






文章目录
1.词向量模型通俗解释
1.1Word2Vec
-
自然语言处理-词向量模型-Word2Vec
-
在自然语言处理(NLP)过程中,每个字中间有顺序
-
比如对一个人进行打分,我们不能只看外在(Extraversion)打分,只在其中一个层面进行描述,而是要结合多个特点Trait,综合各项指标进行打分
-
而仅仅是2维可能是不够的,50维肯定是够的,但是300维计算更精确,通常数据的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖
-
向量和向量之间可以做相似度的计算,先得将词向量构建好

-
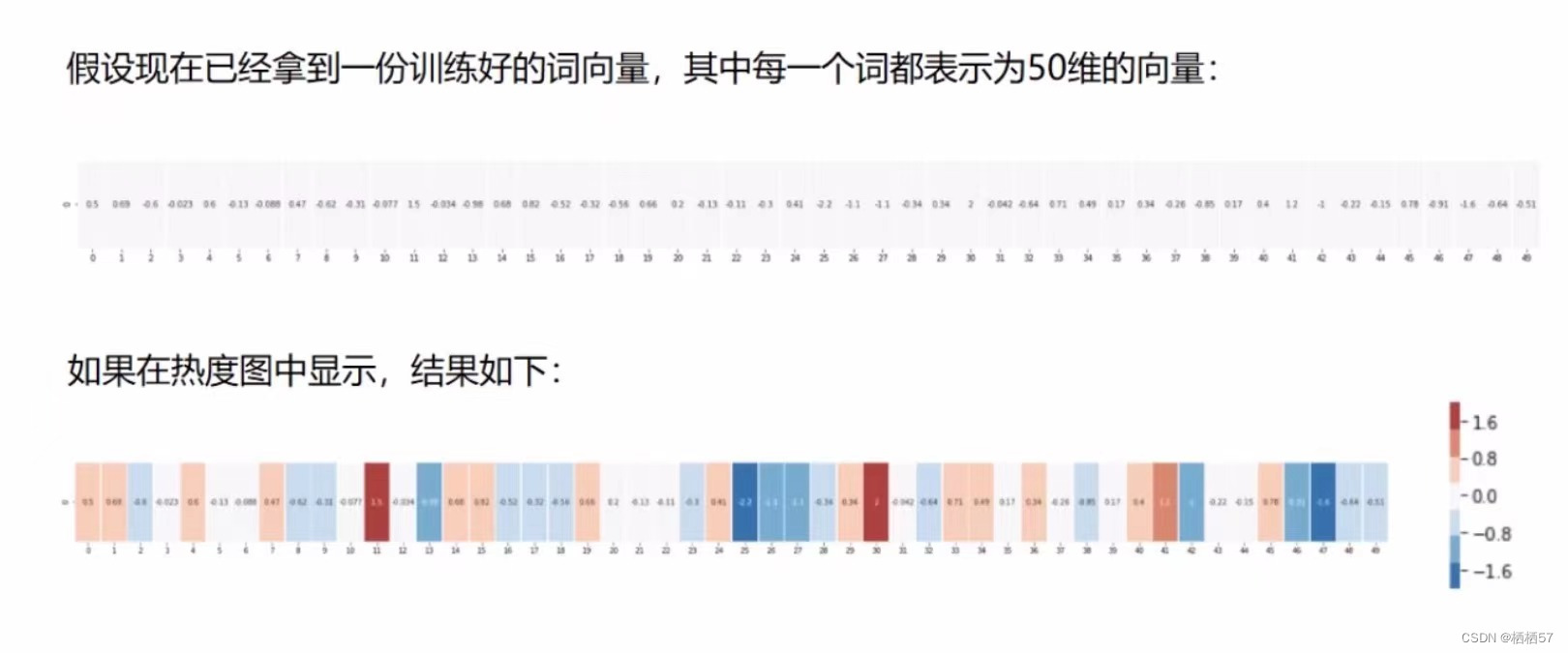
假设现在已经将每个词转化成了50维的向量(如下图所示)
-
计算机能认识,我们不知道是如何进行转化的,相当于一个编码,我们只需要将向量训练出来,剩下如何去评估,如何去衡量,都交给计算机就足够了
