






一、任务
题目:并行化矩阵乘法。使用OpenMP,编写一个并行化的程序,实现两个矩阵的乘法。给定两个矩阵A和 B,它们的维度分别为m×n和n×p。请编写一个并行程序计算它们的乘积矩阵C,其中C的维度为m×p。
二、原理
1. Openmp
OpenMP是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受,用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive) 。OpenMP支持的编程语言包括C、C++和Fortran;而支持OpenMp的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
2. 具体实现
- OpenMP编译必须包含头文件<omp.h>.
- 通过预处理指示符 #pragma omp 来表示使用OpenMP. 例如通过 #pragma om parallel for 来指定下方的for循环采用多线程执行,此时编译器会根据CPU的个数来创建线程数。对于双核系统,编译器会默认创建两个线程执行并行区域的代码。
示例代码:
#include <iostream>
#include <stdio.h>
#include <omp.h> // OpenMP编译需要包含的头文件
int main()
{
#pragma omp parallel for
for (int i = 0; i < 10; ++i)
{
printf("%d",i);
}
return 0;
}
结果:
5136809427请按任意键继续
2.1 OpenMP常用函数
暂时无法在飞书文档外展示此内容
2.2 并行区域
#pragma omp parallel //大括号内为并行区域
{
//put parallel code here.
}
更多语法及选项(来自wiki)
#pragma omp <directive> [clause[[,] clause] ...]
directive
- atomic 内存位置将会原子更新(Specifies that a memory location that will be updated atomically.)
- barrier 线程在此等待,直到所有的线程都执行到此barrier。用来同步所有线程。
- critical 其后的代码块为临界区,任意时刻只能被一个线程执行。
- flush 所有线程对所有共享对象具有相同的内存视图(view of memory)
- for 用在for循环之前,把for循环并行化由多个线程执行。循环变量只能是整型
- master 指定由主线程来执行接下来的程式。
- ordered 指定在接下来的代码块中,被并行化的 for循环将依序执行(sequential loop)
- parallel 代表接下来的代码块将被多个线程并行各执行一遍。
- sections 将接下来的代码块包含将被并行执行的section块。
- single 之后的程式将只会在一个线程(未必是主线程)中被执行,不会被并行执行。
- threadprivate 指定一个变量是线程局部存储(thread local storage)
clause
- copyin 让threadprivate的变量的值和主线程的值相同。
- copyprivate 不同线程中的变量在所有线程中共享。
- default Specifies the behavior of unscoped variables in a parallel region.
- firstprivate 对于线程局部存储的变量,其初值是进入并行区之前的值。
- if 判断条件,可用来决定是否要并行化。
- lastprivate 在一个循环并行执行结束后,指定变量的值为循环体在顺序最后一次执行时取得的值,或者#pragma sections在中,按文本顺序最后一个section中执行取得的值。
- nowait 忽略barrier的同步等待。
- num_threads 设定线程数量的数量。默认值为当前计算机硬件支持的最大并发数。一般就是CPU的内核数目。超线程被操作系统视为独立的CPU内核。
- ordered 使用于 for,可以在将循环并行化的时候,将程式中有标记 directive ordered 的部份依序执行。
