







Spoof Diarization: “What Spoofed When” in Partially Spoofed Audio
论文地址:https://arxiv.org/abs/2406.07816
论文代码:https://github.com/
nii-yamagishilab/PartialSpoof
1.本文工作
-
定义新任务:提出了Spoof Diarization这一新任务,在部分被伪造的音频中不仅确定哪些部分被伪造以及根据伪造的方法聚类
-
建立评估指标:为Spoof Diarization任务定义了评估指标,即Spoof Jaccard错误率(JER),用于衡量模型性能。
-
提出基准模型:提出了一个名为Countermeasure-Condition Clustering(3C)的基准模型,该模型包含两个分支,一个用于聚类,另一个用于提供额外的真实信息,以提高Diarization性能。
-
探索训练方法:研究了三种不同的标记方案(Bin-CM、Mul-CM、Spf-CM)对训练模型的影响,并分析了它们在Spoof Diarization任务中的有效性。
-
实验验证:使用PartialSpoof3数据库进行了实验,验证了所提方法和模型的有效性,并分析了不同模型配置下的性能。
-
复杂性分析:通过实验结果揭示了Spoof Diarization任务的高复杂性,尤其是在面对未知伪造方法时。
-
未来工作展望:文章最后讨论了未来工作的方向,包括处理开放场景下未知伪造方法的识别问题。
2.写作背景
提出Spoof Diarization这一新任务的背景是基于以下几个因素:
-
部分伪造(Partial Spoof, PS)场景的现实性和威胁性增加:与传统的完全伪造场景(整个音频信号通常通过文本到语音(TTS)和/或声音转换(VC)算法生成)相比,部分伪造场景更加现实和具有威胁性。在PS场景中,攻击者可能不需要构建整个伪造音频来实现其目标,而是通过操纵音频文件中的几个任意的、短小的部分来大幅扭曲其原始含义。
-
现有技术的局限性:现有的研究主要集中在Spoof检测(判断音频是否被伪造)和Spoof定位(在真实音频文件中识别特定的可疑伪造片段)。这些任务只关注二元(是/否)问题,即音频或片段是否被伪造,但不足以提供详细的伪造信息,如具体的伪造方法或其他来自伪造算法的线索。在法证场景中,如法庭,不仅需要知道音频是否被伪造,还需要获得关于伪造片段的详细信息,例如具体的伪造方法,这可能有助于追踪伪造的来源或创建者。
-
与说话人Diarization的关联:说话人Diarization是语音处理领域中的一个流行任务,目的是确定给定录音中“谁在何时说话”。Spoof Diarization与说话人Diarization相似,关注的是定位和聚类伪造区域,而不是说话人。
3.Spoof Diarization任务的具体定义
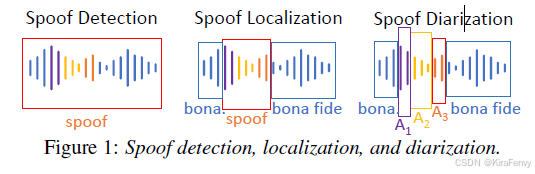
3.1 与现有任务的区别
-
任务目标的差异:
