






Redis学习笔记<二>
一、缓存

缓存模型标准方式是在查询数据库之前先查询缓存,如果缓存数据存在,则直接返回缓存数据;如果缓存数据不存在,则查询数据库,将查询到的数据写入redis中,返回数据。
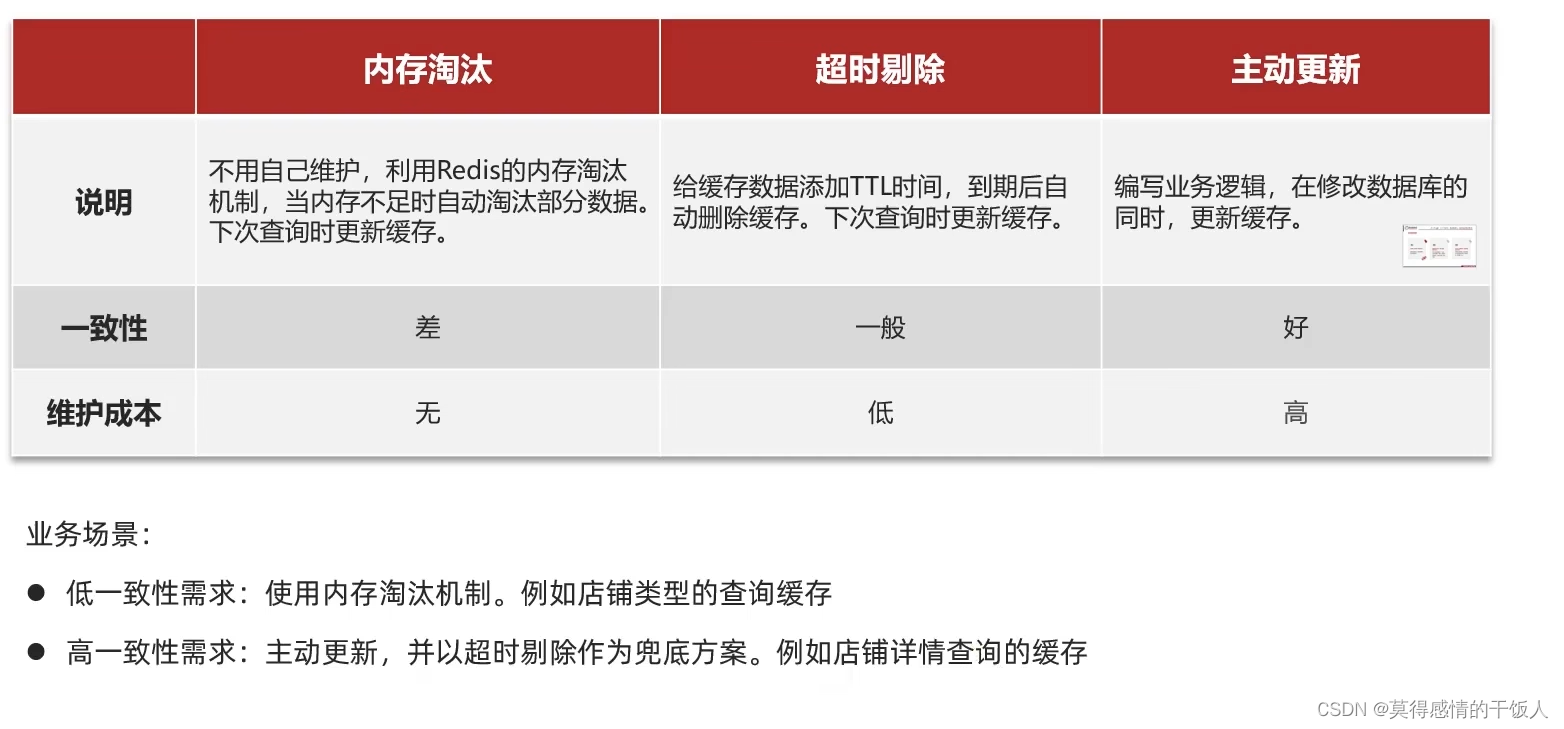
1. 缓存更新
内存淘汰策略: redis自动进行,当redis内存达到咱们设定的max-memery的时候,触发内存淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
超时剔除: 对redis缓存设置超时时间ttl,redis就会剔除过期的数据,方便我们继续使用缓存。
主动更新: 我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题。
一般来说,通常使用主动更新策略解决缓存不一致的问题
更新缓存还是删除缓存?
- 更新缓存: 每次更新数据时都要更新缓存,无效写操作太多
- 删除缓存: 更新数据库时让缓存失效,查询时再更新缓存
如何保证缓存和数据库的操作同时生效或者失败?
- 单体系统: 将缓存和数据库的操作放入同一个事务中
- 分布系统: 采用TCC等分布式事务方案
先操作数据库还是先删除缓存?
