






⭐️(二分)704.二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
提示:
你可以假设 nums 中的所有元素是不重复的。
n 将在 [1, 10000]之间。
nums 的每个元素都将在 [-9999, 9999]之间。
方法一
这道题目的前提是数组为有序数组,同时题目还强调数组中无重复元素,因为一旦有重复元素,使用二分查找法返回的元素下标可能不是唯一的,这些都是使用二分法的前提条件,当大家看到题目描述满足如上条件的时候,可要想一想是不是可以用二分法了。
二分查找涉及的很多的边界条件,逻辑比较简单,但就是写不好。例如到底是 while(left < right) 还是 while(left <= right),到底是right = middle呢,还是要right = middle - 1呢?
大家写二分法经常写乱,主要是因为对区间的定义没有想清楚,区间的定义就是不变量。要在二分查找的过程中,保持不变量,就是在while寻找中每一次边界的处理都要坚持根据区间的定义来操作,这就是循环不变量规则。
写二分法,区间的定义一般为两种,左闭右闭即[left, right],或者左闭右开即[left, right)。
下面以 左闭右闭 作为区间的定义讲解二分算法
我们定义 target 是在一个在左闭右闭的区间里,也就是[left, right] (这个很重要非常重要)。也就是说target可能是左边界也可能是右边界,如果某个时刻已经判断出target肯定不是右边界了,那么不能包含右边界
区间的定义这就决定了二分法的代码应该如何写,因为定义target在[left, right]区间,所以有如下两点:
- while (left <= right) 要使用 <= ,因为left == right是有意义的,所以使用 <=
- if (nums[middle] > target) right 要赋值为 middle - 1,因为当前这个nums[middle]一定不是target,那么接下来要查找的左区间结束下标位置就是 middle - 1
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1; // 定义target在左闭右闭的区间里,[left, right]
while (left <= right) { // 当left==right,区间[left, right]依然有效,所以用 <=
int middle = left + ((right - left) / 2);// 防止溢出 等同于(left + right)/2
if (nums[middle] > target) {
right = middle - 1; // target 在左区间,所以[left, middle - 1]
} else if (nums[middle] < target) {
left = middle + 1; // target 在右区间,所以[middle + 1, right]
} else { // nums[middle] == target
return middle; // 数组中找到目标值,直接返回下标
}
}
// 未找到目标值
return -1;
}
};
时间复杂度:O(log n)
空间复杂度:O(1)
方法二
用的下面万能模版方法
注意如果不加上if (right == nums.size()) return -1;,会出错。比如如果只有一个元素且不是target,right就一直是size,那么在判断nums[right] == target时就会出错,也就是全蓝的情况
class Solution {
public:
// isBlue: < target
int search(vector<int>& nums, int target) {
int left = -1, right = nums.size();
while (left + 1 < right) {
int mid = left + right >> 1;
if (nums[mid] < target) left = mid;
else right = mid;
}
if (right == nums.size()) return -1;
if (nums[right] == target) return right;
return -1;
}
};
⭐️(二分)Acwing 789. 数的范围
给定一个按照升序排列的长度为 n
的整数数组,以及 q
个查询。
对于每个查询,返回一个元素 k
的起始位置和终止位置(位置从 0
开始计数)。
如果数组中不存在该元素,则返回 -1 -1。
输入格式
第一行包含整数 n
和 q
,表示数组长度和询问个数。
第二行包含 n
个整数(均在 1∼10000
范围内),表示完整数组。
接下来 q
行,每行包含一个整数 k
,表示一个询问元素。
输出格式
共 q
行,每行包含两个整数,表示所求元素的起始位置和终止位置。
如果数组中不存在该元素,则返回 -1 -1。
数据范围
1≤n≤100000
1≤q≤10000
1≤k≤10000
输入样例:
6 3
1 2 2 3 3 4
3
4
5
输出样例:
3 4
5 5
-1 -1
这题和上面Leetcode的那题,其实是不同的题,
Leetcode的题保证元素不重复,也就是说要么不存在,要么有且仅有一个
Acwing的题元素可以重复,也就是说我们要找到一个区间,或者不存在
用二分去查找元素要求数组的有序性或者拥有类似于有序的性质,对本题而言,一个包含重复元素的有序序列,要求输出某元素出现的起始位置和终止位置,翻译一下就是:在数组中查找某元素,找不到就输出−1,找到了就输出不小于该元素的最小位置和不大于该元素的最大位置。所以,需要写两个二分,一个需要找到>=x的第一个数,另一个需要找到<=x的最后一个数。
在 C++ 中,使用 >> 1 和 / 2 来实现数值除以 2 虽然在大多数情况下结果相同,但两者在底层的处理方式及行为上存在差异:
性能和实现:
>> 1 是一个位移操作,通常在硬件层面上执行得更快。这是因为它直接在数的二进制表示上移动位,而非执行除法运算。
/ 2 是一个算术除法操作,适用于整数和浮点数,但其执行速度可能较位移操作慢,因为它涉及到更复杂的算术运算。
负数处理:
对于非负整数,>> 1 和 / 2 的结果相同,都是将数字除以 2。