- Spoof检测:目标是判断整个音频信号是否包含伪造片段,关注的是一个二元问题(是或否)。
- Spoof定位:目标是在音频中定位出伪造和真实的区域,但通常不区分伪造片段的具体伪造方法。
- Spoof Diarization:不仅要定位伪造区域,还要根据不同的伪造方法对这些区域进行聚类,提供更详细的伪造信息。
-
开放集挑战:
- Spoof检测和定位:可能不需要处理训练数据中未见过的伪造方法。
- Spoof Diarization:需要能够处理训练时未见过的伪造方法,即“开放集”挑战,这要求系统能够识别和聚类未知的伪造技术。
-
处理伪造片段的粒度:
- Speaker Diarization:可能不会关注非常短的伪造片段,或者在评估时不考虑短片段。
- Spoof Diarization:需要识别和区分短至单个词甚至单个音素的伪造片段,因为这些短片段可能会完全改变音频的含义。
-
聚类的依据:
- Speaker Diarization:聚类是基于说话人的特征,目的是区分不同的说话人,聚类结果取决于实际说话人的数量和特征。
- Spoof Diarization:聚类是基于伪造方法的特征,目的是区分不同的伪造技术或生成模型。聚类结果通常包含两个主要的聚类群体:真实(bona fide)和伪造(spoof)。
3.2 公式化定义
3.2.1 公式化定义
Spoof Diarization的目标是学习一个函数 f d i a f_{dia} fdia,该函数接受一个音频输入 x 1 : T x_{1:T} x1:T,并产生一个多类标签序列 c 1 : M c_{1:M} c1:M。这里, x 1 : T x_{1:T} x1:T 表示一个包含 T T T 个样本的波形,而 c 1 : M c_{1:M} c1:M 表示对 M M M 个段落的段级预测。段落的持续时间可能不同,取决于所使用的模型,最小持续时间可以是一帧(如本文中的情况)。
3.2.2 数学表达式
Spoof Diarization可以被形式化为:
f
d
i
a
:
x
1
:
T
→
c
1
:
M
,
c
m
∈
{
bona fide
,
A
1
,
…
,
A
N
,
[
ConP
]
}
f_{dia} : x_{1:T} \rightarrow c_{1:M}, \quad c_m \in \{ \text{bona fide}, A_1, \ldots, A_N, [\text{ConP}] \}
fdia:x1:T→c1:M,cm∈{bona fide,A1,…,AN,[ConP]}
其中:
- x 1 : T x_{1:T} x1:T 表示一个包含 T T T 个样本的音频波形。
- c 1 : M c_{1:M} c1:M 表示对 M M M 个段落的预测,每个 c m c_m cm 是一个标签,可以是“bona fide”(真实)、 A i A_i Ai(第 i i i 种伪造方法),或者是“ConP”(连接部分,即不同类别的段落无缝连接的部分)。
- N N N 是在实际场景中预期未知的伪造方法的数量,大多数 A ∗ A_* A∗ 在训练数据中是未见过的,这构成了一个“开放集”挑战。
