







各种学习资源
单词词典
数据库表的设计
数据模型主要由四个表组成:word_book_category、word_books、word 和 word_relation。其中,category 表包含单词库的分类信息,word_book 表对应单词书,word 表存储单词信息,word_relation 表关联单词书与单词。确保数据完整性,避免重复单词的问题。
- 插入单词库类别 :根据文件夹名称插入到
word_book_category表。 - 插入单词书 :根据 Excel 文件名插入到
word_books表,并关联category_id。 - 插入单词 :将单词数据插入到
word表,如果重复,则不重复插入。 - 插入关联 :在
word_relation表中关联单词书与单词,确保即使单词重复,也能区分其关联的单词书。
-
运行一半发现报错了:导入文件夹 ‘E:\GraduationDesign\词典库\含音标(新版)\1.中考’ 时出错:nan can not be used with MySQL
-
查看表格数据才发现有的音标是空的,得加个判断,mysql不能存nan
def insert_word(cursor, word, phonetic_uk, phonetic_us, definition): # 处理可能的空值 phonetic_uk = phonetic_uk if phonetic_uk else "" phonetic_us = phonetic_us if phonetic_us else "" definition = definition if definition else "" -
发现还是报这个错,得使用
pd.isna判断# 检查数据是否为 NaN,如果是,则替换为 None phonetic_uk = None if pd.isna(phonetic_uk) else phonetic_uk phonetic_us = None if pd.isna(phonetic_us) else phonetic_us definition = None if pd.isna(definition) else definition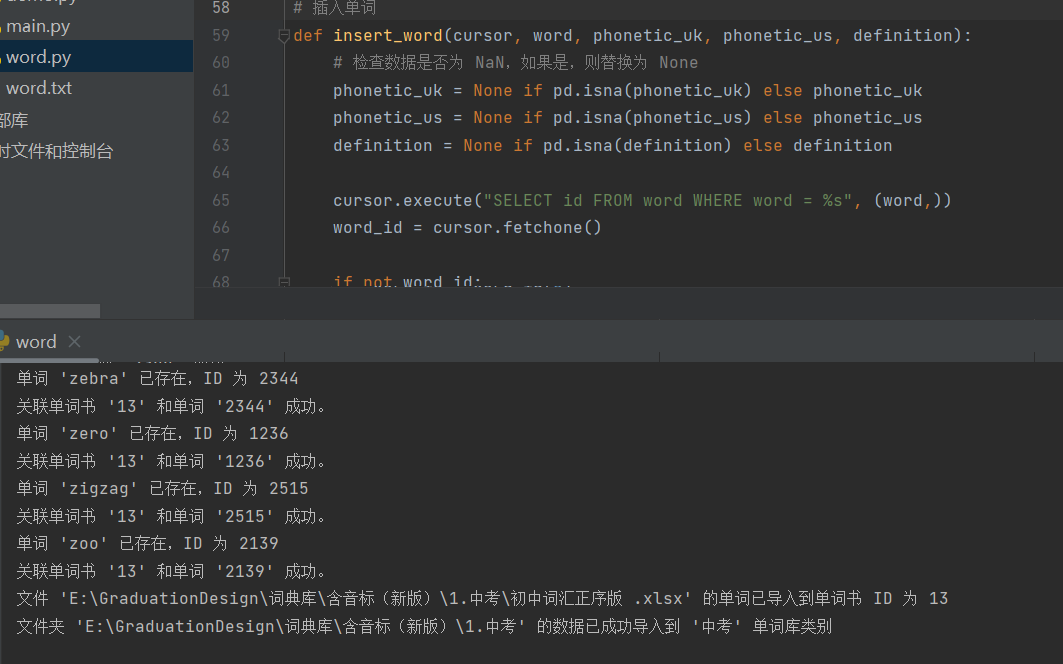
-
又报错了
-
发现有的表里没有列,单词,音标,释义这些
-
通过脚本添加这四列
import requests import os from lxml import etree from openpyxl.styles import Font from openpyxl.styles import Alignment from openpyxl.styles import Side, Border from openpyxl import load_workbook def get_phonetic(): print('————' * 10) workbook = load_workbook(file) # 导入excel表格 worksheet = workbook['Sheet1'] # 读取excel中的sheet1这张表 worksheet.insert_cols(idx=2, amount=2) # 向右插入两列准备存放数据,idx:插入列的位置,amount:插入的列数 worksheet.insert_rows(idx=0, amount=1) # 在顶部插入一行写入注释,idx:插入行的位置,amount:插入的行数 worksheet['A1'] = '单词' # 如果你的单词本第一行原本就有这些注释就不用这代码了,直接删掉就行 worksheet['B1'] = '英音' worksheet['C1'] = '美音' worksheet['D1'] = '释义' font = Font(name='微软雅黑', size=20, bold=False) # 设置全局字体大小样式 worksheet['A1'].font = font worksheet['B1'].font = font worksheet['C1'].font = font worksheet['D1'].font = font alignment = Alignment(horizontal="left") # 设置单元格对齐方式,用于修复墨墨词库csv文件顶部两处单元格的对齐异常问题 worksheet['A2'].alignment = alignment # 如果不需要此代码可删除 worksheet['D2'].alignment = alignment # 如果不需要此代码可删除 border = Border(Side(style=None)) # 设置单元格边框样式,用于修复墨墨词库csv文件顶部两处单元格的边框异常问题 worksheet['A2'].border = border # 如果不需要此代码可删除 worksheet['D2'].border = border # 如果不需要此代码可删除 worksheet.column_dimensions['A'].width = 30 # 设置全局列宽 worksheet.column_dimensions['B'].width = 30 worksheet.column_dimensions['C'].width = 30 worksheet.column_dimensions['D'].width = 30 workbook.save(file) row_index = 2 # 默认结果放到第二行开始 for row in worksheet.iter_rows(min_row=2, max_col=3): # 以行迭代(最小第二行,最多第3列) word = row[0].value # 获取第一列所有表格数据 # 请确保你的单词在第1列,如果你的单词在第N列,请将代码换成:word = row[0+N].value,还要记得改其他各处代码中的数字! url = 'https://www.youdao.com/w/eng/{}'.format(word) # 从有道获取音标 try: data = requests.get(url).text html = etree.HTML(data) num1 = 'A' + str(row_index) num2 = 'B' + str(row_index) num3 = 'C' + str(row_index) num4 = 'D' + str(row_index) British_pron = html.xpath('//*[@id="phrsListTab"]/h2/div/span[1]/span/text()')[0] American_pron = html.xpath('//*[@id="phrsListTab"]/h2/div/span[2]/span/text()')[0] print('正在输出:' + British_pron, American_pron) worksheet.cell(row=row_index, column=2).value = British_pron # 默认将英式音标的结果放到第2列 worksheet.cell(row=row_index, column=3).value = American_pron # 默认将美式音标的结果放到第3列 worksheet[num1].font = font worksheet[num2].font = font worksheet[num3].font = font worksheet[num4].font = font except Exception as e: print(e, word) num1 = 'A' + str(row_index) num4 = 'D' + str(row_index) worksheet[num1].font = font worksheet[num4].font = font row_index += 1 workbook.save(file) print("单词音标全部转换完毕!已经成功保存在原文件:" + file) print('————' * 10) if __name__ == '__main__': file_list = [] print('欢迎来到多个xlsx批量单词音标转换小程序') print('注意事项:\n' '1.请确保你的网络通畅!\n' '2.请确保你的文件后缀格式为xlsx而非csv!\n' '3.请确保你的单词全部在第一列!\n' '4.运行过程漫长请耐心等待,不要中途退出,否则不会得到任何结果!\n' '5.有什么不懂的地方,欢迎私信联系我,B站搜:TUO图欧君\n' ) while True: # 用户设置阶段 try: # 输入你的excel表格的文件存储位置 # file_folder = input('请输入你的excel文件所在目录(比如:F:\我的文件夹):') # E:\GraduationDesign\词典库\含音标(新版)\2.高考 - 副本 file_folder = input('请输入你的excel文件所在目录(比如:E:\GraduationDesign\词典库\含音标(新版)') if not os.path.exists(file_folder): # 判断文件是否存在 print('你输入的文件路径有误,请重新输入!') else: print('————' * 10) print('————文件目录匹配成功!————') break except NameError: print('你输入的文件路径有误,请重新输入!') for root, dirs, files in os.walk(file_folder): for file in files: file_name = os.path.join(file) if file_name.endswith(".xlsx"): file_path = os.path.join(root, file_name) file_list.append(file_path) print('已成功导入:') print(file_list) for i in file_list: file = i print('正在运行:' + i) get_phonetic() -
之后运行发现怎么又重复单词,后面排查代码,原来是之前改bug把重复单词逻辑注释掉了,
-
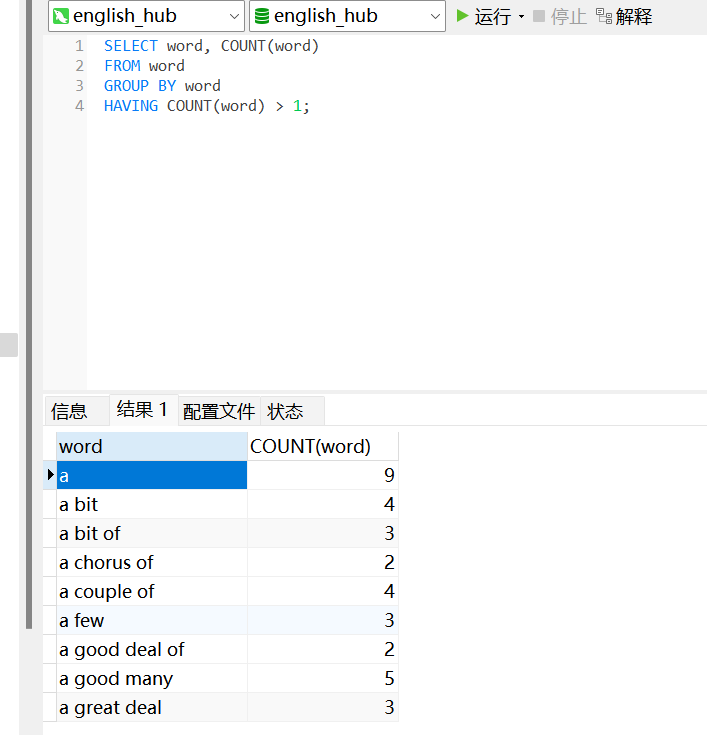
找出 word 表中重复的单词:返回每个重复的单词及其出现的次数。
SELECT word, COUNT(word) FROM word GROUP BY word HAVING COUNT(word) > 1;
DELETE w1 FROM word w1
INNER JOIN word w2
WHERE w1.id > w2.id AND w1.word = w2.word;
- 这个查询将删除 word 表中的重复行,只保留每个单词的最早的实例(即 id 最小的那个)。请注意,这将永久删除数据,所以在运行此查询之前,建议备份您的数据。
ps,我删除后发现relation表里的word_id字段是之前重复单词的,然后以及删掉了。。
-
还好有备份。现在就得写一个多表查询,首先创建了一个临时表 temp_table,它包含 word_relation 表中 word_book_id 为 52 到 65 的记录对应的 word_id 和 word_copy1 表中对应的 word。然后,它更新了 word_relation 表中的 word_id,将旧的 word_id 替换为 word 表中对应的新 id
-- 创建临时表 CREATE TEMPORARY TABLE temp_table AS SELECT wr.word_id AS old_word_id, wc1.word AS word FROM word_relation wr JOIN word_copy1 wc1 ON wr.word_id = wc1.id WHERE wr.word_book_id BETWEEN 52 AND 65; SELECT * FROM temp_table;-- 更新 word_relation 表 UPDATE word_relation wr JOIN temp_table tt ON wr.word_id = tt.old_word_id JOIN word w ON tt.word = w.word SET wr.word_id = w.id WHERE wr.word_book_id BETWEEN 52 AND 65; -
加个索引
ALTER TABLE word_relation ADD INDEX idx_word_book_id (word_book_id); ALTER TABLE word_relation ADD INDEX idx_word_id (word_id);
-- 使用以下的 SQL 语句来查询 word_relation 表中是否存在 word_id 在 word 表中不存在的记录
SELECT *
FROM word_relation
WHERE word_id NOT IN (SELECT id FROM word);
-
ok,我在删减了几百本单词书后,最终导入的有300多本,
word_relation关联表的数据量达到了110w!,校内项目第一次有这么大的数据量,之前项目也就百来个记录
索引的作用这时候终于明显的感受出来了,我在刚导入第一个分类词库的时候忘记创建索引了,跑了二三十分钟好像,之后加了索引几分钟就跑完了,可见其效率
最终代码
word.py
import pandas as pd
import os
import pymysql
# 数据库配置
db_config = {
'host': 'localhost',
'user': 'root',
'password': 'xxx',
'db': '数据库名',
'charset': 'utf8mb4',
}
# 建立数据库连接
def connect_to_db():
return pymysql.connect(**db_config)
# 插入单词库类别
def insert_category(cursor, name):
cursor.execute("SELECT id FROM word_book_category WHERE name = %s", (name,))
category_id = cursor.fetchone()
if not category_id:
cursor.execute(
"INSERT INTO word_book_category (name) VALUES (%s)",
(name,)
)
category_id = cursor.lastrowid
print(f"已插入单词库类别 '{name}',ID 为 {category_id}")
else:
category_id = category_id[0]
print(f"单词库类别 '{name}' 已存在,ID 为 {category_id}")
return category_id
# 插入单词书
def insert_word_book(cursor, name, category_id):
cursor.execute("SELECT id FROM word_books WHERE name = %s", (name,))
word_book_id = cursor.fetchone()
if not word_book_id:
cursor.execute(
"INSERT INTO word_books (name, category_id) VALUES (%s, %s)",
(name, category_id)
)
word_book_id = cursor.lastrowid
print(f"已插入单词书 '{name}',ID 为 {word_book_id}")
else:
word_book_id = word_book_id[0]
print(f"单词书 '{name}' 已存在,ID 为 {word_book_id}")
return word_book_id
# 插入单词
def insert_word(cursor, word, phonetic_uk, phonetic_us, definition):
# 检查数据是否为 NaN,如果是,则替换为 None,去除多余空格确保字段有效
phonetic_uk = None if pd.isna(phonetic_uk) else phonetic_uk