- 先操作数据库更新数据,再删除缓存
倘若先删除缓存,线程1先删除缓存,此时线程2进发现没有缓存,它就会从数据库查询;线程1进行更新数据库的操作,并将其写入redis缓存中;线程1操作完毕之后,恰好线程2查询到数据也将旧数据写入redis缓存中,这就造成了新数据被旧数据覆盖问题;
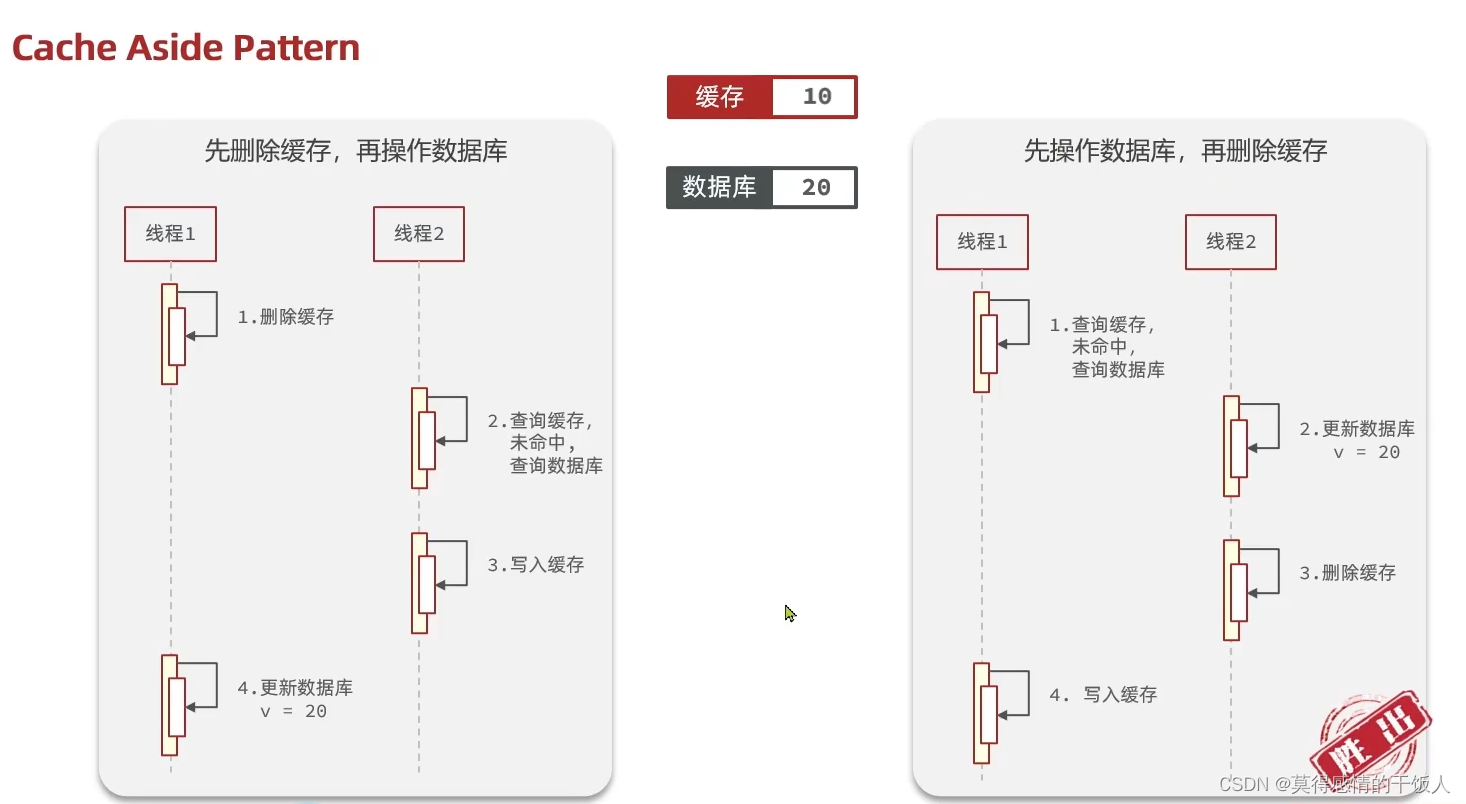
总结: 采用主动更新方案,并以超时剔除方案兜底。
2. 缓存穿透
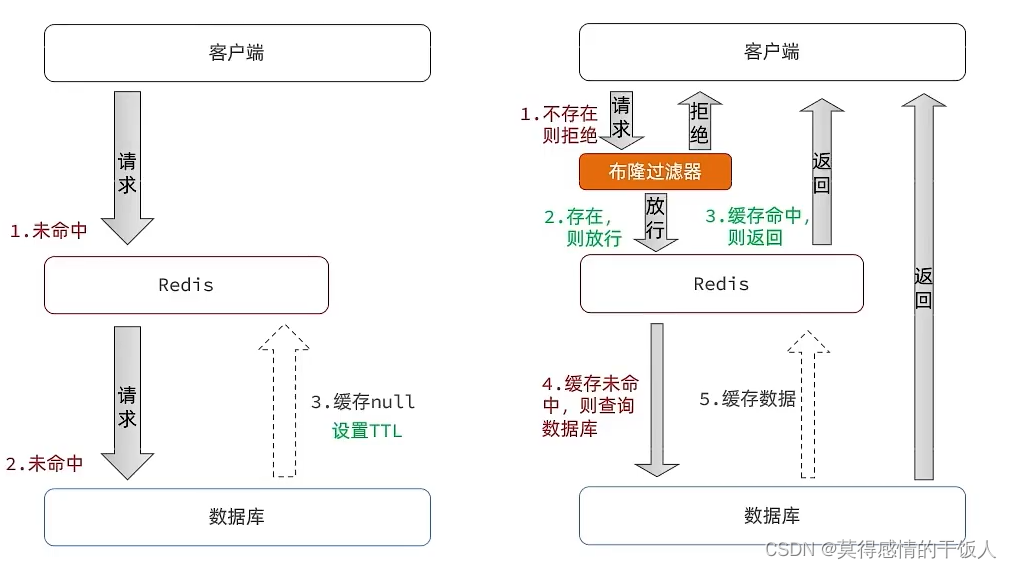
缓存穿透: 缓存穿透是指从客户端请求的数据缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会打在数据库上。
缓存穿透主要有两种解决方案:
缓存空对象: 实现简单,维护方便;但存在额外的内存消耗,以及可能造成短期的数据不一致现象。
布隆过滤: 内存占用较少,没有多余的key;但实现比较复杂并且存在误判的可能;
3. 缓存雪崩
缓存雪崩是指同一时间段内大量的缓存key同时失效或者Redis服务宕机,大量请求到达数据库服务器,带来巨大压力。
解决方案:
- 给不同的key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 添加多级缓存
4. 缓存击穿
缓存击穿也叫作热点key问题,就是一个被高并发并且缓存重建业务比较复杂key突然失效了,无数的请求给数据库带来巨大压力。
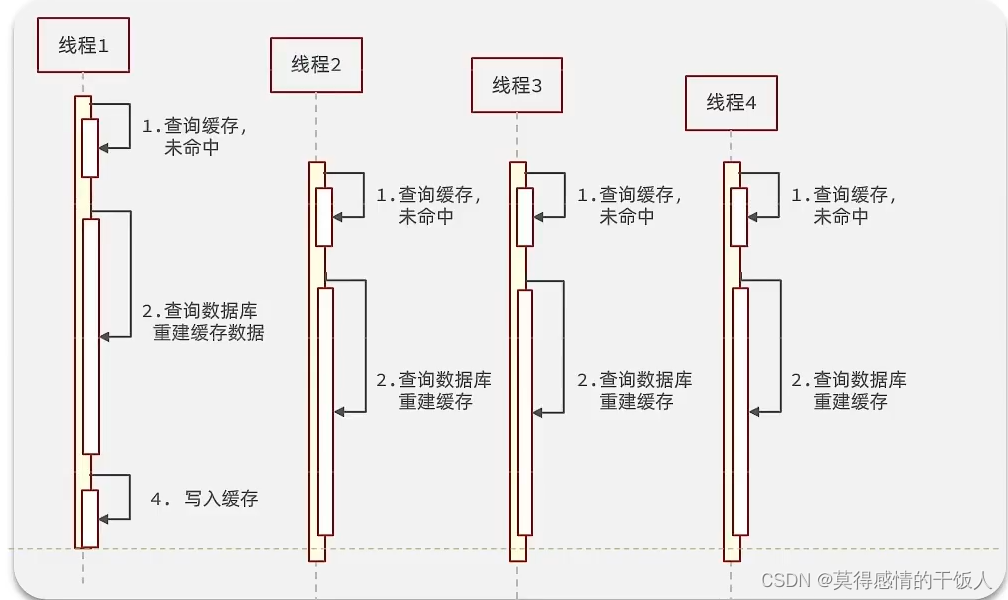
解决方案:
- 互斥锁
- 逻辑过期
互斥锁
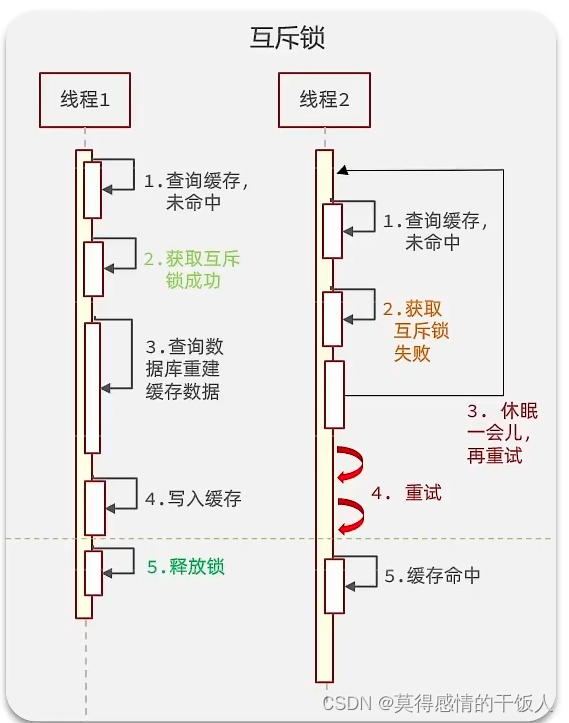
虽然能够保证数据的一致性,但是查询业务变成了串行,让只有一个线程执行操作数据库的逻辑,但是性能会受影响。
思路: 利用redis中的setnx方法来表示获取锁,即redis中如果没有指定的key,则此操作执行成功;如果有这个key,操作则会失败(获取锁失败)。需要注意的是:设置互斥锁的key时,需要设置TTL,防止造成死锁。
逻辑过期
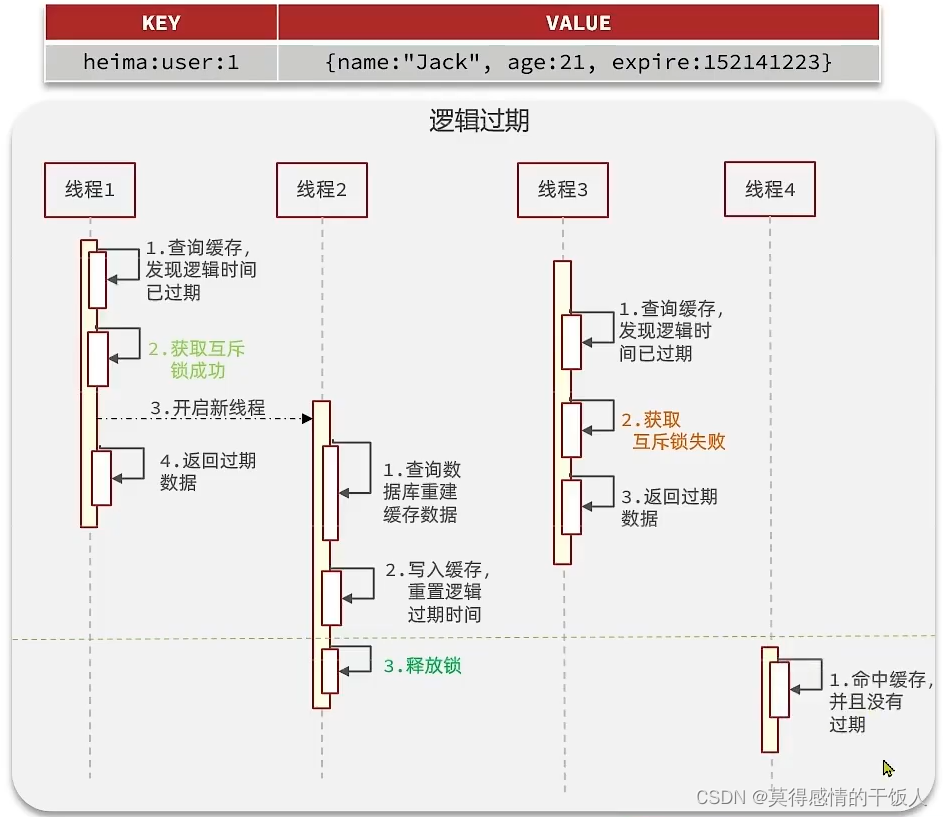