3.2.3 预测和聚类
在预测阶段,理想情况下,Spoof Diarization系统应该能够对训练集中见过的伪造方法进行分类,并将未见过的伪造方法归为一组,类似于目标检测和发现中的做法。作为初步研究,文章中的聚类是在已知伪造方法数量的情况下进行的,而在实际应用中,估计部分伪造音频中正确的聚类数量是一个复杂的问题,未来的研究可以探索更有效和准确的方法来估计聚类数量。
4. Spoof Diarization任务的评估指标
4.1. 评估指标的选择
- 在说话人Diarization中,主要使用两个评估指标:Diarization Error Rate (DER) 和 Jaccard Error Rate (JER)。DER考虑了与录音中总说话时间相关的所有Error,而JER则对所有说话人给予同等重视,与他们的说话时间无关。
- 鉴于Spoof Diarization的性质,即使是非常短的伪造语音片段也可能产生重大影响,因此JER指标更适合这项任务。
4.2. 计算方法
- 为了衡量Spoof Diarization的性能,作者将JER适应为两种形式:JIbona和JERspoof,分别对应于区分真实片段和伪造片段,以及区分不同伪造方法的性能。
- JIbona和JERspoof的计算需要在参考类别和预测聚类之间进行最优映射,这可以通过匈牙利算法(Hungarian algorithm)来确定,这是说话人Diarization中常见的方法。
- JIbona和JERspoof的具体计算公式如下:
J I b o n a , j = F A b o n a , j + M D b o n a , j T O T A L b o n a , j JIbona,j = \frac{FAbona,j + MDbona,j}{TOTALbona,j} JIbona,j=TOTALbona,jFAbona,j+MDbona,j
J E R s p o o f , j = 1 ∣ A j ∣ ∑ A i ∈ A j F A A i , j + M D A i , j T O T A L A i , j JERspoof,j = \frac{1}{|Aj|} \sum_{Ai \in Aj} \frac{FAAi,j + MDAi,j}{TOTALAi,j} JERspoof,j=∣Aj∣1Ai∈Aj∑TOTALAi,jFAAi,j+MDAi,j
其中, F A FA FA 和 M D MD MD 分别代表误报和漏报, T O T A L TOTAL TOTAL 指的是参考和预测之间的联合持续时间。下标 b o n a bona bona 和 A i Ai Ai 分别表示真实和特定的伪造方法 A i Ai Ai。 A j Aj Aj 是第 j j j 个音频中不同伪造方法的集合, ∣ ⋅ ∣ |\cdot| ∣⋅∣ 表示集合的大小。
Q:匈牙利算法是什么
匈牙利算法(Hungarian Algorithm)是一种组合优化算法,用于解决分配问题,特别是在任务分配和聚类问题中。
匈牙利算法的基本原理
