







Android AudioTrack音频流播放
本文简单介绍一下音频流在AudioTrack和AudioFlinger之间的传输。
一、AudioFlinger中数据流
从PlaybackThread创建开始:
void AudioFlinger::PlaybackThread::onFirstRef()
{
run(mName, ANDROID_PRIORITY_URGENT_AUDIO);
}
在创建playbackthread类就开始启动线程了。在Android线程中threadloop为线程真正的执行体,代码实现如下:
bool AudioFlinger::PlaybackThread::threadLoop()
{
...
for(int64_t loopCount = 0; !exitPending(); ++loopCount)
{
cpuStats.sample(myName);
Vector< sp<EffectChain> > effectChains;
std::vector<sp<Track>> activeTracks;
{ // scope for mLock
Mutex::Autolock _l(mLock);
// 处理配置信息
processConfigEvents_l();
// 如果数据为0,则让声卡进入休眠状态
if ((!mActiveTracks.size() && systemTime() > standbyTime) ||
isSuspended()) {
// put audio hardware into standby after short delay
if (shouldStandby_l()) {
//声卡休眠
threadLoop_standby();
mStandby = true;
}
if (!mActiveTracks.size() && mConfigEvents.isEmpty()) {
IPCThreadState::self()->flushCommands();
//...
//线程休眠点,直到AudioTrack发送广播唤醒
mWaitWorkCV.wait(mLock);
...
continue;
}
}
activeTracks.insert(activeTracks.end(), mActiveTracks.begin(), mActiveTracks.end());
// 混音前的准备工作
mMixerStatus = prepareTracks_l(&tracksToRemove);
...
lockEffectChains_l(effectChains);
} // mLock scope ends
if (mBytesRemaining == 0) {
mCurrentWriteLength = 0;
if (mMixerStatus == MIXER_TRACKS_READY) {
// 混音
threadLoop_mix();
} else if ((mMixerStatus != MIXER_DRAIN_TRACK)
&& (mMixerStatus != MIXER_DRAIN_ALL)) {
threadLoop_sleepTime();
if (sleepTime == 0) {
mCurrentWriteLength = mSinkBufferSize;
}
}
if (mMixerBufferValid) {
void *buffer = mEffectBufferValid ? mEffectBuffer : mSinkBuffer;
audio_format_t format = mEffectBufferValid ? mEffectBufferFormat : mFormat;
//把数据从thread.mMixerBuffer复制到thread.mEffectBuffer
memcpy_by_audio_format(buffer, format, mMixerBuffer, mMixerBufferFormat,
mNormalFrameCount * mChannelCount);
}
...
}
...
if (mEffectBufferValid && !mHasDataCopiedToSinkBuffer) {
void *effectBuffer = (mType == SPATIALIZER)? mPostSpatializerBuffer : mEffectBuffer;
if(mType == SPATIALIZER && isHapticSessionSpatialized) {
const size_t srcBufferSize = mNormalFrameCount * audio_byte_per_format(
audio_channel_count_from_out_mask(mMixerChannelMask), mEffectBufferFormat);
const size_t dstBufferSize = mNormalFrameCount *
audio_byte_per_format(mChannelCount, mEffectBufferFormat);
memcpy_by_audio_format(mPostSpatializerBuffer + dstBufferSize, mEffectBufferFormat,
mEffectBuffer + srcBufferSize, mEffectBufferFormat,
mNormalFrameCount * mHapticChannelCount);
}
const size_t framesToCopy = mNormalFrameCount * (mChannelCount + mHapticChannelCount);
// 把数据从thread.mEffectBuffer复制到thread.mSinkBuffer
memcpy_by_audio_format(mSinkBuffer, mFormat, effectBuffer, mEffectBufferFormat, framesToCopy);
}
// enable changes in effect chain
unlockEffectChains(effectChains);
if (!waitingAsyncCallback()) {
// sleepTime == 0 means we must write to audio hardware
if (sleepTime == 0) {
if (mBytesRemaining) {
// 音频输出
ssize_t ret = threadLoop_write();
} else if ((mMixerStatus == MIXER_DRAIN_TRACK) ||
(mMixerStatus == MIXER_DRAIN_ALL)) {
threadLoop_drain();
}
...
} else {
usleep(sleepTime);
}
}
...
}
threadLoop_exit();
if (!mStandby) {
threadLoop_standby();
mStandby = true;
}
...
return false;
}
1.1 prepareTracks_l()函数
MixerThread::prepareTracks_l 的代码实现如下:
AudioFlinger::PlaybackThread::mixer_state AudioFlinger::MixerThread::prepareTracks_l(
Vector< sp<Track> > *tracksToRemove)
{
//默认为空闲状态
mixer_state mixerStatus = MIXER_IDLE;
size_t count = mActiveTracks.size();
...