思路: 逻辑过期时间,并不是真正设置过期时间;热点key会一直存在(有时候会提前存入redis缓存中),只不过会设置一个DTO,添加一个属性来记录key的过期时间。
前期步骤使用互斥锁来保证只有一个线程进行缓存重建的任务。但是与互斥锁方案不同的是,获取锁失败的线程直接返回数据,不会阻塞等待(性能较好,但是不能够保证数据的一致性)。获取锁成功的线程,或开启一个异步线程进行缓存重建,之后它便会直接返回旧数据。缓冲重建完毕之后,便会释放锁。
性能较好,但是缓存重建之前返回的都是之前的数据,不能够保证数据一致性。
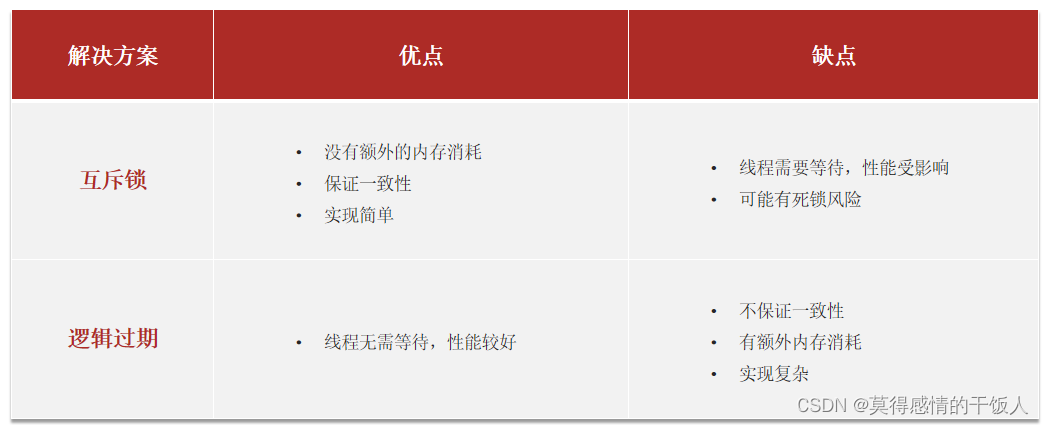
二、线程安全
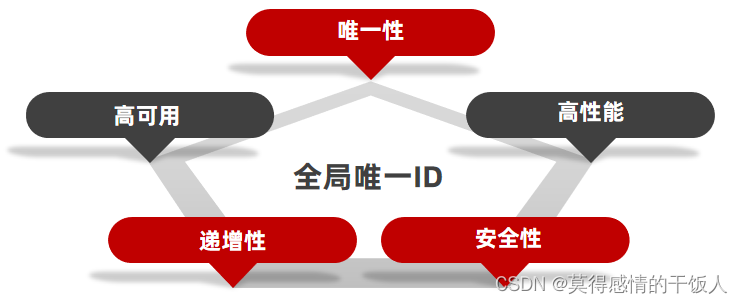
1. 全局唯一ID
全局唯一ID主要用于分布式系统下,主要有下面的几个特性:个人感觉唯一性和递增性将UUID等方法排除在外了。
可以使用Redis构建全局唯一ID生成器

ID组成部分
- 符号位:保证ID永远会是正数
- 时间戳:当前时间 - 指定起始时间,保证递增性
- 序列号:利用Redis中的increatement方法,可以使用某一天或者某一小时作为key,返回递增的count,也可以方便统计。
@Component
public class RedisIdWorker {
/**
* 开始时间戳
*/
private static final long BEGIN_TIMESTAMP = 1640995200L;
/**
* 序列号的位数
*/
private static final int COUNT_BITS = 32;
private StringRedisTemplate stringRedisTemplate;
public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
public long nextId(String keyPrefix) {
// 1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2.生成序列号