对于负数,>> 1 进行的是算术右移,会保留数字的符号位。例如,-1 >> 1 结果为 -1,因为位移后顶部填充的是 1。这样的处理方式在某些情况下会导致与 / 2 结果不同,因为 / 2 总是朝着零的方向舍入(例如,-1 / 2 结果为 0)。
注意AcWing和Leetcode的不同之处:
这里把right == n这个判断直接删掉也能ac,因为leetcode中是给定一个vector,删掉这个判断就可能越界,而acwing里是自己定义大小的数组,删掉这个判断也不会越界
#include <stdio.h>
int a[100010];
int main() {
int n, q;
scanf("%d%d", &n, &q);
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
while (q -- ) {
int x;
scanf("%d", &x);
// 起:>=x的第一个数; isBlue: <x; return right
int left = -1, right = n, mid;
while (left + 1 < right) {
mid = left + right >> 1;
if (a[mid] < x) left = mid;
else right = mid;
}
if (right == n || a[right] != x) {
printf("-1 -1\n");
}
else if (a[right] == x) {
printf("%d ", right);
// 末:<=x的最后一个数; isBlue: <=x; return left
left = -1, right = n;
while (left + 1 < right) {
mid = left + right >> 1;
if (a[mid] <= x) left = mid;
else right = mid;
}
printf("%d\n", left);
}
}
return 0;
}
(二分)35.搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
提示:
1 <= nums.length <= 104
-104 <= nums[i] <= 104
nums 为 无重复元素 的 升序 排列数组
-104 <= target <= 104
class Solution {
public:
// isBlue: < x; return l+1;
int searchInsert(vector<int>& nums, int target) {
int l = -1, r = nums.size();
while (l + 1 < r) {
int mid = l + r >> 1;
if (nums[mid] < target) l = mid;
else r = mid;
}
return l + 1;
}
};
(二分)34. 在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
提示:
0 <= nums.length <= 105
-109 <= nums[i] <= 109
nums 是一个非递减数组
-109 <= target <= 109
这个其实就是上面 Acwiing789 原题

class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
// 第一个; isBlue: <x; return r;
int l = -1, r = nums.size();
while (l + 1 < r) {
int mid = l + r >> 1;
if (nums[mid] < target) l = mid;
else r = mid;
}
if (r == nums.size() || nums[r] > target) return {-1, -1};
// 最后一个; isBlue: <=x; return ll
int ll = -1, rr = nums.size();
while (ll + 1 < rr) {
int mid = ll + rr >> 1;
if (nums[mid] <= target) ll = mid;
else rr = mid;
}
return {r, ll};
}
};
⭐️(二分)69.x 的平方根
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
示例 1:
输入:x = 4
输出:2
示例 2:
输入:x = 8
输出:2
解释:8 的算术平方根是 2.82842…, 由于返回类型是整数,小数部分将被舍去。
提示:
0 <= x <= 2^{31} - 1
本题是一道常见的面试题,面试官一般会要求面试者在不使用 \sqrt{x} 函数的情况下,得到 x 的平方根的整数部分。一般的思路会有以下几种:
1.通过其它的数学函数代替平方根函数得到精确结果,取整数部分作为答案;
2.通过数学方法得到近似结果,直接作为答案。
方法一
「袖珍计算器算法」是一种用指数函数 exp 和对数函数 ln 代替平方根函数的方法。我们通过有限的可以使用的数学函数,得到我们想要计算的结果。
我们将 \sqrt{x} 写成幂的形式 x^{1/2} ,再使用自然对数 e 进行换底,即可得到
x
=
x
1
2
=
(
e
l
n
x
)
1
2
=
e
1
2
l
n
x
\sqrt{x}=x^{\frac{1}{2}}=(e^{lnx})^{\frac{1}{2}}=e^{\frac{1}{2}lnx}
x=x21=(elnx)21=e21lnx
这样我们就可以得到 sqrt{x} 的值了。
注意: 由于计算机无法存储浮点数的精确值(浮点数的存储方法可以参考 IEEE 754,这里不再赘述),而指数函数和对数函数的参数和返回值均为浮点数,因此运算过程中会存在误差。例如当 x=2147395600时, 的计算结果与正确值 46340 相差 10^{-11} ,这样在对结果取整数部分时,会得到 46339 这个错误的结果。
因此在得到结果的整数部分(截断的方式下取整) ans 后,我们应当找出 ans+1 中哪一个是真正的答案
log(x)就是 l n x lnx lnx
时间复杂度:O(1),由于内置的 exp 函数与 log 函数一般都很快,我们在这里将其复杂度视为 O(1)。
空间复杂度:O(1)。
注意(long long)转换很关键,否则两个int相乘可能超出int范围!