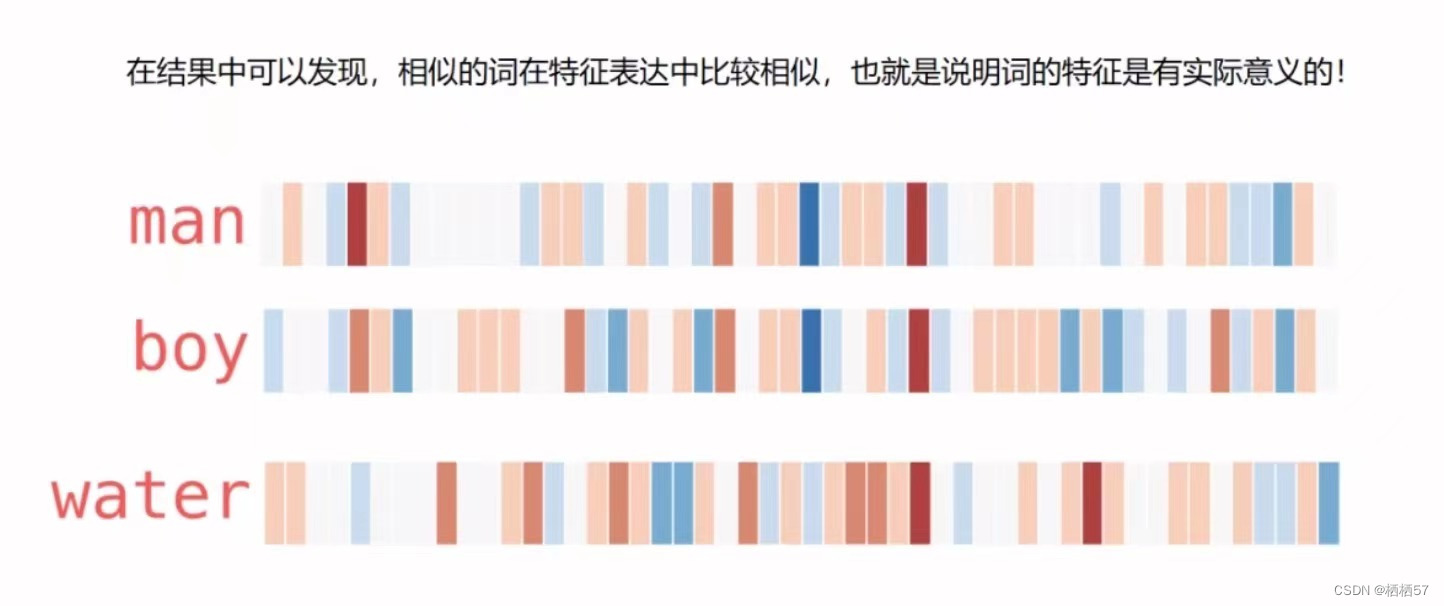
- 在下图中,我们可以观察到man和boy的颜色分布相似度很大,如果看数值的话,对比不是很明显
- 再对比water和man颜色分布差别就很大
1.2如何训练词向量
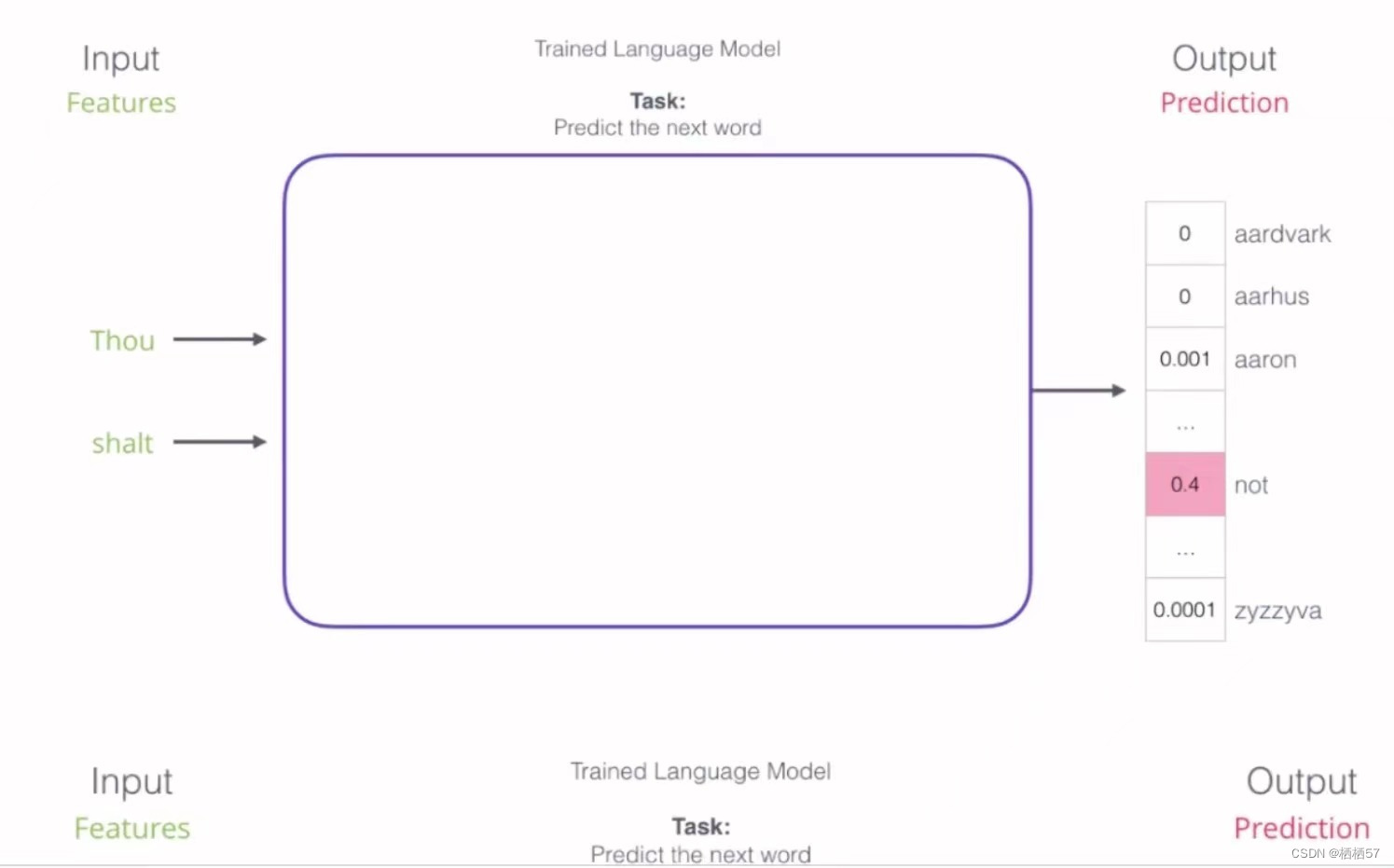
- 比如,左边Thou是第一个词,shalt是第二个词,右边是输出
- 输出相当于神经网络多分类的结果,比如在100个词中,看看对应的哪个词可能性是最高的
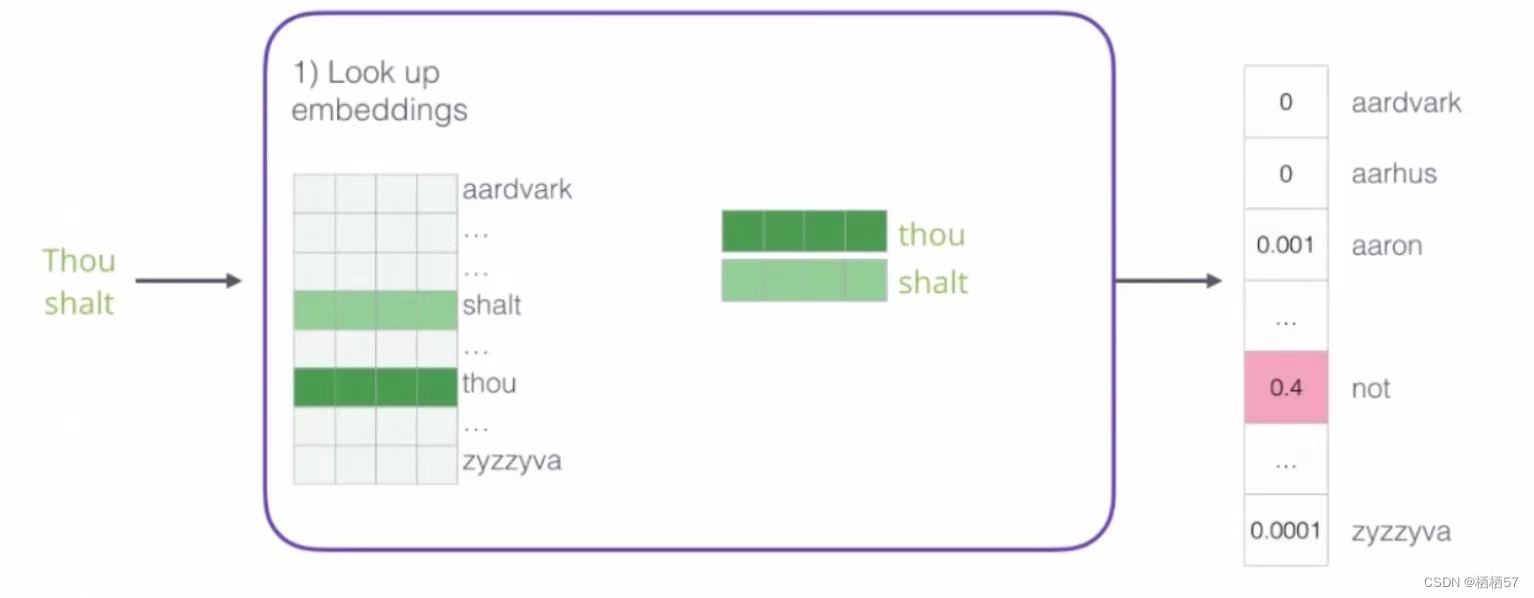
- 词库表(Look up embeddings)
- 在输入神经网络之前,我们需要在词库表中找到对应的词向量,然后得到右边的输出结果
- 大表一开始是随机进行初始化的,比如现在所有文本当中一共包含一千个词,我们先将一千个词列出来,然后跟神经网络的权重初始化是一样的,随机构造一些初始化的策略,然后就随便初始化一些向量