// 2.1.获取当前日期,精确到天
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 2.2.自增长
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3.拼接并返回
return timestamp << COUNT_BITS | count;
}
}
2. 共享变量更新操作
典型事例: 库存超卖问题;
解决方法: 可以使用悲观锁和乐观锁(单体系统),但乐观锁可以用于并发场景下的更新操作。
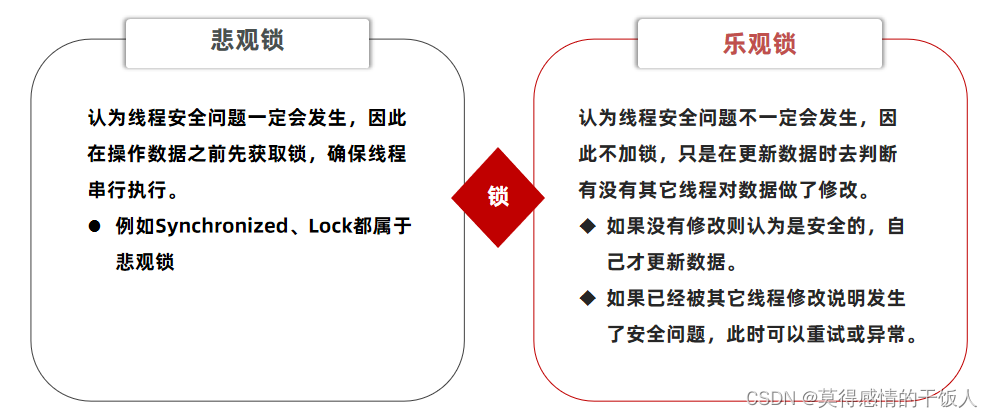
以库存售卖情境为例:乐观锁操作数据库,即执行sql语句时,额外添加一个条件进行判断。判断执行时,库存stock是否改变,但这样执行效率太低;可以改为判断库存总量是否大于0。
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update().gt("stock",0); //where id = ? and stock > 0
3. 共享变量插入操作
乐观锁适合共享变量更新操作,但是对于保存等操作,需要使用悲观锁进行操作,例如采用synchronize代码块。
但在单体系统中,使用悲观锁需要额外注意的是:
- 多个线程必须共用同一把锁,即锁的对象必须是同一个(内存地址)
- 锁必须加载事务的外面,倘若锁加载事务方法中,锁中的操作执行完毕释放锁,但是事务还没有提交,其它的线程就又可以访问数据库进行添加等操作。
- spring的事务底层使用事务方法所在的类的代理对象实现,当类中的某个方法调用带有事务注解的方法时,此时事务是不生效的,得手动调用事务的代理对象。
不直接用userId的原因是: userId是请求时通过ThreadLocal创建出来的, 这意味着不同请求同一时间请求, userId虽然值一样, 但是内存地址完全不一样
synchronized (userId.toString().intern()) { // toString()根本方法是new String(), 也是内存内存地址不一样, intern()将String转换到String常量池中
