






1.下载yolo模型
下载yolo模型需要进入github官网下载,但是这网站有时候进的去,有时候又进不去。
1.1解决无法访问github网站的问题
反正我是经常遇到下面这种情况
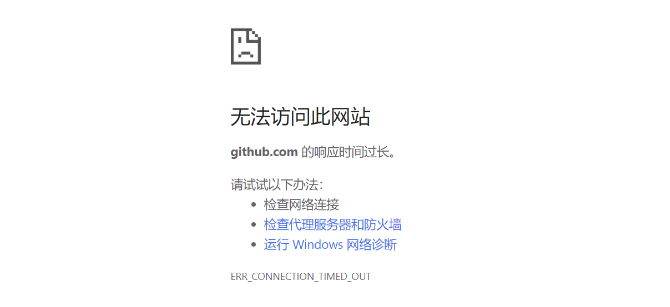
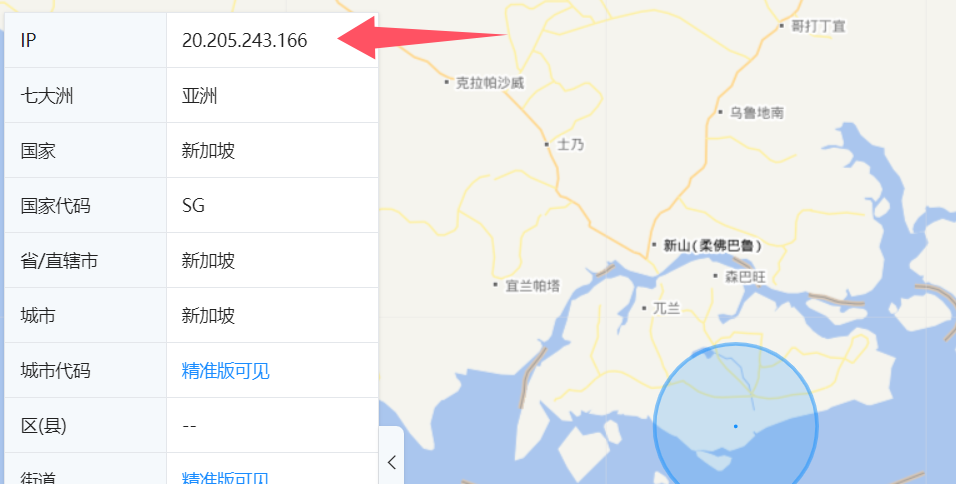
解决方法:1.首先进入这个网址: IP/服务器github.com的信息-站长工具 获取IP地址。
2.其次,通过第一步获得IP地址之后,Ubuntu系统:sudo vim /etc/hosts打开hosts文件,电脑是Windows系统:打开 C:\Windows\System32\drivers\etc 找到hosts文件,将对应的Host地址修改为(要以管理员的身份修改):