class Solution {
public:
int mySqrt(int x) {
if (x == 0 || x == 1) return x;
int ans = exp(0.5 * log(x));
return ((long long)(ans + 1) * (ans + 1) <= x ? ans + 1 : ans);
}
};
方法二
二分查找
二分查找的下界为 0,上界可以粗略地设定为 x。在二分查找的每一步中,我们只需要比较中间元素 mid 的平方与 x 的大小关系,并通过比较的结果调整上下界的范围。由于我们所有的运算都是整数运算,不会存在误差,因此在得到最终的答案ans后,也就不需要再去尝试 ans+1 了。
class Solution {
public:
// isBlue: mid * mid <= x; return l;
int mySqrt(int x) {
if (x == 0 || x == 1) return x;
int l = -1, r = x;
while (l + 1 < r) {
int mid = l + r >> 1;
if ((long long)mid * mid <= x) l = mid;
else r = mid;
}
return l;
}
};
(二分)367.有效的完全平方数
给你一个正整数 num 。如果 num 是一个完全平方数,则返回 true ,否则返回 false 。
完全平方数 是一个可以写成某个整数的平方的整数。换句话说,它可以写成某个整数和自身的乘积。
不能使用任何内置的库函数,如 sqrt 。
示例 1:
输入:num = 16
输出:true
解释:返回 true ,因为 4 * 4 = 16 且 4 是一个整数。
示例 2:
输入:num = 14
输出:false
解释:返回 false ,因为 3.742 * 3.742 = 14 但 3.742 不是一个整数。
提示:
1 <= num <= 231 - 1
方法一
class Solution {
public:
bool isPerfectSquare(int num) {
if (num == 1) return true;
int ans = exp(0.5 * log(num));
if ((long long)ans * ans == num) return true;
if ((long long)(ans + 1) * (ans + 1) == num) return true;
return false;
}
};
方法二

class Solution {
public:
bool isPerfectSquare(int num) {
if (num == 1) return true;
// isBlue: mid * mid <= num; return l;
// [1, num - 1]
int l = 0, r = num;
while (l + 1 < r) {
int mid = l + r >> 1;
if ((long long)mid * mid <= num) l = mid;
else r = mid;
}
if ((long long)l * l == num) return true;
return false;
}
};
(移除元素)27. 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,3,0,4]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 100
0 <= nums[i] <= 50
0 <= val <= 100
方法一

class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int k = 0;
int len = nums.size();
for (int i = 0; i < len; i ++ ) {
if (nums[i] == val) k ++ ;
else nums[i - k] = nums[i];
}
return (len - k);
}
};
方法二
双指针法(快慢指针法): 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
定义快慢指针
快指针:寻找新数组的元素 ,新数组就是不含有目标元素的数组
慢指针:指向更新 新数组下标的位置
很多同学这道题目做的很懵,就是不理解 快慢指针究竟都是什么含义,所以一定要明确含义,后面的思路就更容易理解了。
// 时间复杂度:O(n)
// 空间复杂度:O(1)
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int slowIndex = 0;
for (int fastIndex = 0; fastIndex < nums.size(); fastIndex++) {
if (val != nums[fastIndex]) {
nums[slowIndex++] = nums[fastIndex];
}
}
return slowIndex;
}
};
(移除元素)26. 删除有序数组中的重复项
给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
更改数组 nums ,使 nums 的前 k 个元素包含唯一元素,并按照它们最初在 nums 中出现的顺序排列。nums 的其余元素与 nums 的大小不重要。
返回 k 。
判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = […]; // 输入数组
int[] expectedNums = […]; // 长度正确的期望答案
int k = removeDuplicates(nums); // 调用
assert k == expectedNums.length;
for (int i = 0; i < k; i++) {
assert nums[i] == expectedNums[i];
}
如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
提示:
1 <= nums.length <= 3 * 104
-104 <= nums[i] <= 104
nums 已按 非严格递增 排列
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int k = 0;
int len = nums.size();
for (int i = 0; i < len; i ++ ) {
if (i != 0 && nums[i] == nums[i - 1]) k ++ ;
else nums[i - k] = nums[i];
}
return (len - k);
}
};
⭐️(移除元素)844. 比较含退格的字符串
给定 s 和 t 两个字符串,当它们分别被输入到空白的文本编辑器后,如果两者相等,返回 true 。# 代表退格字符。
注意:如果对空文本输入退格字符,文本继续为空。
示例 1:
输入:s = “ab#c”, t = “ad#c”
输出:true
解释:s 和 t 都会变成 “ac”。
示例 2:
输入:s = “ab##”, t = “c#d#”
输出:true
解释:s 和 t 都会变成 “”。
示例 3:
输入:s = “a#c”, t = “b”
输出:false
解释:s 会变成 “c”,但 t 仍然是 “b”。
提示:
1 <= s.length, t.length <= 200
