







该模板实例化参考了
https://zhuanlan.zhihu.com/p/596449652
引入
这次的神经网络是预测一个数是否大于8,典型的高射炮打蚊子了哈哈,但是对于刚入门不久的我来说还是比较有用的。
采用的是Pytorch深度学习框架,一般而言还是采用gpu来加速计算比较舒服,gpu比cpu真是快了不少。
在这里提供一份可以测试gpu与cpu运算速度差距的代码(gpu运算精度会比cpu差,因为gpu是单精度浮点型,cpu双精度浮点型,当然这是因为我的显卡不够牛掰的原因,牛掰的显卡显然也有双精度浮点型)
'''
**************************************************
@File :torch_test -> main
@IDE :PyCharm
@Author :TheOnlyMan
**************************************************
'''
import torch
import torch.nn as nn
import time
from threading import Thread
def test1():
flag = torch.cuda.is_available()
print(flag)
ngpu = 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3, 3).cuda())
print(torch.__version__)
def test2():
# ----------- 判断模型是在CPU还是GPU上 ----------------------
model = nn.LSTM(input_size=10, hidden_size=4, num_layers=1, batch_first=True)
print(next(model.parameters()).device) # 输出:cpu
model = model.cuda()
print(next(model.parameters()).device) # 输出:cuda:0
model = model.cpu()
print(next(model.parameters()).device) # 输出:cpu
# ----------- 判断数据是在CPU还是GPU上 ----------------------
data = torch.ones([2, 3])
print(data.device) # 输出:cpu
data = data.cuda()
print(data.device) # 输出:cuda:0
data = data.cpu()
print(data.device) # 输出:cpu
def test3():
a = torch.rand(5000, 5000)
for i in range(1, 10):
start_time = time.time()
a.matmul(a)
Cul_end_time = time.time() - start_time
print(f'CPU:{i}->', Cul_end_time)
print(a.norm())
def test4():
a = torch.rand(5000, 5000).cuda()
for i in range(1, 10):
# torch.cuda.synchronize()
start_time = time.time()
a.matmul(a)
# torch.cuda.empty_cache()
# torch.cuda.synchronize()
Cul_end_time = time.time() - start_time
print(f'GPU:{i}->', Cul_end_time)
print(a.norm())
def test5():
x = torch.ones(3, 3)
print(x)
y = x*2
print(y)
print(x*y)
def test6():
start = time.time()
t1 = Thread(target=test3, name='T1', args=())
t2 = Thread(target=test3, name='T2', args=())
t1.start()
t2.start()
t1.join()
t2.join()
print(time.time() - start)
def test7():
start = time.time()
t1 = Thread(target=test3, name='T1', args=())
t2 = Thread(target=test4, name='T2', args=())
t1.start()
t2.start()
t1.join()
t2.join()
print(time.time() - start)
def test8():
start_cpu = time.time()
test3()
end_cpu = time.time()
start_gpu = time.time()
test4()
end_gpu = time.time()
print('CPU:', end_cpu - start_cpu)
print('GPU:', end_gpu - start_gpu)
if __name__ == '__main__':
test8()
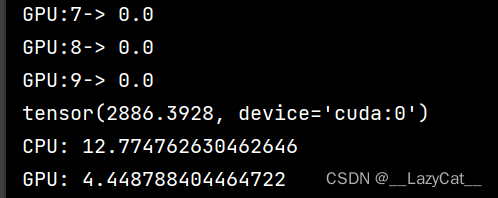
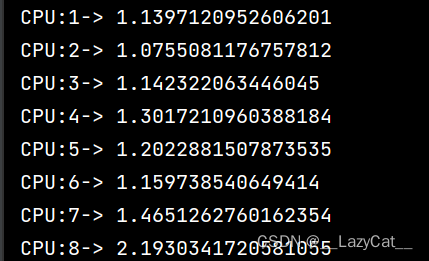
可以看到,gpu的运算速度是真的快,大概有cpu的30倍左右,这里因为我设置测试数据少,那么数据从转移到显存再转移回来都需要一定的时间。
观察一下cpu各个测试点的时间都是1s左右,而gpu除了第一次导入需要一点时间,接下来的运算时间都几乎为0。
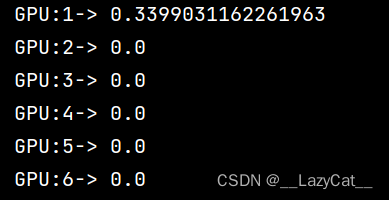
答案也是有一定差距的,就是刚才说到的gpu精度问题。