//对于所有在mActiveTracks里面的Track,都需要进行设置
for (size_t i=0 ; i<count ; i++) {
const sp<Track> t = mActiveTracks[i];
Track* const track = t.get();
// fastTrack不会在这里进行混音,略过
if (track->isFastTrack()) {
...
}
{ // local variable scope to avoid goto warning
audio_track_cblk_t* cblk = track->cblk();
const int trackId = track->id();
if(!mAudioMixer->existd(trackId)) {
status_t status = mAudioMixer->create(trackId, track->mChannelMask,
track->mFormat, track->mSessionId);
}
size_t desiredFrames;
const uint32_t sampleRate = track->mAudioTrackServerProxy->getSampleRate();
const AudioPlaybackRate playbackRate = track->mAudioTrackServerProxy->getPlaybackRate();
desiredFrames = sourceFramesNeededWithTimestretch(sampleRate, mNormalFrameCount,
mSampleRate, playbackRate.mSpeed);
desiredFrames += mAudioMixer->getUnreleasedFrames(track->name());
uint32_t minFrames = 1;
if ((track->sharedBuffer() == 0) && !track->isStopped() && !track->isPausing() &&
(mMixerStatusIgnoringFastTracks == MIXER_TRACKS_READY)) {
minFrames = desiredFrames;
}
//混音的状态下,frameReady = 1,那么会进入下面的条件,进行AudioMixer参数设置
size_t framesReady = track->framesReady();
if ((framesReady >= minFrames) && track->isReady() &&
!track->isPaused() && !track->isTerminated())
{
//音量参数设置
...
//设置AudioMixer参数
mAudioMixer->setBufferProvider(name, track);//源Buffer
mAudioMixer->enable(name);//使能该track,可以混音
//音轨 左 右 aux
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, &vlf);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME1, &vrf);
mAudioMixer->setParameter(name, param, AudioMixer::AUXLEVEL, &vaf);
//音频格式
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::FORMAT, (void *)track->format());
//音轨mask,哪个需要或者不需要混音
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::CHANNEL_MASK, (void *)(uintptr_t)track->channelMask());
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::MIXER_CHANNEL_MASK, (void *)(uintptr_t)mChannelMask);
// limit track sample rate to 2 x output sample rate, which changes at re-configuration
uint32_t maxSampleRate = mSampleRate * AUDIO_RESAMPLER_DOWN_RATIO_MAX;
uint32_t reqSampleRate = track->mAudioTrackServerProxy->getSampleRate();
if (reqSampleRate == 0) {
reqSampleRate = mSampleRate;
} else if (reqSampleRate > maxSampleRate) {
reqSampleRate = maxSampleRate;
}
/*进行重采样
*注意:安卓的MixerThread会对所有的track进行重采样
*那么在混音的时候会调用重采样的混音方法。
*/
mAudioMixer->setParameter(
name,
AudioMixer::RESAMPLE,
AudioMixer::SAMPLE_RATE,
(void *)(uintptr_t)reqSampleRate);
if (mMixerBufferEnabled
&& (track->mainBuffer() == mSinkBuffer
|| track->mainBuffer() == mMixerBuffer)) {
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::MIXER_FORMAT, (void *)mMixerBufferFormat);
//目的buffer
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::MAIN_BUFFER, (void *)mMixerBuffer);
// TODO: override track->mainBuffer()?
mMixerBufferValid = true;
} else {
//...
}
//aux buffer
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::AUX_BUFFER, (void *)track->auxBuffer());
// reset retry count
track->mRetryCount = kMaxTrackRetries;
if (mMixerStatusIgnoringFastTracks != MIXER_TRACKS_READY ||
mixerStatus != MIXER_TRACKS_ENABLED) {
//状态为 ready表示可以混音
mixerStatus = MIXER_TRACKS_READY;
}
} else {
//...
}
} // local variable scope to avoid goto warning
track_is_ready: ;
}
//...
//从mActiveTracks删除需要移除的track
removeTracks_l(*tracksToRemove);
//...