- 神经网络在计算过程中,前向传播计算的是loss,反向传播是通过loss去更新权重参数,而此时在Word2Vec中,不光会更新整个神经网络模型权重参数矩阵,连输入也会进行更新,相当于大表是随机进行初始化的
- 随着训练的进行,每次都会将训练的数据进行更新,一旦训练了100万次之后,就其中的每个词都进行了很多次更新,越进行更新,神经网络学得越好,学得越好的情况下,计算机能表达出当前词向量,也能把下一个词猜得更准确一些
1.3构建训练数据
- 数据:一切可用的文本、图像都可以作为数据进行输入,比如小说中的“今天”跟新闻中的“今天”表达的是一个含义,所以“今天”可以运用在任何场景
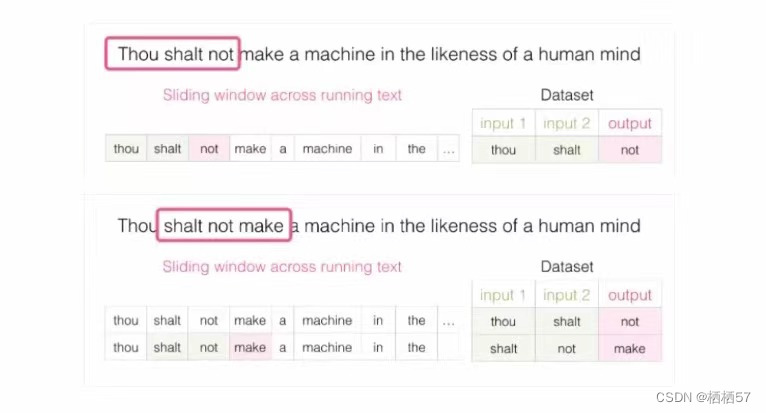
- 当我们拿到一句话(Thou shalt not make a machine in the likeness of a human mind)之后,假设窗口大小为3,那么A(Thou)和B(shalt)相当于两个输入,再输出就是C(not),这就是第一个训练数据(如下图第一行)
