






HDFS的高可用架构
在HDFS分布式文件系统中,NameNode是系统核心节点,存储各类元数据信息,并负责管理文件系统的命名空间和客户端对文件的访问。若NameNode发生故障,会导致整个Hadoop集群不可用,即单点故障问题。为了解决单点故障,Hadoop2.0中HDFS中增加了对高可用的支持。
在高可用HDFS中,通常有两台或两台以上机器充当NameNode,无论何时,都要保证至少有一台处于活动(Active)状态,一台处于备用(Standby)状态。Zookeeper为HDFS集群提供自动故障转移的服务,给每个NameNode都分配一个故障恢复控制器(简称ZKFC),用于监控NameNode状态。若NameNode发生故障,Zookeeper通知备用NameNode启动,使其成为活动状态处理客户端请求,从而实现高可用。
HDFS的高可用架构
 搭建Hadoop高可用集群
搭建Hadoop高可用集群
1.部署集群节点
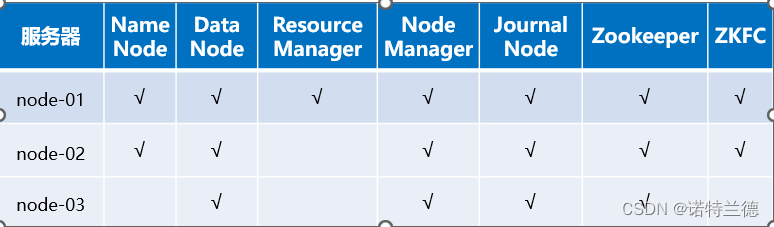
2.环境准备
搭建普通Hadoop集群(参考第2章完成即可)。需要注意的是,原有虚拟机系统主机名为hadoop01,建议初学者在搭建Hadoop HA集群时重新安装虚拟机,以此来巩固前面所学知识,并将三台虚拟主机名设置为node-01、node-02和node-03。
3.配置Hadoop高可用集群
1.修改core-site.xml文件,配置HDFS端口、指定Hadoop的临时目录和Zookeeper集群地址。
2.修改hdfs-site.xml文件,配置NameNode端口和通信方式,并指定元数据存放位置及开启失败自动切换服务,配置隔离机制方法。
3.修改mapred-site.xml文件,将MapReduce计算框架指定为yarn方式。
4.修改yarn-site.xml文件,开启ResourceManager高可用,指定ResourceManager端口名及其地址,并配置Zookeeper集群地址。
5.修改slaves,配置集群主机名称。
6.修改hadoop-env.sh,配置JDK环境变量,将配置好的文件分发传送给node-02,node-03机器中并进行相关配置。
4.启动Hadoop高可用集群
1.启动集群各个节点的Zookeeper服务。
2.启动集群各个节点监控NameNode的管理日志的JournalNode。
3.在node-01节点格式化NameNode,并将格式化后的目录拷贝到node-02中。
4.在node-01上执行“hdfs zkfc -formatZK”命令,进行格式化ZKFC。
5.在node-01节点上执行“start-dfs.sh”命令启动HDFS。
6.在node-01节点上执行“start-yarn.sh”命令启动YARN。
HDFS的高可用框架
NameNode单点故障à两台以上NameNode(Active、Standby)
搭建Hadoop高可用集群
1、Hadoop HA是集群中启动两台或两台以上机器充当NameNode,避免一台NameNode节点发生故障导致整个集群不可用的情况。
2、Hadoop HA是两台NameNode同时执行NameNode角色的工作。
3、在Hadoop HA中,Zookeeper集群为每个NameNode都分配了一个故障恢复控制器,该控制器用于监控NameNode的健康状态。
3. 4配置Hadoop高可用集群
21. 部署集群节点
















 2073
2073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











