







Q3 CIFAR10 图像分类
-
本次运用了
ResNet50进行了图像分类处理(基于Pytorch)
一、数据集
1. 数据集说明
- CIFAR-10数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。
| 编号 | 类别 |
|---|---|
| 0 | airplane |
| 1 | automobile |
| 2 | brid |
| 3 | cat |
| 4 | deer |
| 5 | dog |
| 6 | frog |
| 7 | horse |
| 8 | ship |
| 9 | truck’ |
2. 数据集增强
1). 图像增广介绍
- 大型数据集是成功应用深度神经网络的先决条件。 图像增广在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。 此外,应用图像增广的原因是,随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。 例如,我们可以以不同的方式裁剪图像,使感兴趣的对象出现在不同的位置,减少模型对于对象出现位置的依赖
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)

a. 翻转和裁剪
- 翻转
- 左右翻转图像通常不会改变对象的类别。左右翻转图像通常不会改变对象的类别。这是最早且最广泛使用的图像增广方法之一。
- 上下翻转图像不如左右图像翻转那样常用。但是,至少对于这个示例图像,上下翻转不会妨碍识别。

- 裁剪
- 可以通过对图像进行随机裁剪,使物体以不同的比例出现在图像的不同位置。 这也可以降低模型对目标位置的敏感性。(在下面的代码中,随机裁剪一个面积为原始面积10%到100%的区域,该区域的宽高比从0.5到2之间随机取值)
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)

b. 颜色改变
- 可以改变图像颜色的四个方面:亮度、对比度、饱和度和色调。
-
随机更改图像的亮度

-
可以随机更改图像的色调

2) 数据图像增强
stats = ((0.5,0.5,0.5),(0.5,0.5,0.5))
# 将大小转化为 -1到1
# 随即垂直 水平 翻转 默认 p=0.5
train_transform = tt.Compose([
tt.RandomHorizontalFlip(p=0.5),
tt.RandomVerticalFlip(p=0.5),
tt.RandomCrop(32, padding=4, padding_mode="reflect"),
tt.ToTensor(),
tt.Normalize(*stats)
])
test_transform = tt.Compose([
tt.ToTensor(),
tt.Normalize(*stats)
])
- 对训练集 在数据集导入过程中随机上下,左右翻转(p=0.5),
- 因原数据图片不大,在经过padding = 4后对训练集进行随即裁剪
- 将训练集与测试集利用
torchvision.transforms.Normalize()进行数据集归一化
3. 数据集导入
train_data = CIFAR10(download=True,root="Data", transform=train_transform)
test_data = CIFAR10(root="Data", train=False, transform=test_transform)
BATCH_SIZE = 128
train_dl = DataLoader(train_data, BATCH_SIZE, num_workers=4, pin_memory=True, shuffle=True)
test_dl = DataLoader(test_data, BATCH_SIZE, num_workers=4, pin_memory=True)
-
数据集占比例展示
'frog': 5000 1000 'truck': 5000 1000 'deer': 5000 1000 'automobile': 5000 1000 'bird': 5000 1000 'horse': 5000 1000 'ship': 5000 1000 'cat': 5000 1000 'dog': 5000 1000 'airplane': 5000 1000图像大小 32 ∗ 32 32*32 32∗32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了训练集;另外10000张用于测试,构成测试集
4. 数据集展示
# for 8 images
train_8_samples = DataLoader(train_data, 8, num_workers=4, pin_memory=True, shuffle=True)
dataiter = iter(train_8_samples)
images, labels = dataiter.next()
fig, axs = plt.subplots(2, 4, figsize=(16, 6))
nums = 0
for i in range(2):
for j in range(4):
img = images[nums] / 2 + 0.5
npimg = img.numpy()
axs[i][j].imshow(np.transpose(npimg, (1, 2, 0)))
axs[i][j].set_title(train_data.classes[labels[nums]])
nums += 1
plt.show()

二、模型说明
1.Resnet解决的问题
1.1 退化的出现
- 我们知道,对浅层网络逐渐 叠加 l a y e r s layers layers,模型在训练集和测试集上的性能会变好,因为模型复杂度更高了,表达能力更强了,可以对潜在的映射关系拟合得更好。而**“退化”指的是,给网络叠加更多的层后,性能却快速下降的情况。**
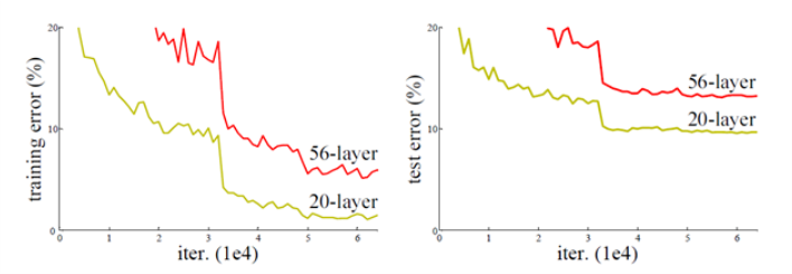
1.2 解决方案
- 调整求解方法,比如更好的初始化、更好的梯度下降算法等
- 调整模型结构,让模型更易于优化——改变模型结构实际上是改变了error surface的形态
ResNet的作者从后者入手,探求更好的模型结构。将堆叠的几层 l a y e r layer layer称之为一个 b l o c k block block,对于某个 b l o c k block block,其可以拟合的函数为 F ( x ) F(x) F(x),如果期望的潜在映射为 H ( x ) H(x) H(x),与其让 F ( x ) F(x) F(x)直接学习潜在的映射,不如去学习残差 H ( x ) − x H(x)-x H(x)−x,即 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x,这样原本的前向路径上就变成了 F ( x )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3360
3360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









