






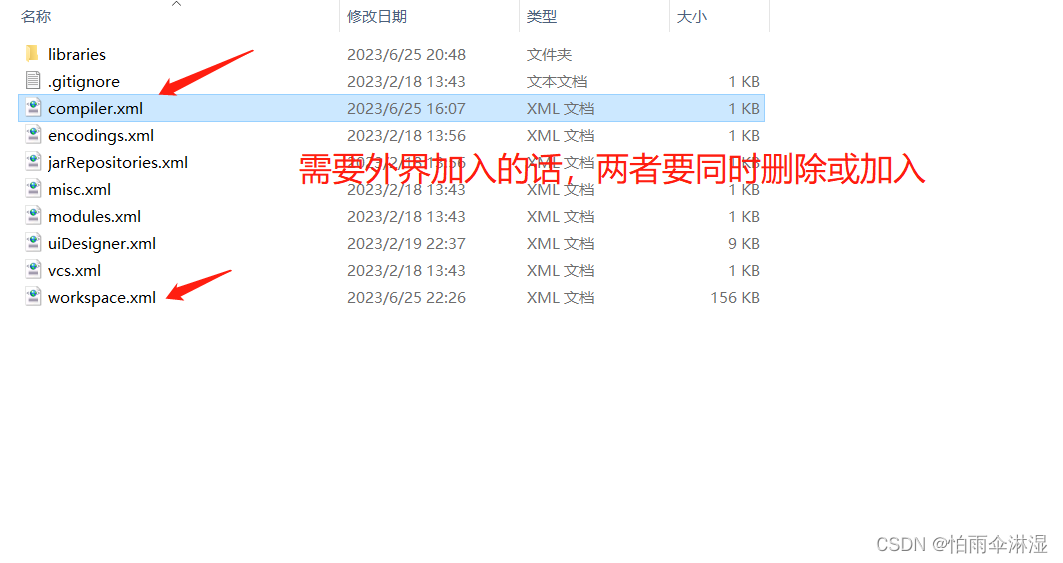
一.初建项目(清除自动生成的多余文件,试项目更加清晰)
1.删除component中所有的文件,assets中文件,在main.js中删除import main.css样式
2.在App.vue中只保留<template><script>标签,其中内容一起删除
3.在template标签中不需要使用div包裹,直接使用{{}}就能获取return里面的值
二.事件修饰符
1. 阻止默认事件: @click.prevent="test" 类似于 test(e){e.preventDefault()}
2.阻止冒泡事件: @click.stop="test" 类似于 test(e){e.stopPropagation()}
三.数组变化侦测
1.pop("test"):向数组中添加test,并且ui页面会自动更新
2.concat(["test"]):会向数组中添加test,但是ui不会自动更新,不在页面展示,但是可以让添加后是数组赋值到原来的数组中,就可以在页面展示 this.names=this.names.concat(["test"])
四.Flowable部署所遇到的问题
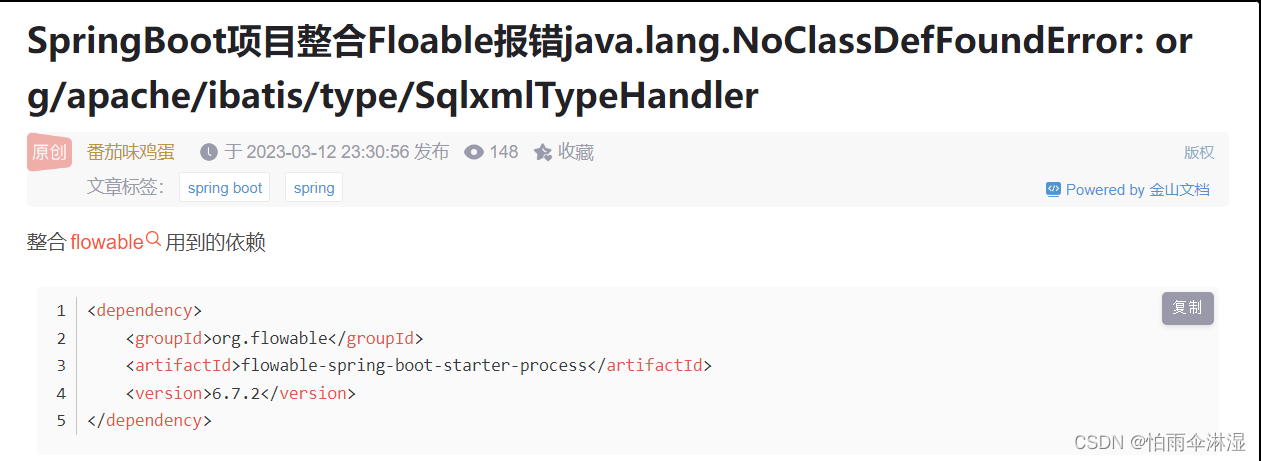
1.SpringBoot与Flowable版本问题
java.lang.NoClassDefFoundError: liquibase/Scope$ScopedRunner
2.mybatis冲突问题
3.连接不上虚拟机
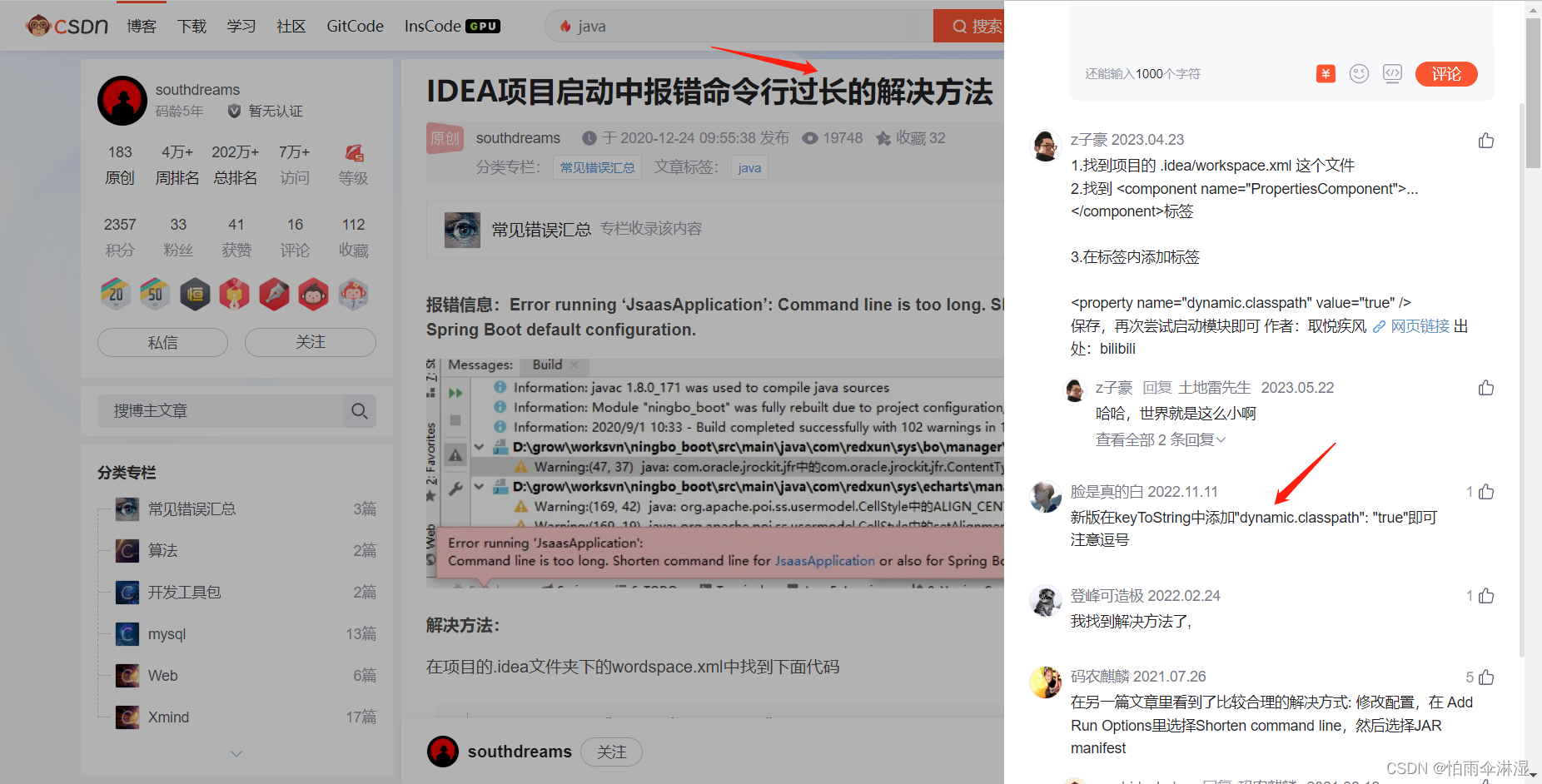
4.idea打印太长
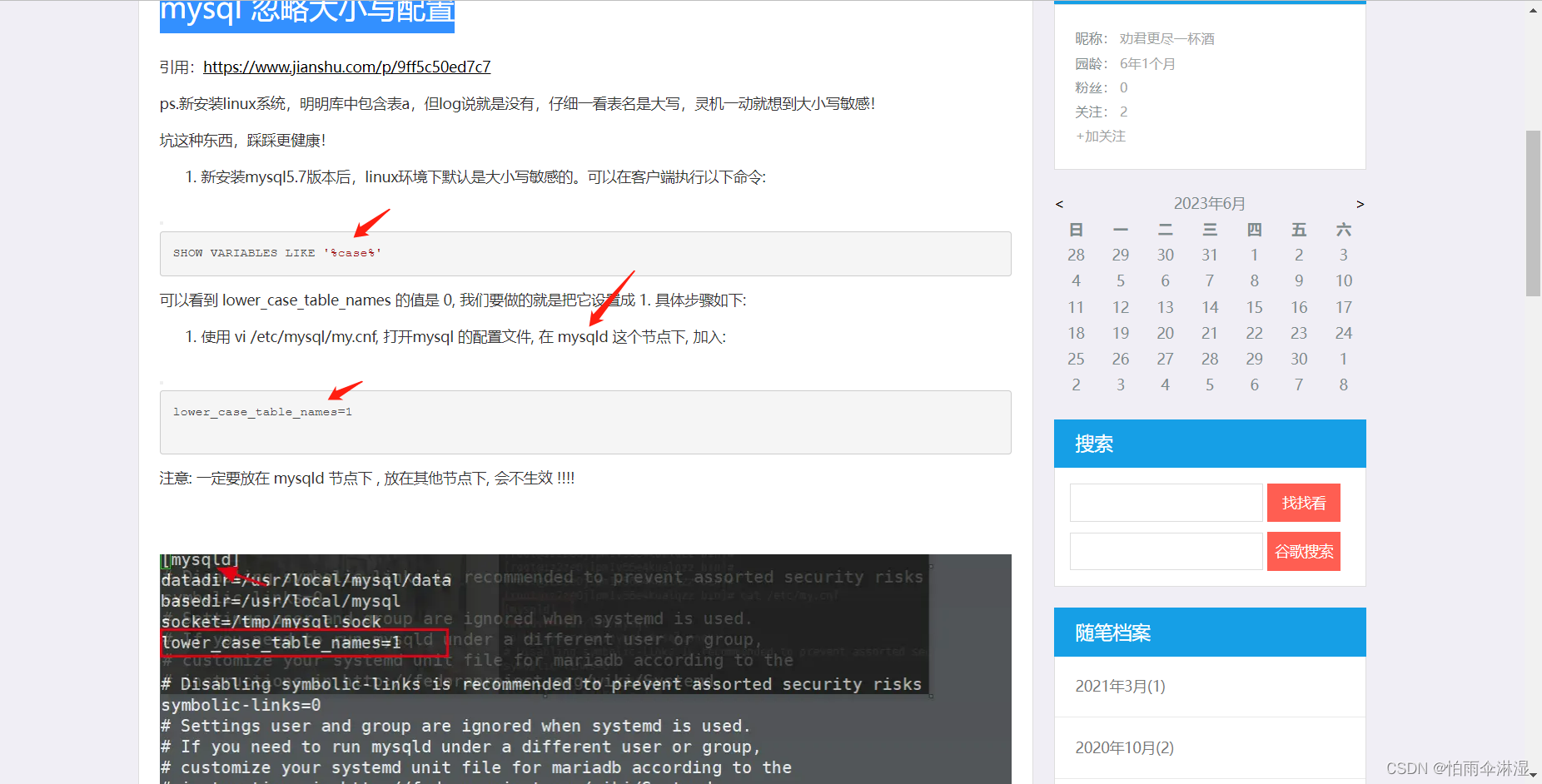
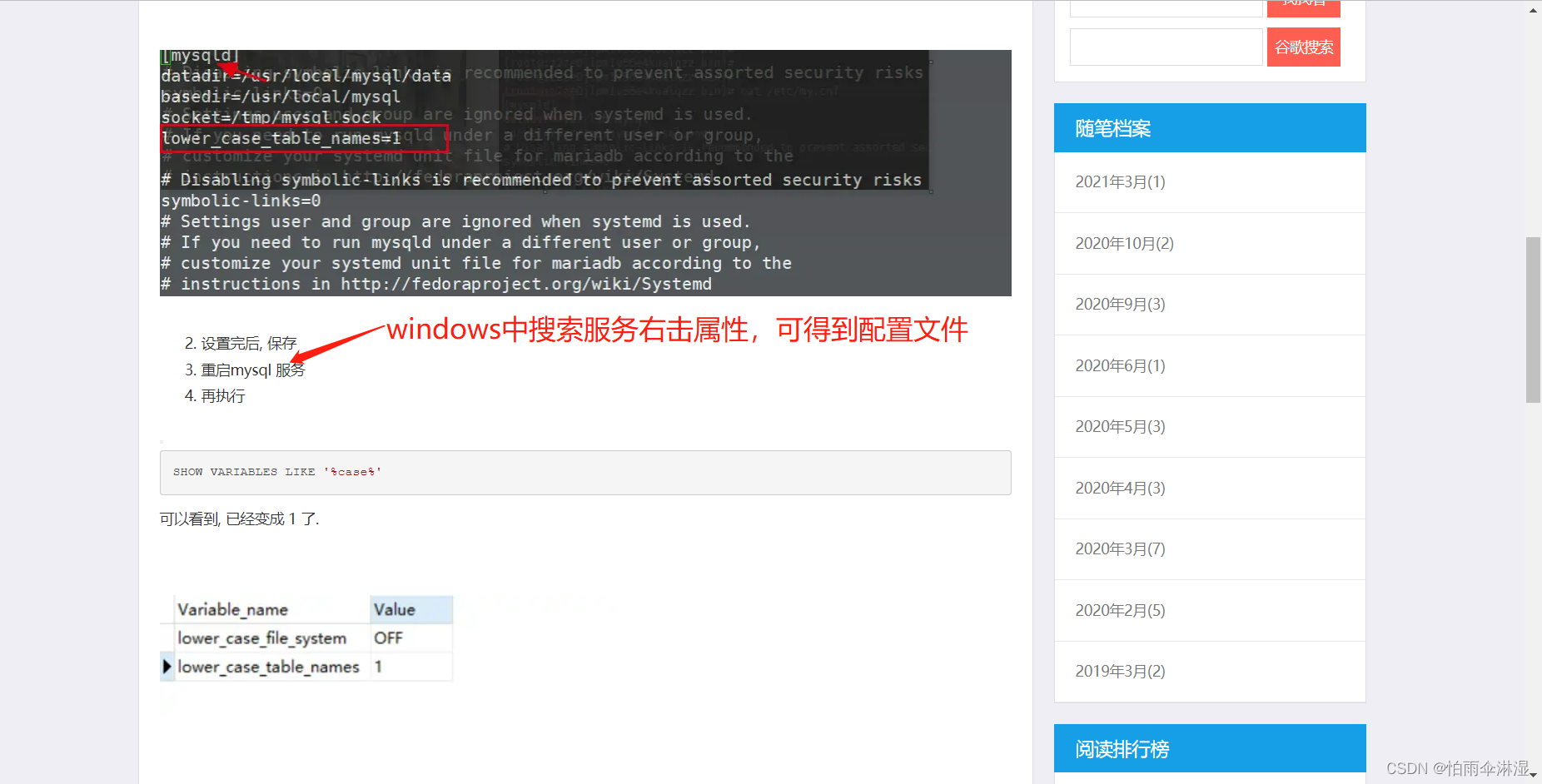
6.mysql忽略大小写问题