s 和 t 只含有小写字母以及字符 ‘#’
一个字符是否会被删掉,只取决于该字符后面的退格符,而与该字符前面的退格符无关。因此当我们逆序地遍历字符串,就可以立即确定当前字符是否会被删掉。
具体地,我们定义 skip 表示当前待删除的字符的数量。每次我们遍历到一个字符:
若该字符为退格符,则我们需要多删除一个普通字符,我们让skip 加 1;
若该字符为普通字符:
若 skip 为 0,则说明当前字符不需要删去;
若 skip 不为 0,则说明当前字符需要删去,我们让 skip减 1。
这样,我们定义两个指针,分别指向两字符串的末尾。每次我们让两指针逆序地遍历两字符串,直到两字符串能够各自确定一个字符,然后将这两个字符进行比较。重复这一过程直到找到的两个字符不相等,或遍历完字符串为止。

class Solution {
public:
bool backspaceCompare(string s, string t) {
int skipS = 0, skipT = 0;
int i = s.size() - 1, j = t.size() - 1;
while (i >= 0 || j >= 0) {
while (i >= 0) {
if (s[i] == '#') {
skipS ++ ; i -- ;
} else if (skipS > 0) {
skipS -- ; i -- ;
} else {
break;
}
}
while (j >= 0) {
if (t[j] == '#') {
skipT ++ ; j -- ;
} else if (skipT > 0) {
skipT -- ; j -- ;
} else {
break;
}
}
if (i >= 0 && j >= 0) {
if (s[i] != t[j])
return false;
} else if (i >= 0 || j >= 0) {
return false;
}
i -- ; j -- ;
}
return true;
}
};
⭐️(双指针)977.有序数组的平方
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
输入:nums = [-4,-1,0,3,10]
输出:[0,1,9,16,100]
解释:平方后,数组变为 [16,1,0,9,100]
排序后,数组变为 [0,1,9,16,100]
示例 2:
输入:nums = [-7,-3,2,3,11]
输出:[4,9,9,49,121]
提示:
1 <= nums.length <= 104
-104 <= nums[i] <= 104
nums 已按 非递减顺序 排序
方法一(双指针)
利用「数组 nums 已经按照升序排序」这个条件。显然,如果数组 nums 中的所有数都是非负数,那么将每个数平方后,数组仍然保持升序;如果数组 nums 中的所有数都是负数,那么将每个数平方后,数组会保持降序。
这样一来,如果我们能够找到数组 nums 中负数与非负数的分界线,那么就可以用类似「归并排序」的方法了。具体地,我们设 neg 为数组 nums 中负数与非负数的分界线,也就是说,nums[0] 到 nums[neg] 均为负数,而 nums[neg+1] 到 nums[n−1] 均为非负数。当我们将数组 nums 中的数平方后,那么 nums[0] 到 nums[neg] 单调递减,nums[neg+1] 到 nums[n−1] 单调递增。
由于我们得到了两个已经有序的子数组,因此就可以使用归并的方法进行排序了。具体地,使用两个指针分别指向位置 neg 和 neg+1,每次比较两个指针对应的数,选择较小的那个放入答案并移动指针。当某一指针移至边界时,将另一指针还未遍历到的数依次放入答案。
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
int n = nums.size();
int negative = -1;
for (int i = 0; i < n; i ++ ) {
if (nums[i] < 0) negative = i;
else break;
}
vector<int> ans;
int i = negative, j = negative + 1;
while (i >= 0 || j < n) {
if (i < 0) {
ans.push_back(nums[j] * nums[j]);
j ++ ;
}
else if (j >= n) {
ans.push_back(nums[i] * nums[i]);
i -- ;
}
else if (nums[j] * nums[j] < nums[i] * nums[i]) {
ans.push_back(nums[j] * nums[j]);
j ++ ;
}
else {
ans.push_back(nums[i] * nums[i]);
i -- ;
}
}
return ans;
}
};
复杂度分析
时间复杂度:O(n)O(n)O(n),其中 nnn 是数组 nums\textit{nums}nums 的长度。
空间复杂度:O(1)O(1)O(1)。除了存储答案的数组以外,我们只需要维护常量空间。
方法二
同样地,我们可以使用两个指针分别指向位置 000 和 n−1n-1n−1,每次比较两个指针对应的数,选择较大的那个逆序放入答案并移动指针。这种方法无需处理某一指针移动至边界的情况,读者可以仔细思考其精髓所在。
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
int n = nums.size();
vector<int> ans(n);
for (int i = 0, j = n - 1, pos = n - 1; i <= j; ) {
if (nums[i] * nums[i] > nums[j] * nums[j]) {
ans[pos] = nums[i] * nums[i];
++ i;
}
else {
ans[pos] = nums[j] * nums[j];
-- j;
}
-- pos;
}
return ans;
}
};
复杂度分析
时间复杂度:O(n)O(n)O(n),其中 nnn 是数组 nums\textit{nums}nums 的长度。
空间复杂度:O(1)O(1)O(1)。除了存储答案的数组以外,我们只需要维护常量空间。
⭐️(滑动窗口)209.长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其总和大于等于 target 的长度最小的 连续
子数组
[numsl, numsl+1, …, numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
示例 3:
输入:target = 11, nums = [1,1,1,1,1,1,1,1]
输出:0
提示:
1 <= target <= 109
1 <= nums.length <= 105
1 <= nums[i] <= 105
进阶:
如果你已经实现 O(n) 时间复杂度的解法, 请尝试设计一个 O(n log(n)) 时间复杂度的解法。
滑动窗口
所谓滑动窗口,就是不断的调节子序列的起始位置和终止位置,从而得出我们要想的结果。
在暴力解法中,是一个for循环滑动窗口的起始位置,一个for循环为滑动窗口的终止位置,用两个for循环 完成了一个不断搜索区间的过程。
那么滑动窗口如何用一个for循环来完成这个操作呢。
首先要思考 如果用一个for循环,那么应该表示 滑动窗口的起始位置,还是终止位置。
如果只用一个for循环来表示 滑动窗口的起始位置,那么如何遍历剩下的终止位置?