phonetic_us = None if pd.isna(phonetic_us) else phonetic_us
definition = None if pd.isna(definition) else definition
# 查找 words 表中的 words_id
cursor.execute("SELECT id FROM words WHERE word = %s", (word,))
words_id = cursor.fetchone()
if words_id:
words_id = words_id[0] # 如果单词存在,获取其 ID
else:
words_id = None # 如果单词不存在,设置 words_id 为 None
# 查找 word 表中的 word_id
cursor.execute("SELECT id FROM word WHERE word = %s", (word,))
word_id = cursor.fetchone()
if not word_id:
# 插入数据到 word 表
cursor.execute(
"""
INSERT INTO word (word, words_id, phonetic_uk, phonetic_us, definition)
VALUES (%s, %s, %s, %s, %s)
""",
(word, words_id, phonetic_uk, phonetic_us, definition)
)
word_id = cursor.lastrowid
print(f"已插入单词 '{word}',ID 为 {word_id},words_id 为 {words_id}")
else:
word_id = word_id[0]
print(f"单词 '{word}' 已存在,ID 为 {word_id}")
return word_id
# 插入关联
def insert_relation(cursor, word_book_id, word_id):
# 检查关联是否已存在
cursor.execute("SELECT id FROM word_relation WHERE word_book_id = %s AND word_id = %s", (word_book_id, word_id))
relation_id = cursor.fetchone()
if not relation_id:
cursor.execute(
"INSERT INTO word_relation (word_book_id, word_id) VALUES (%s, %s)",
(word_book_id, word_id)
)
print(f"关联单词书 '{word_book_id}' 和单词 '{word_id}' 成功。")
else:
print(f"关联已存在:单词书 '{word_book_id}' 和单词 '{word_id}'。")
# 导入 Excel 文件中的单词
def import_words_from_excel(cursor, excel_path, word_book_id):
df = pd.read_excel(excel_path, dtype=str)
try:
for _, row in df.iterrows():
word = row['单词']
phonetic_uk = row.get('英音', None)
phonetic_us = row.get('美音', None)
definition = row.get('释义', None)
# 处理可能的空值
word_id = insert_word(cursor, word, phonetic_uk if phonetic_uk else "", phonetic_us if phonetic_us else "",
definition if definition else "")
insert_relation(cursor, word_book_id, word_id) # 插入关联
cursor.connection.commit() # 提交更改
print(f"文件 '{excel_path}' 的单词已导入到单词书 ID 为 {word_book_id}")
except Exception as e:
cursor.connection.rollback() # 回滚更改
print(f"导入文件 '{excel_path}' 时出错:{e}")
# 遍历文件夹并导入 Excel 文件
def import_words_from_folder(folder_path, category_name):
db = connect_to_db()
cursor = db.cursor()
try:
category_id = insert_category(cursor, category_name) # 插入单词库类别
for root, _, files in os.walk(folder_path):
for file in files:
if file.endswith('.xlsx'):
word_book_name = os.path.splitext(file)[0] # 单词书名称
word_book_id = insert_word_book(cursor, word_book_name, category_id) # 插入单词书
excel_path = os.path.join(root, file)
import_words_from_excel(cursor, excel_path, word_book_id) # 导入单词
print(f"文件夹 '{folder_path}' 的数据已成功导入到 '{category_name}' 单词库类别")
except Exception as e:
db.rollback() # 回滚更改
print(f"导入文件夹 '{folder_path}' 时出错:{e}")
finally:
cursor.close()
db.close()
# 主程序
def main():
folder_paths = {
# '中考': "E:\\GraduationDesign\\词典库\\含音标(新版)\\1.中考",
# '高考': "E:\\GraduationDesign\\词典库\\含音标(新版)\\2.高考",
# '大学英语': "E:\\GraduationDesign\\词典库\\含音标(新版)\\3.大学英语",
# '四级': "E:\\GraduationDesign\\词典库\\含音标(新版)\\3.四级",
# '专四': "E:\\GraduationDesign\\词典库\\含音标(新版)\\3.专四",
# '六级': "E:\\GraduationDesign\\词典库\\含音标(新版)\\4.六级",
# '专八': "E:\\GraduationDesign\\词典库\\含音标(新版)\\4.专八",
# '考研': "E:\\GraduationDesign\\词典库\\含音标(新版)\\5.考研",
# '考博': "E:\\GraduationDesign\\词典库\\含音标(新版)\\6.考博",
# '托福': "E:\\GraduationDesign\\词典库\\含音标(新版)\\7.托福",
# '雅思': "E:\\GraduationDesign\\词典库\\含音标(新版)\\7.雅思",
# '国际英语': "E:\\GraduationDesign\\词典库\\含音标(新版)\\8.国际英语",
# '商务英语': "E:\\GraduationDesign\\词典库\\含音标(新版)\\8.商务英语",
'新概念英语': "E:\\GraduationDesign\\词典库\\含音标(新版)\\8.新概念英语",
'新世纪英专': "E:\\GraduationDesign\\词典库\\含音标(新版)\\8.新世纪英专",
'其他': "E:\\GraduationDesign\\词典库\\含音标(新版)\\9.其他(更多)",
}
for category_name, folder_path in folder_paths.items():
import_words_from_folder(folder_path, category_name)
# 运行脚本
if __name__ == '__main__':
main()
检查是否有单词列.py
import os
import pandas as pd
# 检查 Excel 文件是否包含 "单词" 列
def check_excel_has_word_column(excel_path):
try:
# 读取第一行,检查第一列的名称
df = pd.read_excel(excel_path, nrows=1)
if '单词' not in df.columns:
return False # 不包含 "单词" 列
return True # 包含 "单词" 列
except Exception as e:
print(f"检查文件 '{excel_path}' 时发生错误:{e}")
return False # 如果发生错误,视为不包含 "单词" 列
# 遍历文件夹,检查 Excel 文件
def check_folder_for_invalid_excel(folder_path):
invalid_files = []
for root, _, files in os.walk(folder_path):
for file in files:
if file.endswith('.xlsx'): # 只检查 Excel 文件
excel_path = os.path.join(root, file)
if not check_excel_has_word_column(excel_path):
invalid_files.append(excel_path) # 记录不包含 "单词" 列的文件
return invalid_files
# 主程序
def main():
folder_paths = [
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\2.高考",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\3.大学英语",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\3.四级",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\3.专四",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\4.六级",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\4.专八",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\5.考研",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\6.考博",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\7.托福",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\7.雅思",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\8.国际英语",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\8.商务英语",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\8.新概念英语",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\8.新世纪英专",
# "E:\\GraduationDesign\\词典库\\含音标(新版)\\9.其他(更多)",
]
for folder_path in folder_paths:
invalid_files = check_folder_for_invalid_excel(folder_path)
if invalid_files:
print(f"以下 Excel 文件不包含 '单词' 列:{invalid_files}")
else:
print(f"文件夹 '{folder_path}' 中所有 Excel 文件都包含 '单词' 列")
# 运行脚本
if __name__ == '__main__':
main()
多文件批处理创建单词英音美音释义列表.py
该脚本从网上获取,非本人所写,在这感谢♪
- 原本的表格只有数据单词本身和释义
- 处理后第一行显示列名
单词-英音-美音-释义,音标从有道网爬取
import requests
import os
from lxml import etree
from openpyxl.styles import Font
from openpyxl.styles import Alignment
from openpyxl.styles import Side, Border
from openpyxl import load_workbook
def get_phonetic():
print('————' * 10)
workbook = load_workbook(file) # 导入excel表格
worksheet = workbook['Sheet1'] # 读取excel中的sheet1这张表
worksheet.insert_cols(idx=2, amount=2) # 向右插入两列准备存放数据,idx:插入列的位置,amount:插入的列数
worksheet.insert_rows(idx=0, amount=1) # 在顶部插入一行写入注释,idx:插入行的位置,amount:插入的行数
worksheet['A1'] = '单词' # 如果你的单词本第一行原本就有这些注释就不用这代码了,直接删掉就行
worksheet['B1'] = '英音'
worksheet['C1'] = '美音'
worksheet['D1'] = '释义'
font = Font(name='微软雅黑', size=20, bold=False) # 设置全局字体大小样式
worksheet['A1'].font = font
worksheet['B1'].font = font
worksheet['C1'].font = font
worksheet['D1'].font = font
alignment = Alignment(horizontal="left") # 设置单元格对齐方式,用于修复墨墨词库csv文件顶部两处单元格的对齐异常问题
worksheet['A2'].alignment = alignment # 如果不需要此代码可删除
worksheet['D2'].alignment = alignment # 如果不需要此代码可删除
border = Border(Side(style=None)) # 设置单元格边框样式,用于修复墨墨词库csv文件顶部两处单元格的边框异常问题
worksheet['A2'].border = border # 如果不需要此代码可删除
worksheet['D2'].border = border # 如果不需要此代码可删除
worksheet.column_dimensions['A'].width = 30 # 设置全局列宽
worksheet.column_dimensions['B'].width = 30
worksheet.column_dimensions['C'].width = 30
worksheet.column_dimensions['D'].width = 30
workbook.save(file)
row_index = 2 # 默认结果放到第二行开始
for row in worksheet.iter_rows(min_row=2, max_col=3): # 以行迭代(最小第二行,最多第3列)