- 将窗口往右边进行滑动,那么原来的B窗口的位置变成了之前窗口C对应的字母,即输入和输出不一样了,这样就形成了第二个训练数据(如下图第二行)
- 总结步骤:自己组建滑动窗口大小,记录输入输出,再进行滑动,所以说当前任务并不是有监督的数据集,因为无论什么数据拿过来都是可以做的,但是一定得是有逻辑才是可以用的
2.CBOW与Skip-gram模型对比
2.1CBOW模型
-
continuous bag of words(连续词袋模型)
-
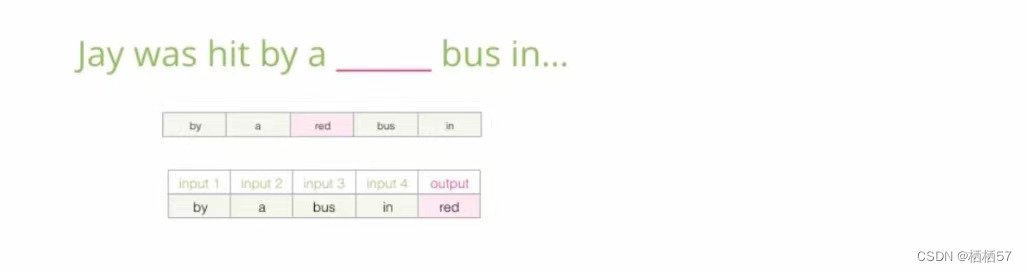
如下图,输入是上下文,输出是中间缺的词
-
比如窗口是5,那么四个输入分别是by 、a 、bus 、 in ,输出就是red,也就是该空是red
2.2Skip-gram模型
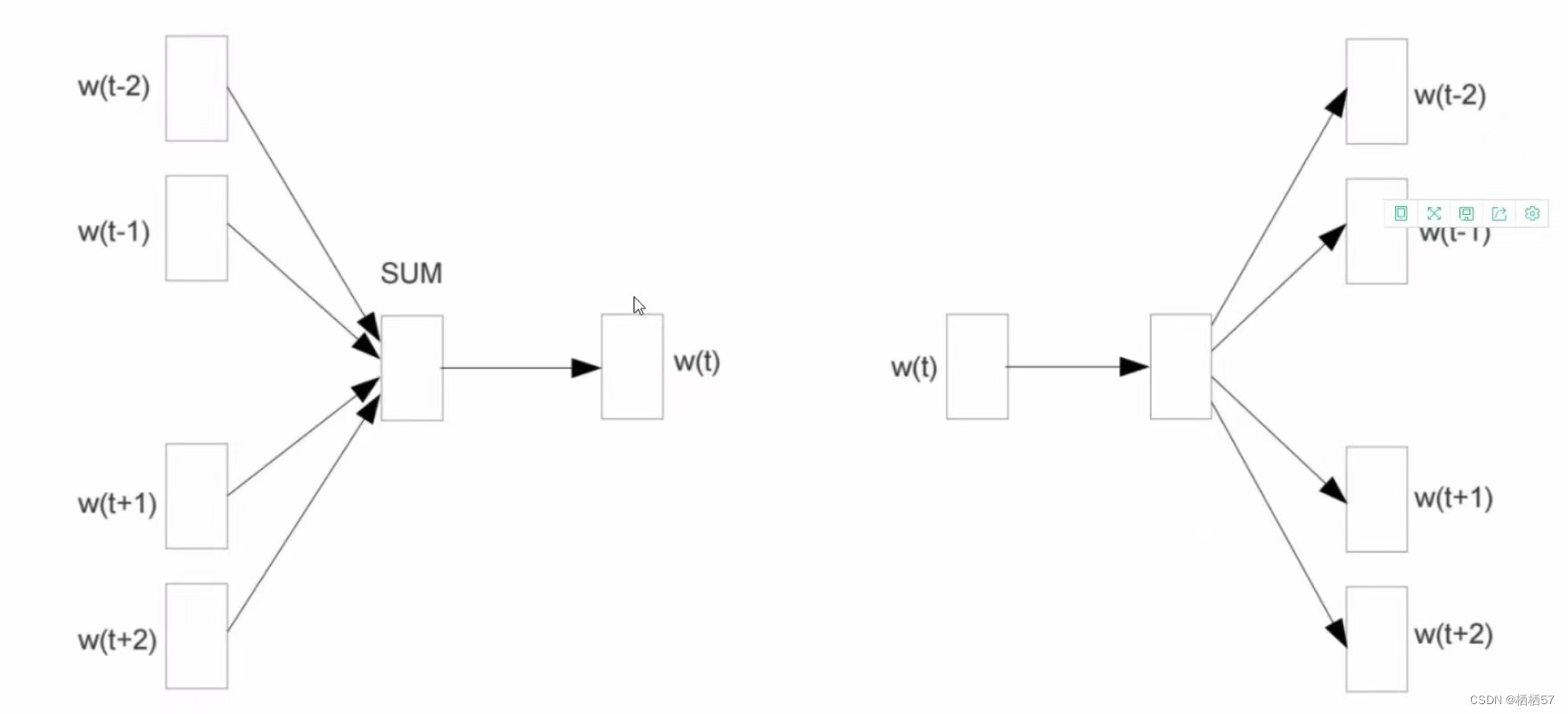