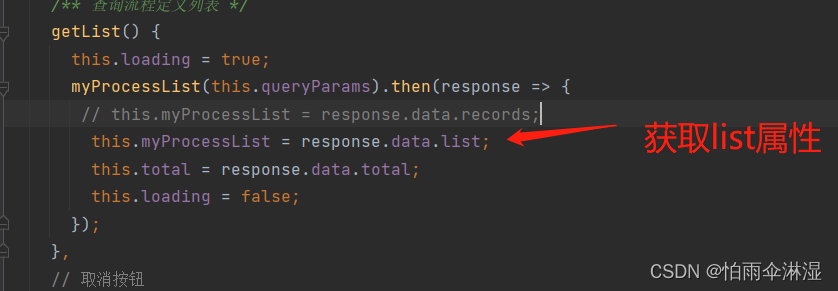
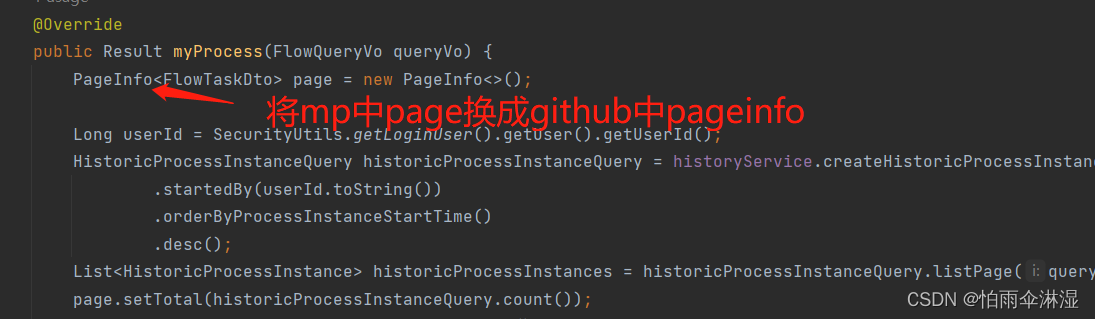
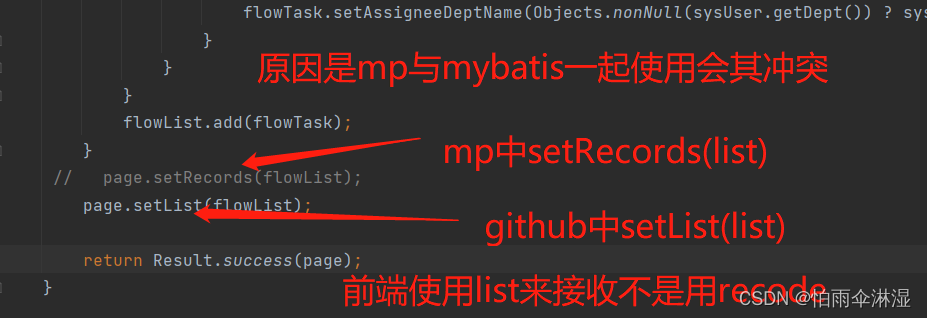
四.mybatis与mybatis-plus冲突解决分页问题
采用GitHub提供的pageInfo来代替,最小的降低代码的修改
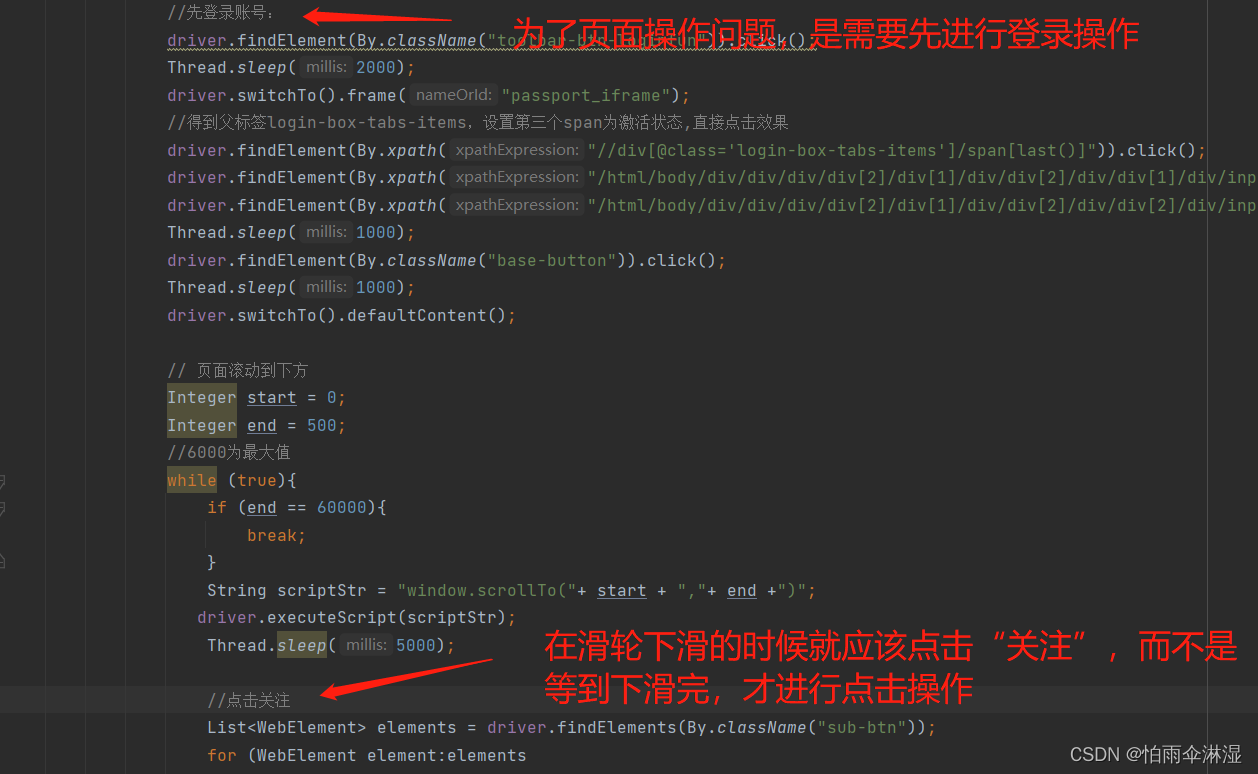
五,selenium中不能获取文本值

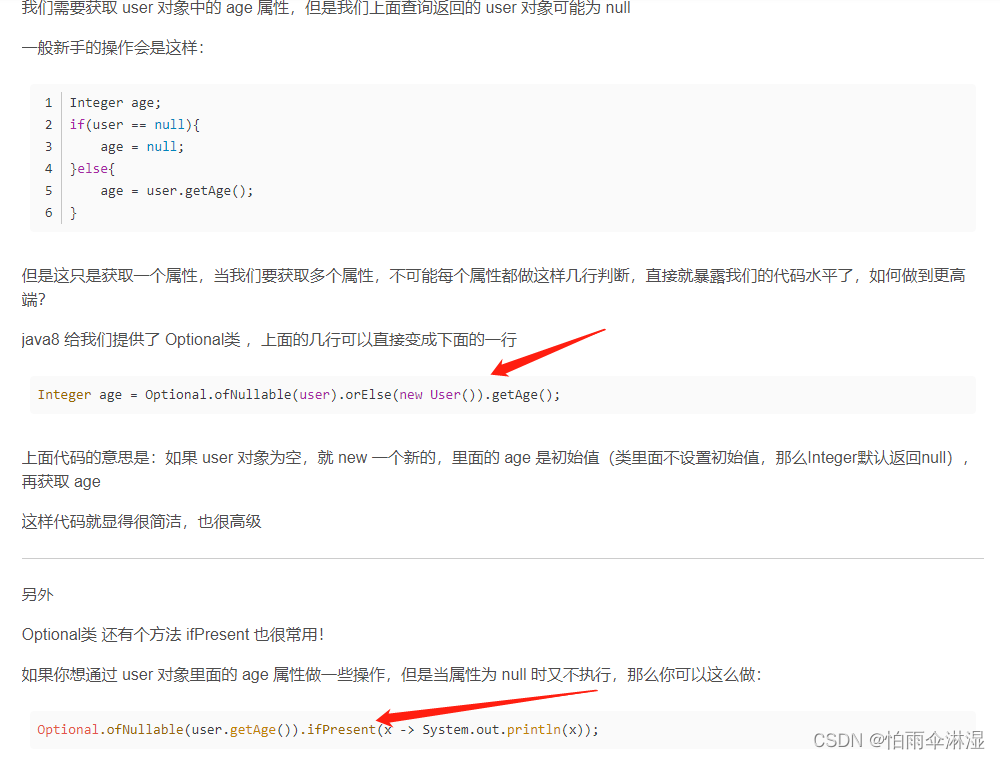
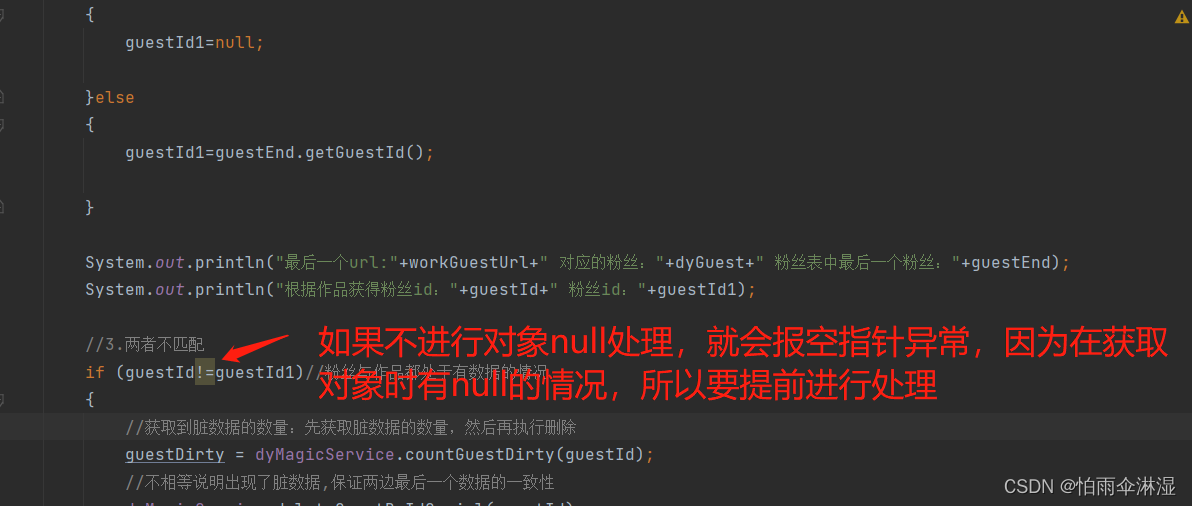
六。在Java中获取对象时可以存在空指针的情况,但这个只是初始化情况才会出现这种情况,解决这个问题可以使用Optional


七.面对MySQL数据库含有大量数据该如何处理?
1.对业务需要处理数据库中所有的数据,尽量通过一次JDBC连接(很消耗系统资源),放到JVM中,然后进行其它的业务操作。但是出现的问题:容易导致oom(内存溢出)+查询速度慢+垃圾回收时间长
2.有关数据库存储优化?
假设要在数据库中保存相关的数据:原则上将不在同一个表做过多的字段处理,需要将所需要保存的字段,进行分开处理,然后通过关联表的形式整合多个表,获取业务需求的字段;
3.MySQL语句优化?
采用最左前缀原则
在每一次的查询中应该都设计保证主键存在,不管该主键是否有用,都应该出现在select中
除了主键外,对经常作为多表之间连接可以设置外键或者索引
4.数据库中含有大量的数据需要处理?
如果只是简单数据展示,可以使用分页的操作,按需进行展示:比如一个页面展示10,20数据。
如果是要对大量数据进行分析后,然后再进行展示,采用多线程
场景:
方式:


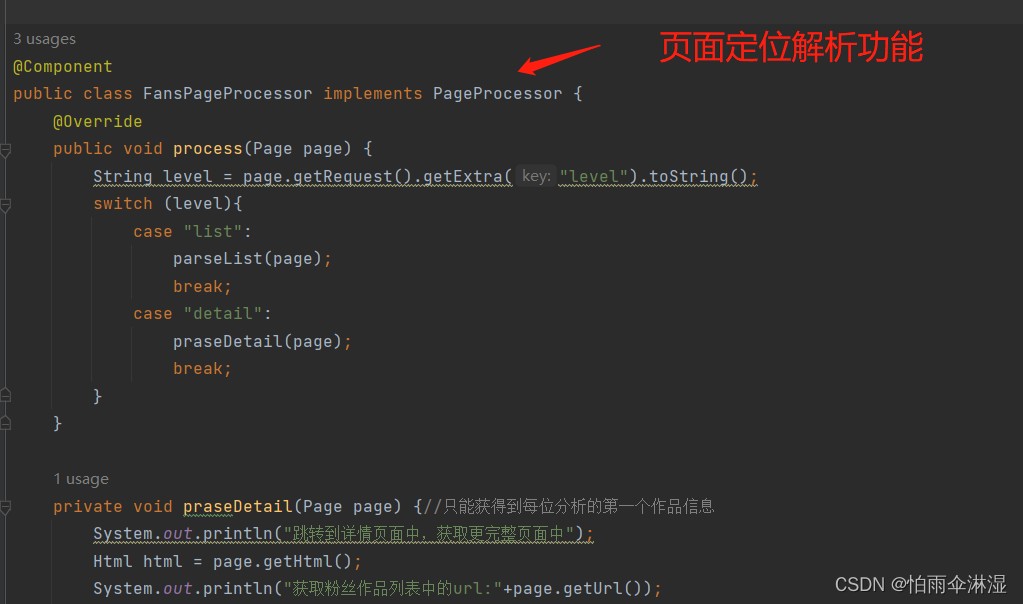
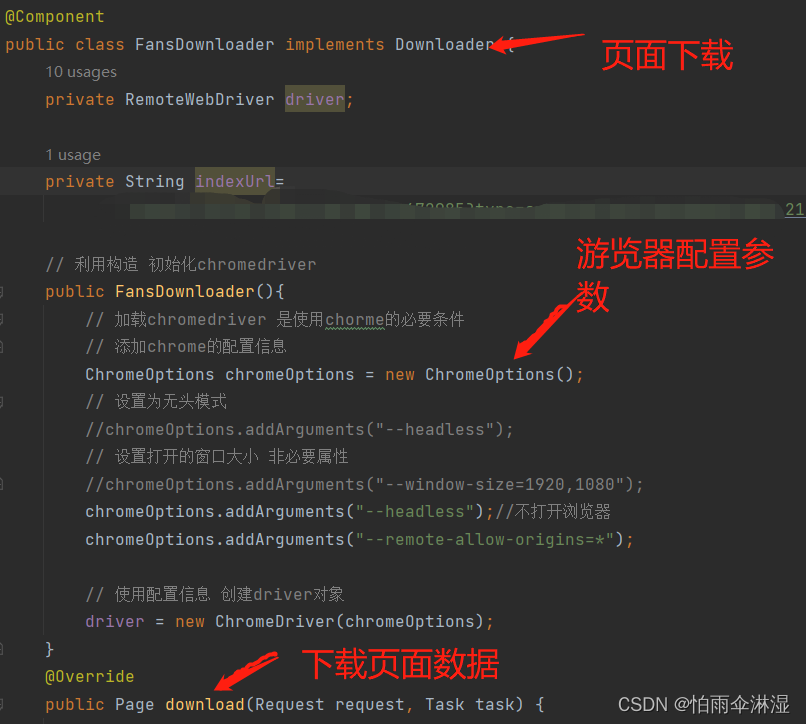
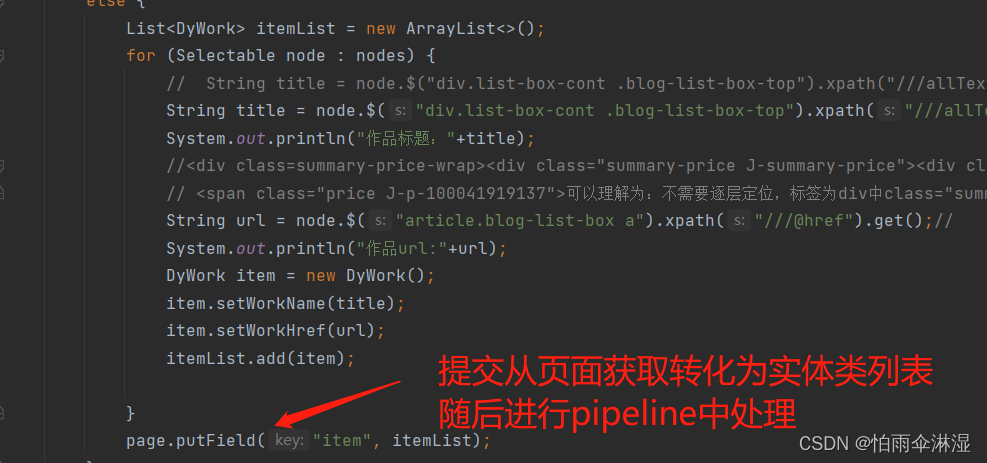
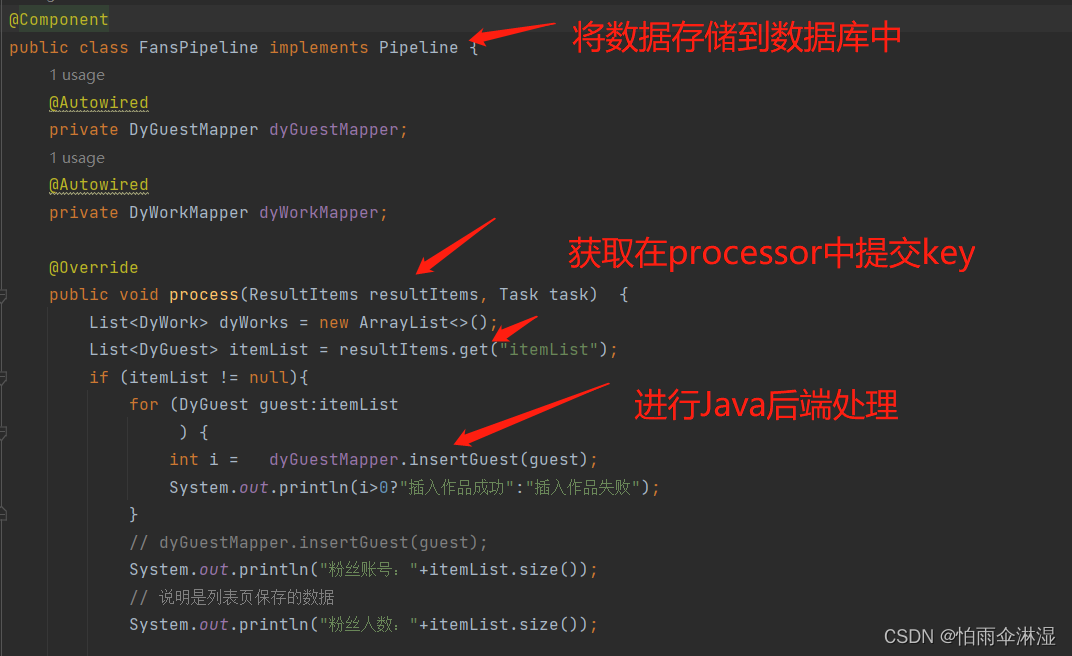
八.网页进行爬虫流程顺序:
download -> pageprocessor->pipeline
->:page作为第一阶段传递
->:page.putField作为第二阶段的传递
spider作为一个管理者,将download,pageprocessor ,pipeline三者整合在一起,然后确定了一个webmagic爬虫正式运行启动

