







二叉查找树的递归定义:

二叉查找树的基本操作:

二叉查找树寻找值的思路:

//可以想象一条有序数列从中间被曲折成三角形,中间点就是树的根节点,左边的值都比根节点小,右边的值都比根节点大
//二叉树的寻找就是二分查找在树上的体现
//在二叉查找树寻找一个值,遍历二叉树应该是只有一条路径的,如果到根节点都没有找到,就说明该值不存在

//就是因为二叉查找树是可以根据值选择左右子树的,而一般二叉树因为不知道x的位置,只能全部遍历,因此这也就是二叉查找树的优点,查找值的速度更快
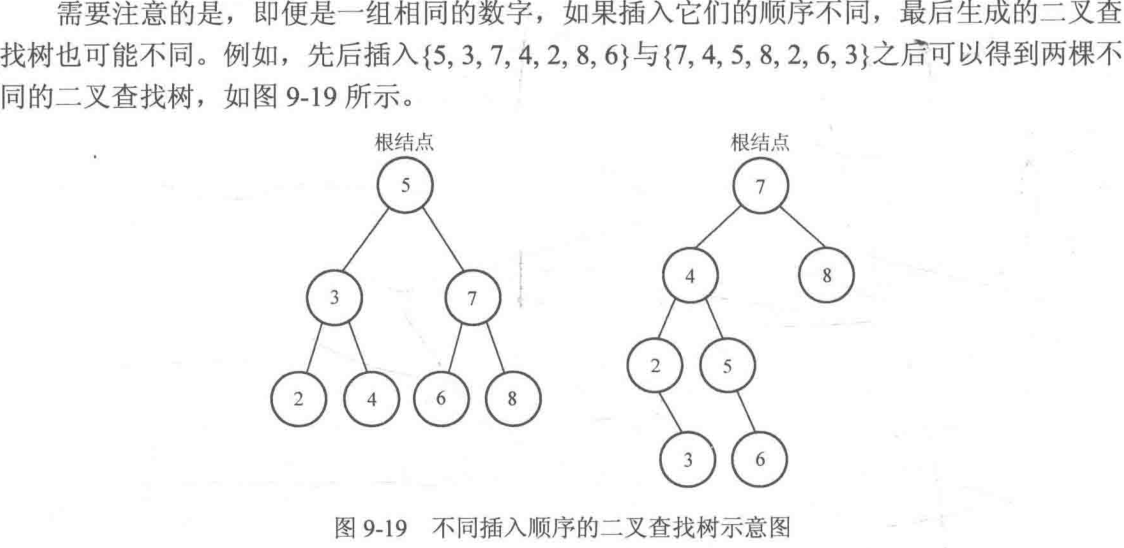
//毕竟第一个插入的就是根结点,插入顺序不同得到的树当然也不同,这也不是肯定的,即插入顺序不同,生成的二叉查找树可能不同,比如改成5374268,生成的二叉树与第一棵是相同的。
二叉查找树的插入:
就是找到它应该在的位置,如果该位置为NULL(插入的位置肯定是叶子结点外,不能是树已有的结点,去更改人家的位置,人家已经生成在哪里了,只能是插入的结点的位置作调整),这个位置就是该结点应该在的位置,如果在应该插入的地方有插入值x了,就不需要插入了。
二叉查找树删除(重难点):



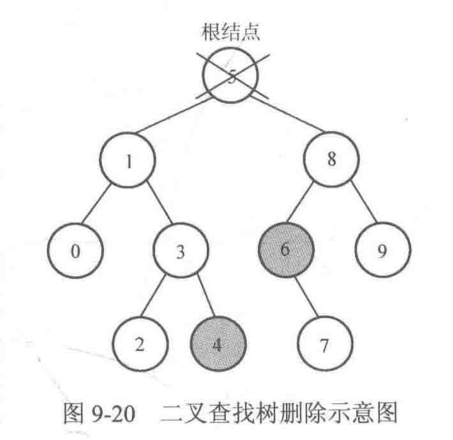
如图,结点5的前驱是4,后继是6,前驱在左子树上的最右孩子(左子树的最大值),后继是右子树的最左孩子(右子树的最小值),找到前驱或者后继,用前驱或者是后继来替代被删除的根结点。
那么如何替代呢?



//按代码顺序写的思路
//前驱和后继不一定是叶子结点,但是被删除的前驱和后继被它的前驱或者后继替代,直到到达叶子结点,该叶子结点作为某个要被删除的结点(可能的x的,也可能是x的后继或者前驱的等等等等)的前驱或者后继。
比如:插入序列为5867,删除5,则6作为5的后继替代掉5,但是6不是叶子结点,不可以直接删除6其后继也就是7替代,最后删除掉7结束递归。
可以进行优化,这样就不用像这样一直递归,找删除点的前驱,找删除点前驱的前驱...
优化:用删除点的前驱的的左孩子的值来代替前驱的值,前驱的左孩子是根节点左子树第二大的值
(也就比前驱小一个单位,才会被放到前驱的左孩子)
用删除点的后继的的右孩子的值来代替后继的值,后继的右孩子是右子树第二小的值
(也就比后继大一个单位,才会被放到后继的右孩子)