匈牙利算法用于解决以下类型的平衡分配问题:
- 有一组代理(或任务)和一组对象(或工人)。
- 每个代理可以被分配给不同的对象。
- 每个代理分配给特定对象都有一个成本或效益值。
- 目标是找到一种分配方式,使得总成本最小化或总效益最大化。
算法的核心思想是:
- 减法步骤:从每一行的所有成本中减去该行的最小成本,然后从每一列的减法结果中减去该列的最小值。
- 覆盖零元素:使用最少数量的水平和垂直线覆盖所有的零元素。
- 检查最优性:如果覆盖的线的数量等于代理(或任务)的数量,则找到了最优分配。如果不是,通过调整成本矩阵中的值来增加零元素的数量,然后重复上述步骤。
何时使用匈牙利算法
匈牙利算法在以下情况下特别有用
- 任务分配问题:需要将一组任务分配给一组代理,使得总成本最小化或效益最大化。
- 聚类问题:在聚类算法中,特别是在需要将数据点分配给特定聚类中心时,匈牙利算法可以用来优化分配。
- 匹配问题:在图论中的匹配问题,如稳定婚姻问题,匈牙利算法可以找到最优匹配。
- 调度问题:在需要将一系列作业分配给机器或工人时,以最小化总完成时间或成本。
- 资源分配:在资源有限且需要优化分配的场景,如网络路由、交通流量管理等。
在Spoof Diarization任务中,匈牙利算法被用来确定参考类别和预测聚类之间的最优映射,以便计算Jaccard错误率(JER)。这是因为在评估聚类性能时,需要将预测的聚类结果与真实的聚类标签进行匹配,而匈牙利算法提供了一种有效的方法来找到这种匹配,从而最小化分类错误。
4.3. 全局评估
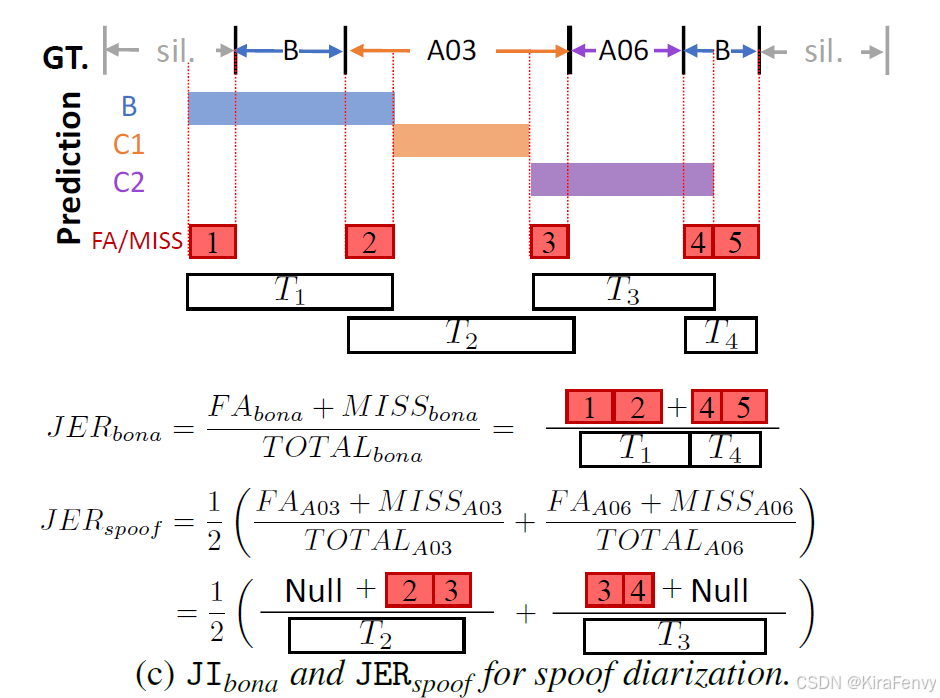
JIbona:计算真实片段的Jaccard指数,衡量模型在识别真实片段上的性能。
JERspoof:计算伪造片段的Jaccard错误率,衡量模型在区分不同伪造方法上的性能。
对于一组音频文件 D D D 的全局评估,使用宏平均(macro averaging)方法来计算JIbona和JERspoof的全局值。
在本文中,宏平均(macro averaging)方法用于计算Spoof Diarization任务的全局评估指标。具体计算方法如下:
对于每个音频文件 j j j,我们分别计算JIbona和JERspoof。然后,对于整个数据集 D D D,我们对所有音频文件的这些指标进行平均,以得到全局的评估结果。
-
宏平均JIbona(JIglobal bona) 的计算公式为:
J I g l o b a l b o n a = 1 ∣ D ∣ ∑ j ∈ D J I b o n a , j JIglobal\ bona = \frac{1}{|D|} \sum_{j \in D} JIbona,j JIglobal bona=∣D∣1j∈D∑JIbona,j -
宏平均JERspoof(JERglobal spoof) 的计算公式为:
J E R g l o b a l s p o o f = 1 ∣ D ∣ ∑ j ∈ D J E R s p o o f , j JERglobal\ spoof = \frac{1}{|D|} \sum_{j \in D} JERspoof,j JERglobal spoof=∣D∣1j∈D∑JERspoof,j