word = row[0].value # 获取第一列所有表格数据
# 请确保你的单词在第1列,如果你的单词在第N列,请将代码换成:word = row[0+N].value,还要记得改其他各处代码中的数字!
url = 'https://www.youdao.com/w/eng/{}'.format(word) # 从有道获取音标
try:
data = requests.get(url).text
html = etree.HTML(data)
num1 = 'A' + str(row_index)
num2 = 'B' + str(row_index)
num3 = 'C' + str(row_index)
num4 = 'D' + str(row_index)
British_pron = html.xpath('//*[@id="phrsListTab"]/h2/div/span[1]/span/text()')[0]
American_pron = html.xpath('//*[@id="phrsListTab"]/h2/div/span[2]/span/text()')[0]
print('正在输出:' + British_pron, American_pron)
worksheet.cell(row=row_index, column=2).value = British_pron # 默认将英式音标的结果放到第2列
worksheet.cell(row=row_index, column=3).value = American_pron # 默认将美式音标的结果放到第3列
worksheet[num1].font = font
worksheet[num2].font = font
worksheet[num3].font = font
worksheet[num4].font = font
except Exception as e:
print(e, word)
num1 = 'A' + str(row_index)
num4 = 'D' + str(row_index)
worksheet[num1].font = font
worksheet[num4].font = font
row_index += 1
workbook.save(file)
print("单词音标全部转换完毕!已经成功保存在原文件:" + file)
print('————' * 10)
if __name__ == '__main__':
file_list = []
print('欢迎来到多个xlsx批量单词音标转换小程序')
print('注意事项:\n'
'1.请确保你的网络通畅!\n'
'2.请确保你的文件后缀格式为xlsx而非csv!\n'
'3.请确保你的单词全部在第一列!\n'
'4.运行过程漫长请耐心等待,不要中途退出,否则不会得到任何结果!\n'
'5.有什么不懂的地方,欢迎私信联系我,B站搜:TUO图欧君\n'
)
while True: # 用户设置阶段
try: # 输入你的excel表格的文件存储位置
# file_folder = input('请输入你的excel文件所在目录(比如:F:\我的文件夹):')
# E:\GraduationDesign\词典库\含音标(新版)\2.高考 - 副本
file_folder = input('请输入你的excel文件所在目录(比如:E:\GraduationDesign\词典库\含音标(新版)')
if not os.path.exists(file_folder): # 判断文件是否存在
print('你输入的文件路径有误,请重新输入!')
else:
print('————' * 10)
print('————文件目录匹配成功!————')
break
except NameError:
print('你输入的文件路径有误,请重新输入!')
for root, dirs, files in os.walk(file_folder):
for file in files:
file_name = os.path.join(file)
if file_name.endswith(".xlsx"):
file_path = os.path.join(root, file_name)
file_list.append(file_path)
print('已成功导入:')
print(file_list)
for i in file_list:
file = i
print('正在运行:' + i)
get_phonetic()
- 查询单词书
-- 查询特定单词书的所有单词
SELECT
w.id,
w.word,
w.phonetic_uk,
w.phonetic_us,
w.definition
FROM
word_relation wr
JOIN
word w ON wr.word_id = w.id
WHERE
wr.word_book_id = 60
考虑后续查询优化
- 给word表创建覆盖索引,减少回表
CREATE INDEX idx_word_info ON word(id, word, words_id, phonetic_uk, phonetic_us, definition(255));
单词大表
CREATE TABLE `words` (
`id` int NOT NULL,
`word` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '单词',
`definition` mediumtext CHARACTER SET utf8 COLLATE utf8_general_ci COMMENT '单词信息html,中英释义、例句',
`audio_url` varchar(255) DEFAULT NULL COMMENT '单词发音url',
`video_url` varchar(255) DEFAULT NULL COMMENT '单词对应视频url',
`subtext` varchar(255) DEFAULT NULL COMMENT '视频字幕',
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `word` (`word`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
测试效果
-
yaml配置文件中安装依赖,及css文件
# webview_flutter-网页 webview_flutter: ^3.0.0 assets: - assets/CollinsEC.css -
导入
import'package:webview_flutter/webview_flutter.dart';编写代码,由于单词的html中是没包括音频播放的代码,需要在其中插入播放代码,<meta name="viewport" content="width=device-width, initial-scale=1.0">可以根据屏幕适配大小下面是完整测试代码
class SpokenPage extends StatefulWidget { _SpokenPageState createState() => _SpokenPageState(); } class _SpokenPageState extends State<SpokenPage> { // css文件内容 String? _loadedCss; void initState() { super.initState(); _loadCssFile(); } // 加载css文件 Future<void> _loadCssFile() async { final String loadedCss = await rootBundle.loadString('assets/CollinsEC.css'); setState(() { _loadedCss = loadedCss; }); } String getWordHtml() { return ''' <body><a name="page_top"></a> <div class="C1_word_header"><span class="C1_word_header_word">abandoned</span> <!--AUDIO_PLACEHOLDER--> <span class="C1_word_header_star">★★★☆☆</span><span class="C1_color_bar"> <ul> <li class="C1_cabr_1"></li> <li class="C1_cabr_2"></li> <li class="C1_cabr_3"></li> <li class="C1_cabr_4"></li> <li class="C1_cabr_5"></li> <li class="C1_cabr_6"></li> </ul> </span></div> <div class="tab_content" id="dict_tab_101" style="display:block"> <div class="part_main"> <div class="collins_content"> <div class="C1_explanation_item"> <div class="C1_explanation_box"><span class="C1_item_number"><a href="entry://#page_top">1</a></span><span class="C1_explanation_label">[ADJ 形容词] </span><span class="C1_text_blue">(场所或建筑物)舍弃不用的,无人居住的;</span>An <span class="C1_inline_word">abandoned</span> place or building is no longer used or occupied. <span class="C1_word_gram">[usu ADJ n]</span></div> <ul> <li> <p class="C1_sentence_en">All that digging had left a network of <span class="C1_text_blue">abandoned</span> mines and tunnels.</p> <p>东挖西掘后留下了一片废弃的矿坑。</p> </li> <li> <p class="C1_sentence_en">//...<span class="C1_text_blue">abandoned</span> buildings that become a breeding ground for crime.</p> <p>沦为了犯罪温床的弃置楼群</p> </li> </ul> </div> </div> </div> </div> </body> '''; } // 构建音频播放的HTML代码片段 String buildAudioHtml(String audioUrl) { return ''' <a style="float: left;margin-top: 8px;margin-right: 4px;" href="#" οnclick="document.getElementById('audio').play(); return false;"> <img src="https://hyf666.oss-cn-fuzhou.aliyuncs.com/english_hub/image/Sound.png" style="margin-bottom:-2px" border="0"> </a> <audio id="audio" style="display:none;"> <source src="$audioUrl" type="audio/mpeg"> </audio> '''; } Widget build(BuildContext context) { // 从后端获取音频地址 const String audioUrl = 'https://hyf666.oss-cn-fuzhou.aliyuncs.com/017.mp3'; String htmlContent = getWordHtml().replaceFirst('<!--AUDIO_PLACEHOLDER-->', buildAudioHtml(audioUrl)); final String contentWithCss = """ <html> <head> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <style> $_loadedCss </style> </head> <body> $htmlContent </body> </html> """; // 将HTML内容转换为Base64编码 final String contentBase64 = base64Encode(const Utf8Encoder().convert(contentWithCss)); return Scaffold( body: _loadedCss == null ? const Center(child: CircularProgressIndicator()) : WebView( initialUrl: 'data:text/html;base64,$contentBase64', javascriptMode: JavascriptMode.unrestricted, ), ); } }
批量插入数据库
-
我从网上搜寻得到mdx的词典库,用了软件MdxExport将其转为txt文件,mdx格式里面其实是一些html标签
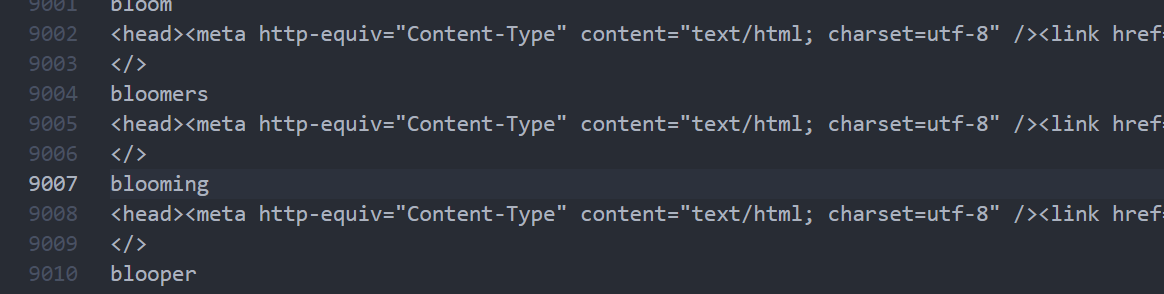
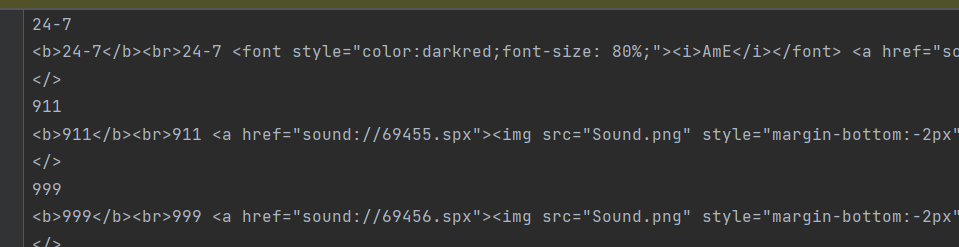
-
以及音频文件,为压缩的spx文件,接着通过格式工厂批量转化为MP3后,询问gpt4编写python脚本处理html标签,并匹配单词对应的音频上传到阿里云oss存储,使用前请配置好bucket。
