






一、介绍一下Spark shuffle:
Spark shuffle就是将分布在不同结点的数据按照一定的规则进行打乱重组。那么,说起shuffle就想到MapReduce中的shuffle,MapReduce中的shuffle是来连接Map和Reduce的桥梁,Map的输出要用到Reduce,则必须经过shuffle环节。由于shuffle阶段涉及磁盘的读写和网络传输,因此shuffle的性能直接影响整个程序的性能和吞吐量。
Spark shuffle分为HashShuffle 和 SortShuffle两种,其中HashShuffle分为优化前和优化后。而现在默认用的是SortShuffle。
注:下文中Map Task 指的就是 Shuffle Write 阶段,Reduce Task 指的就是 Shuffle Read 阶段。
(1)在早期的版本中,用的是未优化的HashShuffle,这种shuffle方式中 ,MapTask过程会按照Hash的方式重组Partition的数据,但不进行排序,每个MapTask会为每个ReduceTask生成一个文件 。但问题来了,如果有M个 MapTask 和R个 ReduceTask的话,那将产生M*R个中间文件,文件数多了,也将伴随着大量的磁盘I/O与大量的内存开销,导致效率低下,同时容易引发OOM。
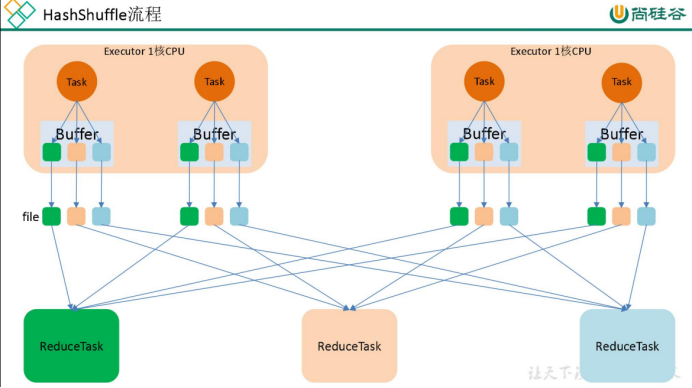
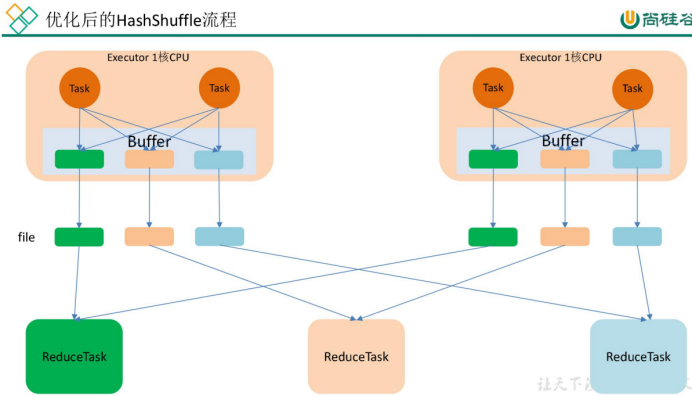
(2)针对上面的问题,Spark对HashShuffle进行了改进。 一个Executor上所有的MapTask生成的分区文件只有一份,即将所有的MapTask相同的分区文件进行合并,这样每个Executor上最多只生成R个分区文件。 (R为ReduceTask的数量)
但问题又来了,虽然这样减少了文件数量,但如果下游Stage的分区数N很大,而一个Executor上又K个Core,还是会产生N*K个文件,同样容易导致OOM。
(3)为了更好的解决上面的问题,Spark参考了MapReduce中的shuffle处理方式,引入基于排序的shuffle写操作机制。
每个Task不会为后续的每个Task创建单独的文件,而是通过缓冲区溢写的方式,在溢写前先根据key进行排序,然后默认以1w条数据为批次溢写到磁盘文件。每次溢写都会产生一个磁盘文件,也就是说一个Task过程会产生多个临时文件。最后将所有的临时文件进行合并,一次写入到最终文件中。这意味着一个Task的所有数据都在这一个文件中,同时单独写一份索引文件,标识各个Task的数据在文件中的索引。
总体来看,SortShuffle解决了HashShuffle的所有弊端,但因为其Shuffle过程需要对记录进行排序,所以在性能上有所损失。
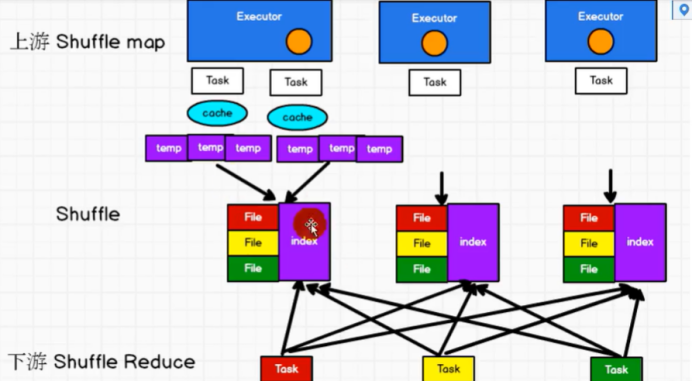
关于 Shuffle Read,主要了解以下问题:
- 在什么时候获取数据 ,Parent Stage 中的一个 ShuffleMapTask 执行完还是等全部 ShuffleMapTasks 执行完?