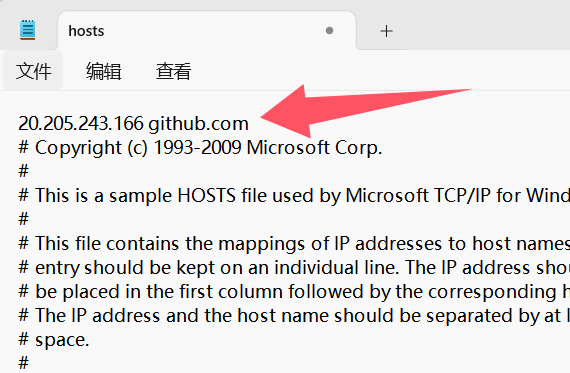
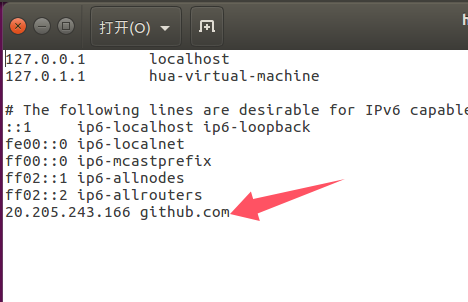
更改完成后,打开命令提示符(cmd),刷新DNS,每次进不去github时候就刷新,虚拟机和Windows下都要刷新,Windows和ubuntu的刷新分别如下,如果还进不了那就下载别的软件吧。
ipconfig /flushdnssudo systemctl restart NetworkManager1.2下载yolov5-6.0
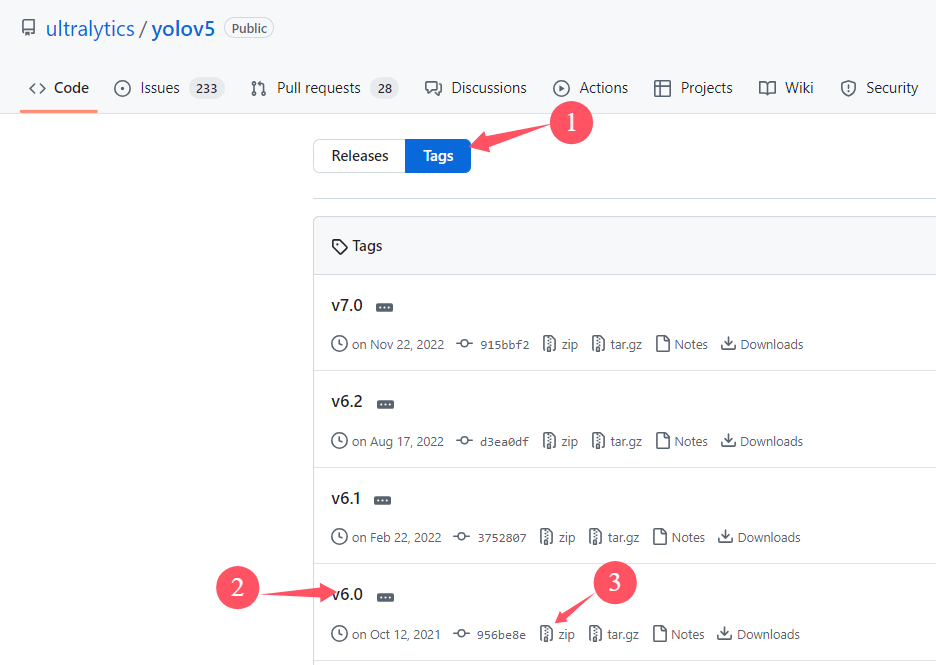