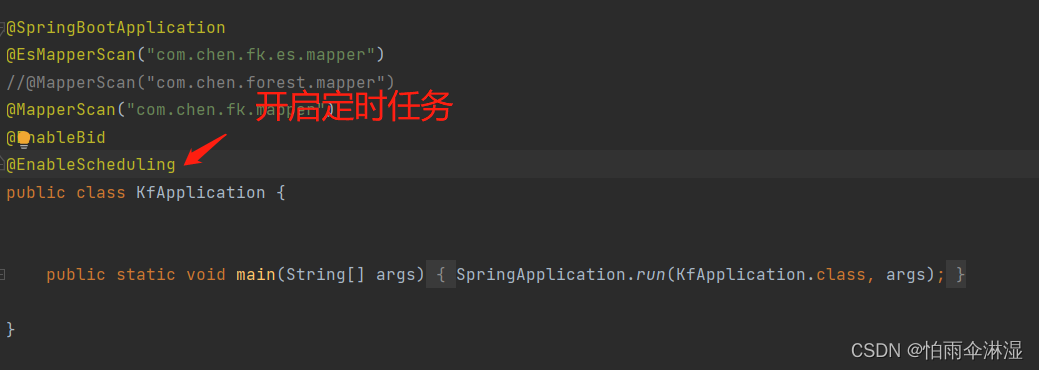
九.使用spring中自带的scheduler定时任务

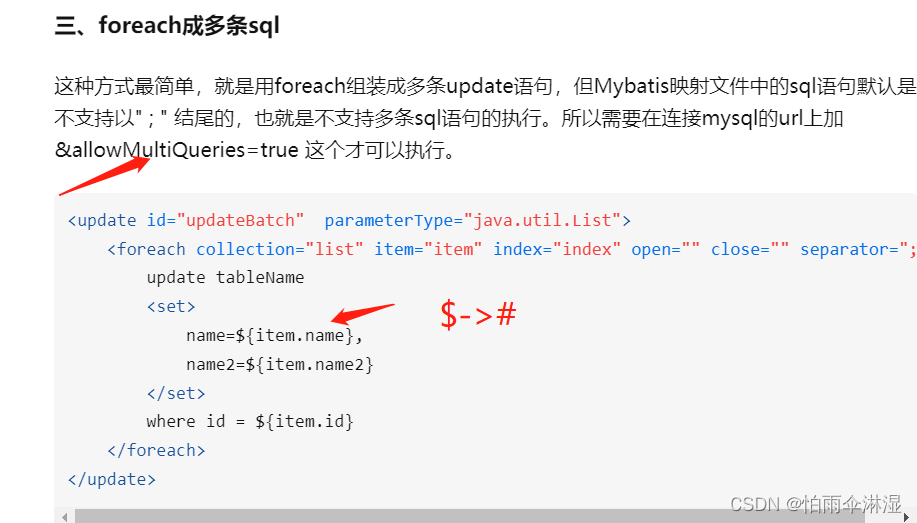
十.Mybatis中批量更新情况
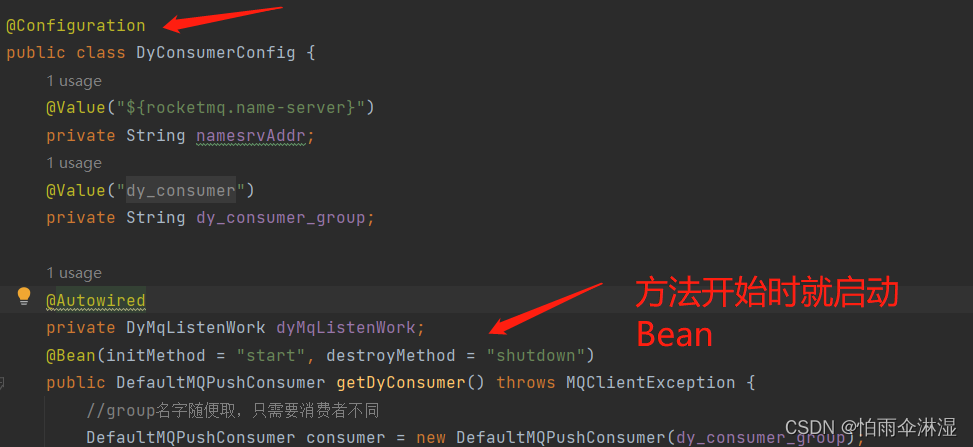
十一.RocketMq的操作使用
集合传递
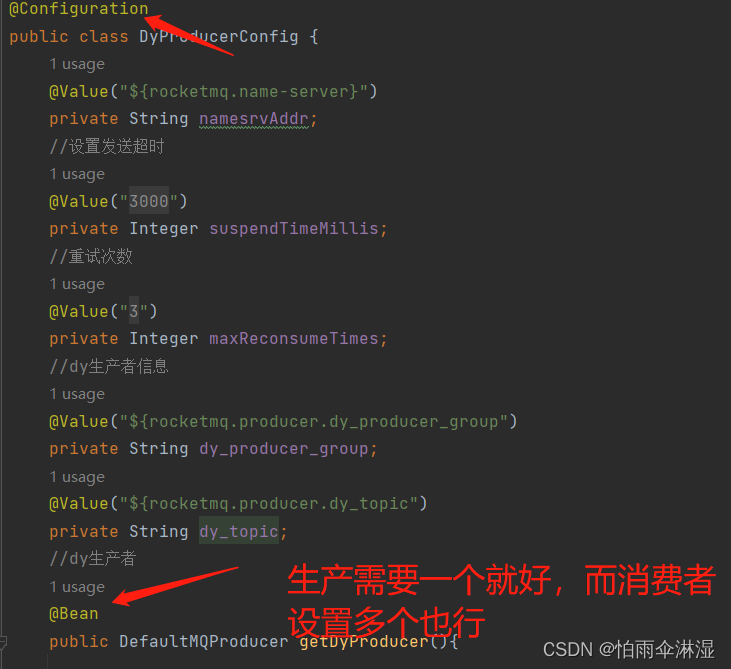
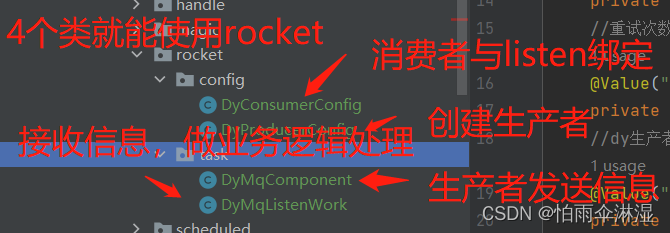


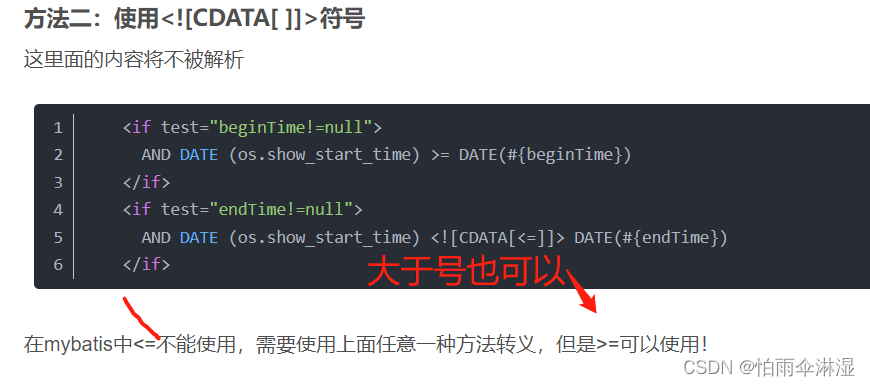
十二.数据库

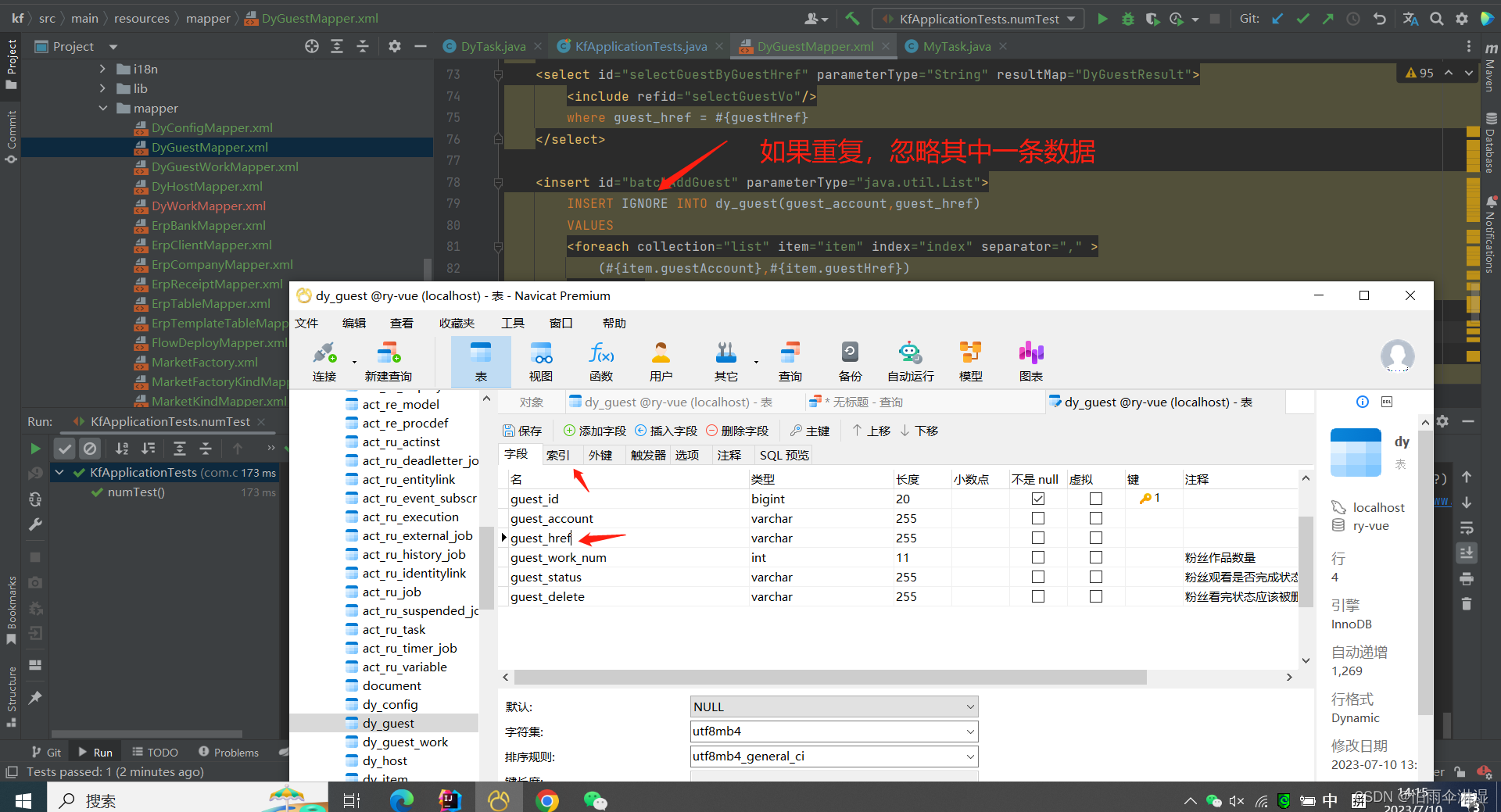
十三.批量增加用户,忽略重复数据
十四.selenium中明明是根据xpath,但是一直获取不到,这是因为没有设置线程暂停
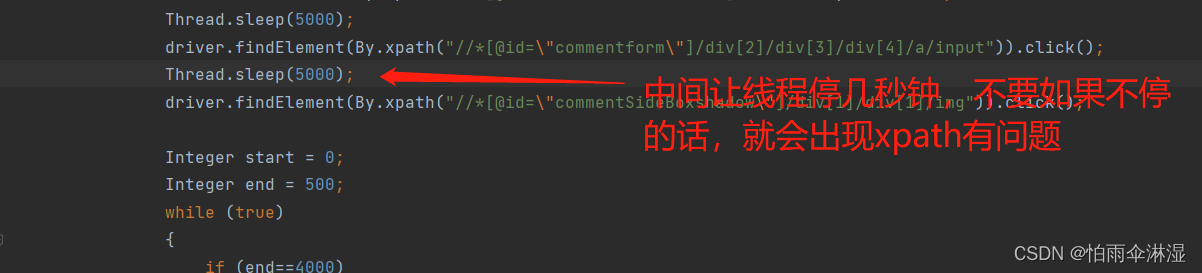
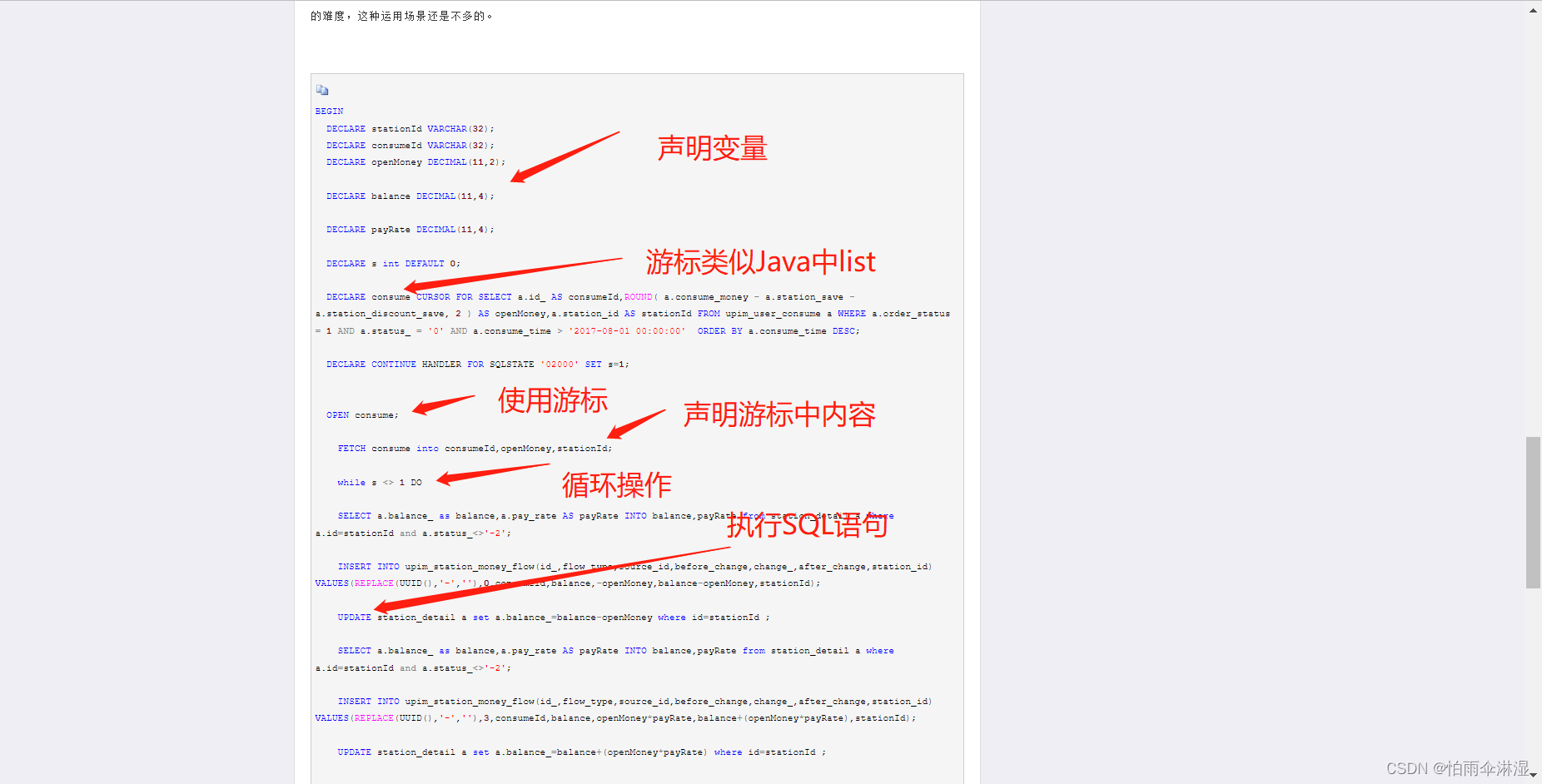
十五.MySQL中存储过程使用,确定好数据库,使用存储过程
https://www.cnblogs.com/daixinyu/p/7402146.html https://blog.csdn.net/weixin_45970271/article/details/124180709