对于单词的信息我原本是打算将其中的信息如中文释义,英文释义,英文例句、词性等等,通过正则筛出来再批量传到数据库,但是发现有点小复杂,而且这个词典包括了css文件,于是我就打算直接将html展示出来,以及音频文件中出了单词原型还有其他形式的音频文件,于是就打算只搞第一个音频,以及有的单词是没有对应音频文件的,就只能给定个id和空的url插入数据库
-
import re import os import time import pymysql import oss2 # OSS配置 access_key_id = 'xxx' access_key_secret = 'xxx' bucket_name = 'xxx' endpoint = 'xxx' # 数据库配置 db_config = { 'host': 'localhost', 'user': 'xxx', 'password': 'xxx', 'db': 'english_hub', 'charset': 'utf8mb4', } # 适用于匹配单词及其HTML内容,考虑单词中可能包含破折号和空格等 word_pattern = re.compile(r'(?P<word>[\w\s\'&-]+)\n<head>.+?<body>(?P<html>.+?)</body>', re.DOTALL) # 适用于从音频信息文件中提取单词原型及其对应的第一个音频文件ID audio_pattern = re.compile(r'(?P<word>[\w\s\'&-]+)</b><br>.+?<a href="sound://(?P<id>\d+).spx">', re.DOTALL) # 初始化OSS和数据库连接 auth = oss2.Auth(access_key_id, access_key_secret) bucket = oss2.Bucket(auth, endpoint, bucket_name) db = pymysql.connect(**db_config) cursor = db.cursor() def upload_audio_to_oss(local_audio_path): # 上传文件到OSS并返回URL # 设置存储路径为english_hub/audio/ oss_key = 'english_hub/audio/' + os.path.basename(local_audio_path) bucket.put_object_from_file(oss_key, local_audio_path) return f"https://{bucket_name}.{endpoint}/{oss_key}" def check_duplicate_id(audio_id): # 查询数据库中是否已存在相同的音频ID cursor.execute("SELECT id FROM words WHERE id = %s", (audio_id,)) result = cursor.fetchone() return result is not None def check_duplicate_word(word): # 查询数据库中是否已存在相同的单词(忽略大小写) cursor.execute("SELECT word FROM words WHERE LOWER(word) = LOWER(%s)", (word,)) result = cursor.fetchone() return result is not None def parse_and_upload(): try: # 计数器 count = 0 # id cnt = 80301 # 解析单词信息文件 with open('Collins COBUILD (CN).txt', 'r', encoding='utf-8') as word_file: word_content = word_file.read() words = word_pattern.finditer(word_content) # 解析音频信息文件 with open('Collins Cobuild Audio.txt', 'r', encoding='utf-8') as audio_file: audio_content = audio_file.read() audios = {m.group('word').lower(): m.group('id') for m in audio_pattern.finditer(audio_content)} # print(audios) for word_match in words: # 移除单词前后的空白字符,包括换行符 word = word_match.group('word').strip().lower() html = word_match.group('html').strip() # 获取音频文件ID audio_id = audios.get(word) audio_url = None if audio_id is None: audio_id = cnt + 1 cnt += 1 if check_duplicate_id(audio_id): print(f"音频ID为 {audio_id} 的单词已存在,跳过插入操作") continue if check_duplicate_word(word): print(f"单词 {word} 已存在,跳过插入操作") continue print(word, audio_id) # 构建音频文件本地路径 audio_path = f'E:/GraduationDesign/词典库/Mdict柯林斯英汉-带发音文件/Collins Cobuild Audio/{audio_id}.mp3' # 检测音频文件是否存在,并上传到OSS if os.path.exists(audio_path): audio_url = upload_audio_to_oss(audio_path) count += 1 # 限制上传数量,避免上传过快导致OSS拒绝服务 if count >= 200: time.sleep(0.2) if count >= 800: time.sleep(0.5) if count >= 1500: count = 0 time.sleep(0.5) # print(f'音频文件{audio_url}上传成功') # 检测数据库是否已连接 if not db.open: db.ping(reconnect=True) print('数据库连接已断开,重新连接') # 将数据插入数据库 sql = "INSERT INTO words (id, word, definition, audio_url) VALUES (%s, %s, %s, %s)" cursor.execute(sql, (audio_id, word, html, audio_url)) db.commit() except Exception as e: print(f"An error occurred: {e}") def main(): parse_and_upload() # 关闭数据库连接 cursor.close() db.close() if __name__ == "__main__": main() -
运行脚本
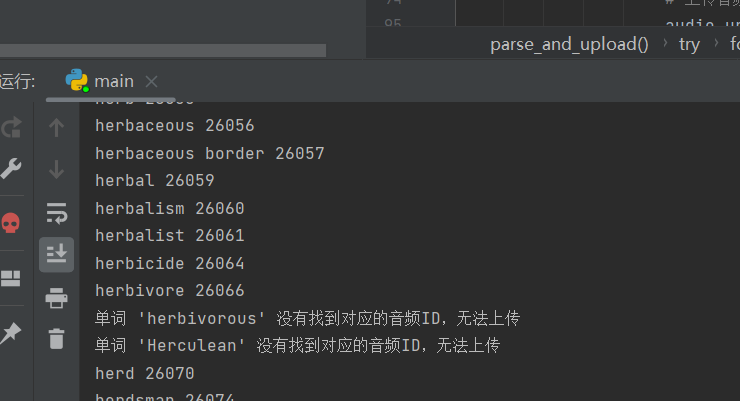
-
有一点要注意下
audio_id = audios.get(word)这代码我刚开始打印出来世none,后面发现用print(repr(word))大打印出来单词前面有个换行符,导致id取不出来,repr()是Python内置函数,它返回对象的“官方”字符串表示形式,通常更具可读性和可理解性word = "Hello\nWorld" print(word) # 输出:Hello # World print(repr(word)) # 输出:"Hello\nWorld" -
之后就是漫长的等待,。。。
在页面中展示
-
先编写后端接口,并测试数据
// 根据单词名获取单词 @Operation(summary = "根据单词名获取单词") @GetMapping("/getByName") public Result getByName(String words) { Result result = new Result(); Words word = wordsService.getByName(words); result.setData(word); return result; } -
测试一下
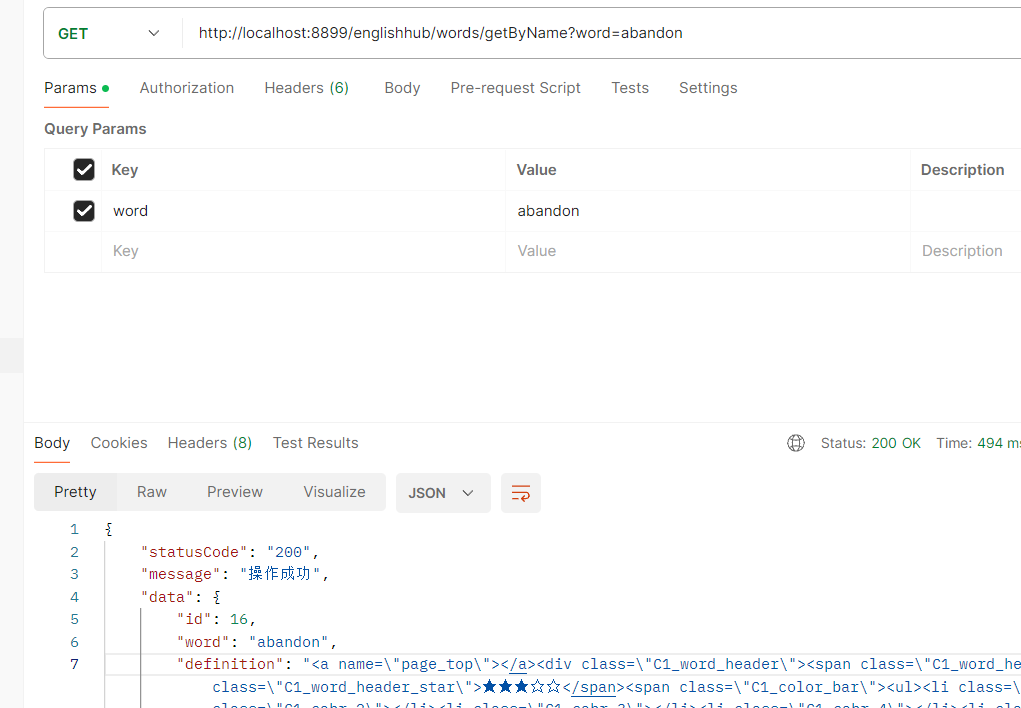
对应视频
-
对于每个单词都有一个对应例句的视频,原本的设想方案是:
- **方案一:**下载完整的影视文件,通过QuickCut软件分割成多个小片段,提取出涉及的单词或短语供用户学习,通过在线找台词,找出需要的例句对应的在影视片段中的具体时刻,发请求https://zhaotaici.cn/php/api/subtitle_seek_api.php?action=seek_all&search_type=text&query=all%20you&pageNum=0&title_filter=&actor_filter=&director_filter=&is_en=1根据返回结果拿到起始时刻和片名和字幕名,写
python脚本,通过片库下载视频,通过字幕库下载对应字幕,然后用quickcut分割,但是这样工作量太大了而且有很多因素会影响,先搁置。 - **方案二:**通过一个根据台词找视频片段的网站,可以输入单词或句子会自动匹配最接近的视频片段,通过发
get请求获取数据,根据正则匹配出视频id,然后再根据视频id发请求获取视频的字幕以及下载MP4,之后再上传到阿里云oss存储返回的url存入数据库。
- **方案一:**下载完整的影视文件,通过QuickCut软件分割成多个小片段,提取出涉及的单词或短语供用户学习,通过在线找台词,找出需要的例句对应的在影视片段中的具体时刻,发请求https://zhaotaici.cn/php/api/subtitle_seek_api.php?action=seek_all&search_type=text&query=all%20you&pageNum=0&title_filter=&actor_filter=&director_filter=&is_en=1根据返回结果拿到起始时刻和片名和字幕名,写
-
相比来说方案一更灵活精确控制所需资源,但是过程非常繁琐,即使是通过自动化脚本。而方案二节省了裁剪时间,但是单词与视频字幕的匹配不一定准确,但我有点懒,就干脆直接按照返回的结果中的第一个视频id保存
当初传音频的时候其实就该一起操作完的,︿( ̄︶ ̄)︿。。
-
突然想起来之前插入单词的时候忘记把
<!--AUDIO_PLACEHOLDER-->插入数据库的definition字段中了,用来显示播放按钮的部分代码,总之这脚本编写过程中遇到挺多问题的,比如在提取英文句子时有的单词不一定有对应例句,这时就要根据单词本身去搜索;以及soup.find("div", {"class": "fs12 tac fwb p05"})只会查找直接子元素中符合条件的div, 而不会查找嵌套的div,导致匹配不到字幕,要改为使用soup.select_one等等 -
下面是脚本的详细实现:
import re import os import time import requests from bs4 import BeautifulSoup from concurrent.futures import ThreadPoolExecutor, as_completed import pymysql import oss2 # OSS配置 access_key_id = 'xxx' access_key_secret = 'xxx' bucket_name = 'xxx' endpoint = 'oss-cn-fuzhou.aliyuncs.com' cnt1 = 0 cnt2 = 0 # 数据库配置 db_config = { 'host': 'localhost', 'user': 'xxx', 'password': 'xxx', 'db': 'english_hub', 'charset': 'utf8mb4', } # 初始化OSS和数据库连接 auth = oss2.Auth(access_key_id, access_key_secret) bucket = oss2.Bucket(auth, endpoint, bucket_name) db = pymysql.connect(**db_config) cursor = db.cursor() def download_video(video_id): """下载视频""" video_url = f"https://y.yarn.co/{video_id}.mp4" local_video_path = f"video/{video_id}.mp4" if os.path.exists(local_video_path): print(f"Video {video_id} already exists 在本地") return local_video_path with open(local_video_path, 'wb') as file: response = requests.get(video_url) file.write(response.content) time.sleep(0.1) global cnt1 cnt1 += 1 if cnt1 > 100: time.sleep(0.1) if cnt1 > 1000: time.sleep(0.2) if cnt1 > 10000: time.sleep(0.3) if cnt1 > 20000: time.sleep(0.4) cnt1 = 0 print(f"Downloaded video {video_id}") return local_video_path def upload_video(local_video_path, video_id): """上传视频到OSS""" oss_key = f'english_hub/video/{video_id}.mp4' if bucket.object_exists(oss_key): print(f"Video {video_id} already exists 在服务器") return f"https://{bucket_name}.