进入官网github.com/ultralytics/,往下拉点击这个yolov5,目前3516dv300支持v5,如果想要部署yolov8,yolov11可以使用其他的板子哈(例如hi3516dv500)。
1.3 连接服务器上传yolo文件
第一步:用pycharm打开刚刚下载好的文件,然后点击设置, 选择ssh配置连接服务器,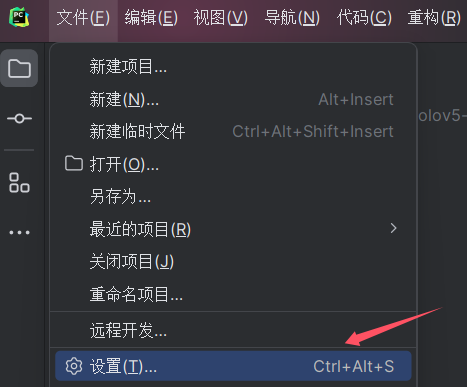
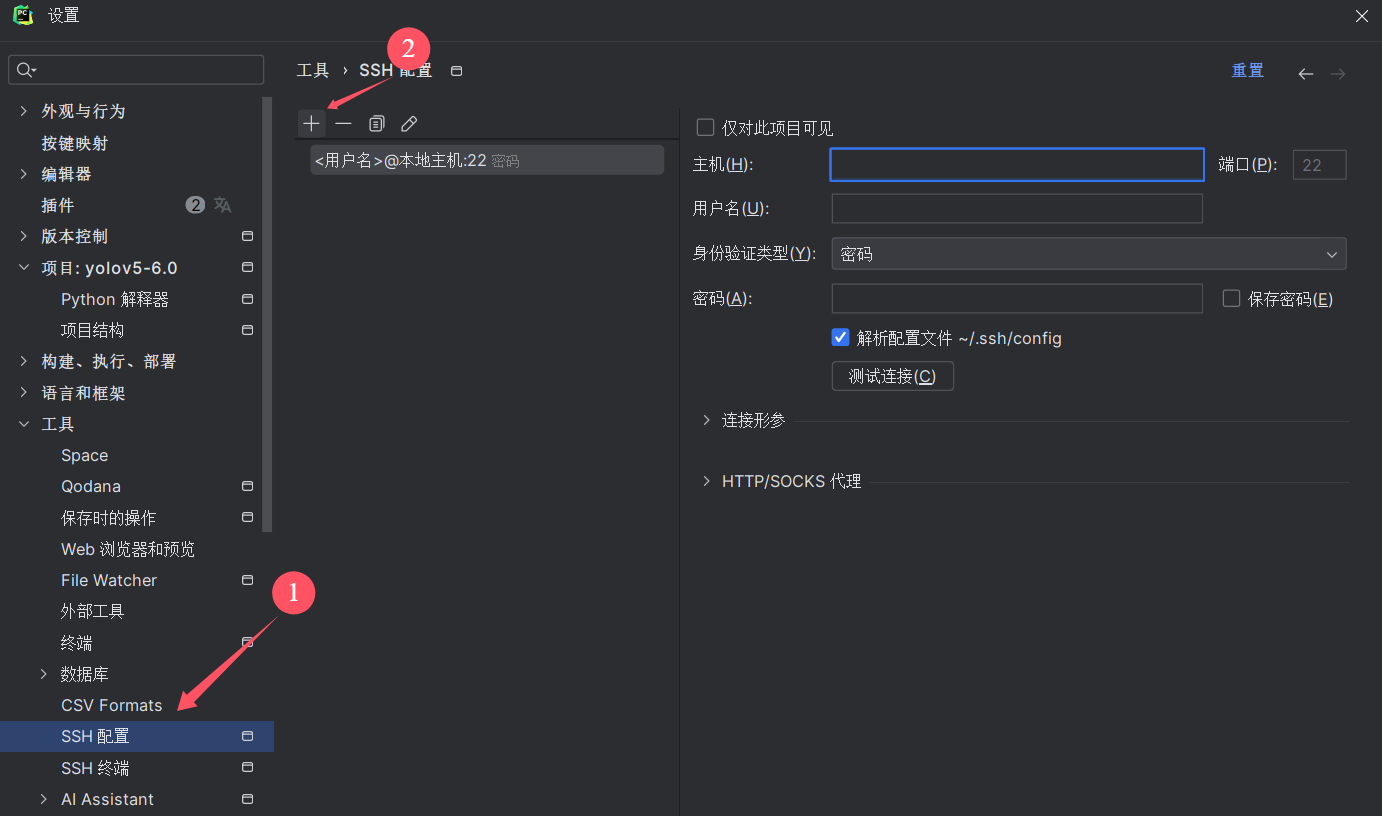
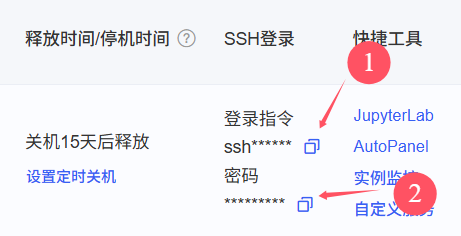
复制好以后的主机这么长一串,15579就是端口号,ssh -p不需要了删了,设置好以后点测试连接能连上就行了,然后点击右下角的应用。
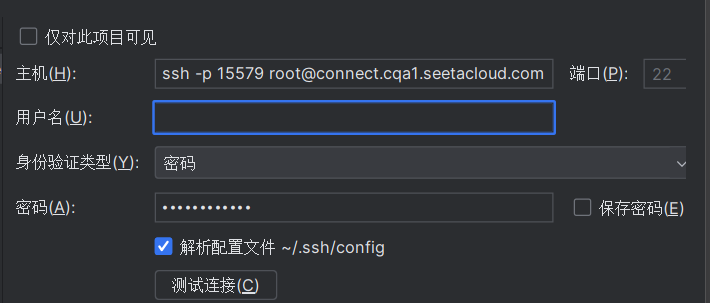
