







在深度学习中,反向传播和梯度计算是模型训练的核心。在上一节我们以均方误差作为梯度下降算法的优化准则,以手动求导的方式构建代码。(这太笨了!)那么有什么更优雅的方式来实现函数的自动求导吗?当然有。
这一期我们来学习PyTorch的Autograd模块。
一、Autograd的基本概念
Autograd是PyTorch中的一个核心模块,用于自动计算张量的梯度。它通过构建和维护计算图(Computational Graph),记录每一个操作,从而在进行反向传播时,能够自动、高效地计算梯度。这对于深度学习中的模型训练至关重要,因为梯度是优化算法(如梯度下降)更新模型参数的基础。Autograd的自动微分功能,使得复杂的神经网络训练过程变得更加简便和高效。
计算图
顾名思义,计算图(Computational Graphs)是用于记录运算的图,它的节点(Node)表示数据,如标量,向量,矩阵,边(Edge)表示运算,如加、减、乘、除、卷积等。通过记录所有节点和边的信息,模型可以方便地完成自动求导。
我们用pytorch官网的一个示例来展示计算图的构建过程。
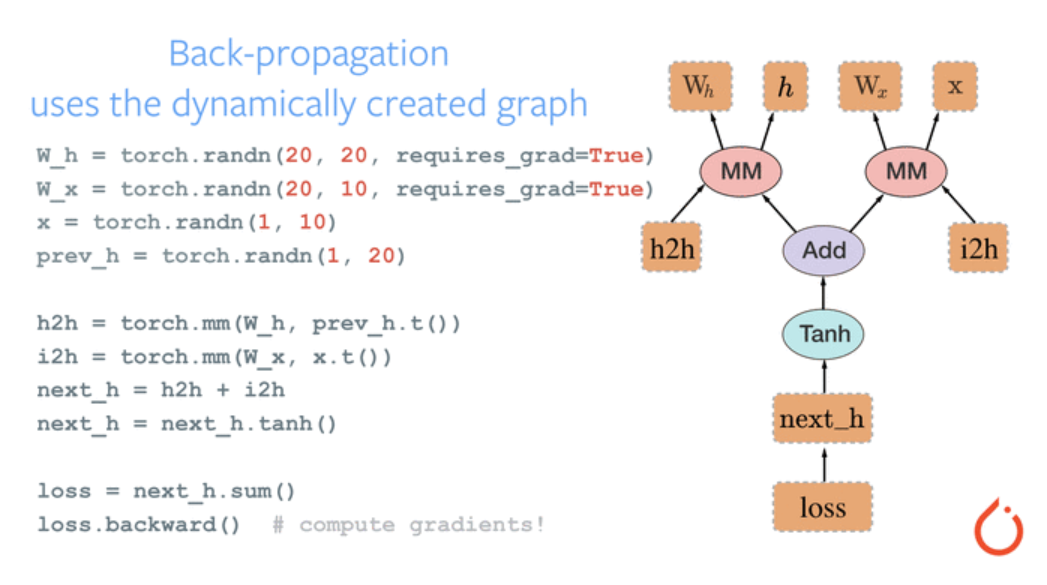
这个图的输入是四个张量
W
h
W_h
Wh,
W
x
W_x
Wx,
x
x
x,
h
h
h,随后调用torch.mm函数进行矩阵相乘分别得到
h
2
h
h2h
h2h,
i
2
h
i2h
i2h,将
h
2
h
h2h
h2h,
i
2
h
i2h
i2h相加并计算双曲正切(tangent hyperbolic)值输出为loss。
计算图有静态图和动态图之分,这一点只要知道pytorch构建的是动态图即可。
张量的梯度属性
细心的你可以发现,在官网给出的示例中
W
h
W_h
Wh,
W
x
W_x
Wx的初始化中特意设置了requires_grad参数,这是为了在反向传播期间计算此张量的梯度。Pytorch主要数据类型为tensor,这里我们有必要介绍tensor数据类型和自动求导相关的属性。
Tensor主要有以下八个主要属性,data,dtype,shape,device,grad,grad_fn,is_leaf,requires_grad。
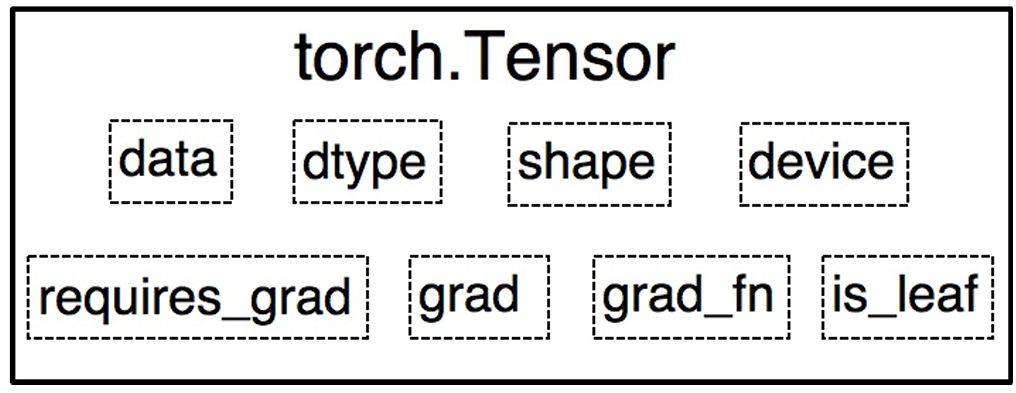
- data:多维数组,是最核心的属性,其他属性都为其服务
- dtype:多维数组的数据类型
- shape:多维数组的形状
- device:tensor所在设备,cpu或cuda
- require_grad:指示是否计算梯度
- grad:对应于data的梯度,形状与data一致
- grad_fn:记录创建该Tensor时用到的Function,在反向传播中使用
- is_leaf:指示张量在计算图中是否为叶子节点,为叶子节点时梯度会被保存,非叶子阶段在反向传播后会被删除
当然Tensor还有很多其他属性,这里我们不再过多介绍。
小结:Autograd的自动求导机制通过有向无环图(directed acyclic graph,DAG)实现,在DAG中记录有数据(tensor.data)和操作(tensor_fn),其中操作在pytorch中统称为Function,包括简单的加减乘除、矩阵运算以及深度学习中的卷积、池化、激活等操作。
二、Autograd的使用
下面我们来介绍Autograd模块是如何编写代码的。如果你有对深度学习的源码有一定接触,那么你一定熟悉loss.backward()这行代码,loss就是模型所构建的损失函数计算结果,是一个张量类型,通过backward接口进行反向梯度计算,这个属性实际上就是在调用Autograd的backward函数。
torch.autograd.backward
backward()函数是使用频率最高的自动求导函数。函数调用如下
torch.autograd.backward(
tensors,
grad_tensors=None,
retain_graph=None,
create_graph=False,
inputs=None
)
- tensor:一个包含一个或多个标量张量或一个张量列表的序列,代表需要计算梯度的损失值或输出值。
- grad_tensors: 与 tensors 中的张量对应的梯度。雅可比向量积中使用,详细见后续代码示例。
- create_graph:是否创建计算图来计算更高阶的导数,在需要计算更高阶导数时使用。
- inputs:指定需要计算梯度的输入张量。如果提供了此参数,只有列出的这些张量的梯度会被计算。
示例一:使用 retain_graph参数
import torch
# 创建张量并设置requires_grad=True
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
# 定义计算
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b) # y = (w + x) * (w + 1)
# 第一次反向传播,保留计算图
y.backward(retain_graph=True)