if (fastTracks > 0) {
//正常混音准备时,这里返回的是MIXER_TRACK_READY
mixerStatus = MIXER_TRACKS_READY;
}
return mixerStatus;
}
prepareTracks_l 主要进行了:
-
确定enabled track, disabled track;
-
对于enabled track, 设置mState.tracks[x]中的参数。
1.2 threadLoop_mix()函数
在prepareTrack_l返回的mMixerStatus值为MIXER_TRACK_READY时,才可以进入threadLoop_mix进行混音。代码实现如下:
void AudioFlinger::MixerThread::threadLoop_mix()
{
//AudioMixer混音
mAudioMixer->process(pts);
//混音了多少音频数据
mCurrentWriteLength = mSinkBufferSize;
if ((sleepTime == 0) && (sleepTimeShift > 0)) {
sleepTimeShift--;
}
sleepTime = 0;
standbyTime = systemTime() + standbyDelay;
}
threadLoop_mix : 处理数据(比如重采样)、混音
-
确定hook:逐个分析mState.tracks[x]的数据, 根据它的格式确定tracks[x].hook,再确定总的mState.hook;
-
调用hook:调用总的mState.hook即可, 它会再去调用每一个mState.tracks[x].hook;
-
混音后的数据会放在mState.outputTemp临时BUFFER中;
-
然后转换格式后存入 thread.mMixerBuffer。
1.3 threadLoop_write()函数
threadLoop_write用于混音后的音频输出,代码实现如下:
ssize_t AudioFlinger::MixerThread::threadLoop_write()
{
if (mFastMixer != 0) {
//...fastMixer处理
}
return PlaybackThread::threadLoop_write();
}
继续分析PlaybackThread::threadLoop_write():
ssize_t AudioFlinger::PlaybackThread::threadLoop_write()
{
mInWrite = true;
ssize_t bytesWritten;
const size_t offset = mCurrentWriteLength - mBytesRemaining;
// If an NBAIO sink is present, use it to write the normal mixer's submix
if (mNormalSink != 0) {
ssize_t framesWritten = mNormalSink->write((char *)mSinkBuffer + offset, count);
//...
// otherwise use the HAL / AudioStreamOut directly
} else {
//如果用fastMixer的话其实会走该分支,先忽略
// Direct output and offload threads
bytesWritten = mOutput->stream->write(mOutput->stream,
(char *)mSinkBuffer + offset, mBytesRemaining);
//...
}
//...
mNumWrites++;
mInWrite = false;
mStandby = false;
return bytesWritten;//返回输出的音频数据量
}
threadLoop_write:把thread.mSinkBuffer写到声卡上
二、AudioTrack中数据流
AudioTrack有两种数据加载模式(MODE_STREAM和MODE_STATIC),对应的数据加载模式和音频流类型,对应着两种完全不同得使用场景。
-
MODE_STREAM:在这种模式下,通过write一次次把音频数据写到AudioTrack中,这中平时通过write系统调用往文件中写数据类似,但这种工作方式每次都需要把数据从用户提供得Buffer中拷贝到AudioTrack内部的Buffer中。
-
MODE_STATIC:这种模式下,在play之前只需要把所有数据通过一次write调用传递到AudioTrack中的内部缓冲区,后续就不必再传递数据了。这种模式适用于像铃声这种内存占用量较小,延时要求较高的文件。
APP写数据会调用write函数:
ssize_t AudioTrack::write(const void* buffer, size_t userSize, bool blocking)
{
if(mTransfer != TRANSFER_SYNC && mTransfer != TRANSFER_SYNC_NOTICE_CALLBACK) {
return INVALID_OPERATION;
}
...
size_t written = 0;
Buffer audioBuffer;
while(userSize >= mFrameSize) {
audioBuffer.frameCount = userSize/ mFrameSize;
// 从共享Buffer得到可写
status_t err = obtainBuffer(&audioBuffer,
blocking? &CLientProxy::kForever : &CLientProxy::kNonBlocking);
size_t toWrite = audioBuffer.size();
// 拷贝到共享Buffer
memcpy(audioBuffer.raw, buffer, toWrite);
buffer = ((const char*)buffer) + toWrite;
userSize -= toWrite;
c += toWrite;
releaseBuffer(&audioBuffer);
}
if(written > 0) {
mFramesWritten += written / mFrameSize;
// 如果为CALLBACK类型,会运行AudioTrackThread线程
if(mTransfer == TRANSFER_SYNC_NOTICE_CALLBACK) {
const sp<AudioTrackThread> t = mAudioTrackThread;
if(t != 0)
t->wake();
}
}
return written;
}
针对mTransfer为CALLBACK类型,AudioTrackThread中ThreadLoop()函数会调用到processAudioBuffer函数:
nsecs_t AudioTrack::processAudioBuffer()
{
sp<AudioTrackCallback> callback = mCallback.promote();
...
size_t writtenFrames = 0;
while (mRemainingFrames > 0) {
Buffer audioBuffer;
audioBuffer.frameCount = mRemainingFrames;
size_t nonContig;
status_t err = obtainBuffer(&audioBuffer, requested, NULL, &nonContig);
requested = &CLientProxy::kNonBlocking;
size_t avail = audioBuffer.frameCount + nonContig;
if(mRetryOnPartialBuffer && audio_has_proportional_frames(mFormat)) {
mRetryOnPartialBuffer = false;
// buffer不够,等待ns
if(avail < mRemainingFrames) {
if(ns > 0){
const nsecs_t timeNow = systemTime();
ns = max(0, ns -(timeNow - timeAfterCallback));
}
nsecs_t delayNs = framesToNanoseconds(
mRemainingFrames- avail, sampleRate, speed);
const nsecs_t afNs = framesToNanoseconds(mAfFrameCount, mAfSampleRate, speed);
if(delays < afNs) {
delays = std::min(delays, afNs / 2);
}
if(ns < 0 || delays < ns) {
ns = delays;
}
return ns;
}
}
size_t reqSize = audioBuffer.size();
// 通过callback取数据
const size_t writtenSize = (mTransfer == TRANSFER_CALLBACK)?