- private 指定变量为线程局部存储。
- reduction Specifies that one or more variables that are private to each thread are the subject of a reduction operation at the end of the
parallel region.- schedule 设定for循环的并行化方法;有 dynamic、guided、runtime、static 四种方法。
- schedule(static, chunk_size) 把chunk_size数目的循环体的执行,静态依序指定给各线程。
- schedule(dynamic, chunk_size) 把循环体的执行按照chunk_size(缺省值为1)分为若干组(即chunk),每个等待的线程获得当前一组去执行,执行完后重新等待分配新的组。
- schedule(guided, chunk_size) 把循环体的执行分组,分配给等待执行的线程。最初的组中的循环体执行数目较大,然后逐渐按指数方式下降到chunk_size。
- schedule(runtime) 循环的并行化方式不在编译时静态确定,而是推迟到程序执行时动态地根据环境变量OMP_SCHEDULE 来决定要使用的方法。
- shared 指定变量为所有线程共享。
2.3 for 循环并行化基本用法
2.3.1 数据不相关性
利用 OpenMP 实现for循环的并行化,需满足数据的不相关性。
在循环并行化时,多个线程同时执行循环,迭代的顺序是不确定的。如果数据是非相关的,那么可以采用基本的 #pragma omp parallel for 预处理指示符。
如果语句S2与语句S1相关,那么必然存在以下两种情况之一:
- 语句S1在一次迭代中访问存储单元L,而S2在随后的一次迭代中访问同一存储单元,称之为循环迭代相关(loop carried dependence);
- S1和S2在同一循环迭代中访问同一存储单元L,但S1的执行在S2之前,称之为非循环迭代相关(loop-independent dependence)。
2.3.2 for循环并行化的几种声明形式
#include <iostream>
#include <omp.h>
int main()
{
//声明形式一
#pragma omp parallel
{
#pragma omp for
for (int i = 0; i < 10; ++i)
{
std::cout << i << std::endl;
}
}
//声明形式二
#pragma omp parallel for
for (int i = 0; i < 10; ++i)
{
std::cout << i << std:: endl;
}
return 0;
}
上面代码的两种声明形式是一样的,可见第二种形式更为简洁。不过,第一种形式有一个好处:可以在并行区域内、for循环以外插入其他并行代码。
2.3.3 for 循环并行化的约束条件
尽管OpenMP可以很方便地对for循环进行并行化,但并不是所有的for循环都可以并行化。下面几种情形的for循环便不可以:
- for循环的循环变量必须是有符号型。例如,for(unsigned int i = 0; i < 10; ++i){…}编译不通过。
- for循环的比较操作符必须是== <, <=, >, >= 。例如,``编译不通过。
- for循环的增量必须是整数的加减,而且必须是一个循环不变量。例如,for(int i = 0; i < 10; i = i+1)编译不通过,感觉只能++i, i++, --i, i–。
- for循环的比较操作符如果是<, <=,那么循环变量只能增加。例如,for(int i = 0; i != 10; --i)编译不通过。
- 循环必须是单入口,单出口==。循环内部不允许能够达到循环以外的跳出语句,exit除外。异常的处理也不必须在循环体内部处理。例如,如循环体内的break或者goto语句,会导致编译不通过。
三、环境
openMP支持的编程语言包括C语言、C++和Fortran,支持OpenMP的编译器包括Sun Studio,Intel Compiler,Microsoft Visual Studio,GCC。我使用CFree5编译器, CPU为6核AMD,配置GCC环境。