- 下图左边是CBOW模型,输入唯独少了t,因为t是要输出的
- 下图右边是Skip-gram模型,只有输入t,然后预测四个输出
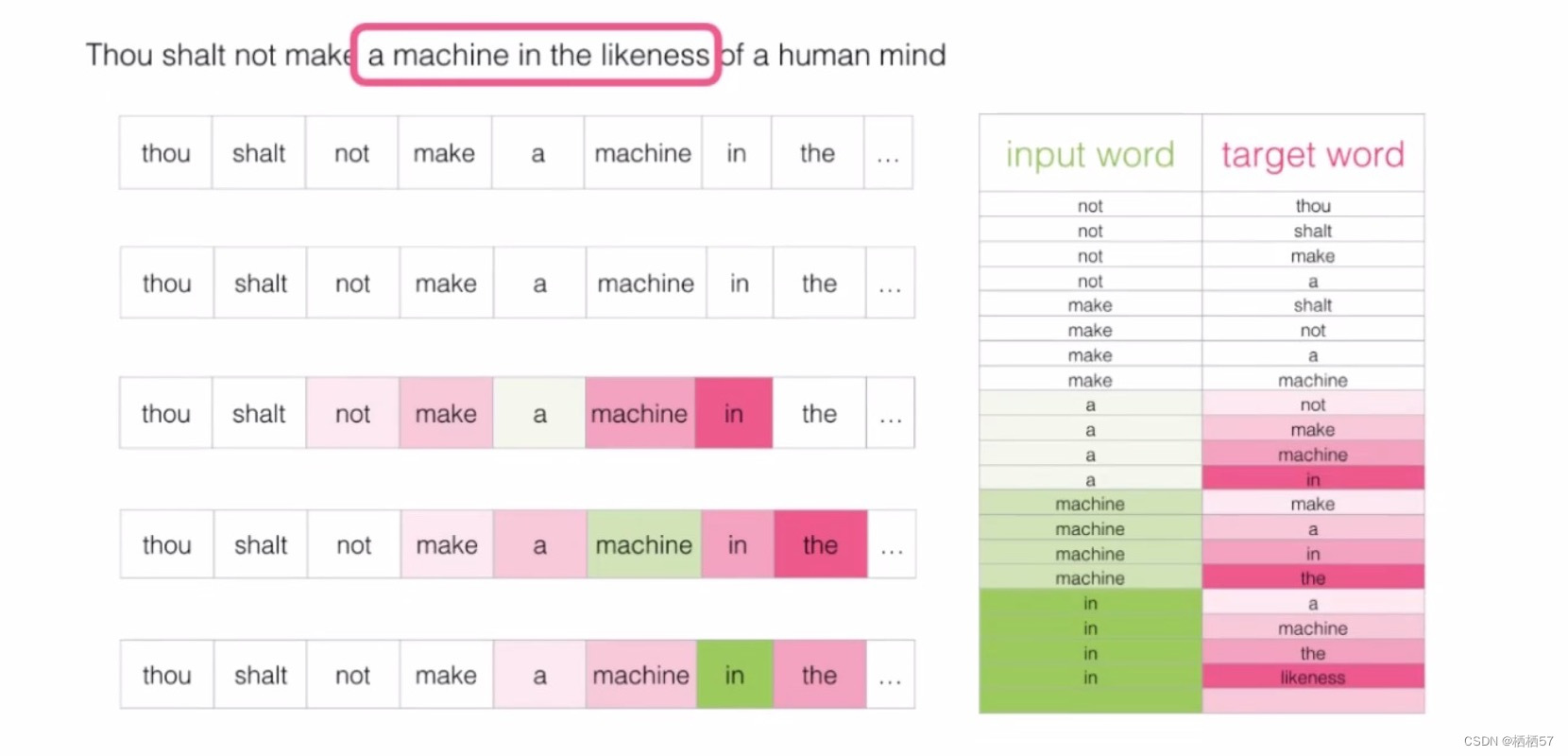
- 下图就是Skip-gram模型的滑动窗口,每个input word都对应四个target word
2.2.1如何对Skip-gram模型进行训练
- 通过前向传播,我们得到Error值
- 再通过Error值,反向传播,看看权重参数如何进行更新
- 对比之前的神经网络是得到loss值,然后反向传播去更新 w w w,因为 w x = f wx=f wx=f,所以对 w w w求偏导 ∂ f ∂ w \frac {\partial f} {\partial w} ∂w∂f
- 而该模型是即要对 w w w求 ∂ f ∂ w \frac {\partial f} {\partial w} ∂w∂f,也要对 x x x求 ∂ f ∂ x \frac {\partial f} {\partial x} ∂x∂f, w w w和 x x x都要更新