VoucherOrderService proxy = (VoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
}
4. 分布式锁
在并发场景下,使用上面的悲观锁会导致锁失效的问题。因为上述方法采用的是JVM中的常量池中的对象作为所有线程的锁;但在分布式场景下,多态Tocat服务器中不可能共用一台JVM,这样所有线程就不会共享同一把锁。
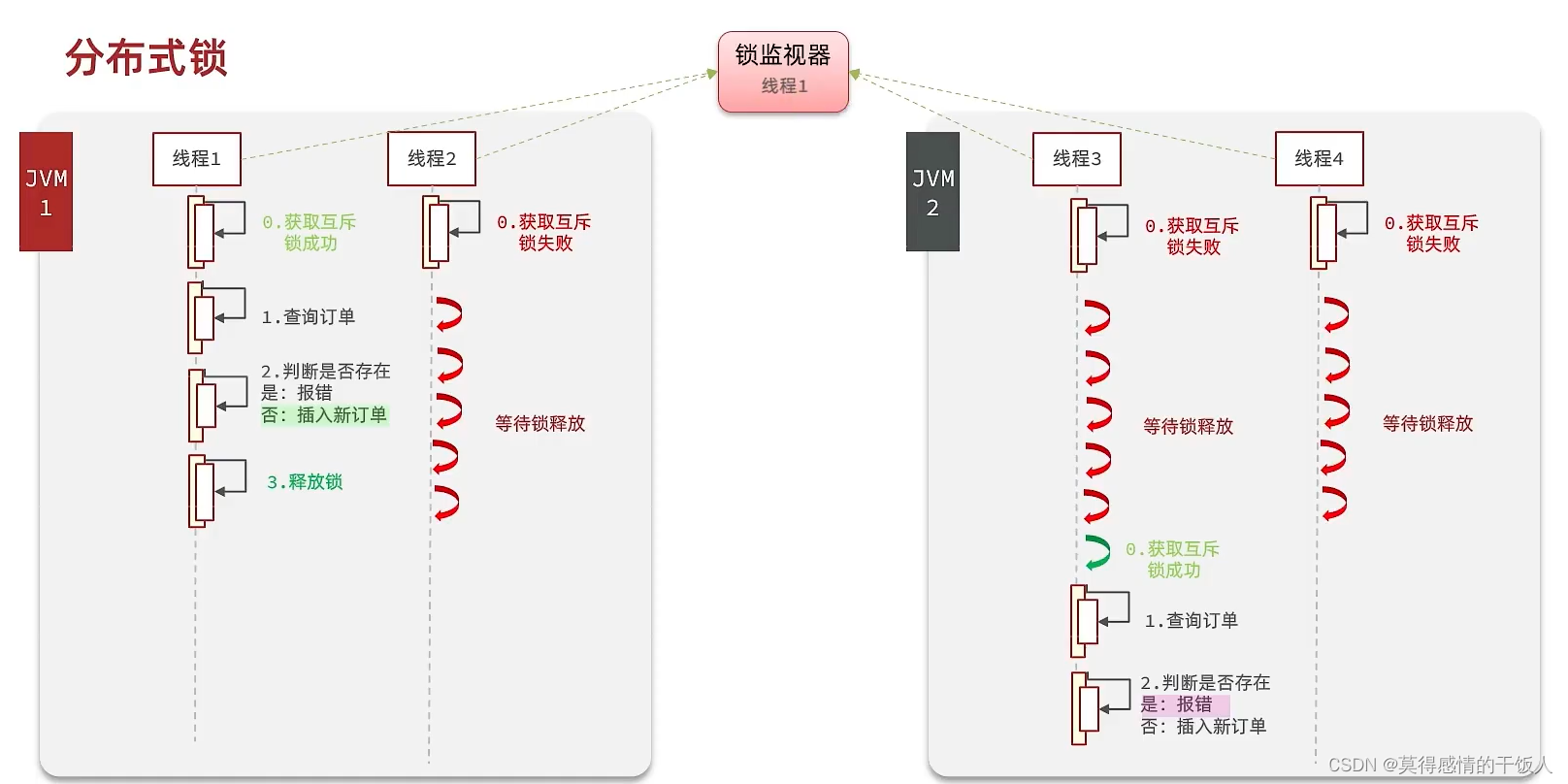
分布式锁
- 多进程可见
- 互斥
- 高可用
- 安全性…
常见的分布式锁主要有三种:Mysql、Redis、Zookeeper
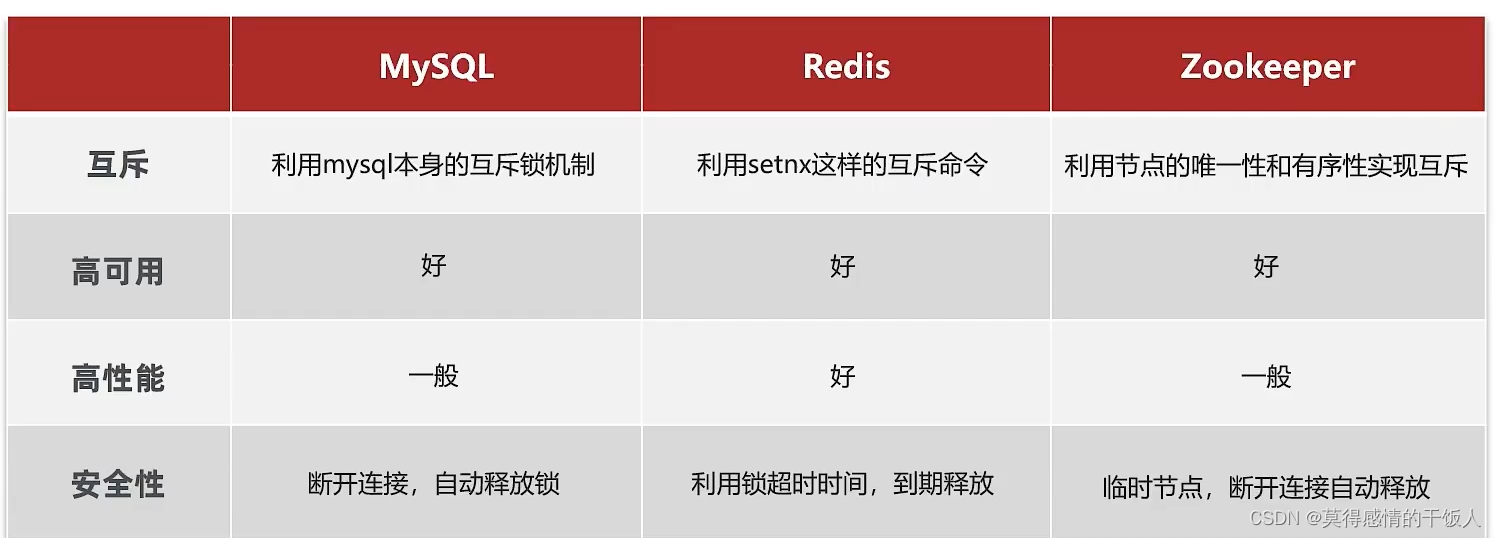
Redis实现分布式锁的思路:
- 获取锁,互斥:确保只有一个线程获取锁
- 非阻塞:获取锁成功则操作数据库,失败则直接返回false
- 释放锁:手动释放锁,设置超时时间防止死锁。
分布式锁的误删情况说明:
持有锁的线程在锁的内部出现了阻塞,导致他的锁自动释放,这时其他线程,线程2来尝试获得锁,就拿到了这把锁,然后线程2在持有锁执行过程中,线程1反应过来,继续执行,而线程1执行过程中,走到了删除锁逻辑,此时就会把本应该属于线程2的锁进行删除。
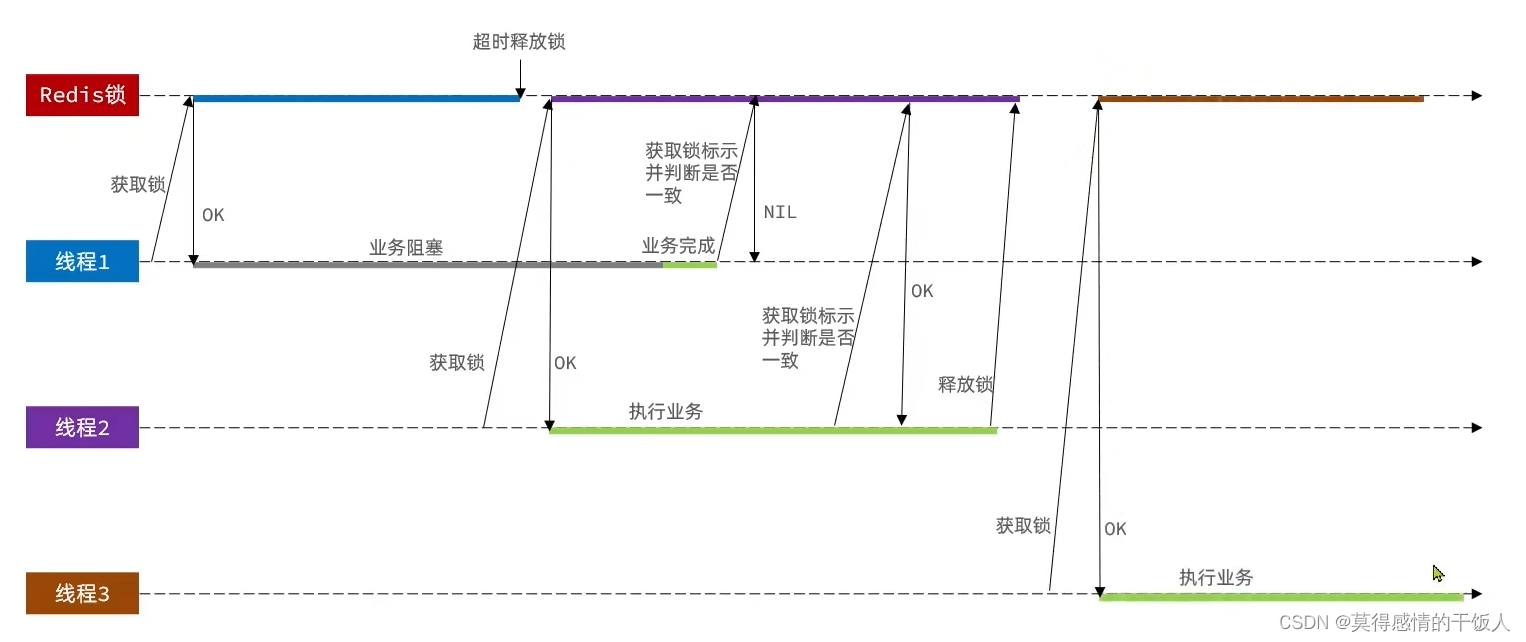
解决方案: 设置锁的时候添加锁的唯一标识作为value,并在删除之前判断是否是属于自己的锁。
加锁
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
释放锁
public void unlock() {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁中的标示
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断标示是否一致
if(threadId.equals(id)) {
// 释放锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}
