







浏览器本地存储
在浏览器的本地存储中,有三种常见的方式:cookie, localStroage 和 sessionStorage。接下来就让我们来一起看看它们吧!
1. cookie
1.1) 什么是 cookie ?
cookie 全称 HTTP Cookie(也叫 Web Cookie 或浏览器 Cookie)
它是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上
即,它是浏览器存储数据的一种方式,一般会自动随着浏览器每次请求发送到服务器上
1.2) 它有什么作用 ?
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
1.3) cookie 的属性
让我们来看一下在浏览器中 cookie 的各种属性
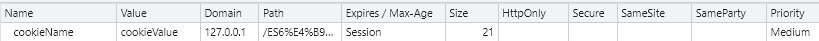
接下来介绍常用的属性:
| 属性 | 属性介绍 |
|---|---|
| Name | cookie 的名称 |
| Value | cookie 的值 |
| Domain | 生成该 cookie 的域名 |
| Path | cookie 生成的路径 |
| Expires / Max-Age | cookie 的过期时间 |
| HttpOnly | 如果设置了,则该 cookie 不能通过 JS 去访问 |
| Secure | 如果设置了,限定 cookie 只有在使用 https 的情况下才可以发送给服务器 |
其中,Name 和 Value 是一个键值对
- 当 Name、Domain、Path 这 3 个都相同时,才是同一个
cookie
在浏览器写入 cookie 的方法
// Name 和 Value 是一个键值对,创建 cookie 时必须填写
document.cookie = "userName = XiXiHaHa";
// 如果需要设置其他项,则用分号隔开
document.cookie = "userName2 = Xii; Path = /study";
-
Domain 和 Path 限定了
cookie的访问范围
(对于 Domain,使用 JS 时,只能读写当前域或父域的cookie)
(对于 Path,使用 JS 时,只能读写当前路径和上级路径的cookie) -
Expires / Max-Age
// 对于 Expires,它的值为 Date 类型
document.cookie = `userName = XiXiHaHa; Expires = ${new Date(想设置的时间)}`;
// 对于 Max-Age,它的值为数字(单位是秒),表示当前时间 + 多少秒后过期
// 如果 Max-Age 的值是 0 或负数,则 cookie 会被删除
document.cookie = `userName2 = Xii; Max-Age = ${24 * 3600}`;
// 这里使用模板字符串,插入表达式,便于计算,修改
// 如果它们没有设置,则该 cookie 在浏览器关闭后就会消失
Tips:
- 浏览器中,每个域名下,
cookie有着数量限制 - 每个
cookie有着大小限制
2. localStorage 和 sessionStorage
2.1) 什么是 localStorage 和 sessionStorage ?
- 它们都是浏览器的一种本地存储数据的方式
- 它们只是存在本地,即浏览器中,不会发送到服务器
它们的区别:
- localStorage:永久存在浏览器中,除非手动删除
- sessionStorage:当浏览器被关闭时,自动消失,存储的数据被清空
2.2) 属性和操作方法
对于 localSorage 的每条存储数据,它们有两个属性,Key 和 Value(是一对键值对)
可以通过它们的 length 属性来查看有多少条
它们的操作方法相同,接下来就以 localStorage 为例
- 创建
// 它的 Key 和 Value 只能是字符串类型,如果不是,则会转换成字符串
localStorage.setItem('userName', 'XiXiHaHa');
- 获取,通过 Key 获取
localStorage.getItem('userName');
// 如果不存在,返回 Null
- 删除:通过 Key 删除
localStorage.removeItem('userName');
// 如果不存在,也不会报错
// 可以使用 clear 一键清空
localStorage.clear();
Tips:
- 浏览器中,在每个域名下,它们有着大小限制
- 不同的域名不能共同
localStorage和sessionStorage














 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