十六.MySQL中limit注意的地方

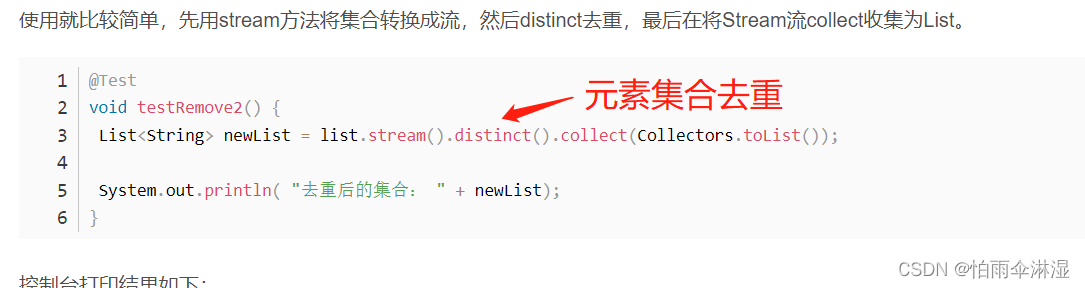
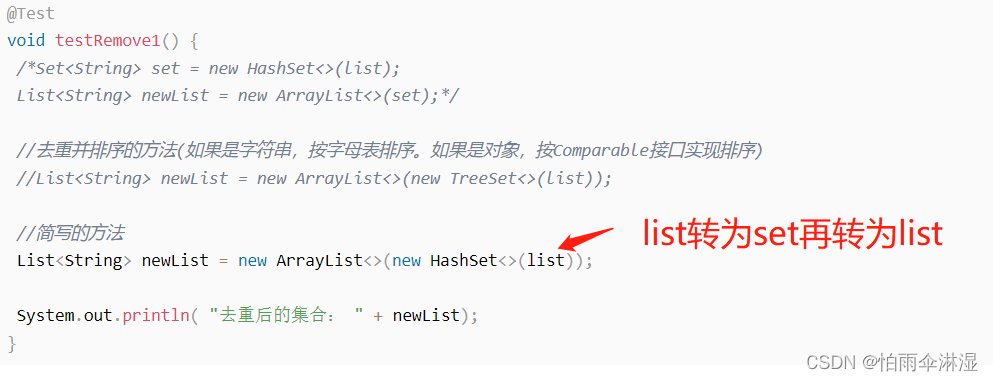
十七.list集合去重
1.元素集合去重
2.对象集合去重
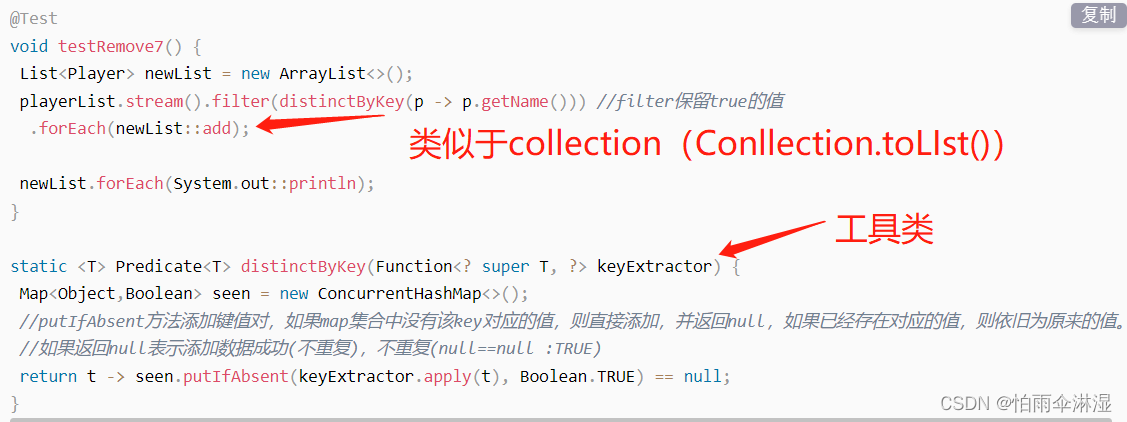
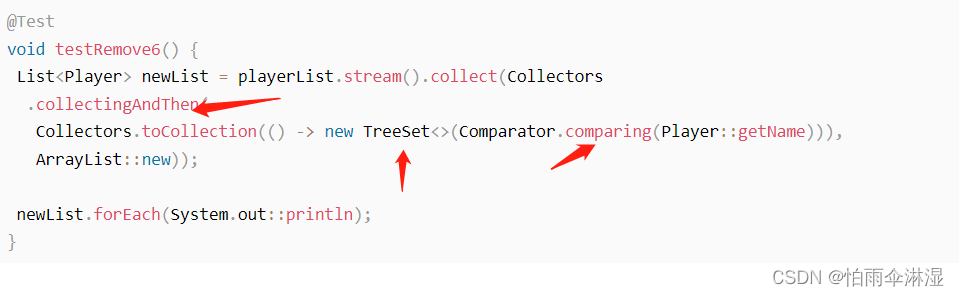
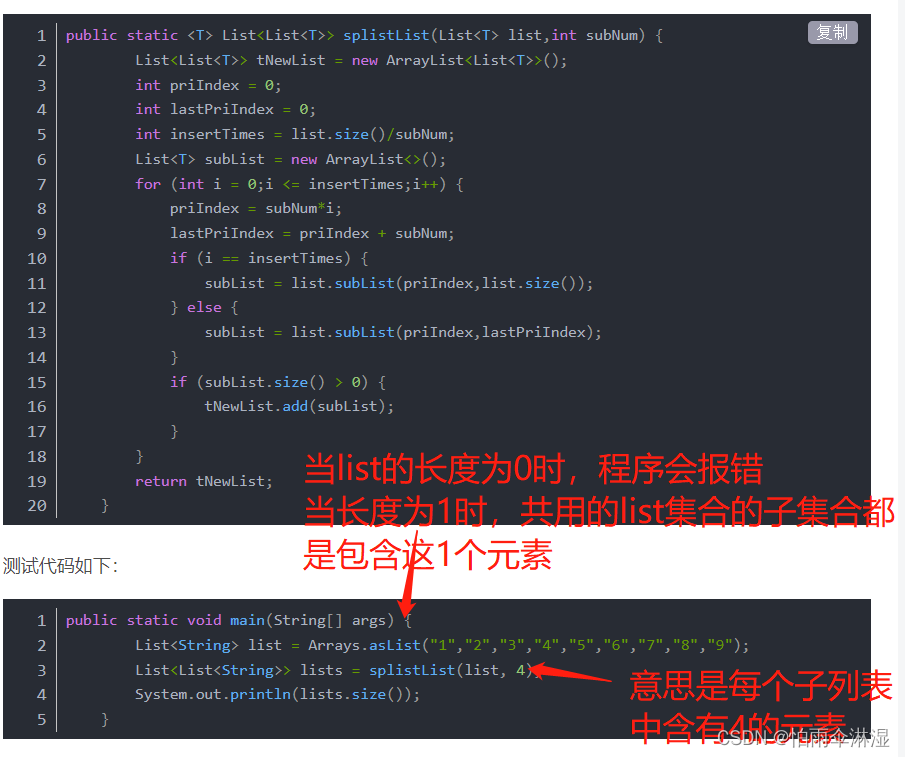
3.对list集合进行分割
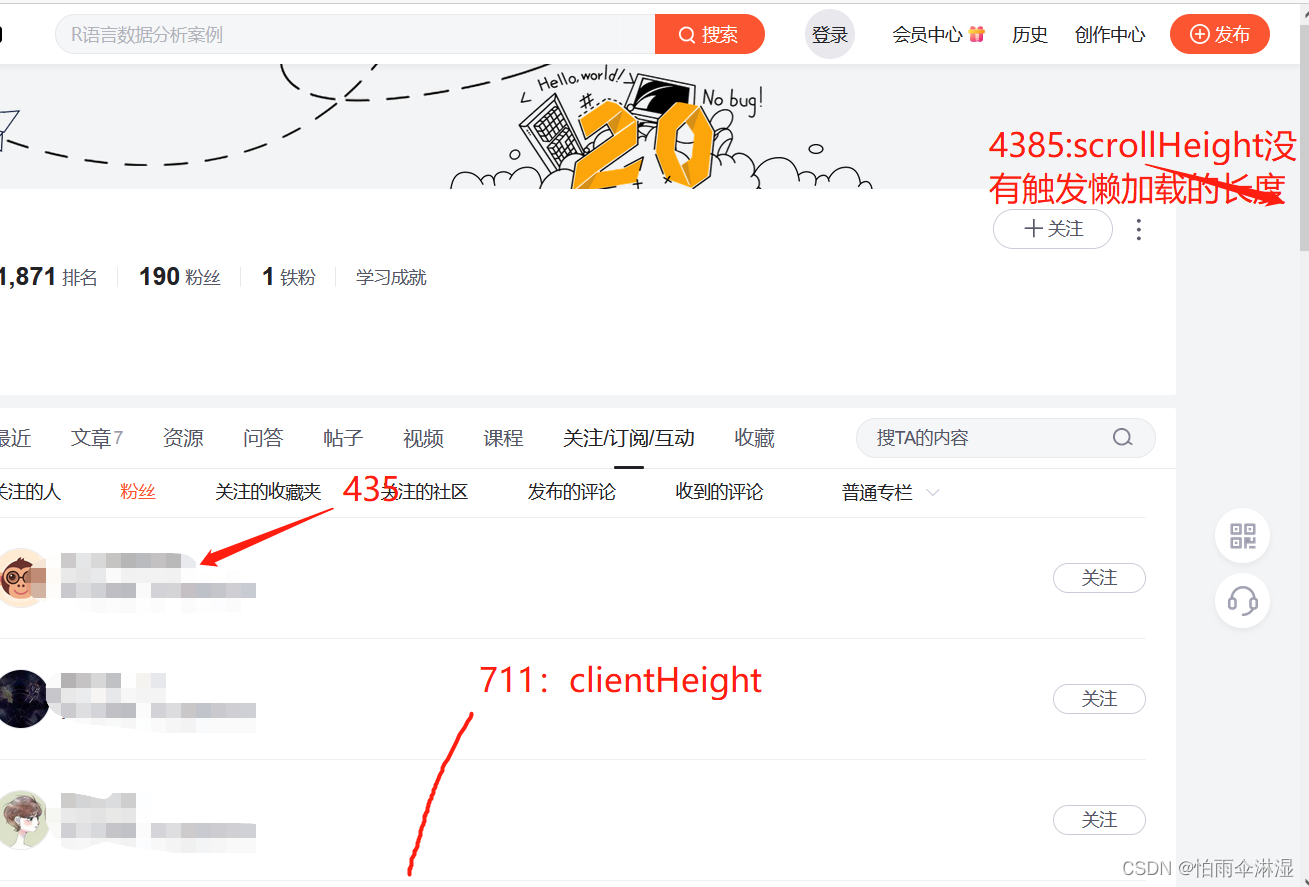
十八.有关解决爬虫下滑轮的问题
二十.list集合的操作
//遍历在for-each循环中使用entries来遍历 Map<Integer, Integer> map = new HashMap<Integer, Integer>(); for (Map.Entry<Integer, Integer> entry : map.entrySet()) { System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue()); } 方法二 在for-each循环中遍历keys或values。 Map<Integer, Integer> map = new HashMap<Integer, Integer>(); //遍历map中的键 for (Integer key : map.keySet()) { System.out.println("Key = " + key); } //遍历map中的值 for (Integer value : map.values()) { System.out.println("Value = " + value); } 方法三使用Iterator遍历 Map<Integer, Integer> map = new HashMap<Integer, Integer>(); Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator(); while (entries.hasNext()) { Map.Entry<Integer, Integer> entry = entries.next(); System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue()); } 二.list流功能 1.Java8中Stream的groupingBy分组器 /** * 使用java8 stream groupingBy操作,按城市分组list */ @Test public void groupingByTest() { Map<String, List<Employee>> employeesByCity = employees.stream().collect(Collectors.groupingBy(Employee::getCity)); System.out.println(employeesByCity); assertEquals(employeesByCity.get("London").size(), 2); } 2. /** * 使用java8 stream groupingBy操作,按城市分组list统计count */ @Test public void groupingByCountTest() { Map<String, Long> employeesByCity = employees.stream().collect(Collectors.groupingBy(Employee::getCity, Collectors.counting())); System.out.println(employeesByCity); assertEquals(employeesByCity.get("London").longValue(), 2L); } /** * 使用java8 stream groupingBy操作,按城市分组list并计算分组销售平均值 */ @Test public void groupingByAverageTest() { Map<String, Double> employeesByCity = employees.stream().collect(Collectors.groupingBy(Employee::getCity, Collectors.averagingInt(Employee::getSales))); System.out.println(employeesByCity); assertEquals(employeesByCity.get("London").intValue(), 175); } /** * 使用java8 stream groupingBy操作,按城市分组list并计算分组销售总值 */ @Test public void groupingBySumTest() { Map<String, Long> employeesByCity = employees.stream().collect(Collectors.groupingBy(Employee::getCity, Collectors.summingLong(Employee::getSales))); //对Map按照分组销售总值逆序排序 Map<String, Long> finalMap = new LinkedHashMap<>(); employeesByCity.entrySet().stream() .sorted(Map.Entry.<String, Long>comparingByValue() .reversed()).forEachOrdered(e -> finalMap.put(e.getKey(), e.getValue())); System.out.println(finalMap); assertEquals(finalMap.get("London").longValue(), 350); } //三.list将流合并 List<ClaimDerive> resultList = Stream.of(sumClaimList, sumPayList, sumRepurchList) .flatMap(Collection::stream) .collect(Collectors.groupingBy(ClaimDerive::getMachineNo)) .values() .stream() .map(claimDeriveList -> { ClaimDerive resultClaimDerive = new ClaimDerive(); resultClaimDerive.setMachineNo(claimDeriveList.get(0).getMachineNo()); claimDeriveList.forEach(resultClaimDerive::merge); return resultClaimDerive; }) .collect(Collectors.toList());https://blog.csdn.net/tjcyjd/article/details/11111401:map的遍历
https://blog.csdn.net/weixin_41835612/article/details/83687088 :list分组
https://blog.csdn.net/qq_58846203/article/details/131331765:list流进行合并
以map的角度对list操作
public class ListCompareUtil { public static void main(String[] args) { List<String> list1 = new ArrayList<String>(); List<String> list2 = new ArrayList<String>(); for (int i = 0; i < 3000000; i++) { list1.add("test"+i); list2.add("test"+i*3); } mapCompare(list1,list2); } /** * 对比两个list取出差并和的集合 * @param oldList 旧集合 * @param newList 新集合 * @param flag 1,旧数据;2,重复的数据;3,新增的数据 * @return */ public static List<String> getCompareList(List<String> oldList, List<String> newList,Integer flag){ long st = System.nanoTime(); Map<String,Integer> map = mapCompare(oldList,newList); List<String> result ; List<String> oldData = Lists.newArrayList(); List<String> addData = Lists.newArrayList(); List<String> repeatData = Lists.newArrayList(); map.entrySet().forEach(stringIntegerEntry -> { if(stringIntegerEntry.getValue()==1) { oldData.add(stringIntegerEntry.getKey()); }else if(stringIntegerEntry.getValue()==2){ repeatData.add(stringIntegerEntry.getKey()); }else{ addData.add(stringIntegerEntry.getKey()); } }); if(flag.equals(1)){ result = oldData; }else if(flag.equals(2)){ result = repeatData; }else{ result = addData; } System.out.println("getCompareList "+(System.nanoTime()-st)); return result; } /** * 单独获取两个不用集合的数据,高效率 * @param list1 * @param list2 * @return */ public static List<String> getDiffrentList(List<String> list1, List<String> list2) { long st = System.nanoTime(); List<String> diff = Lists.newArrayList(); //优先使用数据量大的list,提高效率 List<String> maxList = list1; List<String> minList = list2; if(list2.size()>list1.size()) { maxList = list2; minList = list1; } Map<String,Integer> map = new HashMap<>(maxList.size()); for (String string : maxList) { map.put(string, 1); } for (String string : minList) { if(map.get(string)!=null) { map.put(string, 2); continue; } diff.add(string); } for(Map.Entry<String, Integer> entry:map.entrySet()) { if(entry.getValue()==1) { diff.add(entry.getKey()); } } System.out.println("getDiffrentList total times "+(System.nanoTime()-st)); return diff; } /** * 对比两个list,返回list并集 * @param oldList * @param newList * @return value为1,旧数据;2,重复的数据;3,新增的数据 */ public static Map<String,Integer> mapCompare(List<String> oldList, List<String> newList) { long st = System.nanoTime(); //若知道两个list大小区别较大,以大的list优先处理 Map<String,Integer> map = new HashMap<>(oldList.size()); //lambda for循环数据量越大,效率越高,小数据建议用普通for循环 oldList.forEach(s -> map.put(s, 1) ); newList.forEach(s -> { if(map.get(s)!=null) { //相同的数据 map.put(s, 2); }else { //若只是比较不同数据,不需要此步骤,浪费资源 map.put(s,3); } }); System.out.println("mapCompare total times "+(System.nanoTime()-st)); return map; }https://blog.csdn.net/wanzhix/article/details/85706852
2.map的使用操作
方式一: Map<Object,Object> valueMap = redisCache.getCacheObject(MyUtils.pp_key); if (EmptyUtils.isEmpty(valueMap)) valueMap=MyUtils.getKeys().stream().collect(Collectors.toMap(BhVo::getBhName, BhVo::getBhValue,(u1,u2)->u1+","+u2)); 方式二 Map<String,String> valueMap = redisCache.getCacheMap(MyUtils.pp_key); if (valueMap.isEmpty()) valueMap.put(vo.getBhName(),value);
二十.MySQL编程语言的表达与书写
1.group by 使用