此时难免再次陷入 暴力解法的怪圈。
所以 只用一个for循环,那么这个循环的索引,一定是表示 滑动窗口的终止位置。
窗口就是 满足其和 ≥ s 的长度最小的 连续 子数组。
窗口的起始位置如何移动:如果当前窗口的值大于等于s了,窗口就要向前移动了(也就是该缩小了)。
窗口的结束位置如何移动:窗口的结束位置就是遍历数组的指针,也就是for循环里的索引。
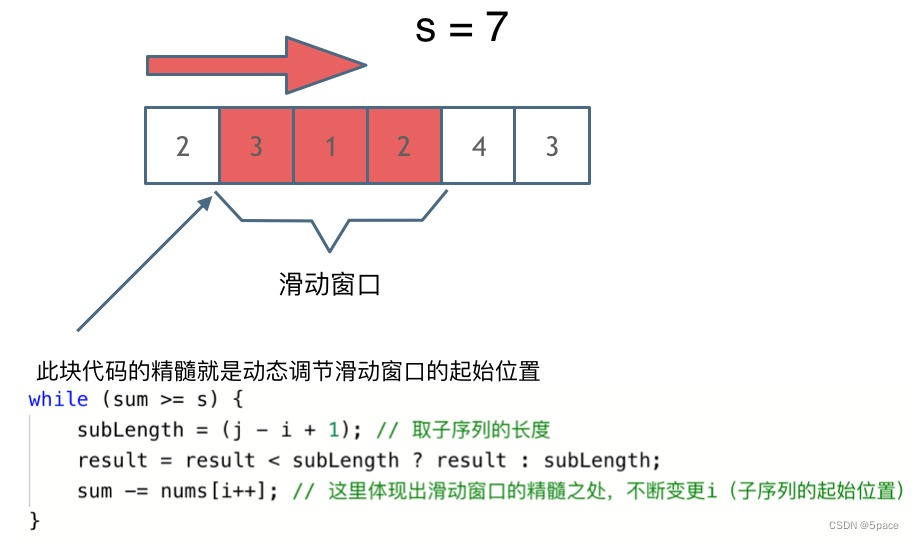
可以发现滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)暴力解法降为O(n)。
在方法一和方法二中,都是每次确定子数组的开始下标,然后得到长度最小的子数组,因此时间复杂度较高。为了降低时间复杂度,可以使用滑动窗口的方法。
定义两个指针 start 和 end 分别表示子数组(滑动窗口窗口)的开始位置和结束位置,维护变量 ssum 存储子数组中的元素和(即从 nums[start] 到 nums[end] 的元素和)。
初始状态下,start 和 end 都指向下标 0,sum 的值为 0。
每一轮迭代,将 nums[end] 加到 sum,如果 sum≥s,则更新子数组的最小长度(此时子数组的长度是 end−start+1),然后将 nums[start] 从 sum 中减去并将 start 右移,直到 sum<s,在此过程中同样更新子数组的最小长度。在每一轮迭代的最后,将 end 右移。
注意内层也是while,而不是if
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int n = nums.size();
if (n == 0) return 0;
int start = 0, end = 0;
int ans= INT_MAX;
int sum = 0;
while (end < n) {
sum += nums[end];
while (sum >= target) {
ans = min(ans, end - start + 1);
sum -= nums[start ++ ];
}
++ end;
}
return ans == INT_MAX ? 0 : ans;
}
};
复杂度分析
时间复杂度:O(n)O(n)O(n),其中 nnn 是数组的长度。指针 start 和 end 最多各移动 n 次。更好地:主要是看每一个元素被操作的次数,每个元素在滑动窗后进来操作一次,出去操作一次,每个元素都是被操作两次,所以时间复杂度是 2 × n 也就是O(n)。
空间复杂度:O(1)O(1)O(1)。
(滑动窗口)713.乘积小于K的子数组
给你一个整数数组 nums 和一个整数 k ,请你返回子数组内所有元素的乘积严格小于 k 的连续子数组的数目。
示例 1:
输入:nums = [10,5,2,6], k = 100
输出:8
解释:8 个乘积小于 100 的子数组分别为:[10]、[5]、[2],、[6]、[10,5]、[5,2]、[2,6]、[5,2,6]。
需要注意的是 [10,5,2] 并不是乘积小于 100 的子数组。
示例 2:
输入:nums = [1,2,3], k = 0
输出:0
提示:
1 <= nums.length <= 3 * 104
1 <= nums[i] <= 1000
0 <= k <= 106

注意到元素>=1,也就是说滑动窗口中的乘积具有单调性,在右端点固定不变的情况下,随着左端点向右移动,乘积非严格递减。因此,在右端点右移动的过程中,左端点不动或右移动。
class Solution {
public:
int numSubarrayProductLessThanK(vector<int>& nums, int k) {
int n = nums.size();
int start = 0, end = 0;
int ans = 0;
long long multi = 1;
while (end < n) {
multi *= nums[end];
while (multi >= k && start < end) {
multi /= nums[start ++ ];
}
if (multi < k) ans += end - start + 1;
++end;
}
return ans;
}
};
⭐️(滑动窗口)3. 无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长
子串
的长度。
示例 1:
输入: s = “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: s = “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: s = “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
提示:
0 <= s.length <= 5 * 104
s 由英文字母、数字、符号和空格组成
这道题仍然满足滑动窗口的单调性