第一步:安装mingw
https://sourceforge.net/projects/mingw/
去这个网站下载mingw,下载后的exe运行即可。
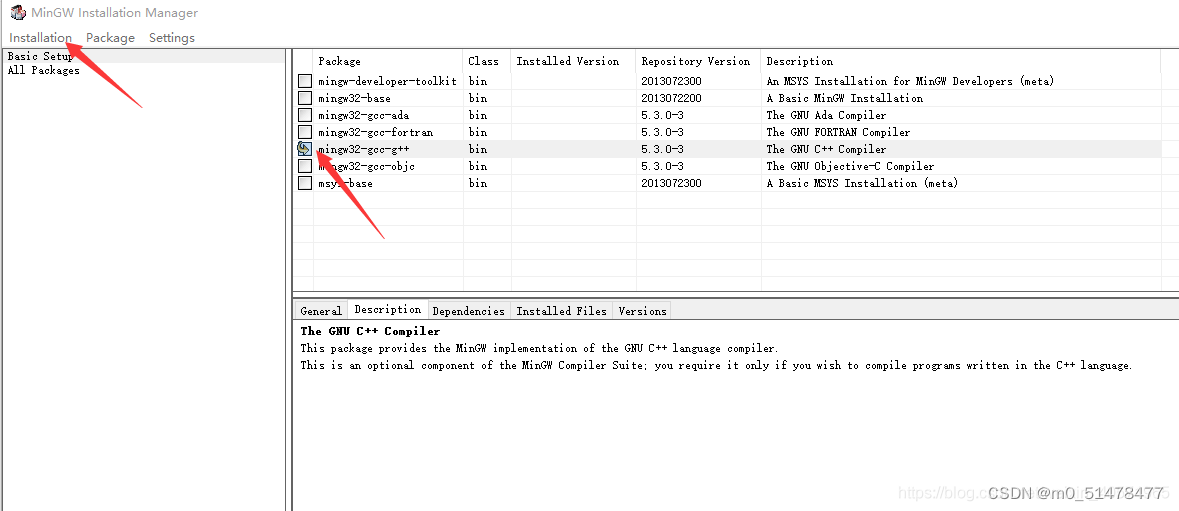
右键点击Mark for Installation。
点击左上角的Installation菜单中的Apply changes选项,然后管理器将开始在线安装或更新被选中的组件。
要记住安装的路径
第二步:配置环境变量
我的电脑->属性->高级系统设置->环境变量->系统变量系统变量->Path->编辑->新建->D:\mingw\bin->确定
系统变量->新建->变量名:LIBRARY_path->变量值:D:\mingw\lib->确定
系统变量->新建->变量名:C_INCLUDE_PATH->变量值:D:\mingw\include->确定
下面就可以验证下我们有没有安装成功把,打开终端,输入
gcc -v
就会出现安装成功的一大堆东西。
下面就可以在终端编译我们写好的C语言程序了。
gcc test.c -o test
第三步:为C-Free配置新版本的gcc编译器
打开C-Free,选择导航栏”构建“-”构建选项“,
可以看出其自带的gcc编译器是3.4.5版本的,非常古老。然后点debug旁边的小箭头,选择“新建配置”。
在“编译器类型”一栏选择“MinGW”,注意不要选择“MinGW(Old)",然后配置名称就随便填一个(我填的是gcctest)就行,确定之后需要手动指定mingw安装路径
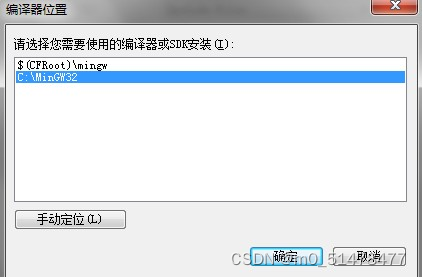
确定之后,就可以看到成功新建了一个GCC编译配置了。
第四步:添加线程工具
问题如下:windows下在命令行模式下使用MinGW编译openmp的C代码,会出现cannot find lpthread。
由于Mingw下没有带pthread库,所以在eclipse中设置多线程动态链接库,也不管用。需要自己下载,
ftp://sourceware.org/pub/pthreads-win32/pthreads-w32-2-8-0-release.exe
解开pthreads-w32-2-8-0-release.exe,把Pre- built.2中的libpthreadGC2.a改名为libpthread.a复制到c:\mingw\lib目录,把include目录下的pthread.h复制到c: \mingw\include目录即可。
第五步:C-FREE开启omp编程支持
C-Free是一款支持多种编译器的专业化C/C++集成开发环境(IDE)。OpenMP是作为共享存储标准而问世的。它是为在多处理机上编写并行程序而设计的一个应用编程接口。它包括一套编译指导语句和一个用来支持它的函数库。具体在cfree里面开启omp的编译支持需要对“构建选项”里面做一些修改。
具体操作如下:选择自己构建的mingw编译器,并把配置切换为release
在编译参数里添加
-fopenmp
(openmp是GCC自带的,在编译时需要加入-fopenmp参数。)
![[图片]](https://img-blog.csdnimg.cn/direct/6e343af60e824987b6f61e4067589106.png)
在连接参数里添加
-lgomp -lpthread
![[图片]](https://img-blog.csdnimg.cn/direct/ceb35f4a16e143fba09138be29b8aedd.png)
之后点击确定就可以了。
四、代码
#include <stdio.h>
#include <omp.h>
#define M 100
#define N 1000
#define P 100
void matrix_multiply(int A[M][N], int B[N][P], int C[M][P]) {
#pragma omp parallel for
for (int i = 0; i < M; ++i) {
for (int j = 0; j < P; ++j) {
C[i][j] = 0;
for (int k = 0; k < N; ++k) {
C[i][j] += A[i][k] * B[k][j];
