






是帮朋友写的码,在原作者的基础上进行的升级:http://t.csdnimg.cn/2wpd
一、功能实现
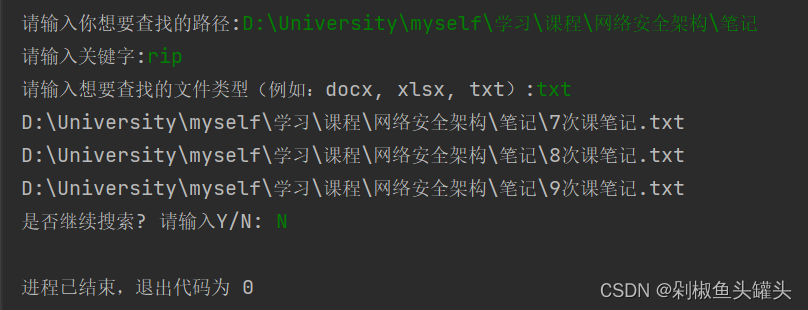
允许自己定义次数,在指定的路径进行文件搜索想要的内容,支持的文件格式为 txt,xlsx, docx 格式,并且在每次搜索之后都有一个搜索判断
代码流程
请求用户输入查询次数。
循环,直到完成所有查询或用户选择退出。
在每次循环中:
请求用户输入搜索路径、关键字和文件类型。
根据文件类型,调用相应的搜索函数(get_doc_dir, get_excel_dir, get_txt_dir)。
如果找到匹配的文件,打印文件路径。
循环结束后,如果还有剩余的搜索次数,询问用户是否继续搜索。
二、安装包需求
pip install python-docx
pip install xlrd==1.2.0
因为只有旧版本的xlrd库支持 .xlsx 和 .xls格式的excel文件
三、源码解释
导入模块
docx: 用于操作 Word 文档。os: 用于文件和目录操作。xlrd: 用于读取 Excel 文件。
get_doc_dir 函数
遍历 Word 文档的所有段落和表格,查找是否包含指定的文本。
def get_doc_dir(tr_text, path):
"""
在 Word 文档中搜索特定文本。
:param tr_text: 要搜索的文本。
:param path: Word 文档的路径。
:return: 如果找到文本,返回 True,否则返回 False。
"""
document = Document(path)
all_paragraphs = document.paragraphs
for paragraph in all_paragraphs:
if tr_text in paragraph.text:
return True
all_tables = document.tables
for table in all_tables:
for row in table.rows:
for cell in row.cells:
if tr_text in cell.text:
return True
return False
get_excel_dir 函数
遍历 Excel 文件的所有单元格,查找是否包含指定的文本。
def get_excel_dir(tr_text, path):
"""
在 Excel 文件中搜索特定文本。
:param tr_text: 要搜索的文本。
:param path: Excel 文件的路径。
:return: 如果找到文本,返回 True,否则返回 False。
"""
book = xlrd.open_workbook(path)
for sheet_name in book.sheet_names():
sheet = book.sheet_by_name(sheet_name)
for i in range(sheet.nrows):
for j in range(sheet.ncols):
if sheet.cell(i, j).ctype == 1 and tr_text in sheet.cell(i, j).value:
return True
return False
get_txt_dir 函数
尝试使用多种字符编码(如 utf-8, gbk, latin1, windows-1252, ansi)来读取 TXT 文件,并搜索特定文本。
如果想搜索其他编码的文本,可以自行添加或修改
def get_txt_dir(tr_text, path):
"""
在 TXT 文件中尝试多种编码搜索特定文本。
:param tr_text: 要搜索的文本。
:param path: TXT 文件的路径。
:return: 如果找到文本,返回 True,否则返回 False。
"""
encodings = ['utf-8', 'gbk', 'latin1','windows-1252','ansi'] # 编码列表
for encoding in encodings:
try:
with open(path, 'r', encoding=encoding) as file:
for line in file:
if tr_text in line:
return True
break # 如果文件成功读取,跳出编码循环
except UnicodeDecodeError:
pass # 如果当前编码失败,尝试下一个编码
except IOError:
print(f"Error: Could not read file {path}")
break # 如果发生IO错误,跳出循环
return False
主程序
允许用户输入搜索次数、路径、关键字和文件类型。根据用户输入的信息,在指定路径下的特定类型文件中搜索关键字。
if __name__ == '__main__':
i = int(input('请输入你想查询的次数:'))
while(i):
i -= 1
# tr_dir = r'D:\University\myself\个人'
tr_dir = input('请输入你想要查找的路径:')
tr_text = input('请输入关键字:')
file_type = input('请输入想要查找的文件类型(例如:docx, xlsx, txt):').lower()
for root, dirs, files in os.walk(tr_dir):
for file_name in files:
full_path = os.path.join(root, file_name)