{endpoint}/{oss_key}" bucket.put_object_from_file(oss_key, local_video_path) time.sleep(0.1) global cnt2 cnt2 += 1 if cnt2 > 100: time.sleep(0.1) if cnt2 > 1000: time.sleep(0.2) if cnt2 > 10000: time.sleep(0.3) if cnt2 > 20000: time.sleep(0.4) cnt2 = 0 print(f"Uploaded video {video_id} to OSS") return f"https://{bucket_name}.{endpoint}/{oss_key}" def extract_first_sentence(html_content): """从HTML内容中提取第一个英文例句""" soup = BeautifulSoup(html_content, 'html.parser') sentence = soup.find('p', {'class': 'C1_sentence_en'}) return sentence.text if sentence else None def extract_word(html_content): """从HTML内容中提取单词""" soup = BeautifulSoup(html_content, 'html.parser') word = soup.find('span', {'class': 'C1_word_header_word'}) return word.text if word else None def extract_subtext(video_id): """从HTML内容中提取字幕""" # https://getyarn.io/yarn-clip/ video_url = f"https://getyarn.io/yarn-clip/{video_id}" response = requests.get(video_url) html = response.content soup = BeautifulSoup(html, 'html.parser') # soup.find("div", {"class": "fs12 tac fwb p05"})只会查找直接子元素中符合条件的div, 而不会查找嵌套的div。 # 查找符合条件的div元素, 无论它是直接子元素还是嵌套元素 subtitle_div = soup.select_one("div.fs12.tac.fwb.p05") if subtitle_div: subtitle_text = subtitle_div.get_text(strip=True) return subtitle_text return None def find_video_id_subtext(word, sentence): """查找视频ID和字幕""" if not sentence: search_query = word.replace(" ", "+") else: search_query = sentence.replace(" ", "+") search_url = f"https://getyarn.io/yarn-find?text={search_query}" response = requests.get(search_url) soup = BeautifulSoup(response.content, 'html.parser') # ids取第一个 # video_ids = [a['href'].split('/')[-1] for a in soup.find_all("a", href=lambda href: href and "/yarn-clip/" in href)] # subtext = extract_subtext(video_ids[0]) # 查找第一个符合条件的a标签 video_a_tag = soup.find("a", href=lambda href: href and "/yarn-clip/" in href) if video_a_tag: video_id = video_a_tag['href'].split('/')[-1] subtext = extract_subtext(video_id) # print(f"video_id: {video_id}") print(f"subtext: {subtext}") return video_id, subtext else: print("No video ID found for the given sentence/word.") return None, None def update_video_url(word_id, video_url, subtext, definition): """ 更新单词的视频URL和字幕、插入AUDIO_PLACEHOLDER """ try: # 检查数据库连接状态 db.ping(reconnect=True) # 检查是否已存在AUDIO_PLACEHOLDER if '<!--AUDIO_PLACEHOLDER-->' not in definition: # 使用正则表达式查找<span class="C1_word_header_word">...</span>并在其后插入<!--AUDIO_PLACEHOLDER--> pattern = re.compile(r'(<span class="C1_word_header_word">.*?</span>)') updated_definition = pattern.sub(r'\1\n <!--AUDIO_PLACEHOLDER-->', definition) else: updated_definition = definition cursor.execute("SELECT video_url, subtext, definition FROM words WHERE id = %s", (word_id,)) result = cursor.fetchone() if result and result[0]: if not result[1] and subtext: # 如果数据库中URL存在但字幕为空,则更新字幕和definition cursor.execute("UPDATE words SET subtext = %s, definition = %s WHERE id = %s", (subtext, updated_definition, word_id)) print(f"Updated subtext and inserted AUDIO_PLACEHOLDER for word ID: {word_id}") elif result[2] != updated_definition: # 如果URL和字幕都存在,只更新definition cursor.execute("UPDATE words SET definition = %s WHERE id = %s", (updated_definition, word_id)) print(f"Inserted AUDIO_PLACEHOLDER for word ID: {word_id}") db.commit() return # 如果URL不存在,则插入新的URL、字幕和更新definition cursor.execute("UPDATE words SET video_url = %s, subtext = %s, definition = %s WHERE id = %s", (video_url, subtext, updated_definition, word_id)) db.commit() print(f"Updated video URL, subtext and inserted AUDIO_PLACEHOLDER for word ID: {word_id}") except Exception as e: db.rollback() print(f"Error updating video URL, subtext, and inserting AUDIO_PLACEHOLDER for word {word_id}: {e}") def process_word(word_id, word, definition): first_sentence = extract_first_sentence(definition) video_id, subtext = find_video_id_subtext(word, first_sentence) if video_id: print(word + " ") local_video_path = download_video(video_id) video_url = upload_video(local_video_path, video_id) if video_url: update_video_url(word_id, video_url, subtext, definition) def check_db_connection(): try: db.ping(reconnect=True) except pymysql.MySQLError as e: print(f"Error checking or reconnecting to the database: {e}") def batch_process(): """批量处理所有单词,每次处理1500个单词""" batch_size = 1500 # 偏移量表示数据库中第几行开始,因为不是一次运行的,中途有断开处理bug offset = 8051 total_words = get_total_words() while offset < total_words: check_db_connection() sql = "SELECT id, word, definition FROM words LIMIT %s OFFSET %s" cursor.execute(sql, (batch_size, offset)) rows = cursor.fetchall() with ThreadPoolExecutor(max_workers=5) as executor: futures = {executor.submit(process_word, row[0], row[1], row[2]): row for row in rows} for future in as_completed(futures): try: future.result() except Exception as e: word_id, _, _ = futures[future] print(f"Error processing word ID {word_id}: {e}") offset += len(rows) print(f"Processed {offset} of {total_words} words") # 释放数据库资源 if db.open: cursor.close() db.close() print("Database connection closed.") def get_total_words(): """获取数据库中单词总数""" cursor.execute("SELECT COUNT(*) FROM words") return cursor.fetchone()[0] # 按间距中的绿色按钮以运行脚本。 if __name__ == '__main__': # html = """""" # sentence = extract_first_sentence(html) # print("sentences:", sentence) # word = extract_word(html) # print("word:", word) # sql_html = """""" # subtext = extract_subtext(sql_html) # print("subtext:", subtext) # video_id = find_video_id(sentence) # print("video_id:", video_id) # process_words() batch_process() # print(find_video_id_subtext("you", "you are a good boy")) # print(get_total_words()) # print(extract_subtext('9a823854-dc10-4e38-8d08-86aedd030926')) -
由于数量有点多,这次加入了线程池控制并发请求,以及处理次数过多,加入检测数据库连接的代码,因为遇到过直接断开了,之后就是漫长的等待。
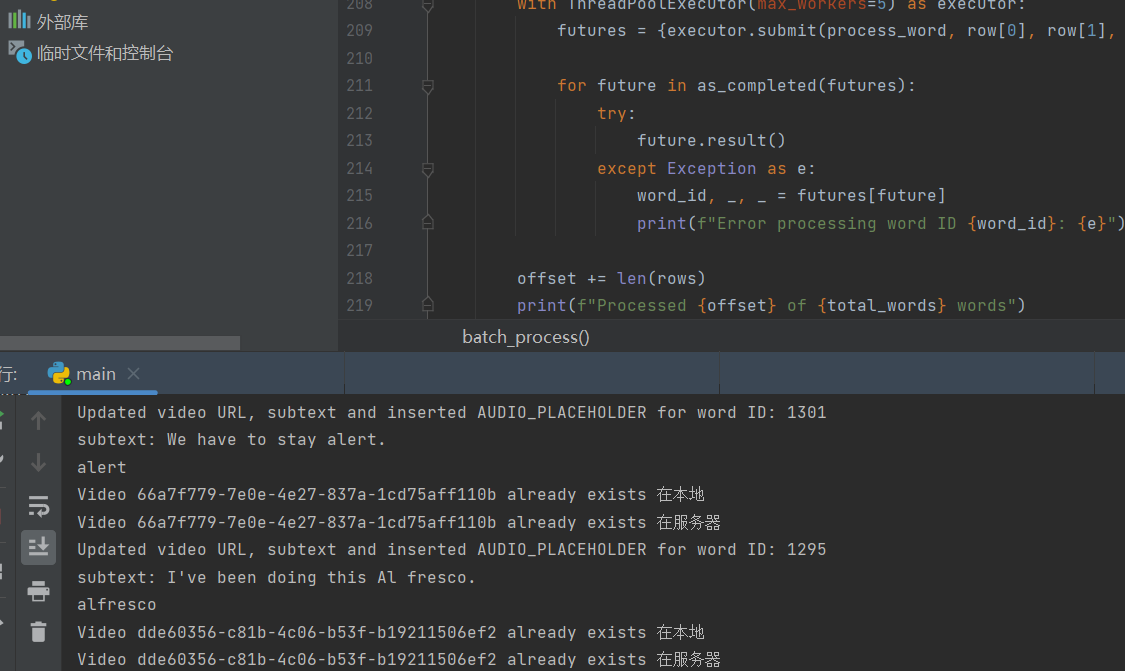
引入播放器
- 使用github上的一个库media_kit,首先yaml引入依赖,注意:如果需要视频和音频支持,则应选择视频库;不应混合使用
dependencies:
media_kit: ^1.1.10 # Primary package.
media_kit_video: ^1.2.4 # For video rendering.
media_kit_libs_video: ^1.0.4 # Native video dependencies.