callback->onMoreData(audioBuffer) : callback->onCanWriteMoreData(audioBuffer);
audioBuffer.mSize = writtenSize;
size_t releasedFrames = writtenSize / mFrameSize;
audioBuffer.frameCount = releasedFrames;
mRemainingFrames -= releasedFrames;
releaseBuffer(&audioBuffer);
writtenFrames += releasedFrames;
}
mFramesWritten += writtenFrames;
mRemainingFrames = notificationFrames;
mRetryOnPartialBuffer = true;
return 0;
}
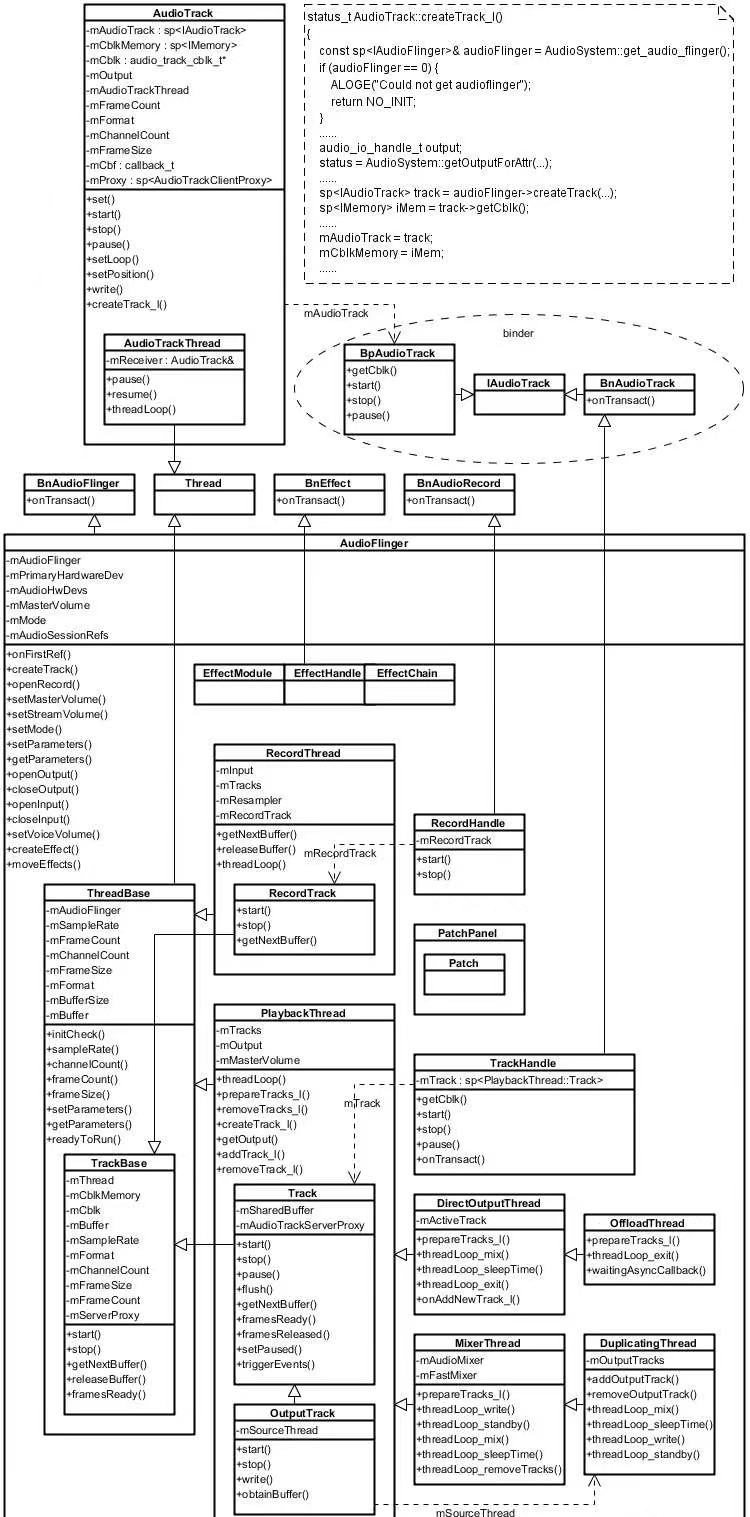
三、AudioTack与AudioFlinger关系图















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