print("第一次反向传播后的w.grad:", w.grad) # 输出: tensor([5.])
# 第二次反向传播
y.backward()
print("第二次反向传播后的w.grad:", w.grad) # 输出: tensor([10.])
#在这个示例中,
#第一次调用 y.backward(retain_graph=True) 保留了计算图,
#所以我们可以再次调用 y.backward() 进行第二次反向传播。
#每次调用 backward 时,梯度会累加到 w.grad 中。
示例二:使用 grad_tensors参数
import torch
# 创建张量并设置requires_grad=True
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
# 定义计算
a = torch.add(w, x) # a = w + x
b = torch.add(w, 1) # b = w + 1
y0 = torch.mul(a, b) # y0 = (w + x) * (w + 1)
y1 = torch.add(a, b) # y1 = (w + x) + (w + 1)
# 合并结果
loss = torch.cat([y0, y1], dim=0) # [y0, y1]
# 定义外部梯度
grad_tensors = torch.tensor([1., 2.])
# 计算梯度
loss.backward(gradient=grad_tensors)
print("使用grad_tensors后的w.grad:", w.grad) # 输出: tensor([9.])
#在这个示例中,
#我们计算了两个标量 y0 和 y1,并将它们合并为一个张量 loss。
#然后,使用 grad_tensors 参数提供了外部梯度 [1., 2.]。
#在调用 loss.backward(gradient=grad_tensors) 后,w.grad 的值是 9,
#这表明 w 的梯度计算考虑了 grad_tensors 的权重。
三、实战训练
现在,我们利用所学知识对上一篇推文的线性拟合代码进行优化完善。可以对比上一篇推文的实战代码看看具体改变了哪里,会对autograd模块有更加深刻的理解。
import torch
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt
def DataLoader(path):
# 加载数据
df = pd.read_csv(path, header=None)
x = df.iloc[:, 0].values
y = df.iloc[:, 1].values
return x, y
def get_J(x, y, b1, b0):
# 计算损失函数
h = b1 * x + b0
delta2 = (y - h) ** 2
J = torch.mean(delta2) / 2
return J
def main():
# 超参设置
alpha = 0.0008
epoch = 4000
path = './Data_Test2/Data/data.csv'
x, y = DataLoader(path)
# 转换为 PyTorch 张量
x = torch.tensor(x, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32)
# 初始化参数,并设置 requires_grad=True 以便自动求导
b1 = torch.tensor(1.0, requires_grad=True)
b0 = torch.tensor(0.3, requires_grad=True)
# 列表存放每轮的损失,以便绘图
l = []
e = []
loss = get_J(x, y, b1, b0).item()
l.append(loss)
ep = 0
e.append(ep)
# 梯度下降
for i in tqdm(range(epoch)):
e.append(i + 1)
# 计算损失
loss = get_J(x, y, b1, b0)
# 反向传播计算梯度
loss.backward()
# 更新参数
with torch.no_grad():
b1 -= alpha * b1.grad
b0 -= alpha * b0.grad
# 清除梯度
b1.grad.zero_()
b0.grad.zero_()
# 记录损失
l.append(loss.item())
plt.plot(e, l)
plt.title('Loss vs. Epoch')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
if __name__ == '__main__':
main()















 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