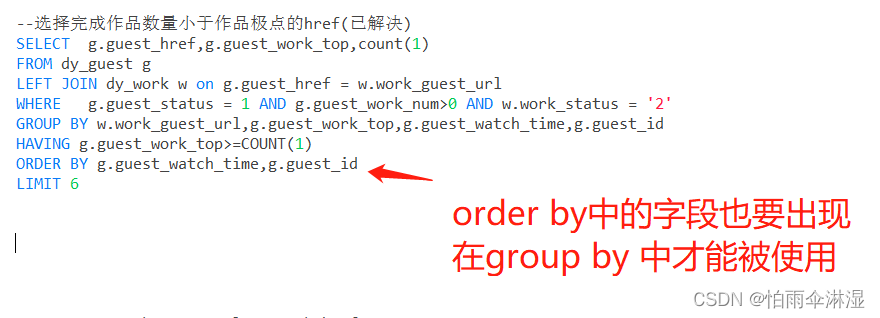
二十二.Mybatis部分
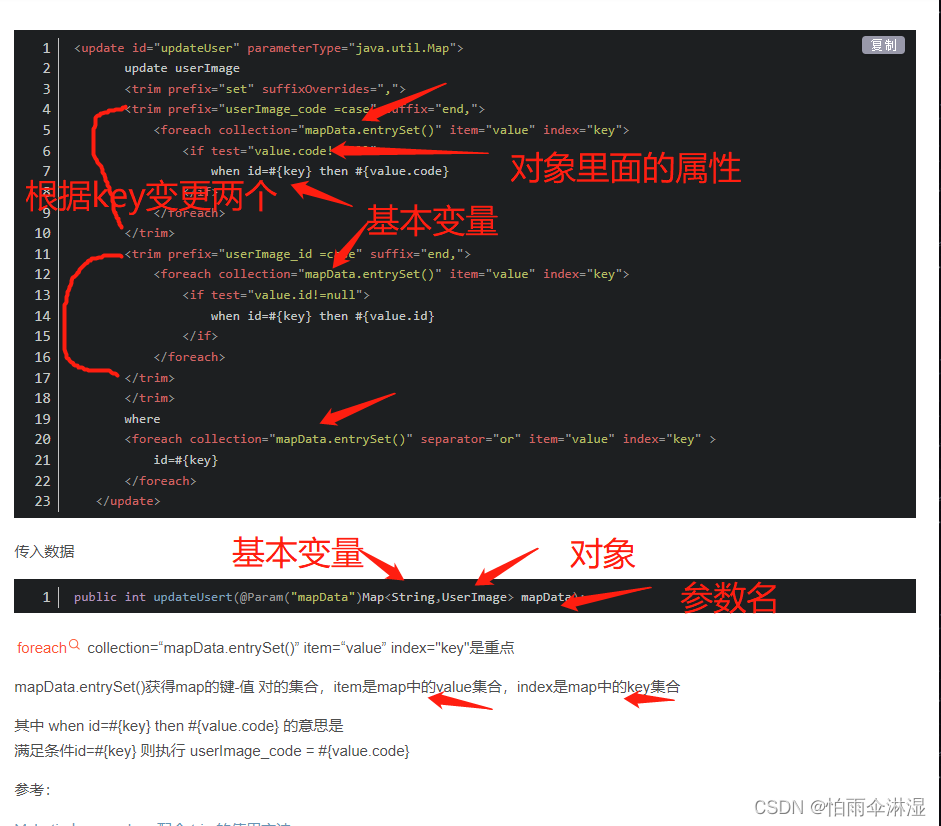
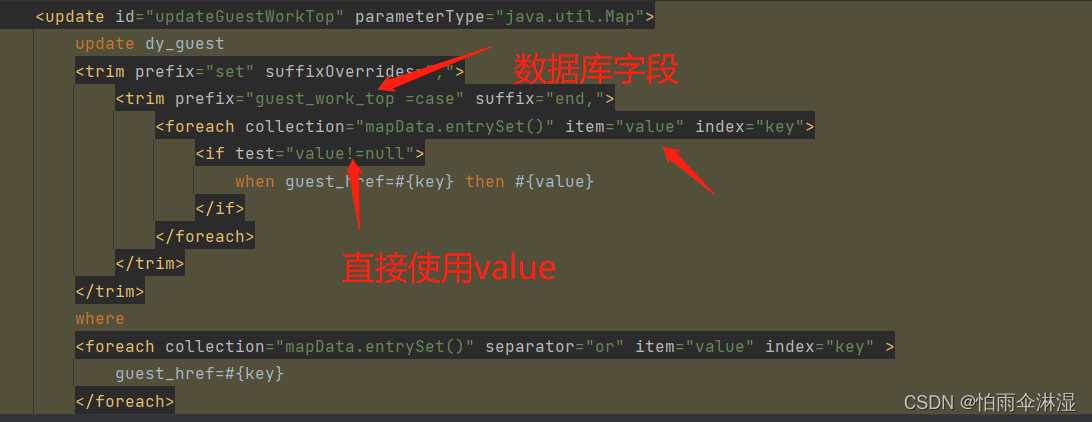
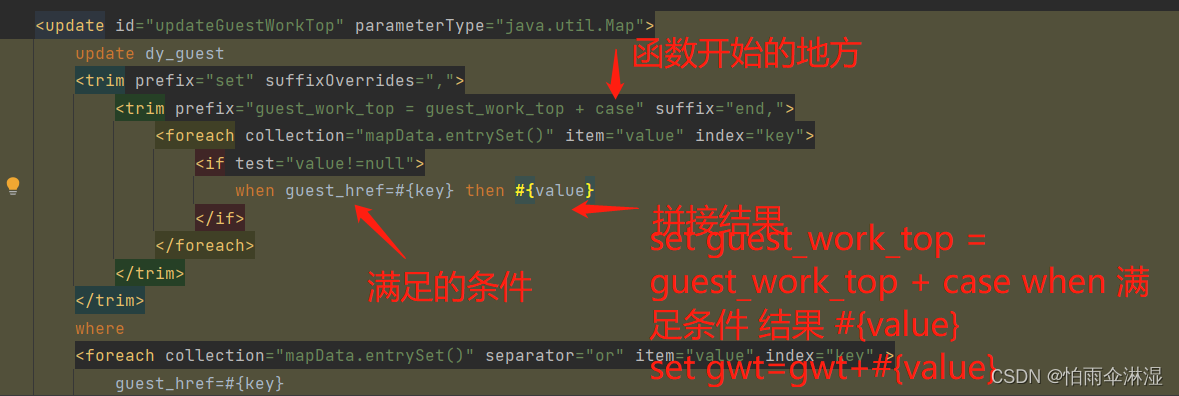
1.map批量更新数据
2.key是基本类型,valu是基本类型
3.map插入数据
(140条消息) Mybatis之foreach遍历Map实现_mybatis foreach map_不放糖的苦咖啡的博客-CSDN博客
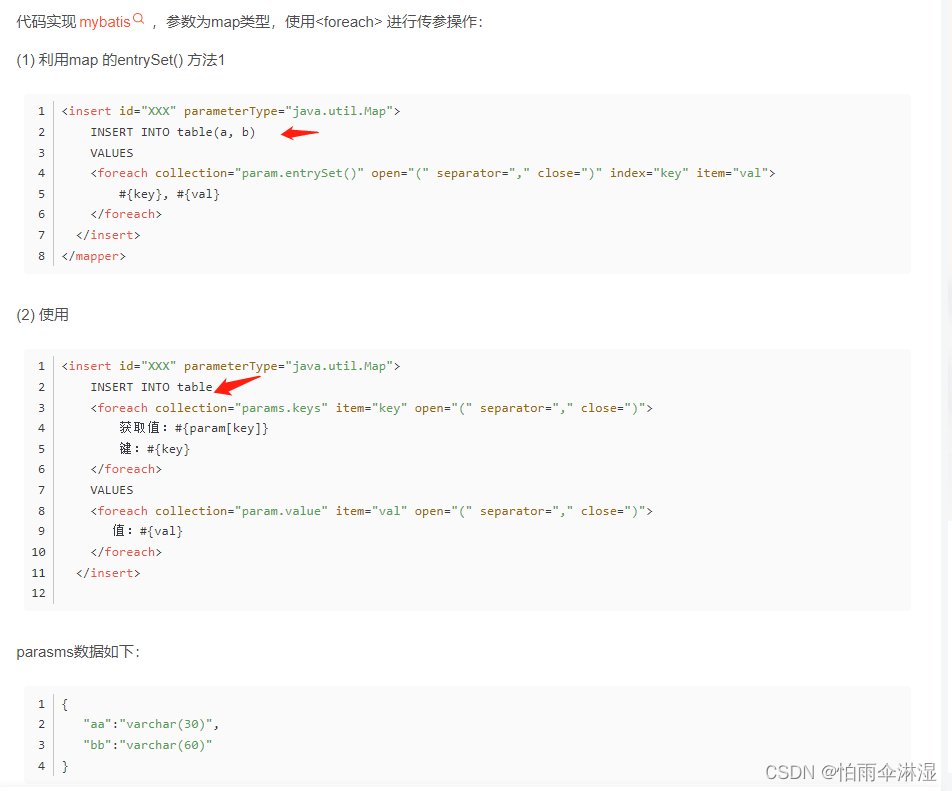
二十三.系统优化的模块
1.
2.MySQL中采用类型varchar(20)和varchar(255)对性能上的影响
总结:字段长度要与实际情况为主,原则上使用较小的字段,能提高相对的性能
https://blog.csdn.net/u010365717/article/details/98496767?ydreferer=aHR0cHM6Ly9jbi5iaW5nLmNvbS8%3D
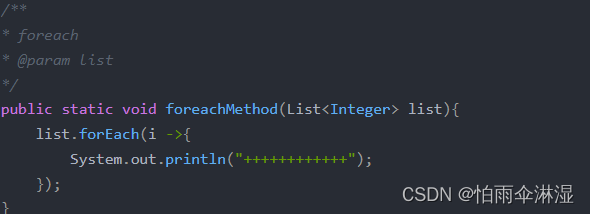
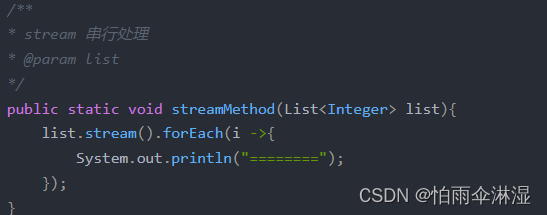
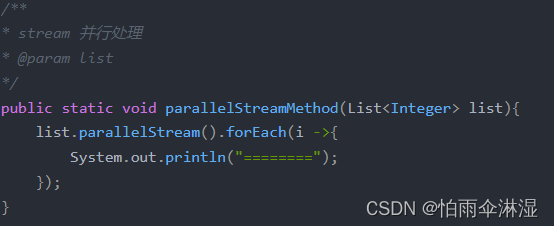
3.对于需要将大量的数据存储在list中,可以先经过数据清洗,然后将分批存储,在分批中对list进行长度的设置
4.list数据循环速度比较
(2)不同数据的情况下循环使用








二十四.
@FunctionalInterface方法接口的使用
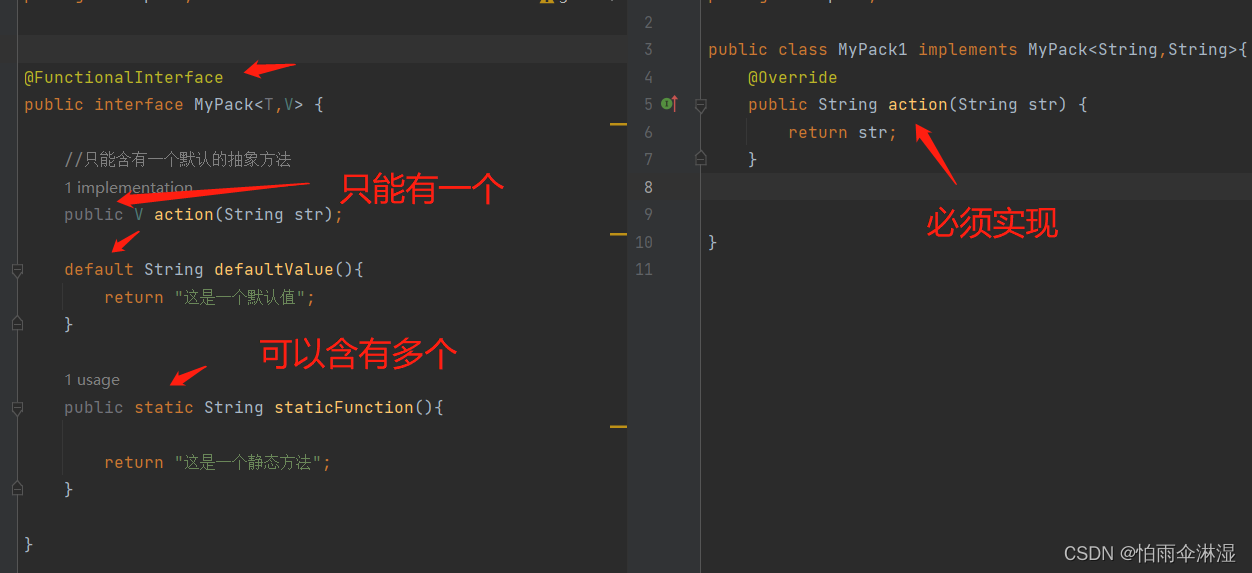
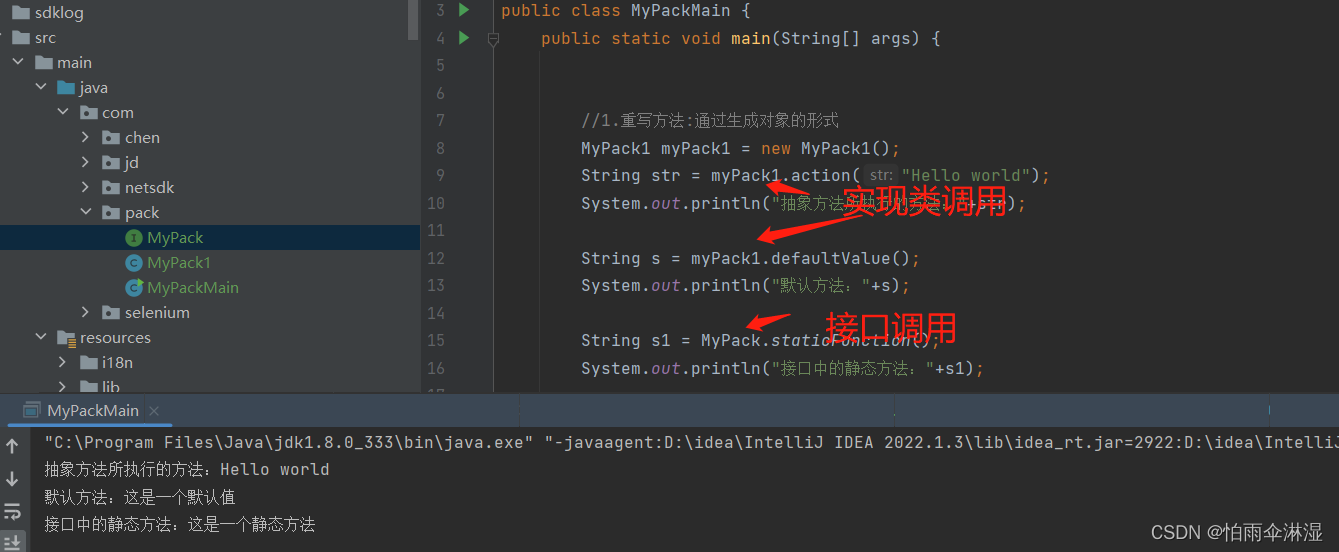
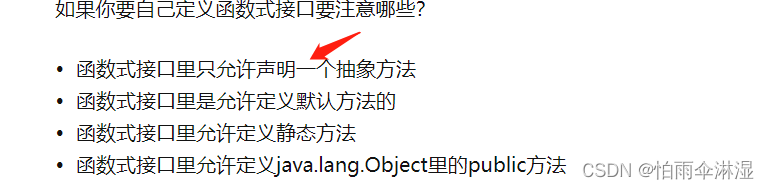