-
接着在main初始化
// 引入media_kit库 import 'package:media_kit/media_kit.dart'; // Provides [Player], [Media], [Playlist] etc. import 'package:media_kit_video/media_kit_video.dart'; void main() async { // 确保Flutter的widget系统初始化完成 WidgetsFlutterBinding.ensureInitialized(); // 初始化GetStorage await GetStorage.init(); // 初始化Service,使用Get.lazyPut()方法来延迟加载服务 Service.init(); final isFirstTime = GetStorage().read('isFirstTime') ?? true; // 初始化MediaKit MediaKit.ensureInitialized(); // 设置设备的首选方向为纵向 await SystemChrome.setPreferredOrientations(<DeviceOrientation>[ DeviceOrientation.portraitUp, DeviceOrientation.portraitDown ]).then((_) => runApp(MyApp( isFirstTime: isFirstTime,))); } -
额但是后来运行发现不兼容,所以暂时不考虑这个库了,
- 改为使用
import 'package:appinio_video_player/appinio_video_player.dart';
新闻
申请api key
中国日报
爬取双语新闻
- 先查看网页源码,找到需要的内容所在的标签gy_box,标题gy_box_txt2,描述gy_box_txt3,图片gy_box_img
- 然后就可以编写代码了,使用beautifulsoup库解析html
import requests
import re
import os
import time
import pymysql
import oss2
from bs4 import BeautifulSoup
# 请求中国日报双语新闻网页
url = "https://language.chinadaily.com.cn/news_bilingual/page_1.html"
response = requests.get(url)
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 定义新闻项的正则表达式
news_items = soup.find_all("div", class_="gy_box")
# 创建一个列表来存储新闻信息
news_list = []
# 从页面中提取每个新闻条目的信息
for item in news_items:
# 提取标题、链接、描述和图片
title_tag = item.find("p", class_="gy_box_txt2").find("a")
title = title_tag.get_text().strip()
link = "https:" + title_tag["href"]
description = item.find("p", class_="gy_box_txt3").get_text().strip()
image = "https:" + item.find("a", class_="gy_box_img").find("img")["src"]
# 将新闻信息添加到列表
news_list.append({
"title": title,
"link": link,
"description": description,
"image": image
})
# 输出新闻列表
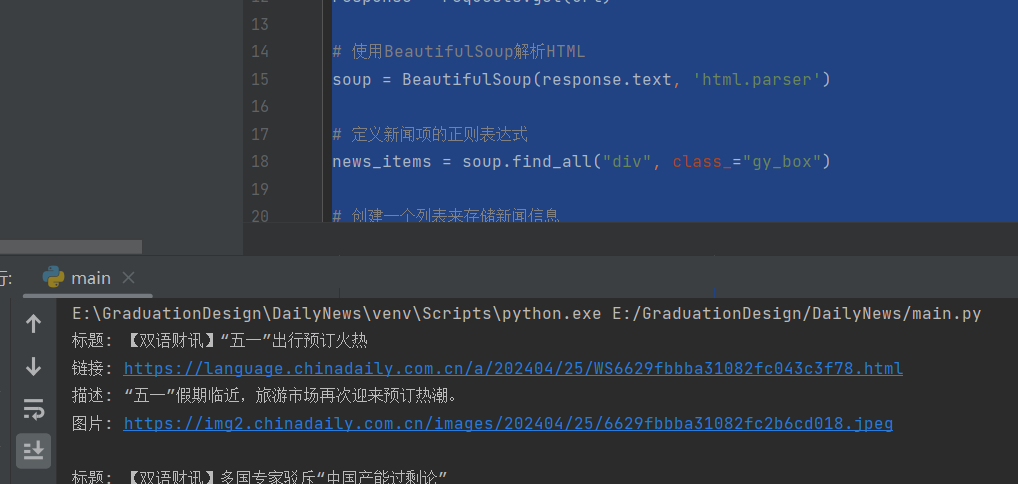
for news in news_list:
print(f"标题: {news['title']}")
print(f"链接: {news['link']}")
print(f"描述: {news['description']}")
print(f"图片: {news['image']}\n")
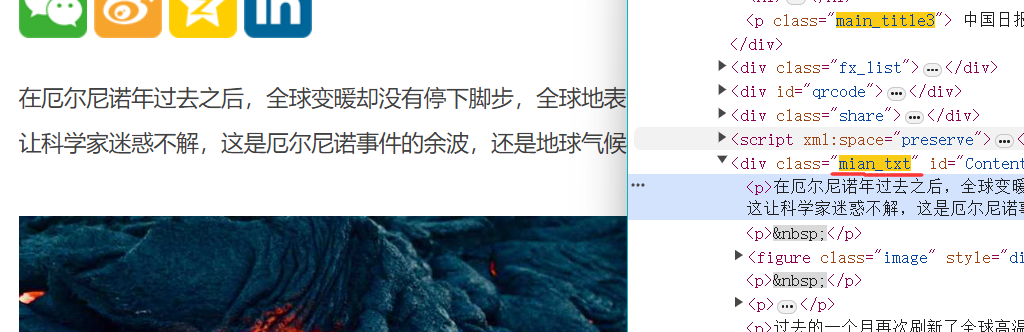
- 接着是a标签里的详情页,找到所需的时间、来源main_title3,主要内容mian_txt
import requests
from bs4 import BeautifulSoup
import json
import re
# 详情页链接
detail_url = "https://language.chinadaily.com.cn/a/202404/25/WS6629fbbba31082fc043c3f78.html"
# 获取详情页内容
response = requests.get(detail_url)
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取时间和来源
time_source = soup.find("p", class_="main_title3").get_text().strip()
# 时间和来源: 中国日报网
# 2024-04-25 14:44
source, time = [item.strip() for item in time_source.split('\n')]
# 提取详细内容
# main_content = soup.find("div", class_="mian_txt").get_text().strip()
content_tags = soup.find("div", class_="mian_txt").find_all("p")
content = [tag.get_text().strip() for tag in content_tags if tag.get_text().strip()] if content_tags else None
# 将列表转换为字符串
content_str = json.dumps(content)
# 输出提取的内容
print(f"详细内容: {content}")
print(f"详细内容: {content_str}")
- 由于为了灵活展示内容实现仅显示英文、仅显示中文或按不同顺序显示的需求,将其转成列表,然后我的数据库时mysql存储不了数组列表,将其转为字符串再存入,
- 后端从数据库取出的时候再转为列表,给前端flutter数据展示
开始运行。。
- 在爬取到某一个新闻的时候突然报错了
detail_response = requests.get(link)
detail_soup = BeautifulSoup(detail_response.text, 'html.parser')
# 提取时间和来源
time_source = detail_soup.find("p", class_="main_title3").get_text(separator='\n').strip()
# 时间和来源: 中国日报网
# 2024-04-25 14:44
source, _time = [item.strip() for item in time_source.split('\n') if item.strip()]
print(f"时间: {_time}")
published_time = datetime.strptime(_time, "%Y-%m-%d %H:%M")
报错显示 Traceback (most recent call last): File "E:/GraduationDesign/DailyNews/main.py", line 66, in source, _time = [item.strip() for item in time_source.split('\n') if item.strip()] ValueError: not enough values to unpack (expected 2, got 1)
询问gpt:错误 “not enough values to unpack (expected 2, got 1)” 通常发生在试图解构一个包含少于所需数量的元素的列表时。在这个案例中,可能是因为 split('\n')没有正确产生预期的两个元素。
多次修改后还是不行,提取不到,但是我写了一个测试类:
from datetime import datetime
import requests
from bs4 import BeautifulSoup
import json
import re
# 详情页链接
detail_url = "https://language.chinadaily.com.cn/a/202403/01/WS65e1a05ba31082fc043ba144.html"
# 获取详情页内容
# response = requests.get(detail_url)
response = """
<!-- 内容 -->
<div class="content">
<div class="content_left">
<div class="main">
<div class="main_title">
<h1><span class="main_title1">【双语财讯】国内外专家对中国今年经济增速充满信心</span>
<span class="main_title2">Economists express confidence in growth this year</span></h1>
<p class="main_title3">
中国日报网
2024-03-01 17:31</p>
</div>
"""
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response, 'html.parser')
time_source = soup.find("p", class_="main_title3").get_text().strip()
# 使用正则表达式提取时间和来源
pattern = r'([^\d]+)(\d{4}-\d{2}-\d{2} \d{2}:\d{2})'
matches = re.search(pattern, time_source)
if matches:
source = matches.group(1).strip()
_time = matches.group(2).strip()
print(f"来源: {source} 时间: {_time}")
# 解析时间
published_time = datetime.strptime(_time, "%Y-%m-%d %H:%M")
print(f"时间: {published_time}")
else:
raise ValueError("无法提取时间和来源,请检查原始数据")
# # 提取时间和来源
# time_source = soup.find("p", class_="main_title3").get_text(separator='\n').strip()
# print(f"时间和来源: {time_source}")
# # 时间和来源: 中国日报网
# # 2024-04-25 14:44
# source, time = [item.strip() for item in time_source.split('\n') if item.strip()]
# print(f"来源: {source}")
# print(f"时间: {time}")
# 提取详细内容
# main_content = soup.find("div", class_="mian_txt").get_text().strip()
# content_tags = soup.find("div", class_="mian_txt").find_all("p")
# content = [tag.get_text().strip() for tag in content_tags if tag.get_text().strip()] if content_tags else None
# # 将列表转换为字符串
# content_str = json.dumps(content)
# # 输出提取的内容
# print(f"详细内容: {content}")
# print(f"详细内容: {content_str}")
# 计算单词数量
def count_words(text):
# 使用正则表达式提取所有英文单词
words = re.findall(r'\b[a-zA-Z]+\b', text)
return len(words)
# 计算列表中所有文本的英文单词数量
# total_words = sum(count_words(item) for item in content)
# print(f"总单词数: {total_words}")
结果:
E:\GraduationDesign\DailyNews\venv\Scripts\python.exe E:/GraduationDesign/DailyNews/test.py
来源: 中国日报网 时间: 2024-03-01 17:31
时间: 2024-03-01 17:31:00
进程已结束,退出代码0
- 测试结果是有的,搞不懂什么问题,
- 最后我换一种方法,使用正则匹配p标签而不是使用soup解析
# 获取详情页内容
detail_response = requests.get(link)
detail_soup = BeautifulSoup(detail_response.text, 'html.parser')
time_source = detail_soup.find("p", class_="main_title3").get_text().strip()
# 使用正则表达式匹配 class 为 main_title3 的 p 标签
pattern = r'<p\s+class="main_title3">(.*?)<\/p>'
# 查找匹配
matches = re.search(pattern, detail_response.text, re.DOTALL)
if matches:
# 提取内容并去除多余的空白
extracted_content = matches.group(1).strip()
# 使用正则表达式提取来源和时间
# 来源: 中国日报网 时间: 2024-03-01 17:31
pattern = r'([^\d]+)(\d{4}-\d{2}-\d{2} \d{2}:\d{2})'
time_matches = re.search(pattern, extracted_content)
if time_matches:
source = time_matches.group(1).strip()
_time = time_matches.group(2).strip()
print(f"来源: {source}, 时间: {_time}")
# 解析时间
publish_time = datetime.strptime(_time, "%Y-%m-%d %H:%M")
# print(f"解析后的时间: {published_time}")
else:
print("无法提取来源和时间")
else:
print("未找到 class 为 main_title3 的 p 标签")
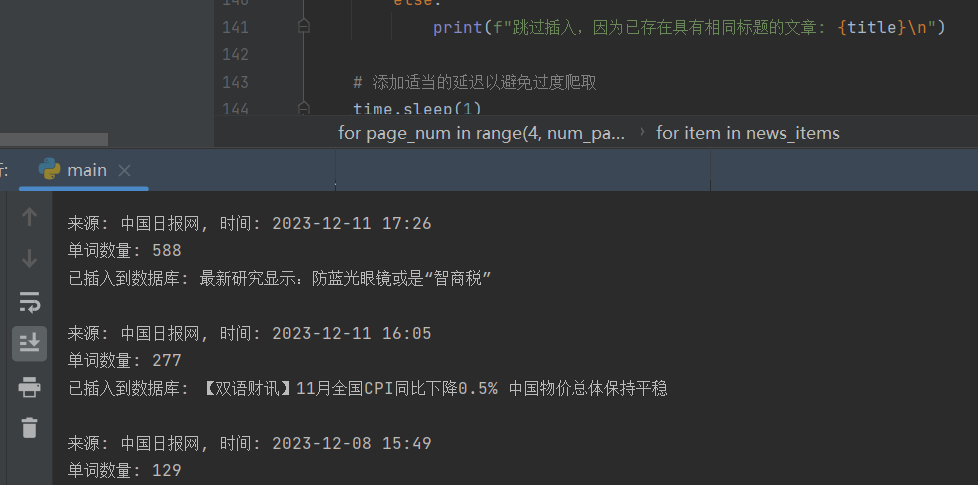
神奇的事可以了,anyway,记录一下~
完整代码
import requests
import re
import time
from datetime import datetime
import json
import pymysql
from bs4 import BeautifulSoup
# 数据库配置
db_config = {
'host': 'localhost',
'user': 'xxx',
'password': 'xxx',
'db': 'xxxx数据库名',
'charset': 'utf8mb4',
}
# 初始化数据库连接
db = pymysql.connect(**db_config)
cursor = db.cursor()
# 新闻列表页URL模板
base_url = "https://language.chinadaily.com.cn/news_bilingual/page_{page}.html"
# 计算单词数量
def count_words(text):
# 使用正则表达式提取所有英文单词
words = re.findall(r'\b[a-zA-Z]+\b', text)
return len(words)
# 循环爬取多页新闻列表
num_pages = 10 # 可以根据需要设置
for page_num in range(1, num_pages + 1):
list_url = base_url.format(page=page_num)
print(f"爬取第 {page_num} 页...")