其中:
- ∣ D ∣ |D| ∣D∣ 是数据集中音频文件的总数。
- J I b o n a , j JIbona,j JIbona,j 是第 j j j 个音频文件的JIbona值。
- J E R s p o o f , j JERspoof,j JERspoof,j 是第 j j j 个音频文件的JERspoof值。
这种宏平均方法对每个音频文件的评估结果给予相同的权重,不考虑每个文件中说话人或伪造方法的活动量。这使得评估结果更加稳健,特别是当数据集中的音频文件在长度和复杂性上存在差异时。通过宏平均,我们可以得出整个数据集上模型的整体性能指标。
Q: 什么是宏平均
考察在不同类别下综合考察分类器的优劣,需要引入宏平均(Macro-averaging)、微平均(Micro-averaging)。
宏平均(Macro Averaging)
宏平均在以下情况下使用:
- 类别不平衡:当数据集中的不同类别样本数量差异较大时,宏平均可以给每个类别相同的权重,避免某些类别由于样本数量多而对总体评估结果产生过大影响。
- 每个类别同等重要:如果每个类别都同等重要,宏平均可以确保每个类别对最终结果的贡献是相等的。
- 类别内部的精度:宏平均更关注每个类别内部的评估精度,适合于需要单独分析每个类别性能的场景。
微平均(Micro Averaging)
微平均在以下情况下使用:
- 整体性能:当关注整体性能而非单个类别性能时,微平均通过全局的TP、FP和FN计算指标,可以给出整体的评估结果。
- 类别不平衡但整体样本量足够:即使类别之间不平衡,但如果整体样本量足够大,微平均可以提供一个全局的评估视角。
- 累积贡献:微平均考虑了所有类别的累积贡献,适合于类别之间有重叠或者需要整体评估的场景。
总结
- 宏平均更适用于类别数量较少、每个类别都很重要且类别间样本分布不均的情况。
- 微平均更适用于类别数量较多、整体样本量较大、且关注整体性能而非单个类别性能的场景。
在实际应用中,选择宏平均还是微平均取决于具体的业务需求和数据特性。有时候,为了全面评估模型性能,可能需要同时报告宏平均和微平均的结果。在Spoof Diarization任务中,由于每个音频文件可以看作是一个独立的类别,且每个文件对整体评估都很重要,因此使用宏平均来计算整体性能是合适的。
计算方式参考https://blog.csdn.net/chenpe32cp/article/details/102519255
5.Countermeasure-Condition Clustering模型
这个模型旨在处理部分伪造(Partial Spoof, PS)场景下的音频,即音频中既包含由真人语音生成的部分,也包含通过文本到语音(TTS)或声音转换(VC)技术生成的伪造部分。3C模型的目标是不仅要定位伪造区域,还要根据不同的伪造方法对这些区域进行聚类。
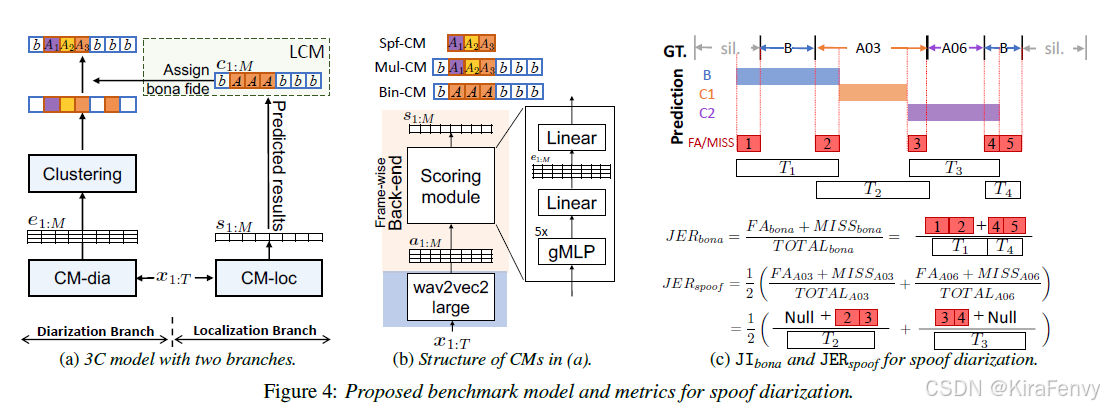