二十五.多线程问题集
1.会遇到问题:同步:就是多个线程在使用同一个变量会出现的问题
2.解决同步的问题:阻塞同步与非阻塞同步两个方式,显然非阻塞方式优于阻塞同步方式
解决了线程的阻塞与唤醒的操作
3.重试机制的原理:CAS(比较和交换机制)
4.使用
5. volatile使用
https://blog.csdn.net/fanrenxiang/article/details/80623884
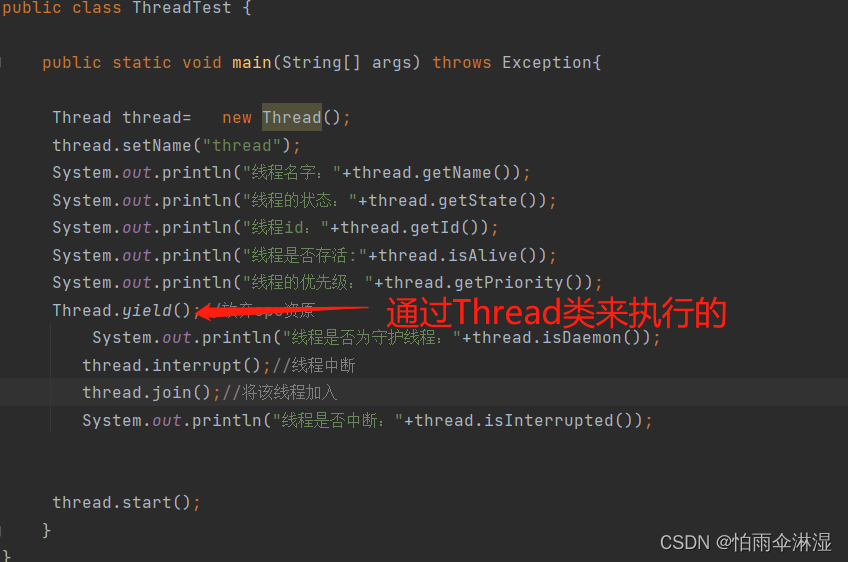
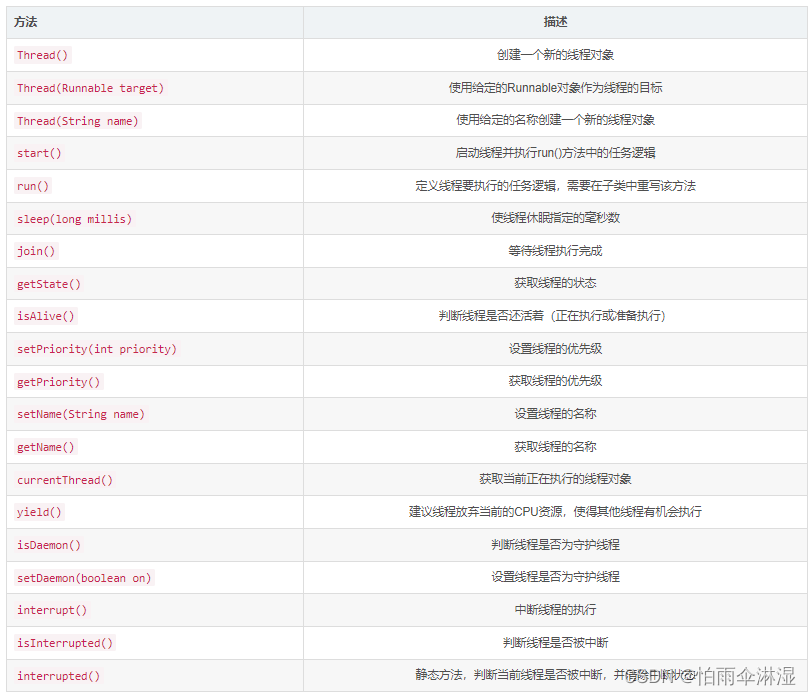
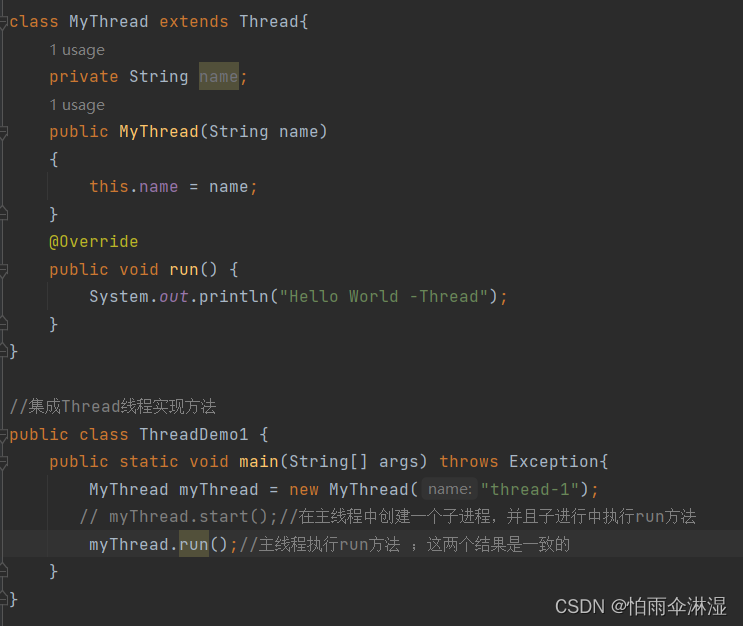
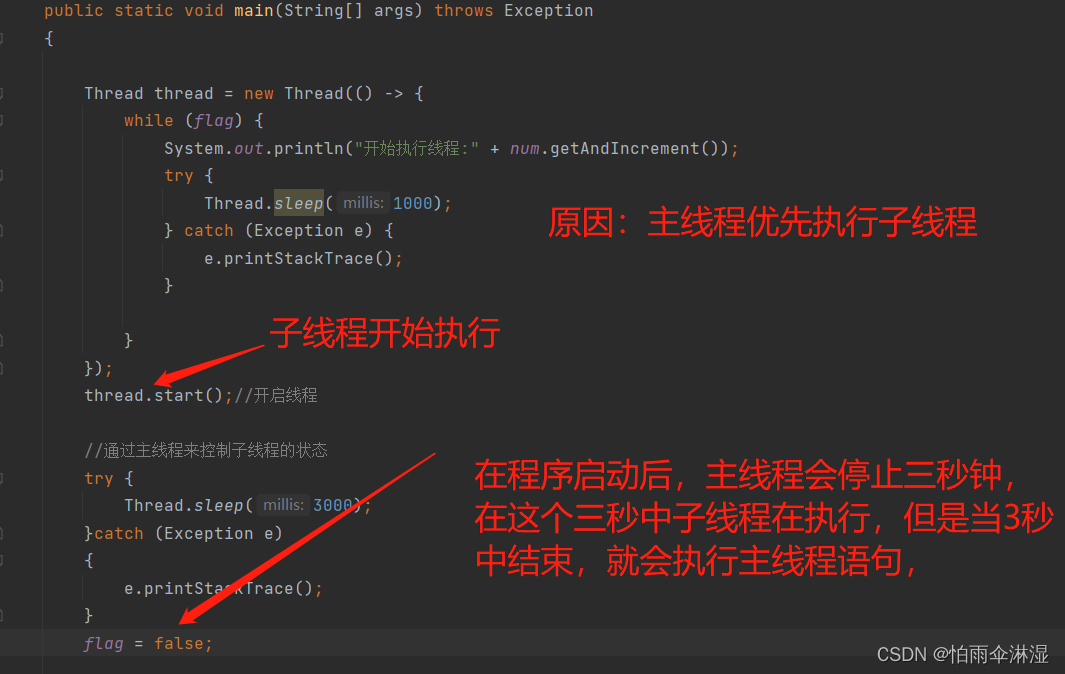
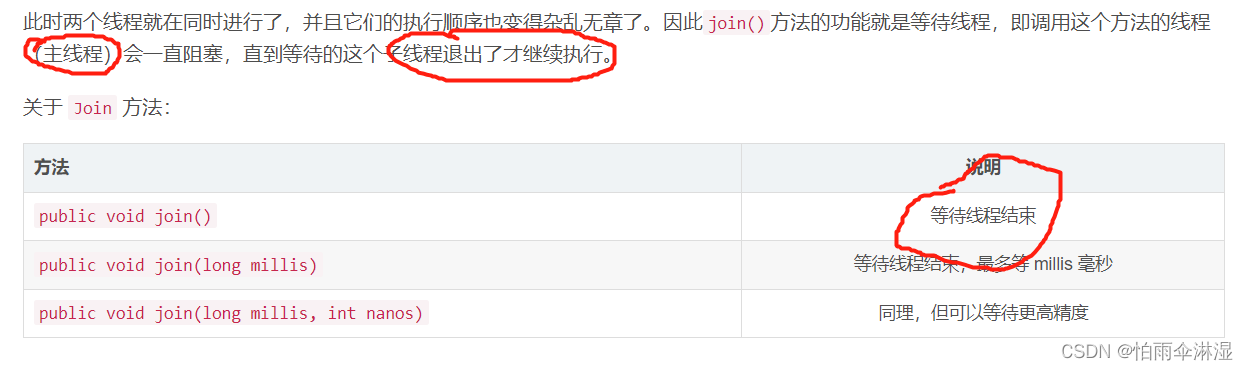
7.线程方法的使用
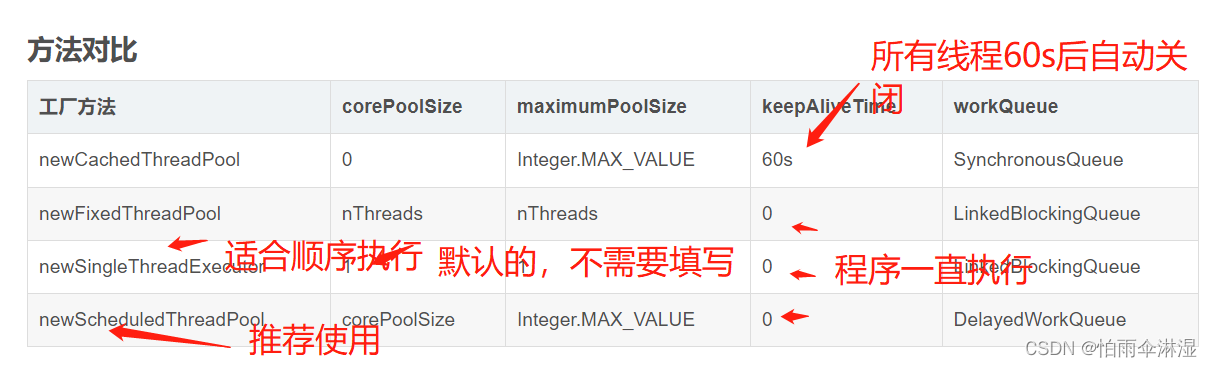
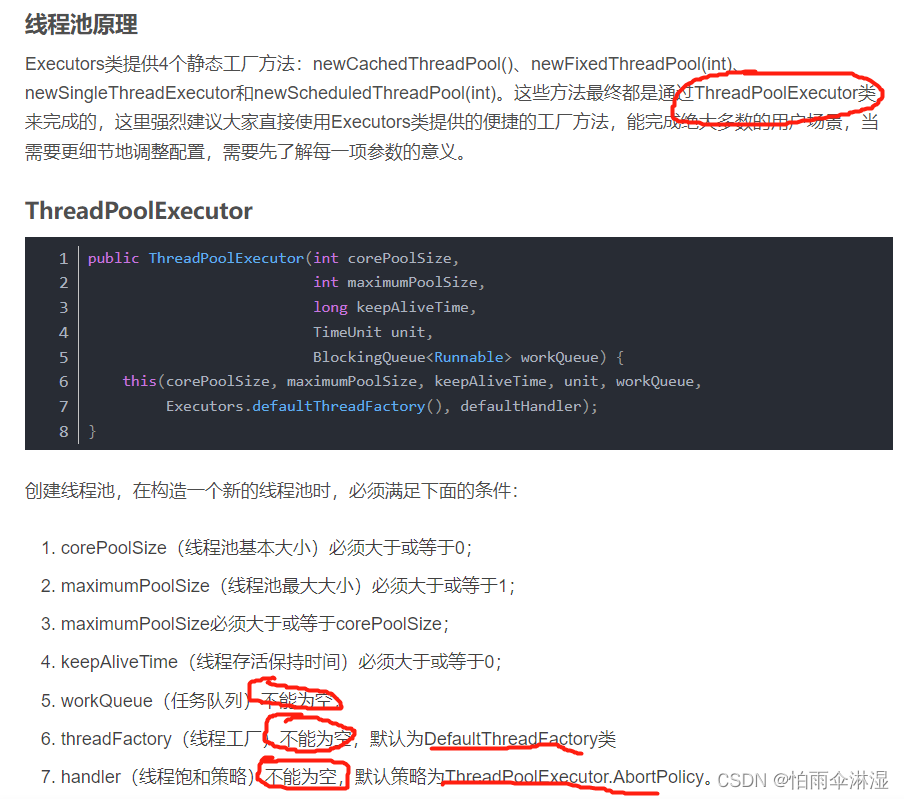
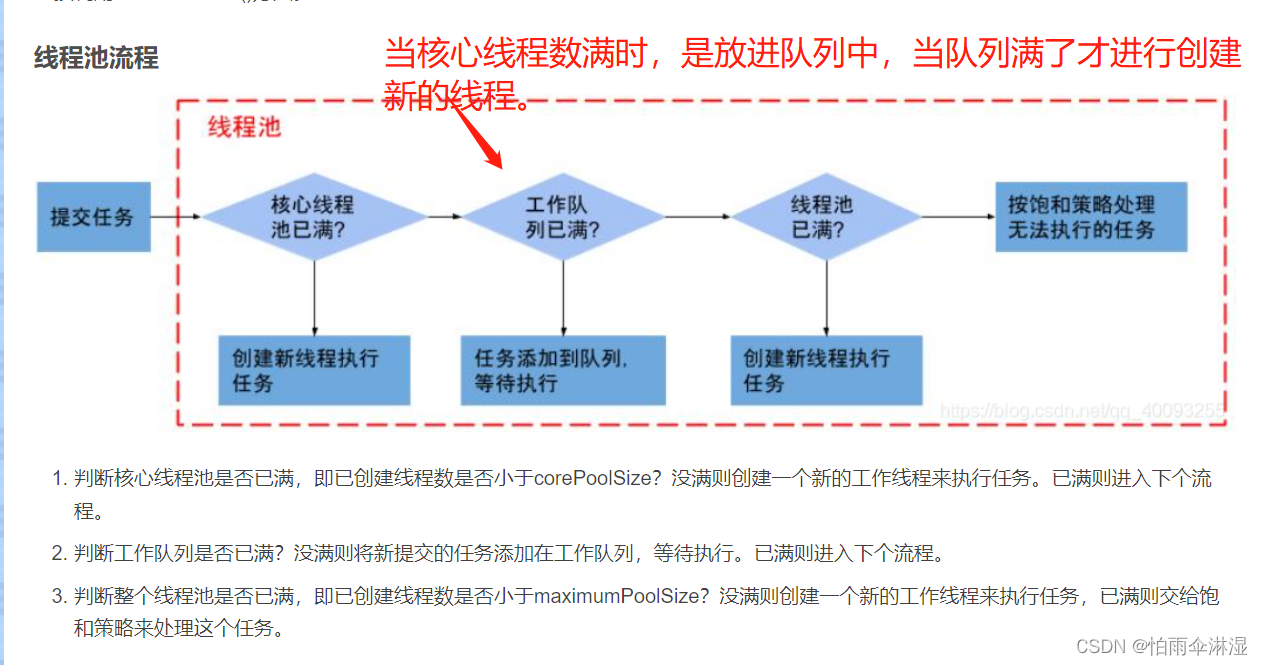
8.线程池的使用:使用Executors进行创建四中线程池类型
9.线程
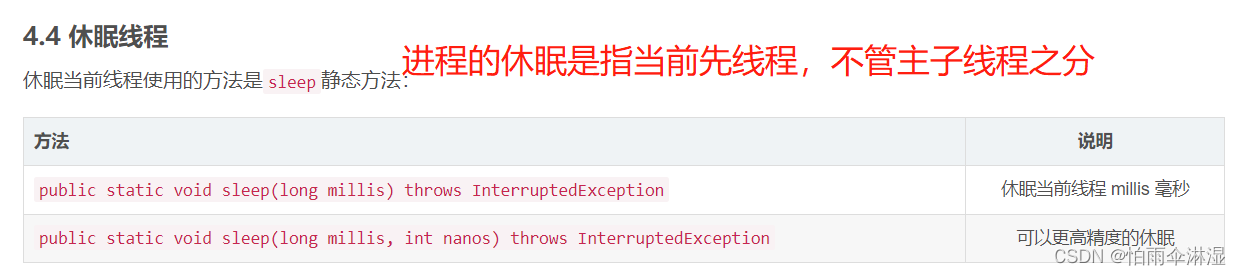
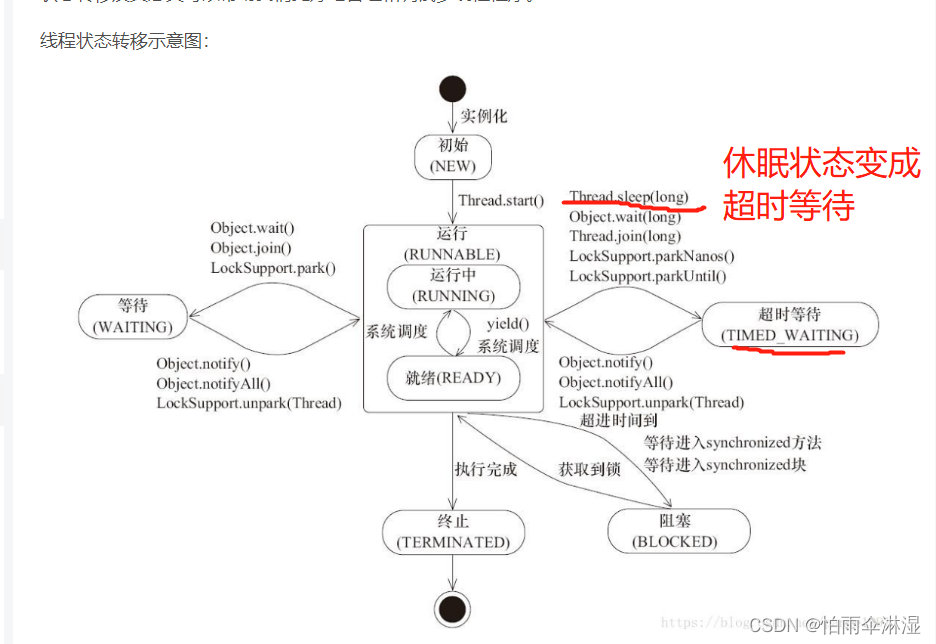
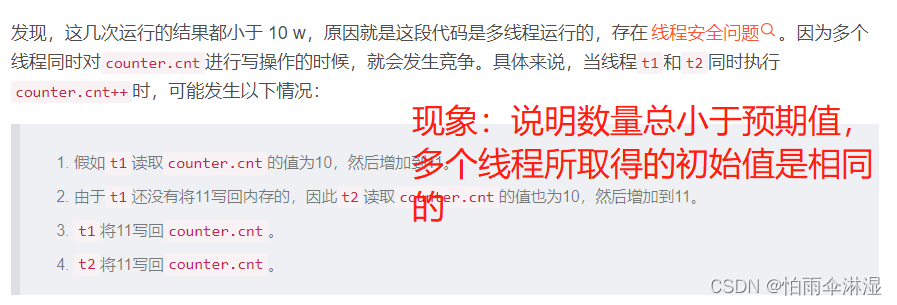
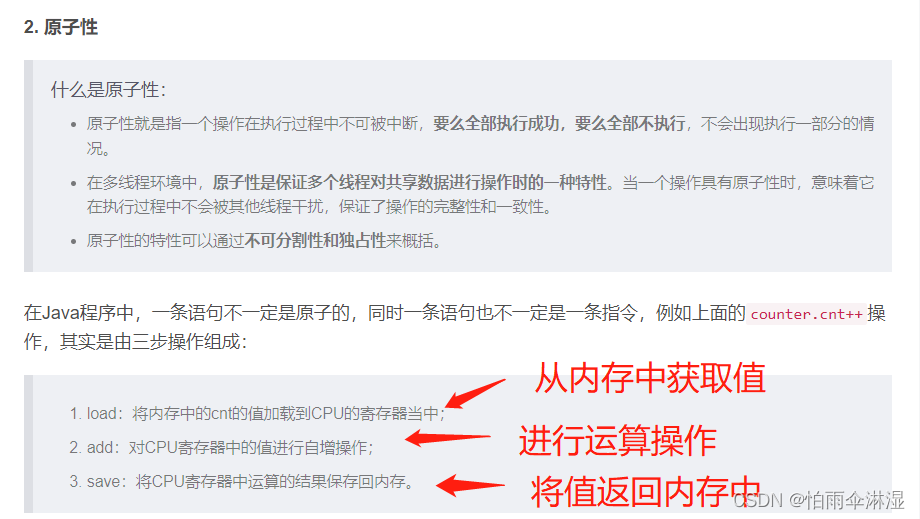
9.1多线程不安全的模块