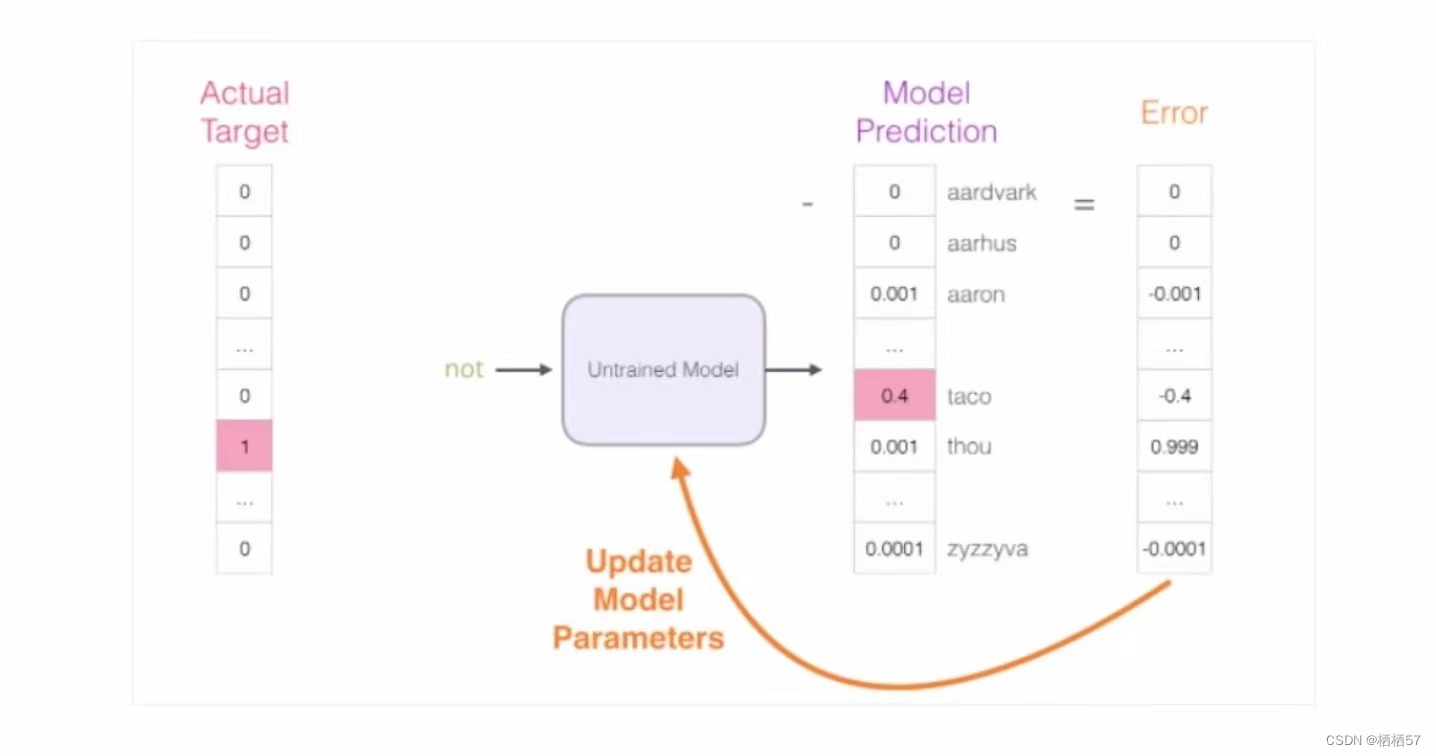
- 对于语料库稍微大一些的,可能的结果太多了,最后一层相当于softmax,计算起来十分耗时
- 下图上半部分表示,not是输入,thou是其输出,但是计算机预测not后面输出的值可能性太多了
- 下图下半部分表示,not thou是输入,输出为thou是not后面词的概率值
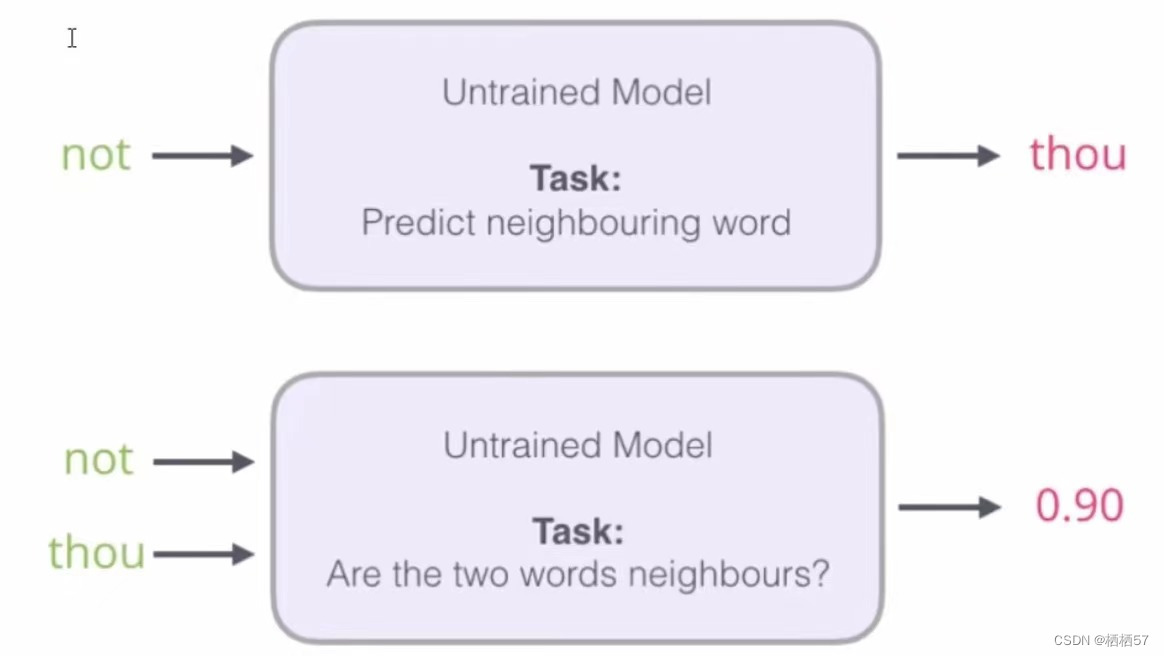
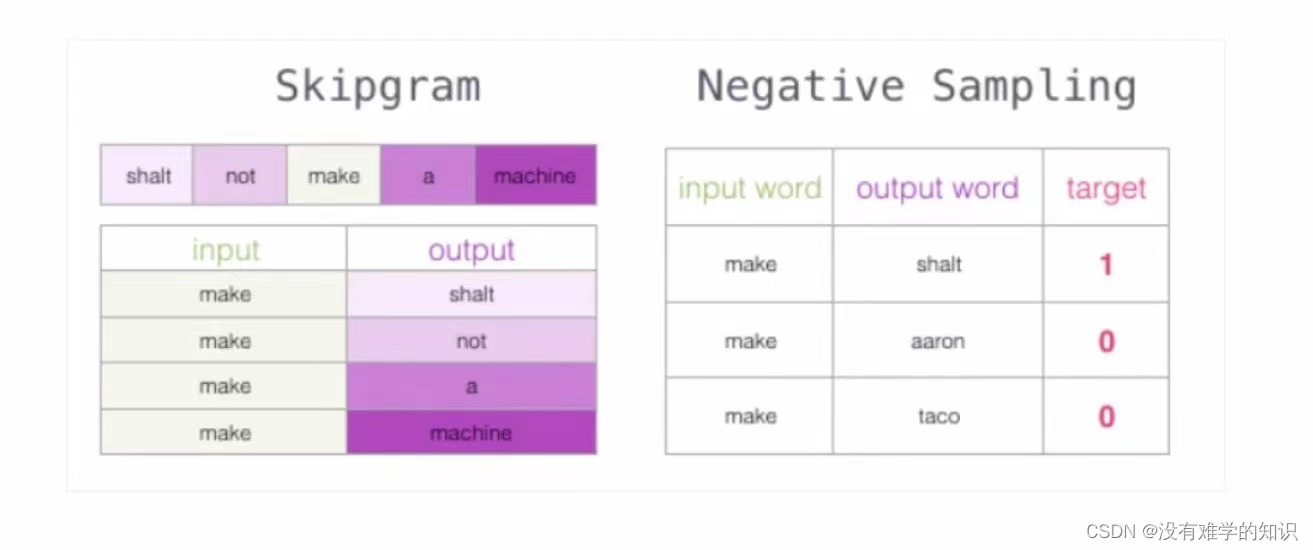
2.2.2负采样方案
- 上述的方案,判断not后面是thou还是不是thou,变成了一个二分类,也就是target值为0或者1,如果一段文字上下文中not后面的值有四种,那么对应到表格中target值就均为1,无法进行较好的训练