当 Parent Stage 的所有 ShuffleMapTasks 结束后再 fetch。- 边获取边处理还是一次性获取完再处理?
因为 Spark 不要求 Shuffle 后的数据全局有序,因此没必要等到全部数据 shuffle 完成后再处理,所以是边 fetch 边处理。
二、Spark的shuffle过程数据一直放在内存中吗?
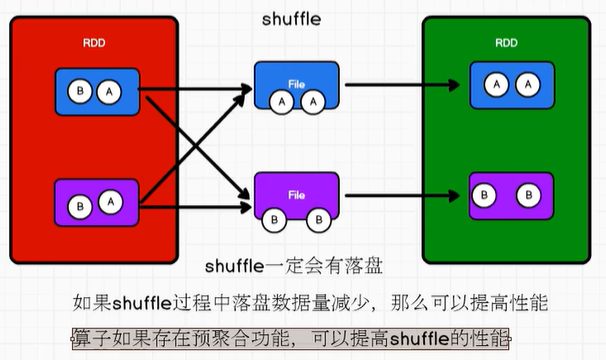
Spark的shuffle过程一定会有落盘,因为shuffle过程中,分区间的数据需要打乱重组,那么下游的Stage必须等到上游的Stage全部处理完了之后才能进行处理,分区间不能流水线一样的处理了,所以如果数据全都放在内存,那么容易出现OOM问题,所以数据是要落盘处理的。
三、shuffle操作增加了什么开销?底层用的什么算法?
Shuffle操作会增加 磁盘I/O、网络传输、序列化和反序列化 的开销。
增加磁盘I/O开销:Map端输出的数据在写入磁盘时,会产生磁盘IO
增加网络传输开销:Reduce任务需要从Map任务的输出中获取数据进行计算,会产生网络传输的开销。
增加序列化和反序列化的开销:Reduce任务需要对Shuffle数据进行聚合和处理,产生序列化和反序列化开销。
shuffle有两种算法,一个HashShuffle、一个SortShuffle,现在底层用的是SortShuffle算法。
四、为什么Spark shuffle 比 MapReduce shuffle快?
五、哪些算子会导致Spark产生shuffle?
产生shuffle的原因是将分区间的数据进行混洗重组了,常用的如:
还有distinct、sortBy、partitionBy、foldByKey、leftOuterJoin、rightOuterJoin、intersection、substract等
六、Spark中,说说Transform算子和Action算子的区别:
Transform算子: 即转换算子,用于功能的补充和封装,将旧的RDD包装成新的RDD,常用的如Map、flatMap、glom、filter等。
Action算子: 即行动算子,行动算子会触发任务的调度和作业的执行,直接返回处理后的结果,而不是新的RDD。
七、介绍一下Spark的常用算子、常见的行动算子、常见的转换算子(窄依赖、宽依赖算子)
转换算子:
窄依赖: map、flatMap、glom、filter
宽依赖: distinct、sortBy、partitionBy、reduceByKey、groupByKey、combineByKey、aggregateByKey、foldByKey、join、leftOuterJoin、rightOuterJoin、cogroup、coalesce、intersection、substract等
行动算子: collect、foreach、reduce、fold、count、countByKey、countByValue、first、take、takeOrdered、aggregate















 1474
1474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