response = requests.get(list_url)
# 睡眠0.5秒
time.sleep(0.5)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取新闻列表
news_items = soup.find_all("div", class_="gy_box")
# 遍历新闻列表并提取详细信息
for item in news_items:
# 获取新闻标题、链接、描述和图片链接
title_tag = item.find("p", class_="gy_box_txt2").find("a")
title = title_tag.get_text().strip()
link = "https:" + title_tag["href"]
description = item.find("p", class_="gy_box_txt3").get_text().strip()
image_link = "https:" + item.find("a", class_="gy_box_img").find("img")["src"]
# 获取详情页内容
detail_response = requests.get(link)
detail_soup = BeautifulSoup(detail_response.text, 'html.parser')
time_source = detail_soup.find("p", class_="main_title3").get_text().strip()
# 使用正则表达式匹配 class 为 main_title3 的 p 标签
pattern = r'<p\s+class="main_title3">(.*?)<\/p>'
# 查找匹配
matches = re.search(pattern, detail_response.text, re.DOTALL)
if matches:
# 提取内容并去除多余的空白
extracted_content = matches.group(1).strip()
# 使用正则表达式提取来源和时间
# 来源: 中国日报网 时间: 2024-03-01 17:31
pattern = r'([^\d]+)(\d{4}-\d{2}-\d{2} \d{2}:\d{2})'
time_matches = re.search(pattern, extracted_content)
if time_matches:
source = time_matches.group(1).strip()
_time = time_matches.group(2).strip()
print(f"来源: {source}, 时间: {_time}")
# 解析时间
publish_time = datetime.strptime(_time, "%Y-%m-%d %H:%M")
# print(f"解析后的时间: {published_time}")
else:
print("无法提取来源和时间")
else:
print("未找到 class 为 main_title3 的 p 标签")
# 提取作者
author_tag = detail_soup.find("p", string=re.compile("编辑:"))
author = author_tag.get_text().strip() if author_tag else None
# 提取文章内容
content_tags = detail_soup.find("div", class_="mian_txt").find_all("p")
content = [tag.get_text().strip() for tag in content_tags if tag.get_text().strip()] if content_tags else None
# 将列表转换为字符串
content_str = json.dumps(content)
# 计算列表中所有文本的英文单词数量
word_count = sum(count_words(item) for item in content)
# 输出提取的所有8个字段
# print(f"标题: {title}")
# print(f"作者: {author}")
# print(f"描述: {description}")
# print(f"链接: {link}")
# print(f"图片链接: {image_link}")
# print(f"发布时间: {published_time}")
# print(f"来源: {source}")
# print(f"内容: {content}")
print(f"单词数量: {word_count}")
# 插入数据库之前,检查是否已经存在具有相同标题的文章
select_query = "SELECT COUNT(*) FROM articles WHERE title = %s"
cursor.execute(select_query, (title,))
result = cursor.fetchone()
# 如果不存在具有相同标题的文章,执行插入操作
if result[0] == 0:
insert_query = """INSERT INTO articles (title, author, description, url, urlToImage, publish_time, content,
source_name, word_count) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s) """
data = (
title,
author,
description,
link,
image_link,
publish_time,
content_str,
source,
word_count
)
cursor.execute(insert_query, data)
db.commit() # 确保插入到数据库
print(f"已插入到数据库: {title}\n")
else:
print(f"跳过插入,因为已存在具有相同标题的文章: {title}\n")
# 添加适当的延迟以避免过度爬取
time.sleep(1)
# 关闭数据库连接
cursor.close()
db.close()
爬取每日一词
- 首先设计数据库表
CREATE TABLE news_hotwords (
id INT NOT NULL AUTO_INCREMENT,
title VARCHAR(255) NOT NULL, -- 标题
url VARCHAR(255) NOT NULL, -- 热词链接
image_url VARCHAR(255), -- 图片链接
description TEXT, -- 描述
content TEXT, -- 内容(JSON字符串)
publish_time DATETIME, -- 发布时间
PRIMARY KEY (id)
);
- 接着分析网页标签,发现跟双语新闻的差不多,详情页不太一样,小问题
完整代码
# 初始化数据库连接
db = pymysql.connect(**db_config)
cursor = db.cursor()
# 每日一词列表页URL模板
base_url = "https://language.chinadaily.com.cn/news_hotwords/page_{page}.html"
# 循环爬取多页每日一词列表
num_pages = 10 # 可以根据需要设置
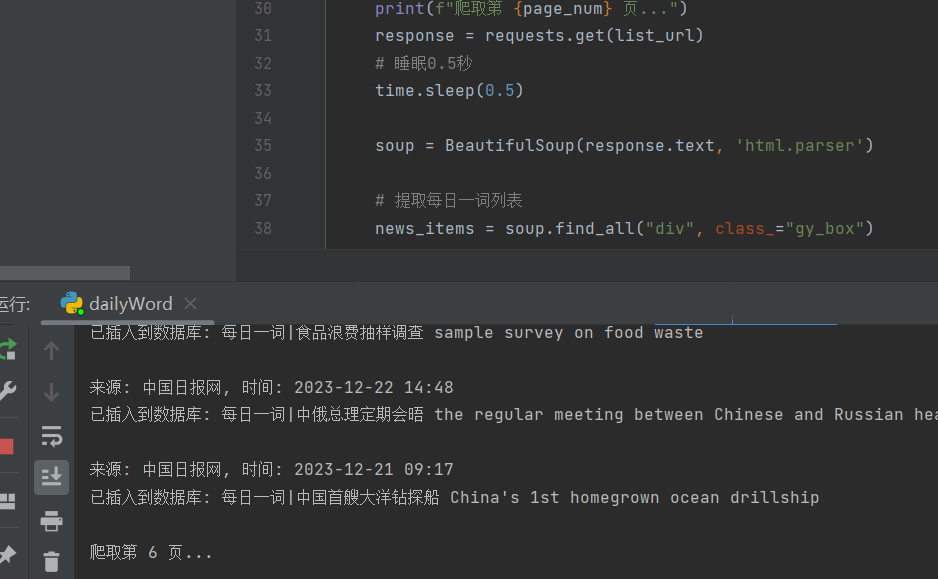
for page_num in range(2, num_pages + 1):
list_url = base_url.format(page=page_num)
print(f"爬取第 {page_num} 页...")