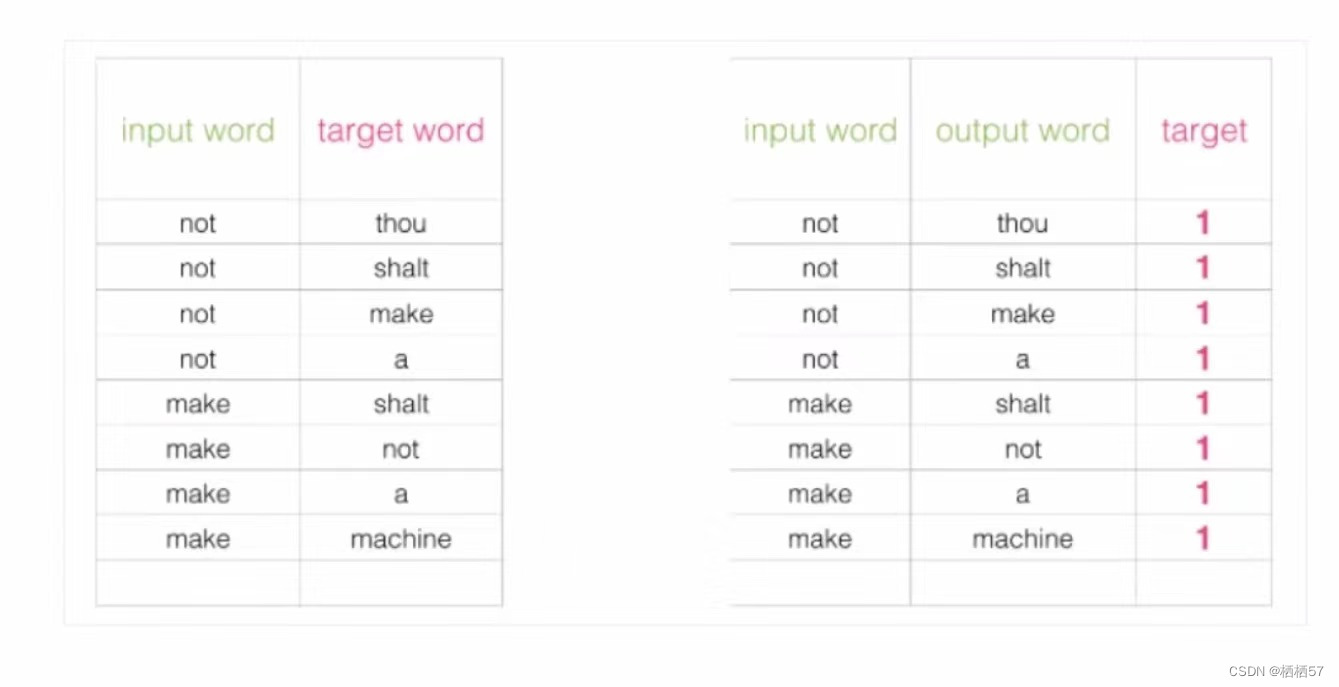
- 改进方案:加入一些负样本(负采样模型)
- 人为的创建一些词,使得target值为0,例如,not 后面不能加I,记为Negative examples负样本、
- 负采样的个数一般5个就行了,因为工具包Gehsim(一个非常好的工具包),默认参数是5个
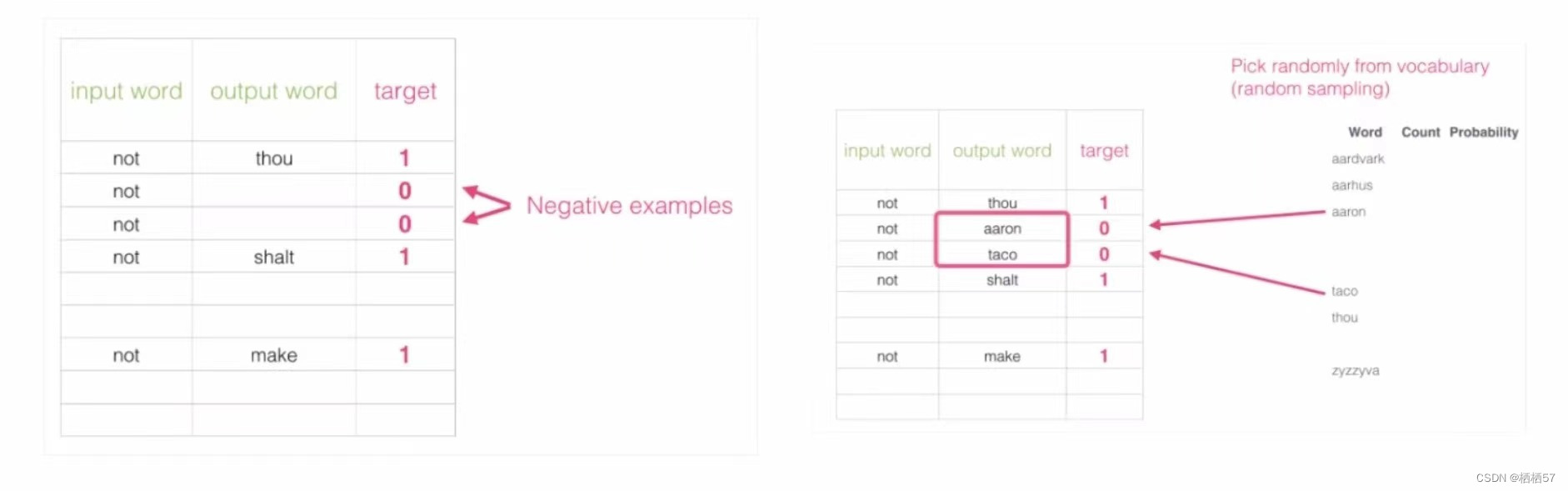
- 如下图左边是原模型训练方案,而右边是我们加入了负样本Negative Sampling
- target进行了改变,1意味着是其后面的单词,0意味着不是后面的单词
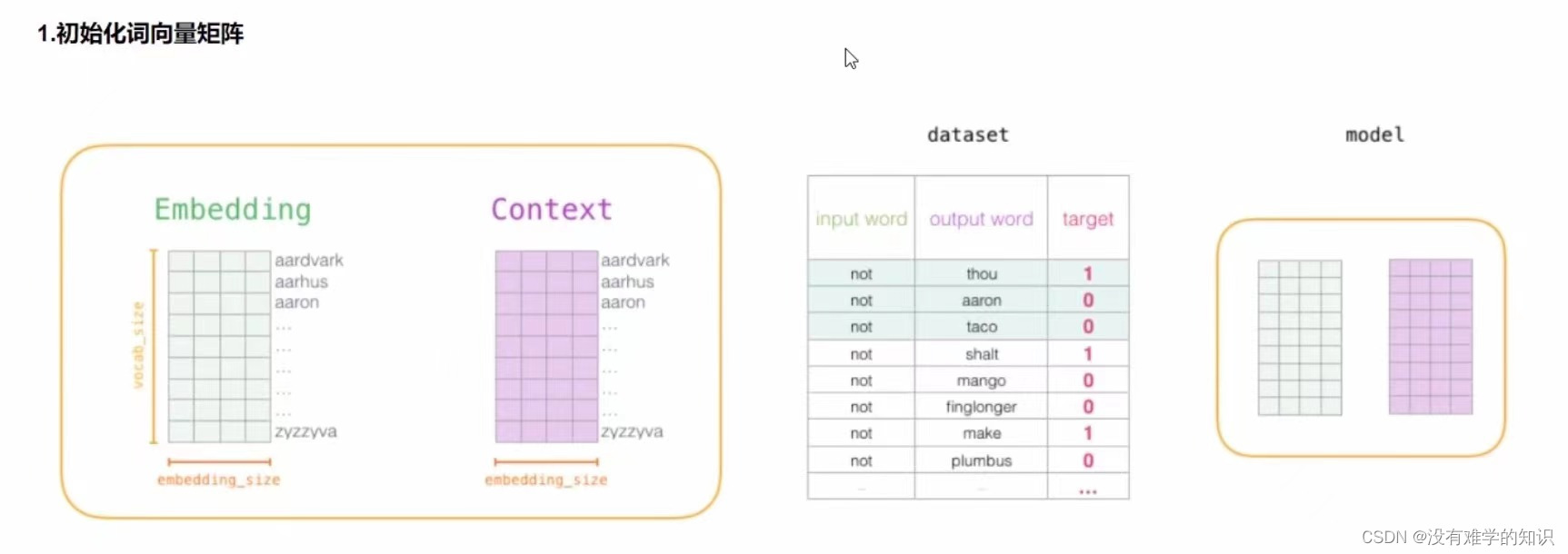
2.2.3词向量训练过程
- 下图左侧绿色的Embedding是词向量大表(意思是有所有的词向量),紫色的Context是对于output
word的一个结果,我们在更新过程中只更新输入