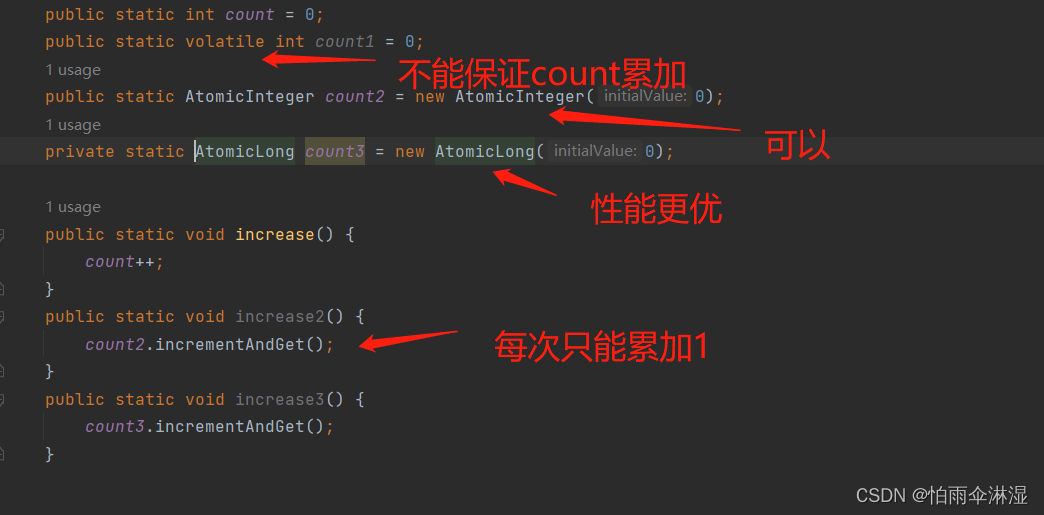




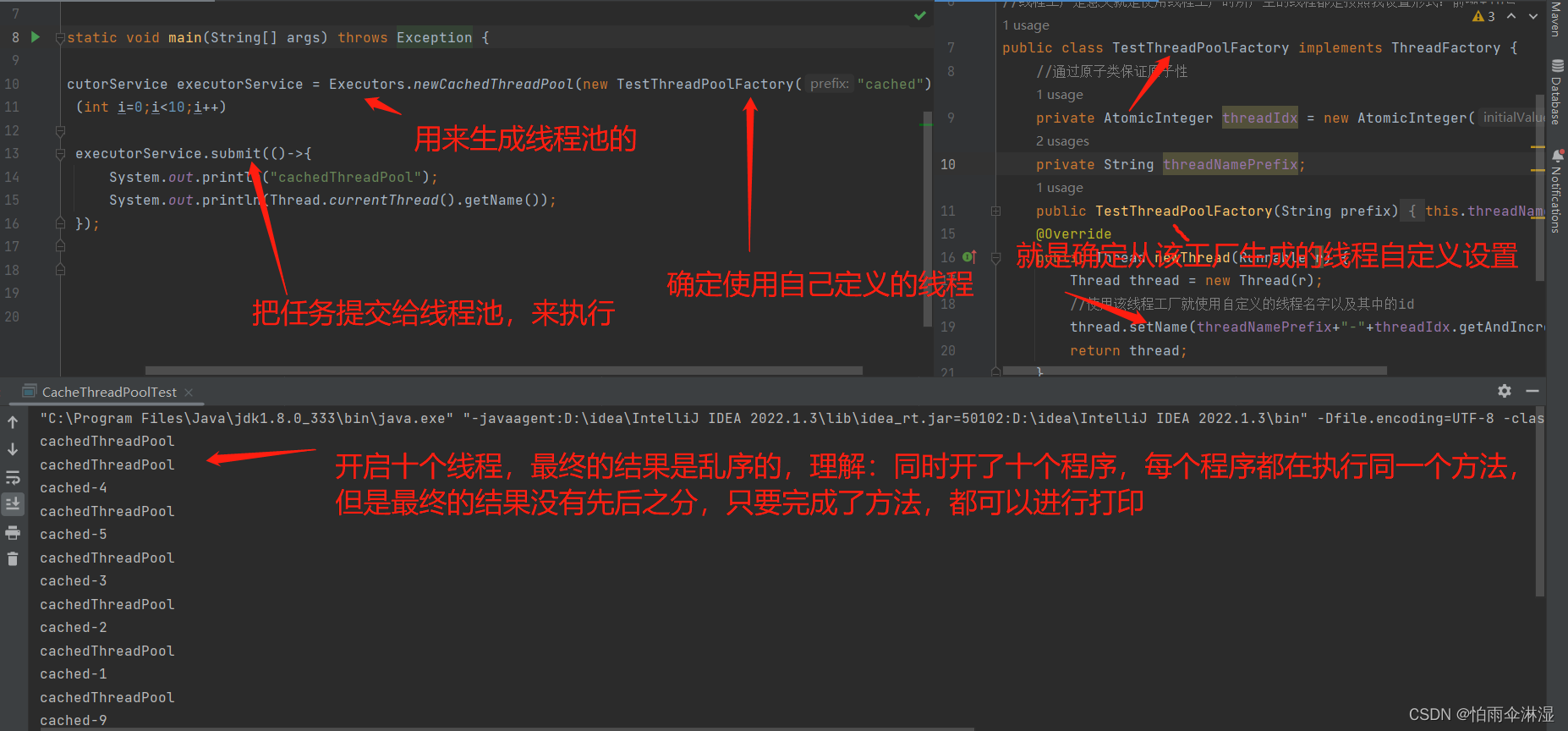
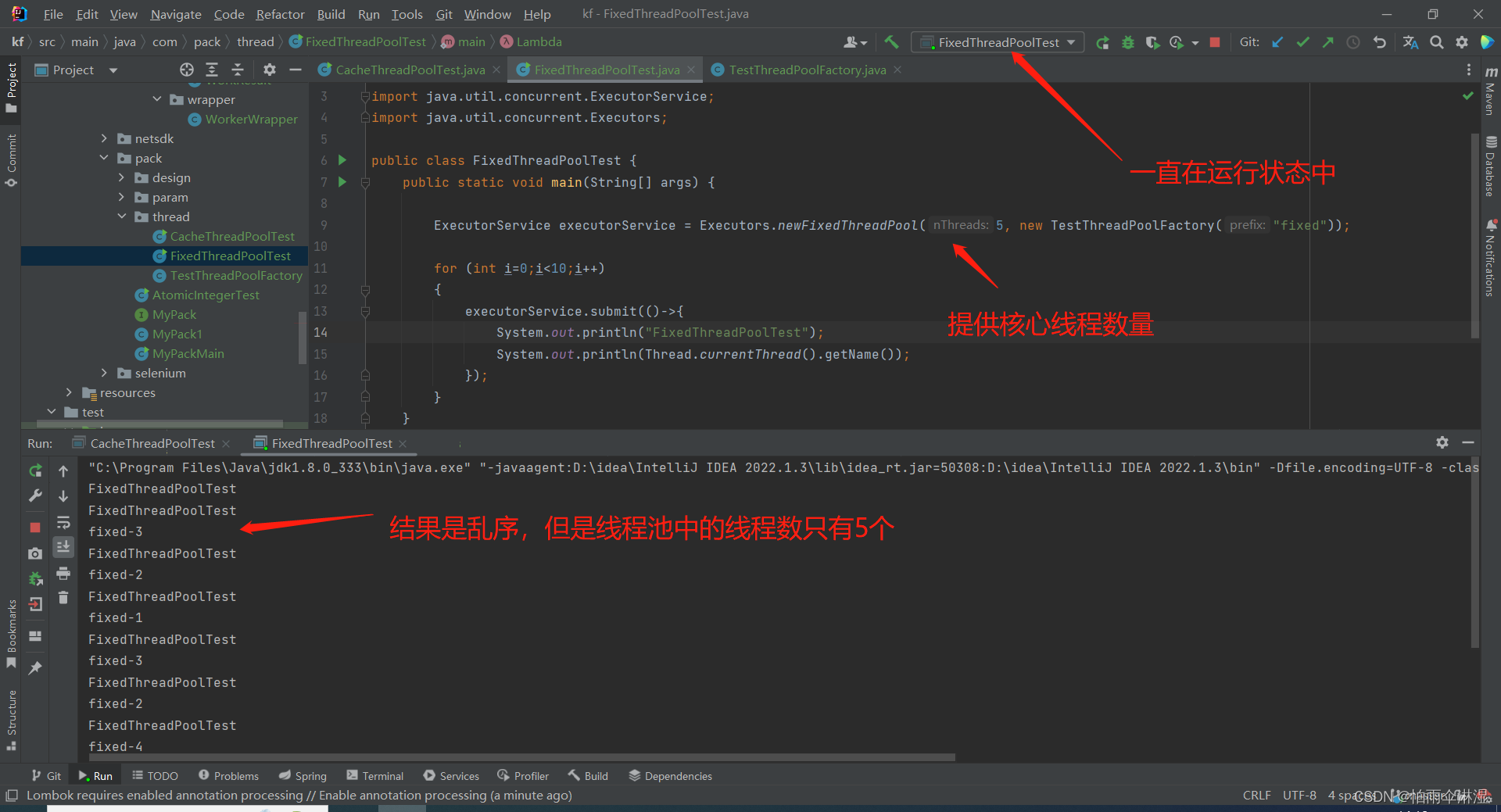
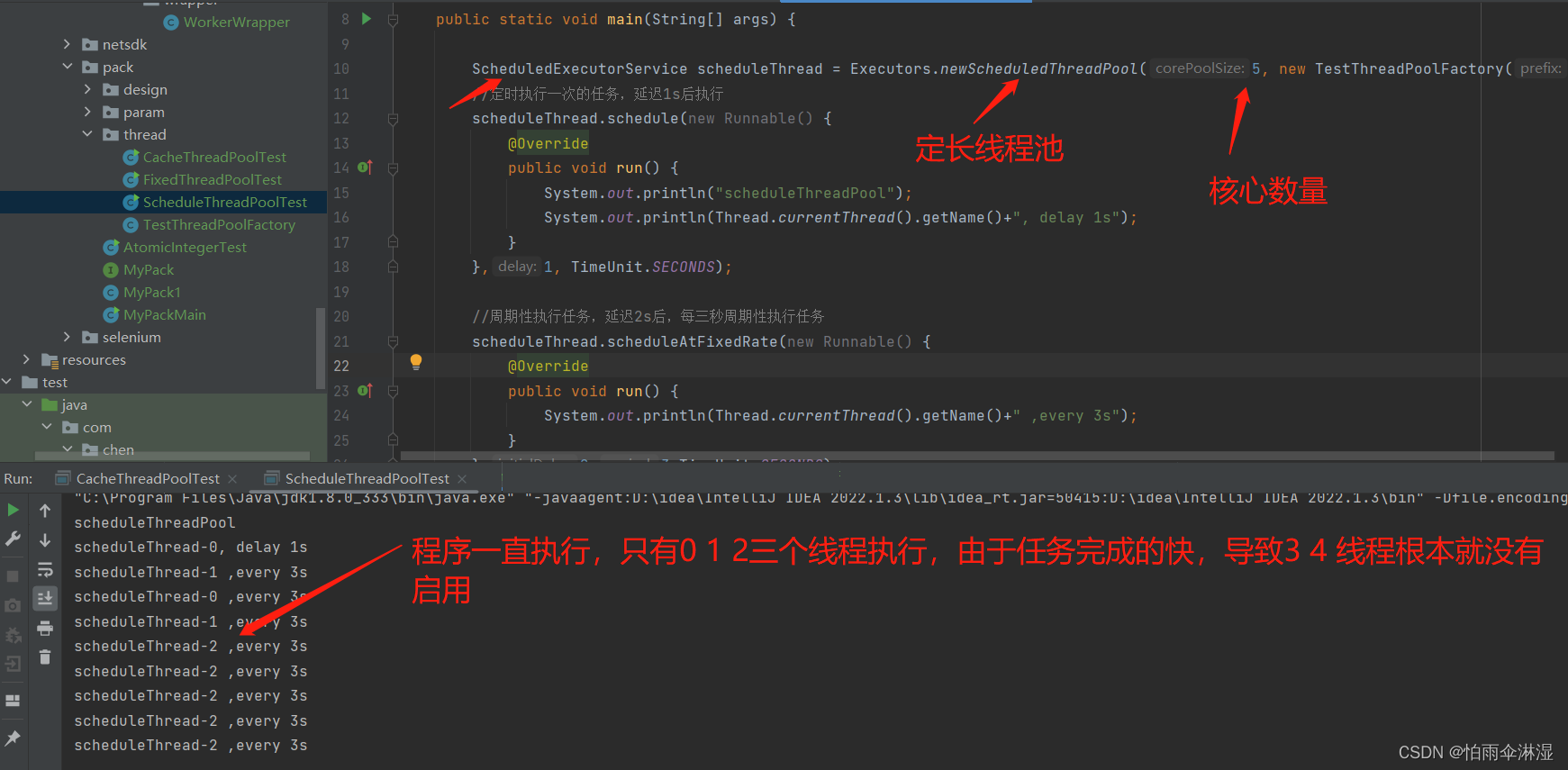
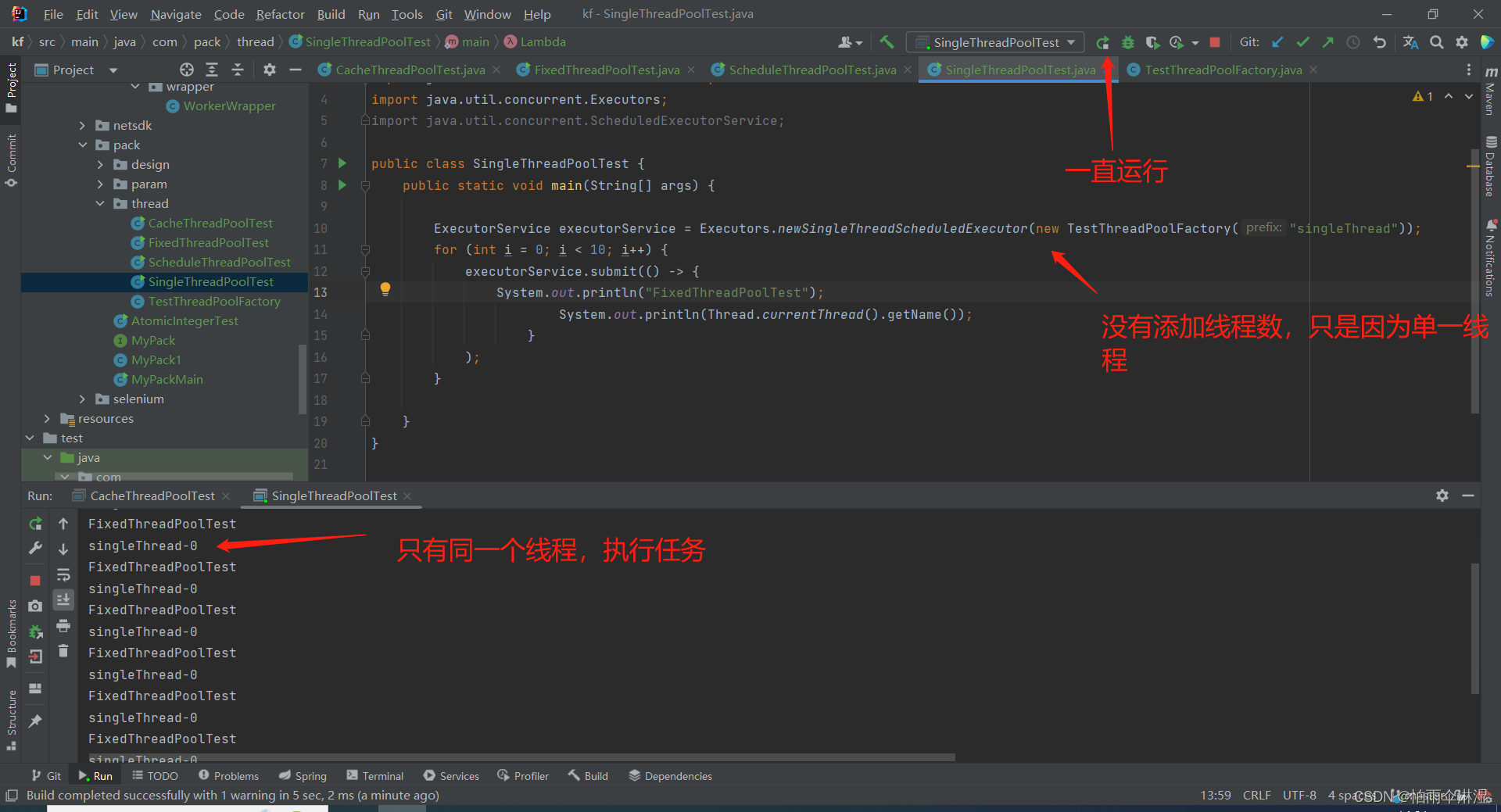