}
//printf("%d\t",C[i][j]);
}
}
}
void matrix_non_multiply(int A[M][N], int B[N][P], int C[M][P]) {
for (int i = 0; i < M; ++i) {
for (int j = 0; j < P; ++j) {
C[i][j] = 0;
for (int k = 0; k < N; ++k) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
}
int main() {
int A[M][N];
int B[N][P];
int C[M][P];
omp_set_num_threads(4); // 设置线程数为4,可以根据实际情况调整
// Perform matrix multiplication
double start_time = omp_get_wtime();
matrix_multiply(A, B, C);
double end_time = omp_get_wtime();
// Print the execution time
printf("multiply Execution time: %f seconds\n", end_time - start_time);
// Perform matrix multiplication
start_time = omp_get_wtime();
matrix_non_multiply(A, B, C);
end_time = omp_get_wtime();
// Print the execution time
printf("Unmultiply Execution time: %f seconds\n", end_time - start_time);
return 0;
}

五、遇到的问题
- 控制台输出为空,只有“请按任意键继续”。在main函数中添加printf测试语句也没有对应的输出结果。
解决方法:
将
#define M 1000
#define N 1000
#define P 1000
减小数据量,就有输出了
#define M 100
#define N 100
#define P 100 //或 1000
- 程序速度为0.002,注释掉
#pragma omp parallel for这一行代码的程序速度为0.001
可能的原因:- 线程创建和同步开销:并行化通常涉及线程的创建和同步操作。对于小规模的任务,线程创建和同步的开销可能会超过并行执行带来的性能优势。因此,在任务规模较小的情况下,并行化可能不如串行执行快。
- 负载不均衡: 当任务被拆分成多个子任务交给不同线程执行时,如果这些子任务的负载不均衡,一些线程可能会比其他线程更早完成工作,然后被阻塞等待其他线程。这种情况也可能导致并行化的性能不佳。
- 硬件限制: 并行化的性能还受限于硬件配置。有些计算机系统上,线程的创建和同步可能会受到一些硬件限制,导致并行化的效果不如期望。
- 使用
omp_set_num_threads(4);就不会出现问题2的情况,即并行计算速度快于顺序计算。
参考
- 【已解决】win10终端编译C语言脚本,报"gcc不是内部或外部命令,也不是可运行的程序或批处理文件"_gcc’ 不是内部或外部命令,也不是可运行的程序 或批处理文件。-CSDN博客
- 玩转轻巧型C/C++ IDE之C-Free(配置GCC、Visual C++、Borland C++编译器) - Matrix海子 - 博客园
- C-FREE开启omp编程支持_omp支持-CSDN博客
- 求教——Windowds下用Eclipse写C++代码提示 cannot find -lpthread-CSDN社区
- windows下在命令行模式下使用MinGW编译C代码,出现cannot find ipthread-CSDN博客
- 【OpenMP】OpenMP: 多线程文件操作_#pragma omp parallel-CSDN博客
- OpenMP(使用C++多线程并行计算优化你的程序)入门篇















 2833
2833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