二叉查找树的所有操作:
#include<iostream>
using namespace std;
struct node {
int data;
node* lchild;
node* rchild;
};
node* newnode(int x) {
node* Node = new node;
Node->data = x;
Node->lchild = NULL;
Node->rchild = NULL;
return Node;
}
void search(node* root, int x) {
if(root == NULL) {
cout << "Search node fail";
return ;//记得return,否则对NULL使用->运算符则会发生错误
}
if(root->data == x) {
cout << "Find the node: " << root->data;
}
if(root->data < x) {
search(root->lchild, x);
} else {
search(root->rchild, x);
}
}
//插入都是往叶子结点外插入的,不会在树里面插入,即不会破坏已经生成的树结构
//叶子结点外有地方放这个结点的;
void insert(node* &root, int x) {
if(root == NULL) {
root = newnode(x);
return ;
}
if(root->data == x)//结点存在则不插入;
return;
else if(root->data > x) {
insert(root->lchild, x);
} else {
insert(root->rchild, x);
}
}
//二叉查找树的建立
node* create(int arr[], int n) {
node* root = NULL;
for(int i = 0; i < n; i++) {
insert(root, arr[i]);
}
return root;
}
node* findpre(node* root) {
while(root->rchild != NULL) {
root = root->rchild;
}
return root;
}
node* findpost(node* root) {
while(root->lchild != NULL) {
root = root->lchild;
}
return root;
}
void deleteNode(node* &root, int x) {
if(root == NULL)
return;
if(root->data == x) {
if(root->lchild == NULL && root->rchild == NULL) {
delete root;
root = NULL;
} else if(root->lchild != NULL) {//找前驱;
node* pre = findpre(root->lchild);
root->data = pre->data;
deleteNode(root->lchild, pre->data);
} else if(root->rchild != NULL) {
node* post = findpost(root->rchild);
root->data = post->data;
deleteNode(root->rchild, post->data);
}
} else if(root->data > x) {
deleteNode(root->lchild, x);
} else if(root->data < x) {
deleteNode(root->rchild, x);
}
}
void print(node* root) {
if(root == NULL)
return;
print(root->lchild);
cout << root->data << " ";
print(root->rchild);
}
int main() {
int a[5] = {1, 2, 3, 4, 5};
node* root = create(a, 5);
print(root);
cout << "\n";
deleteNode(root, 3);
print(root);
cout << "\n";
insert(root, 3);
print(root);
return 0;
} 二叉查找树的性质:

//对二叉查找树进行中序遍历,遍历的结果是有序的


//二叉查找树和平衡二叉树的关系
//比如说插入顺序为12345,那么这个树就会退化一条链,那么查找速度就和一般的二叉树一样了,为O(n),因此引出平衡二叉树(AVL)就可以将高度降低,从而降低查找的时间复杂度
由二叉查找树的性质可以引出一题:
给出n个数(非插入顺序),如何建造一个完全二叉查找树?
完全二叉树可以用数组来表示,数组值为权值,下标为结点编号,根节点的编号为1,左孩子为2*x,右孩子为2*x+1。
//当你创建一个数组的时候, 你就可以说它是一个完全二叉树了,只要按照它的性质进行访问
根据二叉查找树的性质,二叉查找树的中序遍历是有序的,对序列进行排序后,从根结点开始对该完全二叉树进行中序遍历,并将该序列补充到该完全二叉树,从而得到一颗完全二叉查找树。
以上条件建造的完全二叉查找树是唯一的。(二叉查找树的中序遍历序列+完全二叉树)
即它先得是一个完全二叉树,才能是一个完全二叉查找树。
如果还要求该完全二叉查找树的层序遍历呢?
根据完全二叉树的性质,某一个结点编号为x,则左孩子编号一定是2*x,右孩子的编号一定是2*x+1
因此对该数组下标从1到n进行输出,就是该完全二叉树的层序遍历。
如何填充一个数组,使其能够表示一个完全二叉查找树?
如果插入的序列为:8,6,5,7,10,8,11
一般插入的第一个元素为根结点,我们一般将根结点放到数组下标为1的地方
插入8, 1号位置为8
插入6, 6比8小,应该作为8的左孩子,因为是完全二叉树,8的左孩子为2*x, 即2号位
插入5, 5比8小,往左,比6小往左,作为6的左孩子,即2*2 = 4,在4号位置
插入7, 7比8小, 往左,比6大,作为6的右孩子,2 * x + 1 = 2 * 2 + 1 = 5,在5号
插入10, 10比8大,作为8的右孩子,1 * 2 + 1 = 3, 在3号位置
插入8, 8和8相等, 往右, 比10小,作为10的左孩子,2 * 3 = 6,在6号位置
插入11, 比8大,比10大,作为10的右孩子, 2 * 3 + 1 = 7, 在7号位置
综上数组1到7号位置分别为
8, 6, 10, 5, 7, 8, 11
从1到7进行输出即为该二叉查找树的层序遍历,对该数组进行排序即可得该二叉查找树的中序遍历
(建议把图画出来再对照着看)















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









