









计算机是如何执行递归函数的呢? 答案是使用递归工作栈(recursion stack)。
- 当一个函数被调用时,一个返回地址( 即被调函数一旦执行完,接下去要执行的程序指令的地址)和被调函数的局部变量和形参的值都要存储在递归工作栈中。当执行一次返回时,被调函数的局部变量和形参的值被恢复为调用之前的值(这些值存储在递归工作栈的顶部),而且程序从返回地址处继续执行,这个返回地址也存储在递归工作栈的顶部。
如果把数组线性表的右端定义为栈顶,那么入栈和出栈操作对应的就是线性表在最好情况下的插入和删除操作。结果两个操作的时间都为O(1)。
用链表的左端作为栈顶,需要调用的链表方法是get(0)、insert(0,theElement) 和erase(0),其中每一个链表方法需要用时0(1)。分析表明,我们应该选择链表的左端作为栈顶。
括号匹配
- 通过观察可以发现,如果从左至右地扫描一个字符串,那么每一个右括号都与最近扫描的那个未匹配的左括号相匹配。
- 这种观察结果促使我们在从左至右的扫描过程中,将扫描到的左括号保存到栈中。每当扫描都一个右括号,就将它与栈顶的左括号(如果存在)相匹配,并将匹配的左括号从栈顶删除。
void printMatchedPairs(string expr)
{
//括号匹配
arrayStack<int> s;
int length = (int) expr.size() ;
//扫描表达式expr寻找左括号和右括号
for (int i = 0; i < length; i++)
{
if (expr.at(i) == '(')
s.push(i);
else
if (expr.at(i) == ')')
{
try
{//从栈中删除匹配的左括号
cout << s.top() << ' ' << i << endl;
s.pop() ;
}
//没有栈匹配
catch (stackEmpty)
{//栈为空。没有匹配的左括号
cout << "No match for right parenthesis"<< "at"<< i << endl;
//栈不为空。剩余在栈中的左括号是不匹配的
}
}
}
while (!s.empty())
{
cout << "No match for left parenthesis at”<< s.top() << endl;
s.pop() ;
}
}
使用栈求解汉诺塔问题
//全局变量,tower[1:3] 表示三个塔
arrayStack<int> tower[4] ;
void moveAndShow(int,int, int, int) ;
void towersOfHanoi(int n)
{//函数moveAndShow的预处理程序
for(int d=n;d>0;d--)
//初始化
tower[1].push(d);//把碟子d加到塔1
//把n个碟子从塔1移到塔3,用塔2作为中转站
moveAndShow(n,1, 2,3) ;
}
void moveAndShow(int n, int X,int y, int z)
{//把塔x顶部的n个碟子移到塔y,显示移动后的布局
//用塔z作为中转站
if(n>0)
{
moveAndshow(n-1, X,Z,y) ;
int d = tower[x].top() ; //把一个碟子:
tower[x].pop() ; //从塔x的顶部移到
tower[y].push(d) ; //塔y的顶部
showState() ;
//显示塔3的布局
moveAndShow(n-1, Z, y, x) ;
}
}
列车车厢重排


开关盒布线
- 每对要连接的管脚称为一个网组。对于给定的一些网组,我们需要确定,它们能否连接而又不发生交叉。
- 图8-8a是一个布线的示例,其中有8个管脚和4个网组。四个网组分别是(1,4),(2,3), (5, 6)和(7, 8)。图8-8b的布线在网组( 1, 4)和(2, 3)之间有交叉,而图8-8c的布线没有交叉。因为这4个网组的布线可以没有交叉,所以这个开关盒称为可布线开关盒( routable switch box)。

- 如果从管脚1开始沿顺时针方向遍历图8-8a的管脚,那么遍历的管脚顺序是1, 2,.,8。管脚1和4是一个网组,于是管脚1至4之间出现的所有管脚构成第一个分区,管脚4至1之间出现的所有管脚构成另一个分区。
- 把管脚1插入栈,然后继续处理,直到管脚4。这个过程使我们仅在处理完一个分区之后才能进入下一个分区。 下一个是管脚2,它与管脚3是一个网组,它们把当前分区分成两个分区。与前面的做法一样,把管脚2插入栈,然后继续处理,直到管脚3。由于管脚3和管脚2是一个网组,而管脚2正处在栈顶, 可将管脚2从栈顶删除。接下来将遇到管脚4,可从栈顶删除管脚1。
- 按照这种方法继续下去,我们可以完成对所有分区的处理,而且当8个管脚都检查之后,栈为空。
- 所以程序的输入数组为:[1,2,2,1,3,3,4,4] -> 对于索引为:[1,2,3,4,5,6,7,8]
迷宫老鼠
-
首先把迷宫的入口作为当前位置。如果当前位置是迷宫出口,那么已经找到了一条路径,寻找工作结束。
-
如果当前位置不是迷宫出口,则在当前位置上放置障碍物,以阻止寻找过程又绕回到这个位置。然后检查相邻位置是否有空闲(即没有障碍物), 如果有,就移动到一个空闲的相邻位置上,然后从这个位置开始寻找通往出口的路径。如果不成功,就选择另一个空闲的相邻位置, 并从它开始寻找通往出口的路径。
-
为了方便移动,在进入新的相邻位置之前,把当前位置保存在一个栈中。如果所有空闲的相邻位置都已经被探索过,但还未能找到路径,则表明迷宫不存在从入口到出口的路径。

-
我们需要把迷宫(一个0和1的矩阵)、迷宫的每个位置以及栈都表示出来。
-
迷宫一般被描述成一个int类型的二维数组maze。(由于每个数组的位置仅有0或1两种取值,因此可以用bool型二维数组,true 代表1, false代表0。 这样,表示迷宫的数组空间就被减少了。)迷宫矩阵的位置(i, j)对应于数组maze的位置[i] [j]。
-
现在,迷宫的所有位置都处在一圈障碍物所围成的边界之内,从迷宫的每个位置开始,都有4种可能的移动方向(可能每个方向都有障碍物)。因为给迷宫围上了一圈障碍物,所以程序不再需要处理边界条件。
-
可以定义一个带有数据成员row和col的类position,使用它的对象来跟踪记录迷宫位置。用数组表示栈,栈用来保存从入口到当前位置的路径。一个没有障碍物的m*m迷宫,最长的路径可包含m^2个位置。
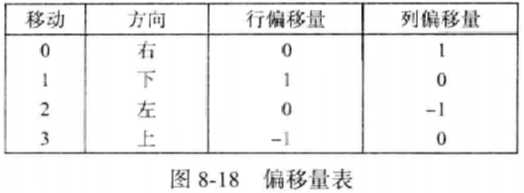
-
计算这些坐标。把向右、向下、向左和向上移动分别表示为0、1、2和3。在图8-18的表中, offset[i].row 和 offset[j].col 分别是从当前位置沿方向i移动到下一个相邻位置时,row 和col坐标的增量。















 2199
2199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