5.1 模型结构
3C模型包含两个主要分支:
-
Diarization Branch(聚类分支):这个分支类似于传统的说话人聚类流程,包括一个嵌入提取器(CM-dia)后跟一个聚类模块。它负责将输入音频分割成同质区域,并根据音频特征将这些区域聚类到不同的组中。
-
Localization Branch(定位分支):这个分支提供额外的真实(bona fide)信息,辅助Diarization Branch更准确地预测真实区域。它通过帧级预测分数来确定哪些帧是真实的。
3C模型通过结合这两种分支的信息,提高对伪造和真实区域的识别能力,并根据不同的伪造方法对伪造区域进行聚类。这种结构使得3C模型能够有效地处理开放集问题,即在实际应用中可能遇到训练阶段未见过的伪造方法。
5.2 工作流程
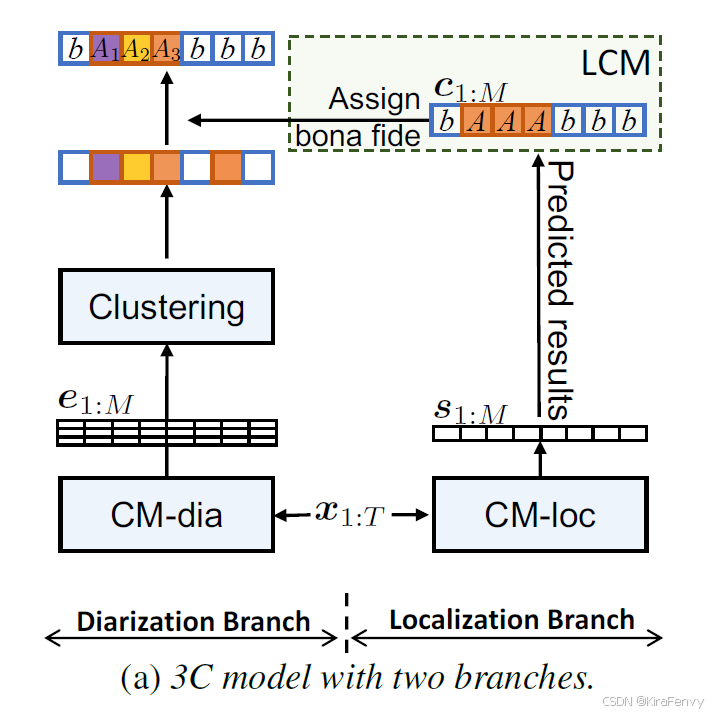
- 嵌入提取:给定输入音频 x 1 : T x_{1:T} x1:T,首先在Diarization Branch中提取帧级嵌入 e 1 : M e_{1:M} e1:M
- 成对亲和矩阵:计算成对亲和矩阵,用于后续的聚类过程。
- 帧级预测:在Localization Branch中,通过二分类或多分类策略,为每个帧 s 1 : M s_{1:M} s1:M 确定一个预测分数,以识别真实的帧。
- 条件聚类:使用Label-based CM-constraint (LCM)方法,如果Localization Branch识别一个帧为真实,那么最终输出也将标记为真实,从而影响Diarization Branch的输出。
5.3 标记方案
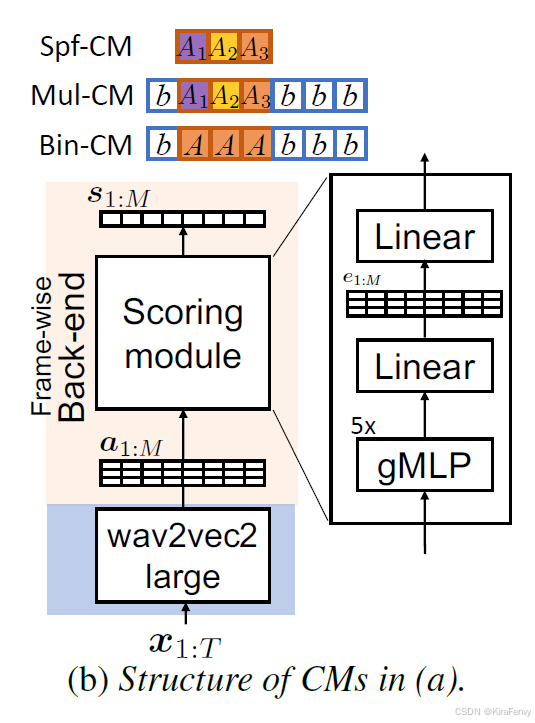
3C模型探索了三种不同的标记方案来训练模型:
- Bin-CM:二分类,区分真实和伪造。
- Mul-CM:多分类,区分真实、各种伪造方法以及连接部分。
- Spf-CM:多伪造分类,专注于区分不同的伪造方法,不包括数据真实性。
这些标记方案提供了不同的训练策略,以适应不同的应用需求。例如,Mul-CM提供了最全面的训练,因为它包括了所有类别,这可能有助于模型在面对未知伪造方法时保持较好的泛化能力。而Bin-CM则简化了问题,专注于最基本的真实与伪造的区分
5.3.1. Bin-CM:二分类标记方案
- 目标:区分真实(bona fide)和伪造(spoof)音频片段。
- 标签: y m ∈ { bona fide , spoof } y_m \in \{\text{bona fide}, \text{spoof}\} ym∈{bona fide,spoof}。
- 训练重点:模型仅关注于区分真实和伪造音频,将所有伪造方法聚合为一个类别进行训练。
- 应用:适用于需要简单区分真实和伪造音频的场景,特别是在对伪造方法的具体类型不敏感的情况下。
5.3.2. Mul-CM:多分类标记方案
- 目标:区分真实音频和多种不同的伪造方法。