分布式锁的原子性问题
线程1现在持有锁之后,在执行业务逻辑过程中,他正准备删除锁,而且已经走到了条件判断的过程中,比如他已经拿到了当前这把锁确实是属于他自己的,正准备删除锁,但是此时他的锁到期了,那么此时线程2进来,但是线程1他会接着往后执行,则会删除线程2的锁。
解决方案: 采用Lua脚本,将拿锁、比锁、删锁这三个操作当作原子性操作。
Lua释放锁脚本
-- 获取锁的表示
local id = redis.call('get', KEYS[1])
-- 比较标识
if (id == ARGV[1]) then
return redis.call('del', KEYS[1])
end
return 0
redisTemplate中的execute()方法可以执行Lua脚本并传入key和参数
// lua脚本实现原子性操作
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
UNLOCK_SCRIPT.setResultType(Long.class);
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
}
public void ubLock() {
// 分布式锁删除时得先判断是否是自己的锁, 还得保证取锁、比较、删除锁的原子性操作
stringRedisTemplate.execute(UNLOCK_SCRIPT, Collections.singletonList(keyPrefix + name),
ID_PREFIX + Thread.currentThread().getId());
}
基于setnx实现的分布式锁存在以下问题:

分布式锁-redission可以解决上述问题:
- 底层采用state记录锁重入的状态,解决锁不可重入问题。
- 锁重试和WatchDog机制,解决锁不可重试以及超时释放问题。
- MultiLock加锁机制,在多个节点上加上锁才算加锁成功。
引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
配置Redisson客户端
