






- 后尾的 t 分布,不要求所有的样本的均值比较近 (允许存在离异点),因而相较于高斯分布,相对于噪音更加的鲁棒。Note:这是与高斯分布的一个明显差异。假设方差未知,均值是已知的。
- 模型中参数估计:可以直接估计。
不需要EM 算法- t 分布也是潜变量模型

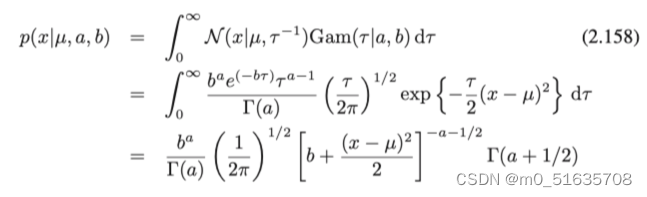
我们通常所知t分布是从抽样分布给出的,这里给出了一个不一样的形式。假如有一
个均值已知、方差未知的单变量高斯和一个Gamma先验,将精度积分出来,得到x的
边际分布:
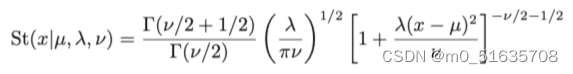
t分布是将无限个具有相同平均值但精度不同的高斯分布相加得到的。这赋予了该分
布一个叫做
鲁棒性的重要属性
,这意味着它对少数数据点的异常值的敏感性要比高斯
分布低得多。
周期变量: 并不是所有的变量都具有连续性
混合高斯分布:当数据具有多峰的模式时,可以尝试使用混合高斯模型。方差和均值都未知

混合高斯分布与t分布的区别:
相似点:都是基于高斯分布,潜变量模型。
区别:混合高斯分许方差和均值都是未知,需要用EM 算法求解。

VAE 模型(补充):
变分自编码(VAE): 都是潜变量,联系?(后面需要完善)。已知观测到的数据,反推决定这个分布的参数?
指数族分布
该分布主要有一下分布模式:


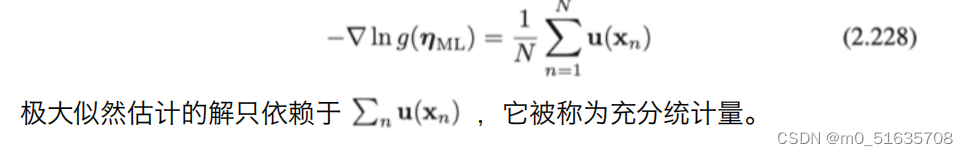
Note:
- 主要是通过数据的分布(分布中的参数)来刻画数据的属性。目前熟悉的分布:高斯分布,t 分布,泊松分布,负二项分布,二项分布。
- 先验分布,回归系数加先验,拉普拉斯先验-lasso,高斯先验-norm2-岭回归。
- 共轭先验,
- 添加先验可以使得估计的参数靠近先验。就是说当我们的先验比较准确的时候,就可以有比较好的解。
- DCA, 变分自编码,这些复杂的分布:(1)观测数据不受隐变量的影响,如来自于不同的类别,(2)隐变量来自于一个分布,这就会导致模型更加的复杂。如何估计这些隐变量就变得更加的复杂。
- 分布的估计问题主要有两种:
- 参数化方法:估计参数就可以反推分布。这样就需要对数据进行一般假设。
- 非参数方法:数据的分布不需要假设。主要的方法,直方图方法,核函数, knn (k 近邻)。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