class Solution {
public:
int lengthOfLongestSubstring(string s) {
if (s.size() == 0) return 0;
int n = s.size();
int ans = 0;
unordered_set<char> se;
int left = 0;
for (int right = 0; right < n; right ++ ) {
while (se.find(s[right]) != se.end()) {
se.erase(s[left ++ ]);
}
se.insert(s[right]);
ans = max(ans, right - left + 1);
}
return ans;
}
};
⭐️(滑动窗口)904. 水果成篮
你正在探访一家农场,农场从左到右种植了一排果树。这些树用一个整数数组 fruits 表示,其中 fruits[i] 是第 i 棵树上的水果 种类 。
你想要尽可能多地收集水果。然而,农场的主人设定了一些严格的规矩,你必须按照要求采摘水果:
你只有 两个 篮子,并且每个篮子只能装 单一类型 的水果。每个篮子能够装的水果总量没有限制。
你可以选择任意一棵树开始采摘,你必须从 每棵 树(包括开始采摘的树)上 恰好摘一个水果 。采摘的水果应当符合篮子中的水果类型。每采摘一次,你将会向右移动到下一棵树,并继续采摘。
一旦你走到某棵树前,但水果不符合篮子的水果类型,那么就必须停止采摘。
给你一个整数数组 fruits ,返回你可以收集的水果的 最大 数目。
示例 1:
输入:fruits = [1,2,1]
输出:3
解释:可以采摘全部 3 棵树。
示例 2:
输入:fruits = [0,1,2,2]
输出:3
解释:可以采摘 [1,2,2] 这三棵树。
如果从第一棵树开始采摘,则只能采摘 [0,1] 这两棵树。
示例 3:
输入:fruits = [1,2,3,2,2]
输出:4
解释:可以采摘 [2,3,2,2] 这四棵树。
如果从第一棵树开始采摘,则只能采摘 [1,2] 这两棵树。
示例 4:
输入:fruits = [3,3,3,1,2,1,1,2,3,3,4]
输出:5
解释:可以采摘 [1,2,1,1,2] 这五棵树。
提示:
1 <= fruits.length <= 105
0 <= fruits[i] < fruits.length
滑动窗口
我们可以使用滑动窗口解决本题,left 和 right 分别表示满足要求的窗口的左右边界,同时我们使用哈希表存储这个窗口内的数以及出现的次数。
我们每次将 right 移动一个位置,并将 fruits[right] 加入哈希表。如果此时哈希表不满足要求(即哈希表中出现超过两个键值对),那么我们需要不断移动 left,并将 fruits[left] 从哈希表中移除,直到哈希表满足要求为止。
需要注意的是,将 fruits[left] 从哈希表中移除后,如果 fruits[left] 在哈希表中的出现次数减少为 0,需要将对应的键值对从哈希表中移除。
class Solution {
public:
int totalFruit(vector<int>& fruits) {
int n = fruits.size();
unordered_map<int, int> cnt;
int start = 0, ans = 0;
for (int end = 0; end < n; ++end) {
++cnt[fruits[end]];
while (cnt.size() > 2) {
auto it = cnt.find(fruits[start]);
--it->second;
++start;
if (it->second == 0) {
cnt.erase(it);
}
}
ans = max(ans, end - start + 1);
}
return ans;
}
};
复杂度分析
时间复杂度:O(n),其中 n 是数组 fruits 的长度。
空间复杂度:O(1)。哈希表中最多会有三个键值对,可以看成使用了常数级别的空间。
⭐️(滑动窗口)76.最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
注意:
对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:“BANC”
解释:最小覆盖子串 “BANC” 包含来自字符串 t 的 ‘A’、‘B’ 和 ‘C’。
示例 2:
输入:s = “a”, t = “a”
输出:“a”
解释:整个字符串 s 是最小覆盖子串。
示例 3:
输入: s = “a”, t = “aa”
输出: “”
解释: t 中两个字符 ‘a’ 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。
提示:
m == s.length
n == t.length
1 <= m, n <= 10^5
s 和 t 由英文字母组成
进阶:你能设计一个在 o(m+n) 时间内解决此问题的算法吗?