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.150.101:6379")
.setPassword("123321");
// 创建RedissonClient对象
return Redisson.create(config);
}
}
使用Redisson分布式锁
@Resource
private RedissionClient redissonClient;
@Test
void testRedisson() throws Exception{
//获取锁(可重入),指定锁的名称
RLock lock = redissonClient.getLock("anyLock");
//尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位
boolean isLock = lock.tryLock(1,10,TimeUnit.SECONDS);
//判断获取锁成功
if(isLock){
try{
System.out.println("执行业务");
}finally{
//释放锁
lock.unlock();
}
}
}
三、Redis消息队列
消息队列: 存储和管理消息,也被称为消息代理
生产者: 发送消息到消息队列
消费者: 从消息队列获取消息并处理消息

消息队列的好处在于解耦,个人理解就是同步变异步。举例,查询用户信息、判断是否能够创建订单、创建订单、更新库存这几个原本是同步串行的操作,但中间创建订单、更新库存向数据库写入操作执行比较缓慢,为了提高处理效率,可以将订单信息存入队列中,主线程直接返回订单号,开辟另外一个线程处理队列中的订单信息直至创建成功。
Redis有三种可以模拟队列的方式:
-
基于List实现消息队列
优点: 基于Redis存储,不受JVM限制;基于Redis持久化机制,长时间存储;满足消息队列的有序性
缺点: 只能满足但消费者;存在消息数据丢失的风险,比如list中的BRPOP()是获取并移除消息,当消息处理到一半,但会服务出现宕机等问题,再次启动时消息队列中已经没有原先的数据了。 -
基于PubSub实现消息队列
优点: 采用发布订阅模型,支持多生产者、多消费者
