







一、KNN简介
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别 。
该方法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最邻近点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。另外还有一种 Reverse KNN法,它能降低KNN算法的计算复杂度,提高分类的效率 。
KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
二、算法衍生与介绍
问题引领:想一想:下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类?

1. 最近邻算法
提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类。由此,我们引出最近邻算法的定义:为了判定未知样本的类别,以全部训练样本作为代表点,计算未知样本与所有训练样本的距离,并以最近邻者的类别作为决策未知样本类别的唯一依据。但是,最近邻算法明显是存在缺陷的,我们来看一个例子。
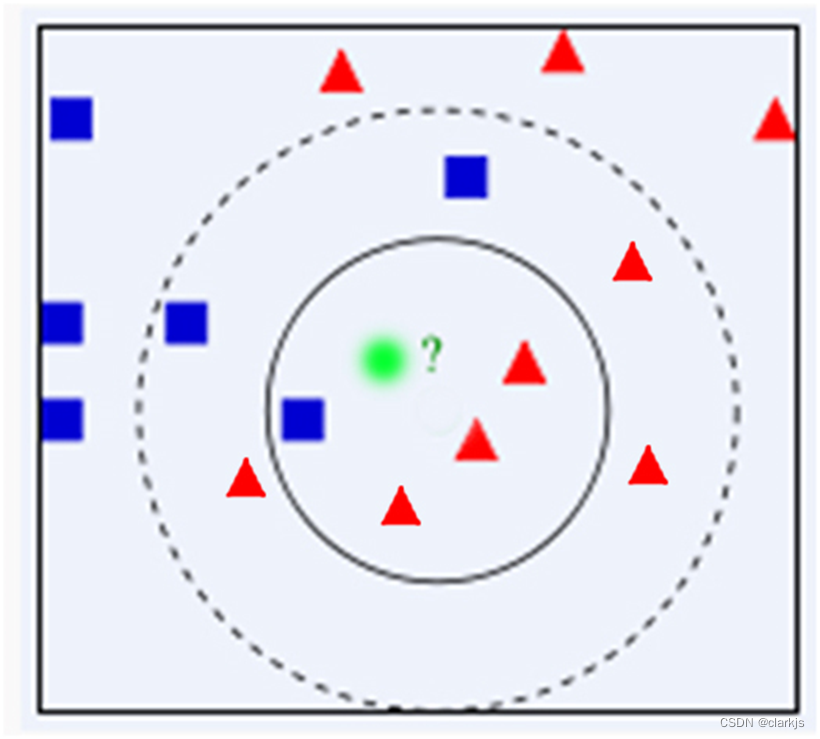
其实这个例子不太好,但是大家应该理解其中的意思,如果蓝色的是噪声,那其实绿点本应该属于红色。但最近邻算法毫无疑问地将其分类为蓝色,所以存在不足。
显然,通过上面的例子我们可以明显发现最近邻算法的缺陷——对噪声数据过于敏感,为了解决这个问题,我们可以可以把位置样本周边的多个最近样本计算在内,扩大参与决策的样本量,以避免个别数据直接决定决策结果。由此,我们引进K-最近邻算法。
2. K-最近邻算法
(1)K-近邻算法介绍
基本思路是:选择未知样本一定范围内确定个数的K个样本,该K个样本大多数属于某一类型,则未知样本判定为该类型。
算法步骤:
step.1---初始化距离为最大值
step.2---计算未知样本和每个训练样本的距离dist
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近邻样本
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
step.6---统计K个最近邻样本中每个类别出现的次数
step.7---选择出现频率最大的类别作为未知样本的类别
(2)K-近邻算法缺陷
观察下面的例子,我们看到,对于位置样本X,通过KNN算法,我们显然可以得到X应属于红点,但对于位置样本Y,通过KNN算法我们似乎得到了Y应属于蓝点的结论,而这个结论显然是错误的。
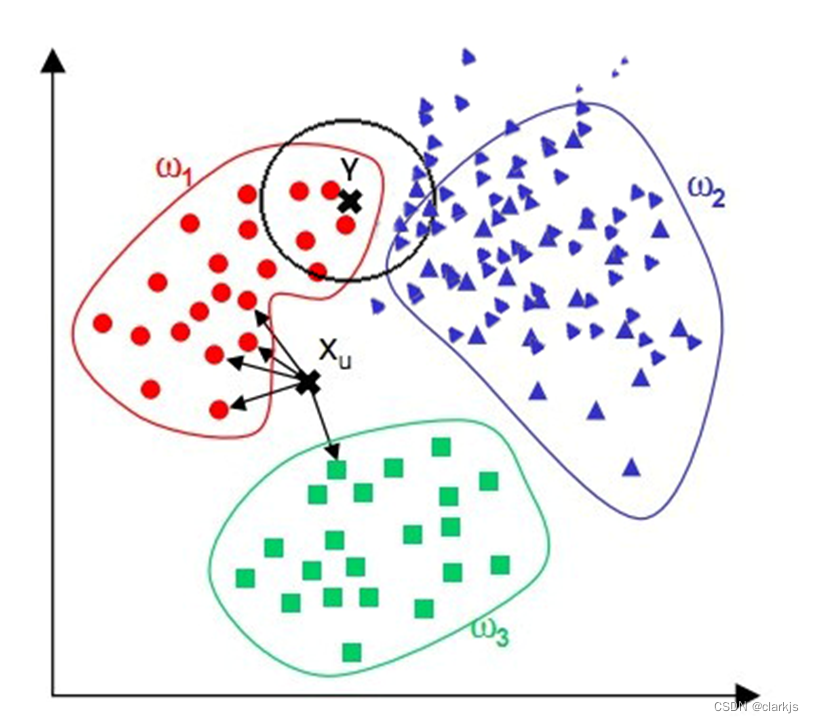
(3)解决方案