同样是滑动窗口,这两题有什么区别?区别在于76题求的是最小滑窗,而本题求的是最大滑窗。
方法一
前置知识:滑动窗口
如果您不知道滑动窗口,推荐先看视频 滑动窗口【基础算法精讲 03】,并完成 209. 长度最小的子数组 作为本题的铺垫,因为这两题都属于「最短型」滑动窗口。
什么是「涵盖」
看示例 1,s 的子串 BANC 中每个字母的出现次数,都大于等于 t=ABC 中每个字母的出现次数,这就叫涵盖。
滑动窗口怎么滑
原理和 209 题一样,按照视频中的做法,我们枚举 sss 子串的右端点 right(子串最后一个字母的下标),如果子串涵盖 ttt,就不断移动左端点 left 直到不涵盖为止。在移动过程中更新最短子串的左右端点。
具体来说:
1、初始化 ansLeft=−1, ansRight=m,用来记录最短子串的左右端点,其中 m 是 s 的长度。
2、用一个哈希表(或者数组)cntT 统计 t 中每个字母的出现次数。
3、初始化 left=0,以及一个空哈希表(或者数组)cntS,用来统计 s 子串中每个字母的出现次数。
4、遍历 s,设当前枚举的子串右端点为 right,把 s[right] 的出现次数加一。
5、遍历 cntS 中的每个字母及其出现次数,如果出现次数都大于等于 cntT\textit{cntT}cntT 中的字母出现次数:
如果 right−left<ansRight−ansLeft,说明我们找到了更短的子串,更新 ansLeft=left, ansRight=right。
把 s[left] 的出现次数减一。
左端点右移,即 left 加一。
重复上述三步,直到 cntS 有字母的出现次数小于 cntT 中该字母的出现次数为止。
6、最后,如果 ansLeft<0,说明没有找到符合要求的子串,返回空字符串,否则返回下标 ansLeft 到下标 ansRight 之间的子串。
由于本题大写字母和小写字母都有,为了方便,代码实现时可以直接创建大小为 128 的数组,保证所有 ASCII 字符都可以统计。
class Solution {
public:
bool is_covered(int cnt_s[], int cnt_t[]) {
for (int i = 'A'; i <= 'Z'; i ++ ) {
if (cnt_s[i] < cnt_t[i]) {
return false;
}
}
for (int i = 'a'; i <= 'z'; i ++ ) {
if (cnt_s[i] < cnt_t[i]) {
return false;
}
}
return true;
}
string minWindow(string s, string t) {
int m = s.length();
int cnt_s[128]{}, cnt_t[128]{};
for (char c : t) {
cnt_t[c] ++ ;
}
int ans_left = -1, ans_right = m, left = 0;
for (int right = 0; right < m; right ++ ) {
cnt_s[s[right]] ++ ;
while (is_covered(cnt_s, cnt_t)) {
if (right - left < ans_right - ans_left) {
ans_left = left;
ans_right = right;
}
cnt_s[s[left ++ ]] -- ;
}
}
return ans_left < 0 ? "" : s.substr(ans_left, ans_right - ans_left + 1);
}
};
复杂度分析
时间复杂度:O(∣Σ∣m+n),其中 m 为 s 的长度,n 为 tt 的长度,∣Σ∣ 为字符集合的大小,本题字符均为英文字母,所以 ∣Σ∣=52。注意 left 只会增加不会减少,left 每增加一次,我们就花费 O(∣Σ∣) 的时间。因为 left 至多增加 m 次,所以二重循环的时间复杂度为 O(∣Σ∣m),再算上统计 t 字母出现次数的时间 O(n),总的时间复杂度为 O(∣Σ∣m+n)。
空间复杂度:O(∣Σ∣)。如果创建了大小为 128 的数组,则 ∣Σ∣=128。
方法二:优化
上面的代码每次都要花费 O(∣Σ∣) 的时间去判断是否涵盖,能不能优化到 O(1) 呢?
可以。用一个变量 less 维护目前子串中有 less 种字母的出现次数小于 t 中字母的出现次数。
具体来说(注意下面算法中的 less 变量):
1、初始化 ansLeft=−1, ansRight=m,用来记录最短子串的左右端点,其中 m 是 s 的长度。
2、用一个哈希表(或者数组)cntT 统计 t 中每个字母的出现次数。
3、初始化 left=0,以及一个空哈希表(或者数组)cntS,用来统计 s 子串中每个字母的出现次数。
4、初始化 less 为 t 中的不同字母个数。
5、遍历 s,设当前枚举的子串右端点为 right,把字母 c=s[right] 的出现次数加一。加一后,如果 cntS[c]=cntT[c],说明 c 的出现次数满足要求,把 less 减一。
6、如果 less=0,说明 cntS 中的每个字母及其出现次数都大于等于 cntT 中的字母出现次数,那么:
如果 right−left<ansRight−ansLeft,说明我们找到了更短的子串,更新 ansLeft=left, ansRight=right。
把字母 x=s[left]的出现次数减一。减一前,如果 cntS[x]=cntT[x],说明 x 的出现次数不满足要求,把 less 加一。
左端点右移,即 left 加一。
重复上述三步,直到 less>0,即 cntS 有字母的出现次数小于 cntT 中该字母的出现次数为止。
7、最后,如果 ansLeft<0,说明没有找到符合要求的子串,返回空字符串,否则返回下标 ansLeft 到下标 ansRight 之间的子串。

class Solution {
public:
string minWindow(string s, string t) {
int m = s.length();
int cnt_s[128]{}, cnt_t[128]{};
int ans_left = -1, ans_right = m, left = 0;
int less = 0;
for (char c : t) {
cnt_t[c] ++ ;
if (cnt_t[c] == 1) {
less ++ ;
}
}
for (int right = 0; right < m; right ++ ) {
char c = s[right];
cnt_s[c] ++ ;
if (cnt_s[c] == cnt_t[c]) {
less -- ;
}
while (less == 0) {
if (ans_right - ans_left > right - left) {
ans_left = left;
ans_right = right;
}
c = s[left ++ ];
cnt_s[c] -- ;
if (cnt_s[c] < cnt_t[c]) {
less ++ ;
}
}
}
return ans_left < 0 ? "" : s.substr(ans_left, ans_right - ans_left + 1);
}
};
复杂度分析
时间复杂度:O(m+n) 或 O(m+n+∣Σ∣)(创建大小为 ∣Σ∣ 的数组需要 O(∣Σ∣) 的时间。),其中 m 为 s 的长度,n 为 t 的长度,∣Σ∣=128。注意 left 只会增加不会减少,二重循环的时间复杂度为 O(m)。使用哈希表写法的时间复杂度为 O(m+n),数组写法的时间复杂度为 O(m+n+∣Σ∣)。