缺点: 不支持数据持久化;无法避免数据丢失;消息堆积有上限,超出时数据丢失。
缺点很多,基本不使用 -
基于Sream数据结构–消费者组 实现消息队列

实现基本思路如下:
while(true) {
// 尝试监听队列,使用阻塞模式,最长等待2000毫秒 '>' 表示从下一个未消费的信息开始读取
Object msg = redis.call("XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 >");
if (msg == null) { // 消息队列中没有数据,直接开始下一次循环
continue;
}
try {
handleMessage(msg);
// 处理消息没有发生异常,ack确认消息处理成功,从pendingList中移除消息
redis.acknowledge();
} catch(Exception e) {
// 消息处理异常,消息还在pendList中
while (true) {
// 0 表示从pendingList中第一个消息开始读取
Object msg = redis.call("XREADGROUP GROUP g1 c1 STREAM s1 0")
if (msg == null) {
break; // 表示没有异常消息,结束循环
}
try {
handPendingList(msg);
} catch (Exception e) {
continue; // pendingList中处理消息异常,继续执行下一次循环
}
}
}
}
Redis三种消息队列实现方式对比:
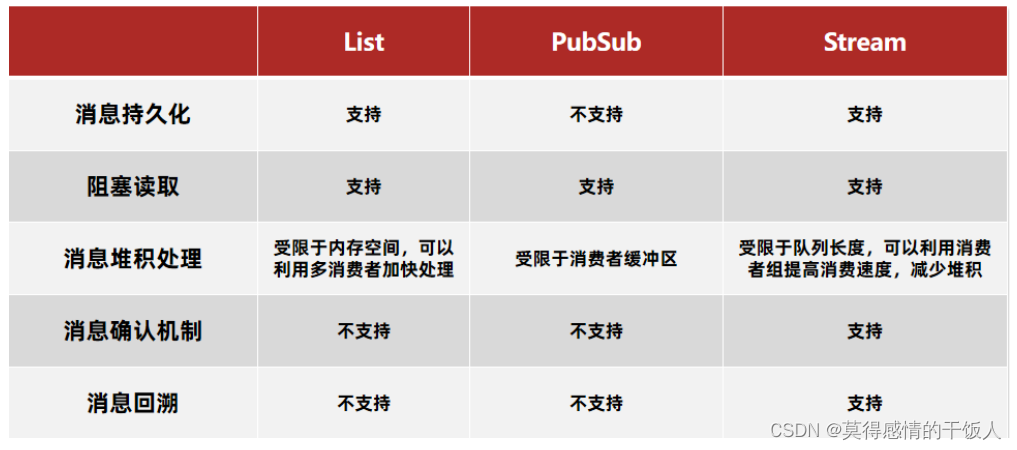
基于Stream数据结构实现的消息队列通过维护一个标识标记还未处理过消息的位置以及ack确认机制能够很好解决消息漏读和数据丢失的问题,但是针对大流量消息队列,redis还是存在内存限制问题,还是得学一下RabbitMq等中间件。
上述图片取自B站黑马Redis课程















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









