







 本文介绍了如何通过对Ci.txt宋词数据集进行分词和统计词频的步骤,包括处理文本格式,消除标点符号,统计单字和双字词频,并将结果存储。虽然存在一些异常情况,如无词句和标点未完全清除,但提供了改进思路。
本文介绍了如何通过对Ci.txt宋词数据集进行分词和统计词频的步骤,包括处理文本格式,消除标点符号,统计单字和双字词频,并将结果存储。虽然存在一些异常情况,如无词句和标点未完全清除,但提供了改进思路。
辛苦手码不易, 如若有帮助烦请不吝收藏点赞 😃
本文主要在学校实验的基础上,按照实现顺序对实验的实现进行了讲解
在这里主要分享的是分词以及统计词频的部分
生成宋词实现地址:
生成宋词实现地址
要想实现从原始数据集到生成宋词,一般顺序为 分词-> 统计词频 -> 算法实现
分词&统计词频
要想实现分词, 我们应先对数据集进行处理, 首先观察一下数据集的格式:
初步浏览数据集后, 对文本文件相应特点总结如下:
# ci.txt的文本特点:
# ·排列方式:
# 词名XXX
# 空格
# 词内容xxxxxxx
# ·内容:中文,中文符号(',''。''、')
# 要求: 统计分词单字 统计单字字频 保存为字典,写入Char_dict.txt
介于上述特性, 我设计了如下的读取方式:
- 调用readlines()函数,将文本以行为基本单位,作为列表元素读取,此时,列表中的排列方式大致为:
[‘词牌名’, ‘换行符’, ‘词句(含标点)’…](此时还未对文本进行解码操作,故元素内容均为编码)
得到初步的列表后,对列表进行遍历,访问每个元素。对每个元素首先进行解码操作,如果遍历到换行符‘/r/n’,则略去 ,而对于词句中的标点,则统一置换为空格,以便后续划分出单句,划分出单句后,将每首词的单句作为元素,分别装入列表,这样,一个列表即为一首词的内容,列表元素为单句,再将列表作为元素,放入新的列表。
此时,新列表的构成应为:
[‘词牌名’, [‘词句(以空格划分的单句)’]…]

- 开始遍历新列表,鉴于其词牌名与词句交替出现,这里选择对遍历统计奇偶,只挑取词句元素进行操作,对于词牌名则忽略。对于词句,主要消去其句末换行符,将处理结果再次放入新的列表。这时,列表组成为:
[‘单句(不区分是哪首词)’…]