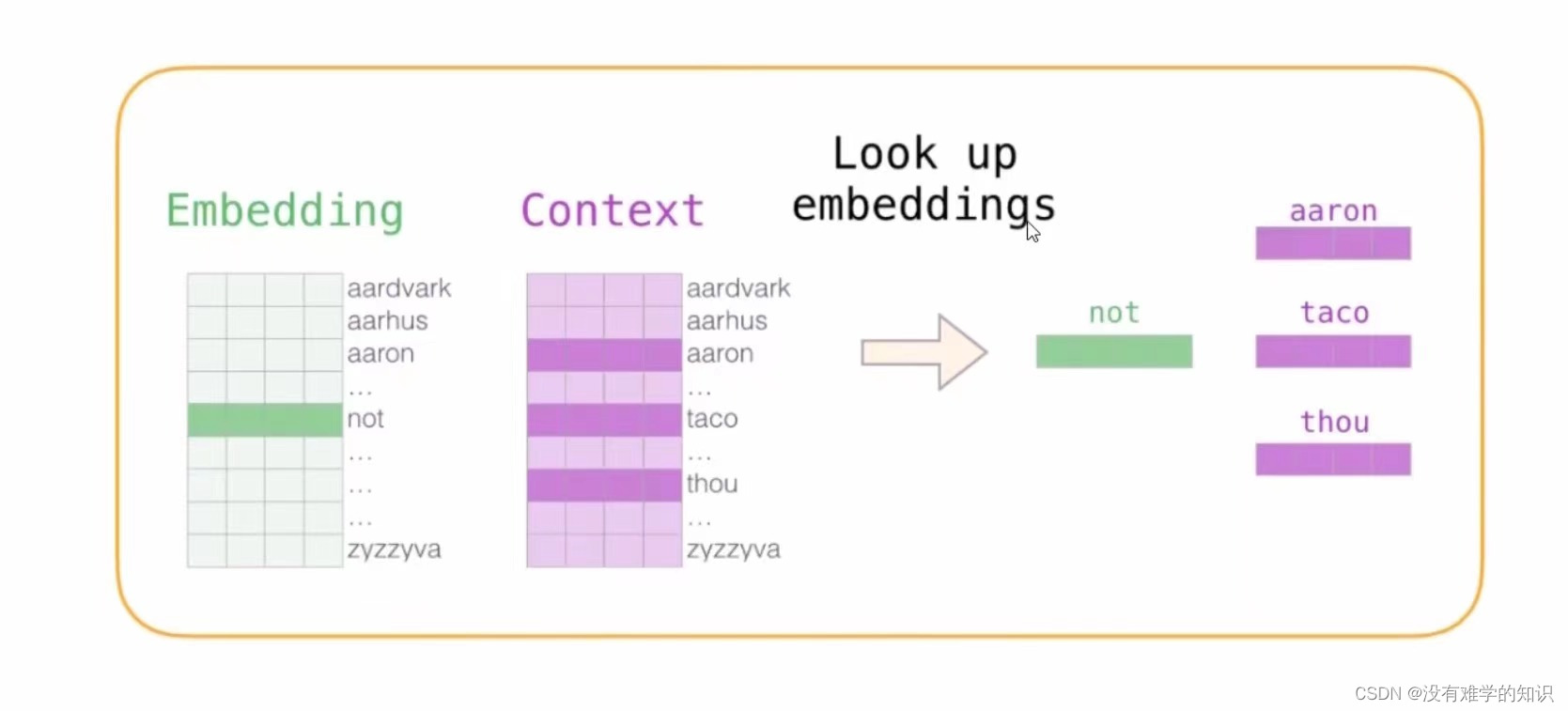
- 下图绿色代表输入,紫色代表输出
- 在不断的训练之后,这个词汇表Embedding就越更新越准,当每个词对应的四维向量训练好了,都迭代更新完了,就相当于Word2Vec就完整的训练好了,每一个词对应向量拿到手了,就相当于完成了词向量模型,最终的目的就是想得到一个词最终用向量表达是什么,
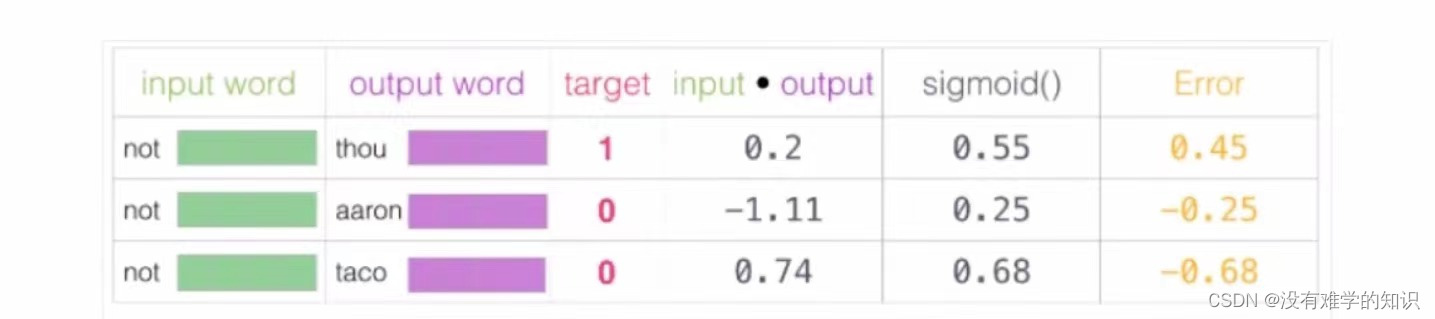
- 再通过神经网络返向传播来计算更新,此时不光更新权重参数矩阵 w w w,也会更新书输入数据
- 下表中input*output是计算神经网络前向传播,sigmoid是二分类任务,Error是当前损失函数的结果,通过Error数值进行反向传播,更新数据 w w w和 x x x
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











