
(8, '鸭', '女', '8888', '2023-10-27 17:05:09'),
(9, '菊', '男', '0369', '2023-10-17 23:05:09');思路:先根据性别group,但是想要取到所有的 user_id 就必须用函数 group_concat() 。
select user_sex as sex,
group_concat(user_name order by user_id desc separator ',') as name
from users_sex
group by user_sex
;















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