- 正式开始统计词频。这里分别对字数为1、2的词进行统计,其方法略有不同。
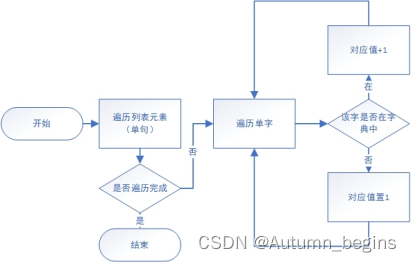
单字: 对列表进行遍历,对每个字符串元素再进行遍历,对于字数为一的,设置分支逻辑:若该单字在字典中,则其值加一,若不在字典中,将其值置1,由此得到以字典数据结构存储的单字词频。
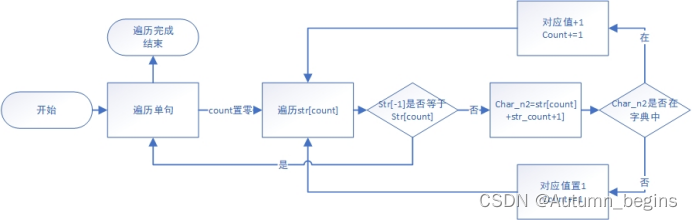
双字: 对于双字,由于遍历只能单字遍历,故需要增设新的判断逻辑:增设计数值count,结合字符串特性,将char_n2变量以eachSentence[count]+eachSentence[count+1]进行赋值,然后对char_n2执行单字词频统计时的字典操作逻辑。对每个单句,执行上述循环操作,若遍历到末字,则跳出循环。由此一来,便可以得出存有双字词频信息的字典。
最后,将单双字的词频信息分别写入新的文本文件进行存储。写入流程如下:提取字典键列表,遍历该列表,对每一次遍历,写入键名字,写入分隔符“/”,最后写入该键对应值(即词频)和换行符,最后得到的文本效果见下一章节。
实现代码如下:
char_dict_n1={}
char_dict_n2={}
sh = [',','。','!','、','?','【','】']
char_result01=open('char_result_n1.txt','w') #存放字频
char_result02=open('char_result_n2.txt','w') #存放双字词频
with open('Ci.txt','rb')as res_file:
lines=res_file.readlines()
count=-1
line_member=[]
sentence_member=[]
for line in lines:
new_line = line.decode('gbk', 'ignore')
cooked_line=new_line
if new_line == '\r\n':#消去换行符
continue
for each in sh:
cooked_line=cooked_line.replace(each,' ')#消去标点 插入空格便于划分单句
line_member.append(cooked_line.split(' '))
for eachLine in line_member:#根据文本内容特点 忽略词牌名
count = count + 1
if count%2==0:
continue
for each in eachLine:
if each!='\r\n':#删去句末换行符
sentence_member.append(each)
for eachSentence in sentence_member:#n1字典构造
for each_char in eachSentence:
if each_char in char_dict_n1:
char_dict_n1[each_char]+=1
else:
char_dict_n1[each_char] = 1
for eachSentence in sentence_member:#n2字典构造
count = 0
while eachSentence:
if eachSentence[-1]==eachSentence[count]:
break
char_n2=eachSentence[count]+eachSentence[count+1]
if char_n2 in char_dict_n2:
char_dict_n2[char_n2]+=1
else:
char_dict_n2[char_n2]=1
count+=1
# print(char_dict_n2)
# print(char_dict)
#保存
dict01_keys=char_dict_n1.keys()
dict02_keys=char_dict_n2.keys()
for eachkey in dict01_keys:
char_result01.write(eachkey)
char_result01.write('/')
char_result01.write(str(char_dict_n1[eachkey])+'\n')
char_result01.close()
for eachkey in dict02_keys:
char_result02.write(eachkey)
char_result02.write('/')
char_result02.write(str(char_dict_n2[eachkey])+'\n')
char_result02.close()
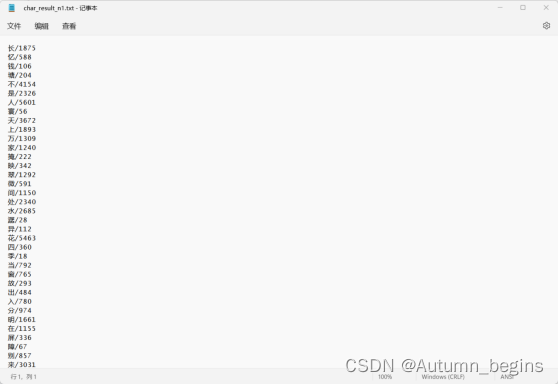
分词效果如下:
- 单字分词效果
- 双字分词效果

最终的分词效果基本完成了实验要求,但还是有一些不够完善的地方,比如:Ci.txt文件中,存在着只有词牌名而无词的情况;标点符号没有彻底消除的情况;以及突然出现的乱码或是作者名的情况,在代码实现时,我一开始并没有考虑到上述问题,在后续使用到这些词频生成宋词的实验中,这些问题暴露了出来并给我带来了不少麻烦。
文本异常(符号)

文本异常(无词句)

文本异常(作者名)

上述错误可在分词阶段进行清洗, 读者可自行尝试. 以下给出我的解决思路:
针对我以奇偶交替而区分词牌名与词的方式,无法消除只有词牌名而无词的情况,在实验二中,我选取了根据是否含标点符号来对词牌名与词句进行划分,规避了上述问题,而对没有消除的标点符号,我将对代码进行多次测试,对出现的未删除的符号,将其添加至相应列表中,或是通过编码判断其是否为汉字,后者效果应会更佳,限于时间,我在本次实验中未使用后者。
数据集分享如下(BD网盘提取码ZGKK):
Ci.txt宋词数据集
Ci.txt宋词数据集


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