response = requests.get(list_url)
# 睡眠0.5秒
time.sleep(0.5)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取每日一词列表
news_items = soup.find_all("div", class_="gy_box")
# 遍历每日一词列表并提取详细信息
for item in news_items:
# 获取标题、链接、描述、图片链接
title_tag = item.find("p", class_="gy_box_txt2").find("a")
title = title_tag.get_text().strip()
link = "https:" + title_tag["href"]
description = item.find("p", class_="gy_box_txt3").get_text().strip()
image_link = "https:" + item.find("a", class_="gy_box_img").find("img")["src"]
# 获取详情页内容
detail_response = requests.get(link)
detail_soup = BeautifulSoup(detail_response.text, 'html.parser')
# 提取时间和来源
time_source = detail_soup.find("p", class_="main_title3").get_text().strip()
# 使用正则表达式匹配 class 为 main_title3 的 p 标签
pattern = r'<p\s+class="main_title3">(.*?)<\/p>'
# 查找匹配
matches = re.search(pattern, detail_response.text, re.DOTALL)
if matches:
# 提取内容并去除多余的空白
extracted_content = matches.group(1).strip()
# 使用正则表达式提取来源和时间
# 来源: 中国日报网 时间: 2024-03-01 17:31
pattern = r'([^\d]+)(\d{4}-\d{2}-\d{2} \d{2}:\d{2})'
time_matches = re.search(pattern, extracted_content)
if time_matches:
source = time_matches.group(1).strip()
_time = time_matches.group(2).strip()
print(f"来源: {source}, 时间: {_time}")
# 解析时间
publish_time = datetime.strptime(_time, "%Y-%m-%d %H:%M")
# print(f"解析后的时间: {published_time}")
else:
print("无法提取来源和时间")
else:
print("未找到 class 为 main_title3 的 p 标签")
# 提取文章内容为列表
content_tags = detail_soup.find("div", id="Content").find_all("p")
content = [tag.get_text().strip() for tag in content_tags if tag.get_text().strip()] if content_tags else None
# 将列表转换为JSON字符串
content_str = json.dumps(content)
# 插入数据库之前,检查是否已经存在具有相同标题的文章
select_query = "SELECT COUNT(*) FROM news_hotwords WHERE title = %s"
cursor.execute(select_query, (title,))
result = cursor.fetchone()
# 如果不存在具有相同标题的文章,执行插入操作
if result[0] == 0:
insert_query = """INSERT INTO news_hotwords (title, url, image_url, description, publish_time, content,
source_name) VALUES (%s, %s, %s, %s, %s, %s, %s) """
data = (
title,
link,
image_link,
description,
publish_time,
content_str,
source
)
cursor.execute(insert_query, data)
db.commit() # 确保插入到数据库
print(f"已插入到数据库: {title}\n")
else:
print(f"跳过插入,因为已存在具有相同标题的热词文章: {title}\n")
# 添加适当的延迟以避免过度爬取
time.sleep(1)
# 关闭数据库连接
cursor.close()
db.close()
每日一句
通过免费api每日一句英文 - 教书先生API 免费API数据接口调用服务平台 (oioweb.cn)
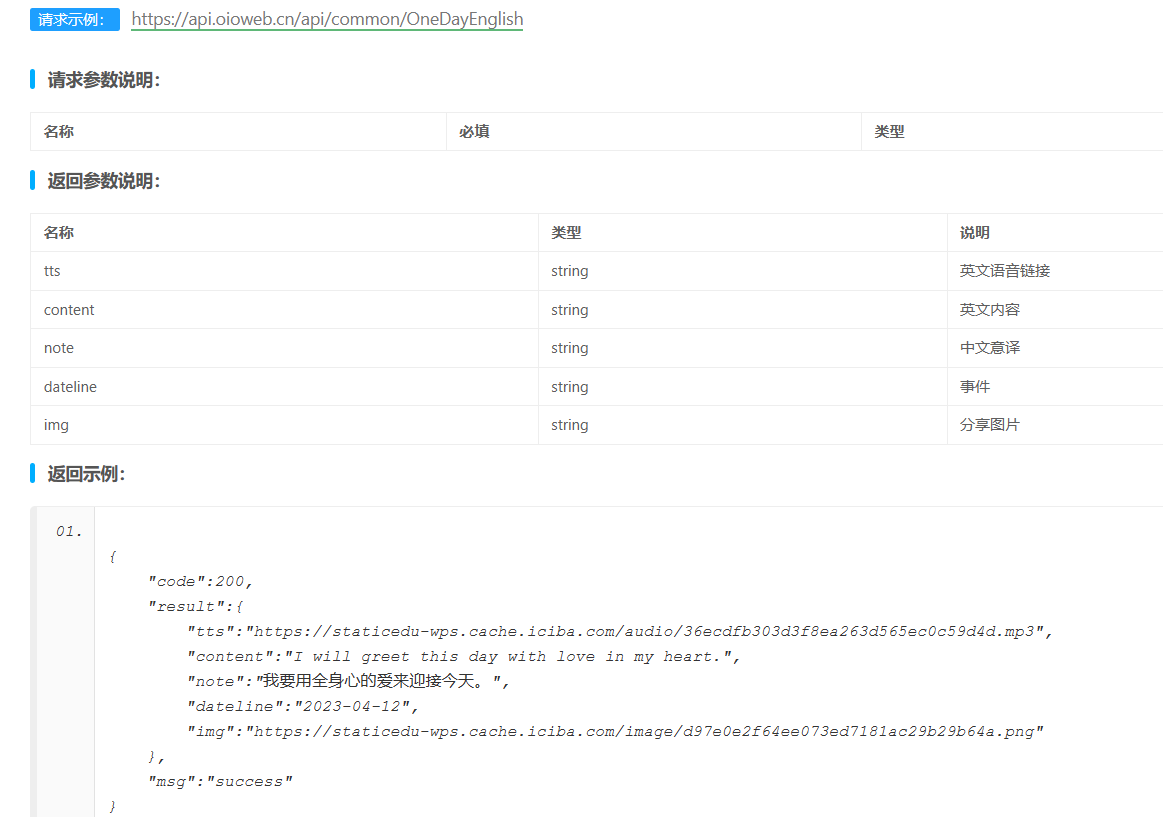
- py
电子书
- 通过Developer Center | 开放图书馆 (openlibrary.org)提供的api进行访问,在其开发人员中心中有详细的介绍,
- 电报搜索或者磁力网盘搜索英语学习资源,
-
额接着编写代码,后台管理系统中使用element的上传函数,后端接口存到阿里云oss,返回url存数据库中,
-
先建立表
CREATE TABLE e_books ( id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(255) NOT NULL COMMENT '名称', author VARCHAR(255) COMMENT '作者', filePath VARCHAR(255) NOT NULL COMMENT '存储OSS中的文件路径', fileType VARCHAR(10) NOT NULL COMMENT 'pdf 或 epub', createdAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', updatedAt TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间' ) CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='电子书表'; CREATE TABLE e_book_attributes ( id INT AUTO_INCREMENT PRIMARY KEY, e_book_id INT NOT NULL COMMENT '关联e_books表id', attribute_key VARCHAR(255) COMMENT '属性键(如series-系列, version-版本, issue-期数等)', attribute_value VARCHAR(255) COMMENT '属性值' ) CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='电子书属性表'; -
后端四层架构代码,使用
idea插件easycode自动生成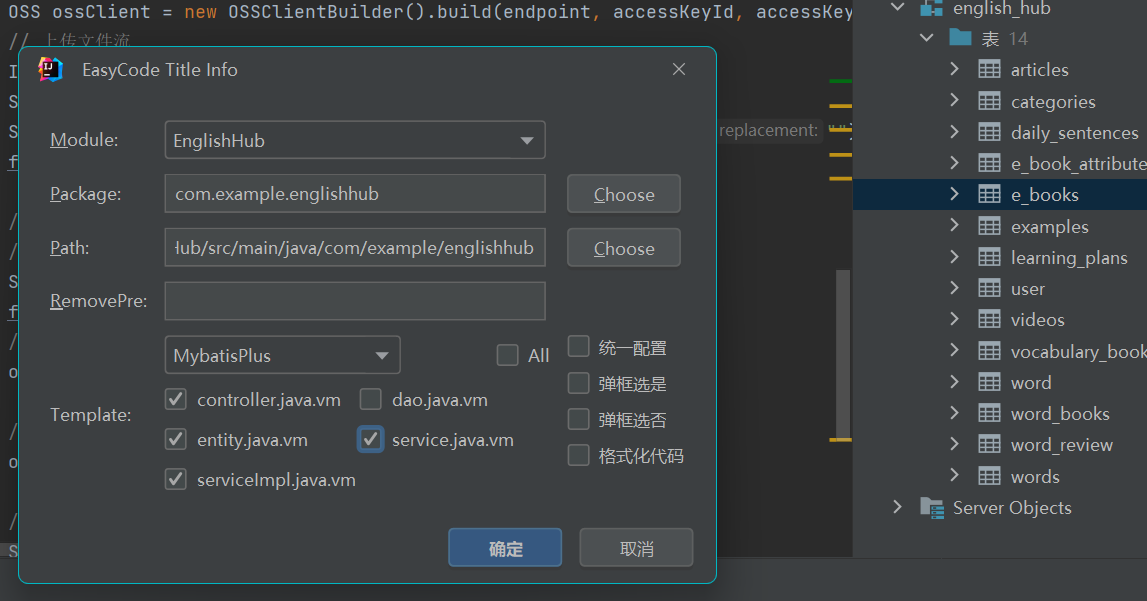 或者用mybatis-plus的代码生成器
或者用mybatis-plus的代码生成器
-
-
本人使用的是
springboot3+mybatis-plus中的fastgenerator跟刚刚的EazyCode混合使用,easycode生成控制层controller,其余三层则由代码生成器package com.example.englishhub; import com.baomidou.mybatisplus.generator.FastAutoGenerator; import com.baomidou.mybatisplus.generator.config.rules.DbColumnType; import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine; import java.io.File; import java.sql.Types; /** * @Author: hahaha * @Date: 2024/4/14 21:06 */ public class CodeGenerator { public static void main(String[] args) { // 数据库配置信息 String url = "jdbc:mysql://localhost:3306/你的数据库名?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC"; String username = "xxx"; String password = "xxx"; // 当前项目路径 String currentPath = new File("").getAbsolutePath(); String codeOutputDir = currentPath + "/src/main/java"; FastAutoGenerator.create(url, username, password) .globalConfig(builder -> { // 设置作者 builder.author("hahaha") // 指定输出目录 .outputDir(codeOutputDir); }) .dataSourceConfig(builder -> builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> { int typeCode = metaInfo.getJdbcType().TYPE_CODE; if (typeCode == Types.SMALLINT) { return DbColumnType.INTEGER; } return typeRegistry.getColumnType(metaInfo); })) .packageConfig(builder -> { // 设置父包名 builder.parent("com.example") // 设置父包模块名 .moduleName("englishhub") // pojo 实体类包名 .entity("entity") // Service 包名 .service("service") // ***ServiceImpl 包名 .serviceImpl("service.impl") // Mapper 包名 .mapper("mapper") // Controller 包名 .controller("controller"); }) .strategyConfig(builder -> { // 设置需要生成的表名 builder.addInclude("e_book_attributes") // 设置过滤表前缀 .addTablePrefix("t_") // Entity 配置 .entityBuilder() // 开启 lombok 模型 .enableLombok() // 覆盖已生成文件 .enableFileOverride() // Controller 配置 .controllerBuilder() // 开启生成 @RestController 控制器 .enableRestStyle() // 覆盖已生成文件 .enableFileOverride() // Service 配置 .serviceBuilder() // 覆盖已生成文件 .enableFileOverride() // Mapper 配置 .mapperBuilder() // 覆盖已生成文件 .enableFileOverride(); }) // 默认的是 Velocity引擎模板 .templateEngine(new FreemarkerTemplateEngine()) .execute(); } } -
我的项目目录
编写逻辑
- 后端
视频
类包名
.entity(“entity”)
// Service 包名
.service(“service”)
// ***ServiceImpl 包名
.serviceImpl(“service.impl”)
// Mapper 包名
.mapper(“mapper”)
// Controller 包名
.controller(“controller”);
})
.strategyConfig(builder -> {
// 设置需要生成的表名
builder.addInclude(“e_book_attributes”)
// 设置过滤表前缀
.addTablePrefix(“t_”)
// Entity 配置
.entityBuilder()
// 开启 lombok 模型
.enableLombok()
// 覆盖已生成文件
.enableFileOverride()
// Controller 配置
.controllerBuilder()
// 开启生成 @RestController 控制器
.enableRestStyle()
// 覆盖已生成文件
.enableFileOverride()
// Service 配置
.serviceBuilder()
// 覆盖已生成文件
.enableFileOverride()
// Mapper 配置
.mapperBuilder()
// 覆盖已生成文件
.enableFileOverride();
})
// 默认的是 Velocity引擎模板
.templateEngine(new FreemarkerTemplateEngine())
.execute();
}
}
- 我的项目目录
[外链图片转存中...(img-KSyErRKo-1715576133056)]
### 编写逻辑
- 后端
## 视频




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