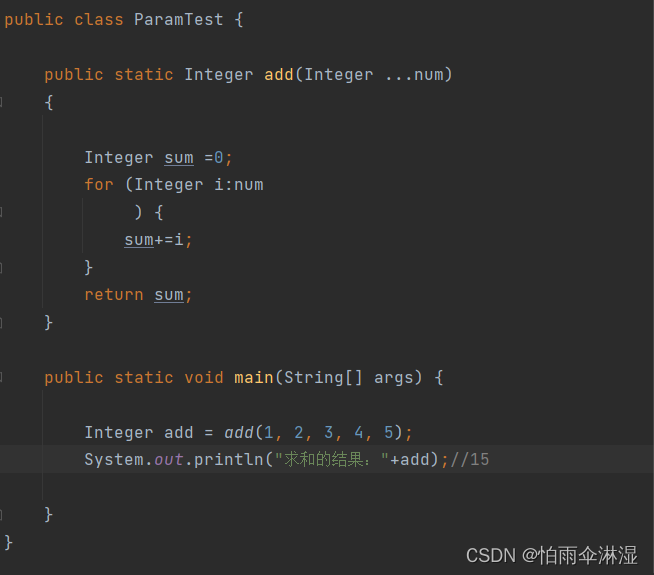
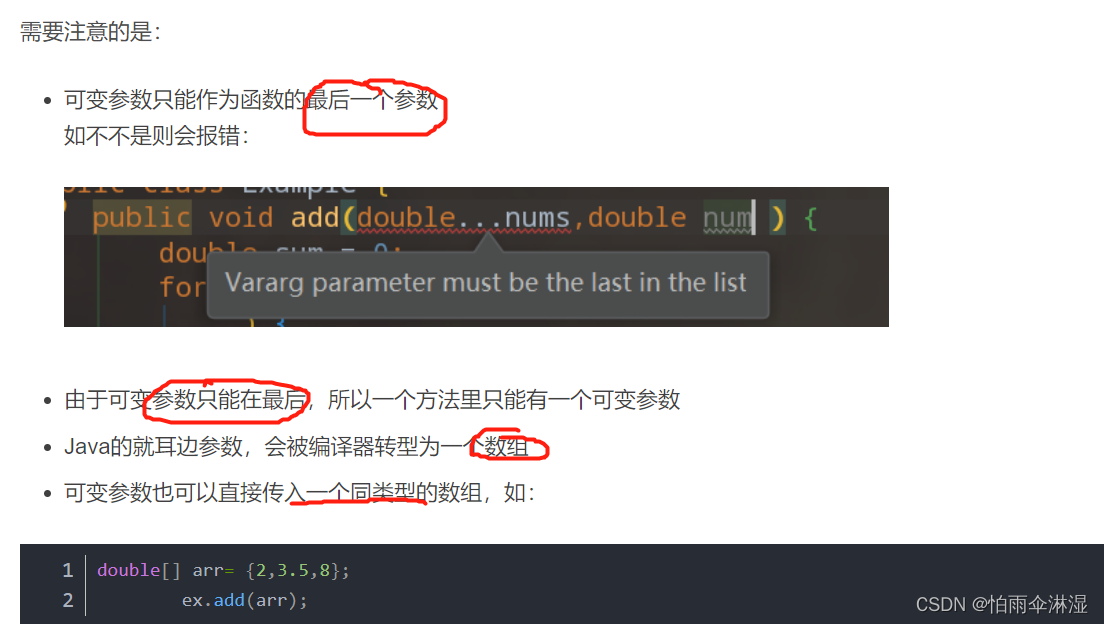
二十六.可变参数的使用
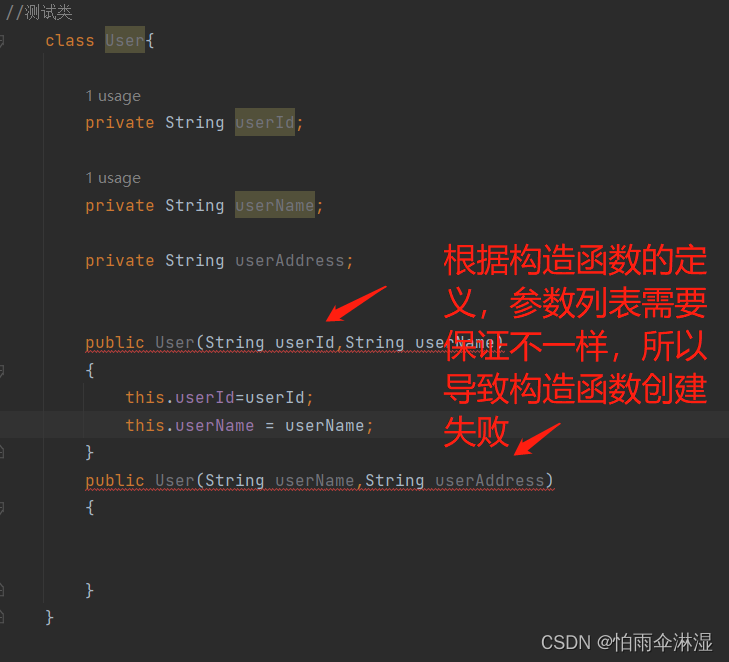
二十七.设计模式
1.建造者模式
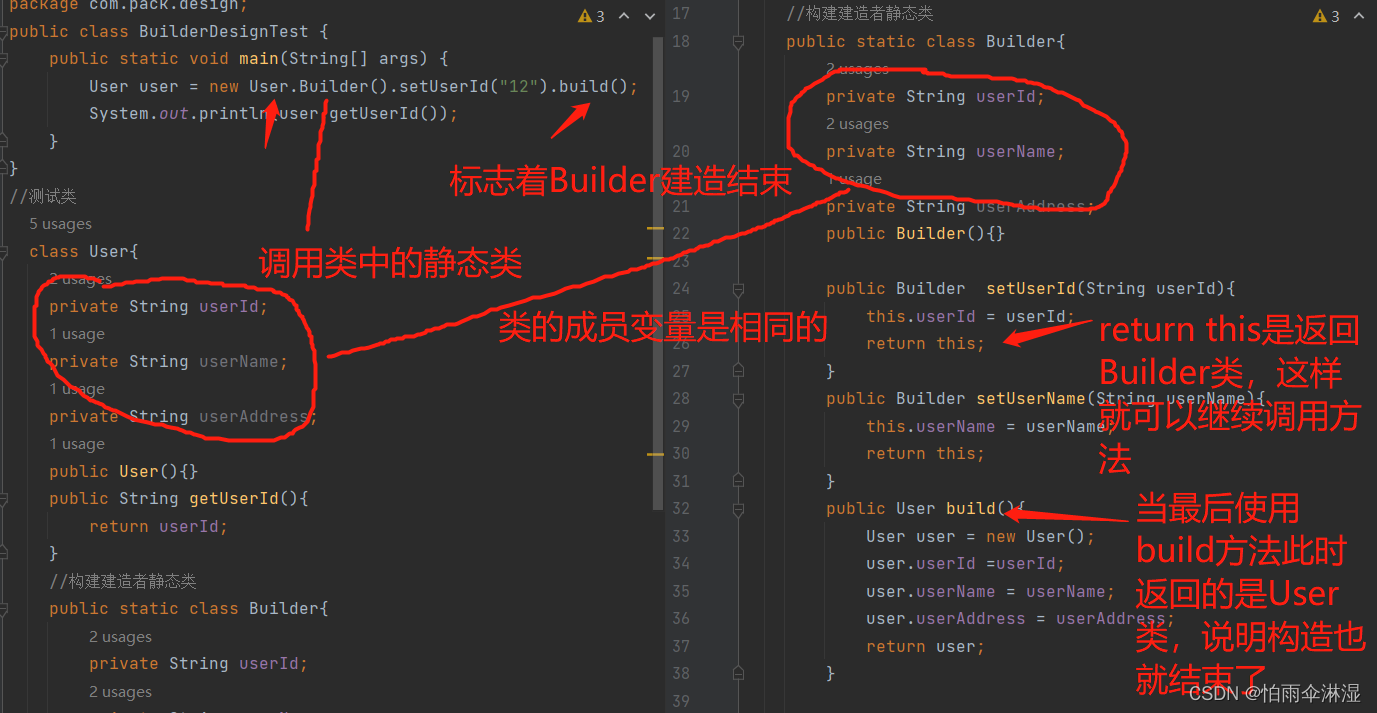
二十八.Java中小知识点
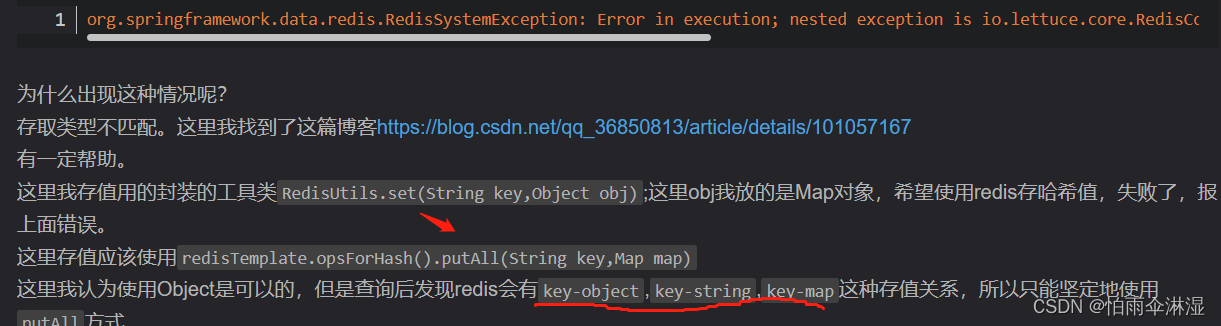
四.map中存入redis中不能使用类型于object对象中
RedisTemplate.opsForHash().putAll(key,value):进行存储 RedisTemplate.expire(key,时间,TimeUnit.SECONDS)设置redis的过期时间 RedisTemplate.opsForHash().entries(key)获Map数据补充:1.通过docker文件也能更新mysql中cof文件,具有等效性,修海mysqlId中添加:lower_case_table_names=1 这样就可以进行忽略大小写表名问题

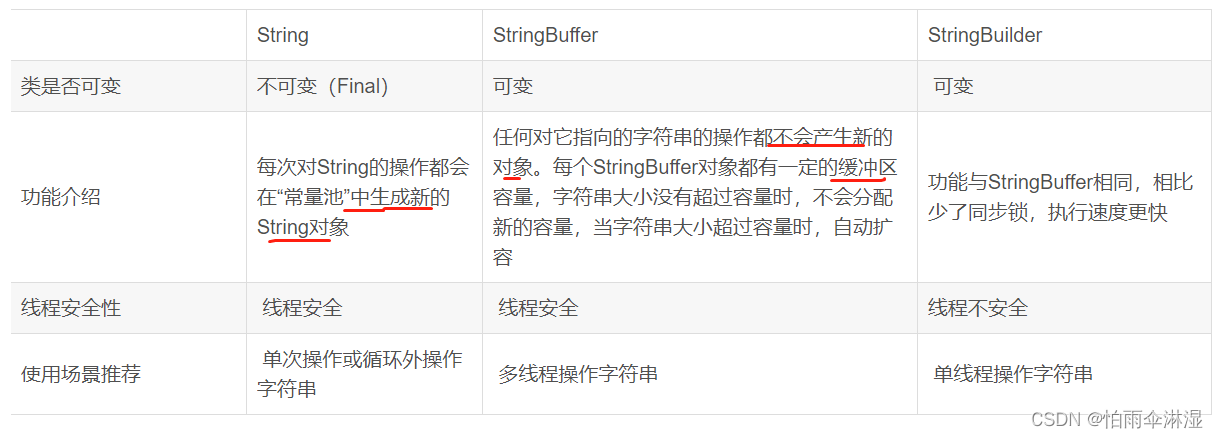
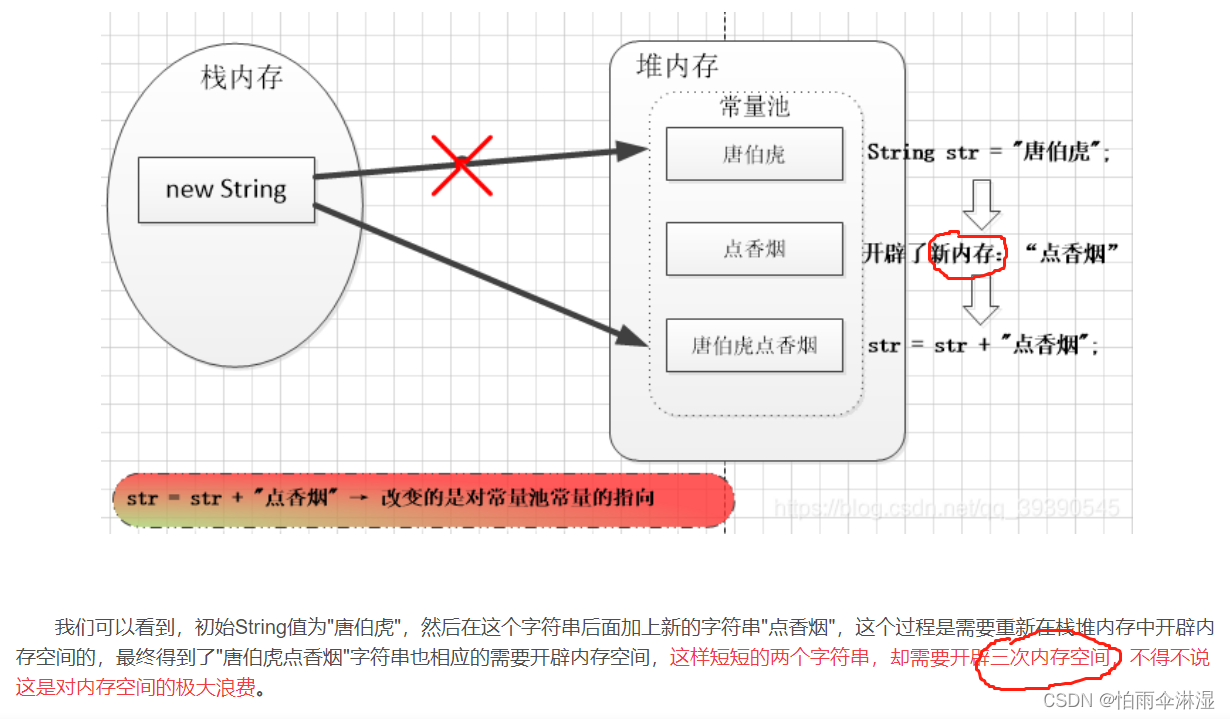

三十.Vue中小知识
1.点击表格
<el-table :data="tableData" @cell-click="cellHandleclick" //当某个单元格被点击时会触发该事件 @row-click="rowHandleclick" > methods: { cellHandleclick(row, column, cell, event) { console.log(row); console.log(column); console.log(cell); console.log(event); //如果规定点击某一列执行,利用column中的label属性 if(column.label === '某一列名称') { //执行逻辑 } } //如果想规定点击某一行执行 rowHandleclick(row, column, event){ //执行逻辑 } }2.将鼠标变为小手
<el-table class="tables" @cell-click="cellHandleclick" :data="tableData" border style="width: 100%;cursor:pointer">3.手机游览器自适应pc端(对我的项目没有作用,但还是记录一下)
通用的形式: <meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0"> 或者: <meta name="viewport" content="width=device-width, initial-scale=1"> 最后一个是有用,内容能够显示,但是不够美观 <meta name="viewport" content="width=device-width, user-scalable=yes, initial-scale=0.3, maxmum-scale=1.0, minimum-scale=0.3"> 下载插件 npm install --save vue-meta import Meta from "vue-meta"; Vue.use(Meta); //这里是与data()属于同级的关系,不然不起效果 data() { return {}; }, metaInfo: { meta: [ { name: 'viewport', content: 'width=device-width, user-scalable=yes, initial-scale=0.3, maximum-scale=1.0, minimum-scale=0.3' }, ] },
















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