代码还附带了多线程的比较,感兴趣的可以自己试试。
好了回归主题。整体来说,构建一个较为完整的模型分为五个阶段:
- 模型定义
- 数据处理和加载
- 训练模型(Train and Validate)
- 测试模型
- 训练过程可视化(可选)
接下来根据这五个阶段构建一个完整的神经网络来拍这个蚊子(一个数是否大于8)。
正文
模型定义
在模型定义之前,我们需要先提前导入合适的库,同时设置随机数种子(设置42比较具有深刻的含义,但我偏向一个大质数998244353)
import random
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
seed = 998244353
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
torch.cuda.manual_seed_all(seed)
这里设置一个超参数类来保存所需要的参数,其中包含这次训练用的超小型数据集和测试集。
class ArgParse:
def __init__(self) -> None:
self.batch_size = 1
self.lr = 0.01
self.epochs = 30
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.data_train = np.array([-1, 2, 8, 3, 4, 9, 10, 11, 0, 13, -3, 5])
self.data_test = np.array([0, 3, 2, 8, 9, 11, 12, 4])
然后就是经典的神经网络结构了:
class MyModel(nn.Module):
def __init__(self, in_dim, hidden1, hidden2, out_dim):
super(MyModel, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim, hidden1), nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(hidden1, hidden2), nn.ReLU(True)
)
self.layer3 = nn.Sequential(
nn.Linear(hidden2, out_dim), nn.ReLU(True)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
数据处理和加载
这里继承Dataset类构造出一个新的派生类来处理数据,其中__getitem__方法用来遍历数据,其中由于设置batch_size为1,每次抽一个就够了。
class DataSet(Dataset):
def __init__(self, flag='train') -> None:
self.flag = flag
assert flag in ['train', 'test'], 'not implement'
if self.flag == 'train':
self.data = ArgParse().data_train
else:
self.data = ArgParse().data_test
def __getitem__(self, item):
val = self.data[item]
label = 1 if val > 8 else 0
return torch.tensor(label, dtype=torch.long), torch.tensor([val], dtype=torch.float)
def __len__(self):
return len(self.data)
训练模型(Train and Validate)
内容较长,大概是获取数据,建立损失函数和优化器,进行epochs轮训练,每轮训练将数据样本迭代进行,然后获取损失函数的梯度,根据梯度更新网络参数,同时做一些正确率的预测。
def train():
args = ArgParse()
train_dataset = DataSet('train')
train_loader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, shuffle=True)
test_dataset = DataSet('test')
test_loader = DataLoader(dataset=test_dataset, batch_size=args.batch_size, shuffle=True)
model = MyModel(1, 32, 16, 2).to(args.device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
train_epochs_loss = []
valid_epochs_loss = []
train_acc = []
val_acc = []
for epoch in range(args.epochs):
model.train()
train_epoch_loss = []
acc, nums = 0, 0
for idx, (label, inputs) in enumerate(tqdm(train_loader)):
inputs = inputs.to(args.device)
label = label.to(args.device)
outputs = model(inputs)
optimizer.zero_grad()
loss = criterion(outputs, label)
loss.backward()
optimizer.step()
train_epoch_loss.append(loss.item())
acc += sum(outputs.max(axis=1)[1] == label).cpu()
nums += label.size()[0]
train_epochs_loss.append(np.average(train_epoch_loss))
train_acc.append(100 * acc / nums)
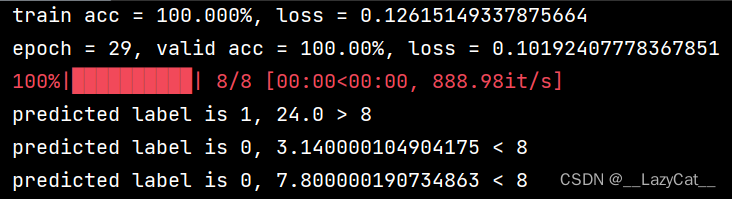
print("train acc = {:.3f}%, loss = {}".format(100 * acc / nums, np.average(train_epoch_loss)))
with torch.no_grad():
model.eval()
val_epoch_loss = []
acc, nums = 0, 0
for idx, (label, inputs) in enumerate(tqdm(test_loader)):
inputs = inputs.to(args.device) # .to(torch.float)
label = label.to(args.device)
outputs = model(inputs)
loss = criterion(outputs, label)
val_epoch_loss.append(loss.item())
acc += sum(outputs.max(axis=1)[1] == label).cpu()
nums += label.size()[0]
valid_epochs_loss.append(np.average(val_epoch_loss))
val_acc.append(100 * acc / nums)
print("epoch = {}, valid acc = {:.2f}%, loss = {}".format(epoch, 100 * acc / nums,
np.average(val_epoch_loss)))
测试模型
这个就是正常的获取训练好的模型然后计算结果了。
def pred(val):
model = MyModel(1, 32, 16, 2)
model.load_state_dict(torch.load('model.pth'))
model.eval()
val = torch.tensor(val).reshape(1, -1).float()
res = model(val)
res = res.max(axis=1)[1].item()
print("predicted label is {}, {} {} 8".format(res, val.item(), ('>' if res == 1 else '<')))
训练过程可视化(可选)数据处理和加载
可视化则是看想要怎么表达数据了。
plt.figure(figsize=(12, 4))
plt.subplot(121)
plt.plot(train_epochs_loss[:])
plt.title("train_loss")
plt.subplot(122)
plt.plot(train_epochs_loss, '-o', label="train_loss")
plt.plot(valid_epochs_loss, '-o', label="valid_loss")
plt.title("epochs_loss")
plt.legend()
plt.show()
torch.save(model.state_dict(), 'model.pth')
结尾
这个例子作为入门模板的使用的还是不错的,关于模块里面的前向传播,反向传播,梯度的相关知识需要自己了解,这里只是提供常用的编写程序思路。















 201
201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