空间复杂度:O(∣Σ∣)。无论 m 和 n 有多大,额外空间都不会超过 O(∣Σ∣)。

⭐️(滑动窗口)1004. 最大连续1的个数 |||
给定一个二进制数组 nums 和一个整数 k,如果可以翻转最多 k 个 0 ,则返回 数组中连续 1 的最大个数 。
示例 1:
输入:nums = [1,1,1,0,0,0,1,1,1,1,0], K = 2
输出:6
解释:[1,1,1,0,0,1,1,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 6。
示例 2:
输入:nums = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3
输出:10
解释:[0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 10。
提示:
1 <= nums.length <= 105
nums[i] 不是 0 就是 1
0 <= k <= nums.length
对于数组 AAA 的区间 [left,right] 而言,只要它包含不超过 k 个 0,我们就可以根据它构造出一段满足要求,并且长度为 right−left+1 的区间。
因此,我们可以将该问题进行如下的转化,即:
对于任意的右端点 right,希望找到最小的左端点 left,使得 [left,right] 包含不超过 k 个 0。
只要我们枚举所有可能的右端点,将得到的区间的长度取最大值,即可得到答案。
要想快速判断一个区间内 0 的个数,我们可以考虑将数组 A 中的 0 变成 1,1 变成 0。此时,我们对数组 A 求出前缀和,记为数组 P,那么 [left,right] 中包含不超过 k 个 1(注意这里就不是 0 了),当且仅当二者的前缀和之差:
P[right]−P[left−1]小于等于 k。这样一来,我们就可以容易地解决这个问题了。
方法一(滑动窗口)

class Solution {
public:
int longestOnes(vector<int>& nums, int k) {
int n = nums.size();
int left = 0;
int cnt0 = 0, cnt1 = 0;
int ans = 0;
for (int right = 0; right < n; right ++ ) {
if (nums[right] == 0) cnt0 ++ ;
else cnt1 ++ ;
while (cnt0 > k && left < right) {
if (nums[left] == 0) cnt0 -- ;
else cnt1 -- ;
left ++ ;
}
if (cnt0 <= k) ans = max(ans, cnt0 + cnt1);
}
return ans;
}
};
方法二(二分)
待补
⭐️59.螺旋矩阵II
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
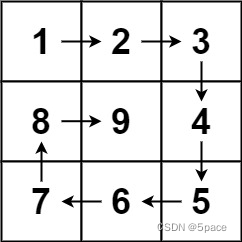
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
示例 2:
输入:n = 1
输出:[[1]]
提示:
1 <= n <= 20
方法一
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> mat(n, vector<int>(n));
int cnt = 1;
int l = 0, r = n - 1, t = 0, b = n - 1;
while (cnt <= n * n) {
for (int i = l; i <= r; i ++ ) mat[t][i] = cnt ++ ;
t ++ ;
for (int i = t; i <= b; i ++ ) mat[i][r] = cnt ++ ;
r -- ;
for (int i = r; i >= l; i -- ) mat[b][i] = cnt ++ ;
b -- ;
for (int i = b; i >= t; i -- ) mat[i][l] = cnt ++ ;
l ++ ;
}
return mat;
}
};
方法二(优)

class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> mat(n, vector<int>(n, 0));
int l = 0, r = n - 1;
int cnt = 1;
while (l < r) {
for (int i = l; i < r; i ++ ) mat[l][i] = cnt ++ ;
for (int i = l; i < r; i ++ ) mat[i][r] = cnt ++ ;
for (int i = r; i > l; i -- ) mat[r][i] = cnt ++ ;
for (int i = r; i > l; i -- ) mat[i][l] = cnt ++ ;
l ++ ;
r -- ;
}
if (n % 2 == 1) mat[l][l] = cnt;
return mat;
}
};
⭐️54. 螺旋矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:

输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
示例 2:
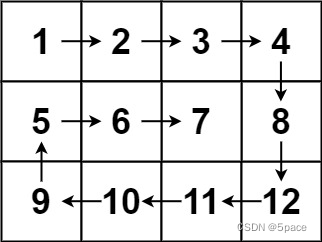
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 10
-100 <= matrix[i][j] <= 100

class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
vector<int> ans;
if (matrix.empty()) return ans;
int l = 0, r = matrix[0].size() - 1;
int t = 0, b = matrix.size() -1;
int all = (r + 1) * (b + 1);
int cnt = 1;
while (cnt <= all) {
for (int i = l; i <= r; i ++ ) {
ans.push_back(matrix[t][i]);
cnt ++ ;
}
if (t >= b) break;
t ++ ;
for (int i = t; i <= b; i ++ ) {
ans.push_back(matrix[i][r]);
cnt ++ ;
}
if (r <= l) break;
r -- ;
for (int i = r; i >= l ; i -- ) {
ans.push_back(matrix[b][i]);
cnt ++ ;
}
b -- ;
for (int i = b; i >= t; i -- ) {
ans.push_back(matrix[i][l]);
cnt ++ ;
}
l ++ ;
}
return ans;
}
};
















 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