- 标签: y m ∗ ∈ { bona fide , A 1 , … , A N , ConP } y^*_m \in \{\text{bona fide}, A_1, \ldots, A_N, \text{ConP}\} ym∗∈{bona fide,A1,…,AN,ConP}。
- 训练重点:模型被训练以识别真实音频和多种具体的伪造方法,包括连接部分(ConP)。
- 应用:适用于需要详细区分不同伪造技术的场景,可以提供更丰富的信息以支持法证分析和安全应用。
5.3.3. Spf-CM:多伪造分类标记方案
- 目标:专门区分不同的伪造方法,不包括真实音频。
- 标签: y m ⋆ ∈ { A 1 , … , A N , ConP } y^{\star}_m \in \{A_1, \ldots, A_N, \text{ConP}\} ym⋆∈{A1,…,AN,ConP}。
- 训练重点:模型专注于区分不同的伪造方法,不涉及真实音频的分类,以探索是否能够提高对伪造方法的区分能力。
- 应用:适用于对伪造方法的识别精度要求较高的场景,尤其是在真实音频的干扰不是主要关注点时。
6.实验
6.1 实验设置
- 数据库:实验使用了PartialSpoof3数据库,该数据库包含了不同比例的真实(bona fide)和伪造(spoof)音频片段。
- 预处理:应用了适应性的声音活动检测(VAD)来移除非语音部分,除了连接部分。非语音段在评分预测时不被考虑。
- 模型训练:所有计数模型(CM)以20毫秒的分辨率进行训练,使用wav2vec2-large作为前端,gMLPs作为后端,并在spoof定位上实现了最佳性能。
6.2 训练CM以支持Spoof Diarization
- 标记方案的影响:分析了三种不同的标记方案(Bin-CM、Mul-CM、Spf-CM)对模型性能的影响,特别是在定位真实片段和区分不同伪造方法方面。
- 不同CM的利用:探讨了如何利用不同标记方案训练的CM来优化3C模型的性能。
6.3 实验结果
- 开发集和评估集的性能:展示了不同配置下的3C模型在开发集和评估集上的性能,包括JIbona(真实片段的Jaccard指数)和JERspoof(伪造片段的Jaccard错误率)。
- 模型比较:比较了仅使用Diarization Branch和结合Localization Branch的3C模型的性能,分析了引入定位分支对模型性能的影响。
- CM-loc选项的比较:比较了使用Bin-CM和Mul-CM作为CM-loc时的性能,以确定哪种方案更适合于定位真实片段。
6.4 结果分析
- 性能差异:分析了在已知和未知伪造方法上的性能差异,以及这些差异对整体性能的影响。
- 挑战和复杂性:讨论了在开放集场景下,未知伪造方法对模型性能的影响,以及未来工作中需要解决的挑战。
6.5 结论
- 任务复杂性:强调了即使在控制场景下,Spoof Diarization任务的复杂性,尤其是在面对未知伪造方法时。
- 未来工作:提出了未来研究的方向,包括处理开放集问题和改进模型以更好地处理复杂的伪造场景。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