虽然解决了之前错判的问题,但KNN从算法实现的过程大家可以发现,该算法存两个严重的问题:(1)需要存储全部的训练样本;(2)需要进行繁重的距离计算量。改进如下:👇
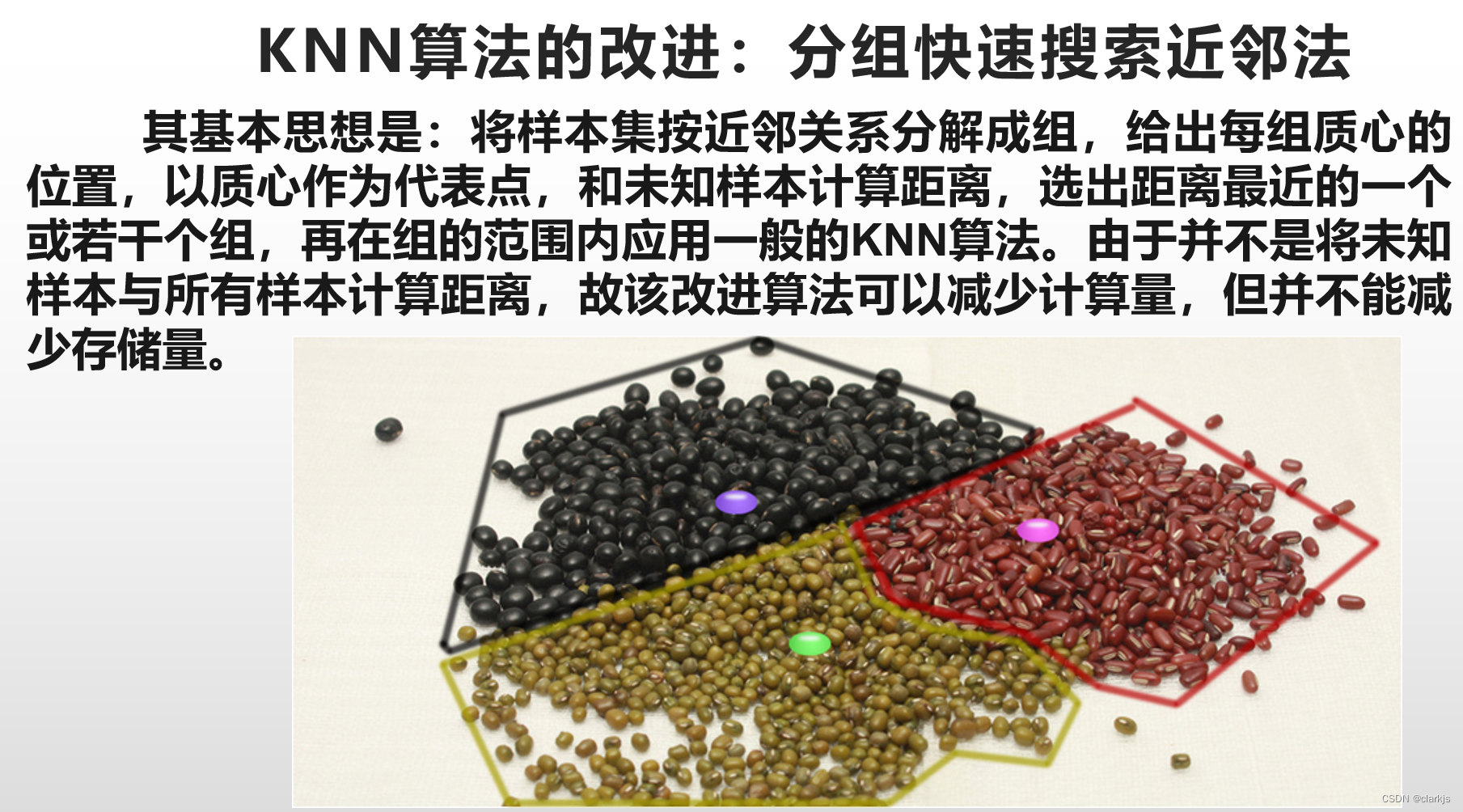
3. KNN算法的改进:分组快速搜索近邻法
4. KNN算法的改进:压缩近邻算法

















 5464
5464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