# Skip temporary or hidden files (often start with ~ or .)
if file_name.startswith('~') or file_name.startswith('.'):
continue
full_path = os.path.join(root, file_name)
if file_type == 'docx' and file_name.lower().endswith(('.docx', '.doc')):
if os.path.exists(full_path): # Check if the file exists
try:
if get_doc_dir(tr_text, full_path):
print(full_path)
except Exception as e:
print(f"Error processing file {full_path}: {e}")
elif file_type == 'xlsx' and file_name.lower().endswith(('.xlsx', '.xls')):
if get_excel_dir(tr_text, full_path):
print(full_path)
elif file_type == 'txt' and file_name.lower().endswith('.txt'):
if get_txt_dir(tr_text, full_path):
print(full_path)
if i == 0:
print("查询次数已用完。")
if i != 0:
judge = input("是否继续搜索? 请输入Y/N: ")
if judge.upper() == 'N': # Check if input is 'N' or 'n'
break # Exit loop if input is not 'Y'
四、代码源码
from docx import Document
import os, xlrd
def get_doc_dir(tr_text, path):
"""
Search for specific text in a Word document.
:param tr_text: Text to search for.
:param path: Path to the Word document.
:return: True if the text is found, False otherwise.
"""
document = Document(path)
all_paragraphs = document.paragraphs
for paragraph in all_paragraphs:
if tr_text in paragraph.text:
return True
all_tables = document.tables
for table in all_tables:
for row in table.rows:
for cell in row.cells:
if tr_text in cell.text:
return True
return False
def get_excel_dir(tr_text, path):
"""
Search for specific text in an Excel file.
:param tr_text: Text to search for.
:param path: Path to the Excel file.
:return: True if the text is found, False otherwise.
"""
book = xlrd.open_workbook(path)
for sheet_name in book.sheet_names():
sheet = book.sheet_by_name(sheet_name)
for i in range(sheet.nrows):
for j in range(sheet.ncols):
if sheet.cell(i, j).ctype == 1 and tr_text in sheet.cell(i, j).value:
return True
return False
def get_txt_dir(tr_text, path):
"""
Search for specific text in a TXT file with multiple encoding attempts.
:param tr_text: Text to search for.
:param path: Path to the TXT file.
:return: True if the text is found, False otherwise.
"""
encodings = ['utf-8', 'gbk', 'latin1','windows-1252','ansi'] # 编码列表
for encoding in encodings:
try:
with open(path, 'r', encoding=encoding) as file:
for line in file:
if tr_text in line:
return True
break # 如果文件成功读取,跳出编码循环
except UnicodeDecodeError:
pass # 如果当前编码失败,尝试下一个编码
except IOError:
print(f"Error: Could not read file {path}")
break # 如果发生IO错误,跳出循环
return False
if __name__ == '__main__':
i = int(input('请输入你想查询的次数:'))
while(i):
i -= 1
# tr_dir = r'D:\University\myself\个人'
tr_dir = input('请输入你想要查找的路径:')
tr_text = input('请输入关键字:')
file_type = input('请输入想要查找的文件类型(例如:docx, xlsx, txt):').lower()
for root, dirs, files in os.walk(tr_dir):
for file_name in files:
full_path = os.path.join(root, file_name)
# Skip temporary or hidden files (often start with ~ or .)
if file_name.startswith('~') or file_name.startswith('.'):
continue
full_path = os.path.join(root, file_name)
if file_type == 'docx' and file_name.lower().endswith(('.docx', '.doc')):
if os.path.exists(full_path): # Check if the file exists
try:
if get_doc_dir(tr_text, full_path):
print(full_path)
except Exception as e:
print(f"Error processing file {full_path}: {e}")
elif file_type == 'xlsx' and file_name.lower().endswith(('.xlsx', '.xls')):
if get_excel_dir(tr_text, full_path):
print(full_path)
elif file_type == 'txt' and file_name.lower().endswith('.txt'):
if get_txt_dir(tr_text, full_path):
print(full_path)
if i == 0:
print("查询次数已用完。")
if i != 0:
judge = input("是否继续搜索? 请输入Y/N: ")
if judge.upper() == 'N': # Check if input is 'N' or 'n'
break # Exit loop if input is not 'Y'















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