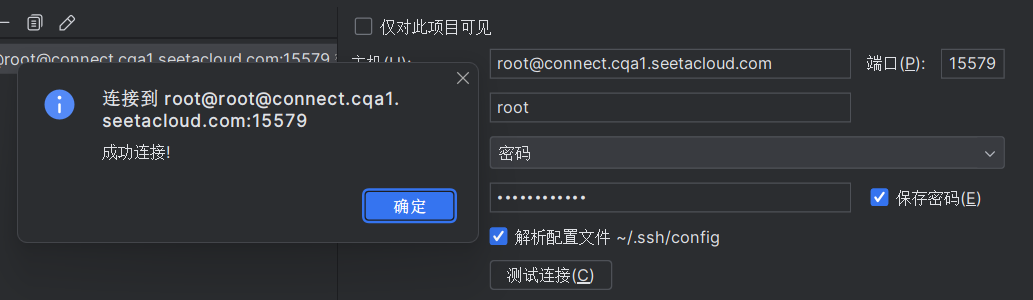
第二步:添加解释器,点击ssh连接,点击现有的,就是我们第一步添加的,然后下一步。
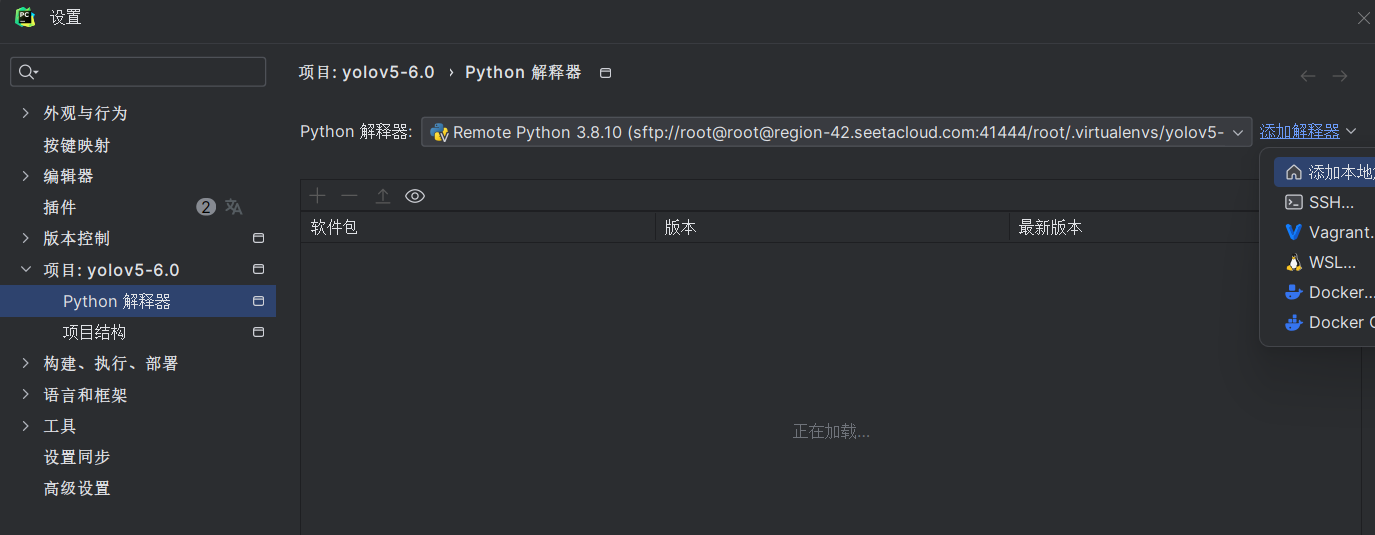
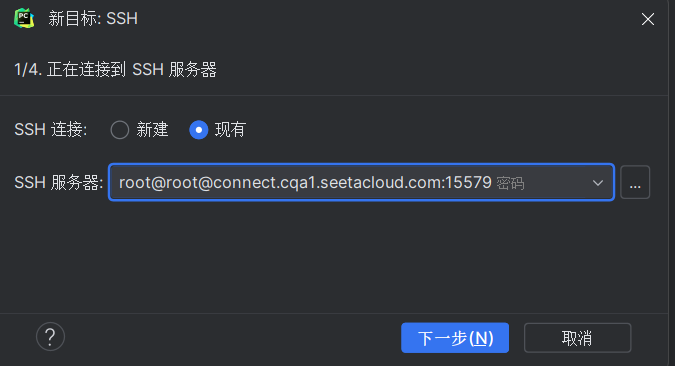
可以能会出现这种情况
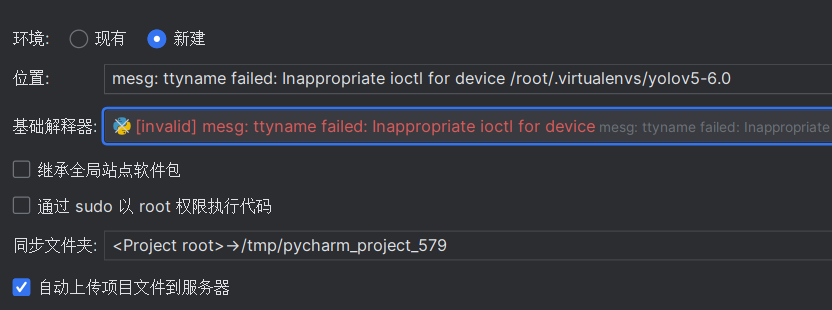
解决办法:进入要登入的服务的用户目录下,把.profile中的mesg n || true改为tty -s && mesg n || true,然后source生效即可,具体什么意思可以搜一下gpt



改完以后记得source,然后再次重新连接就有了解释器了,

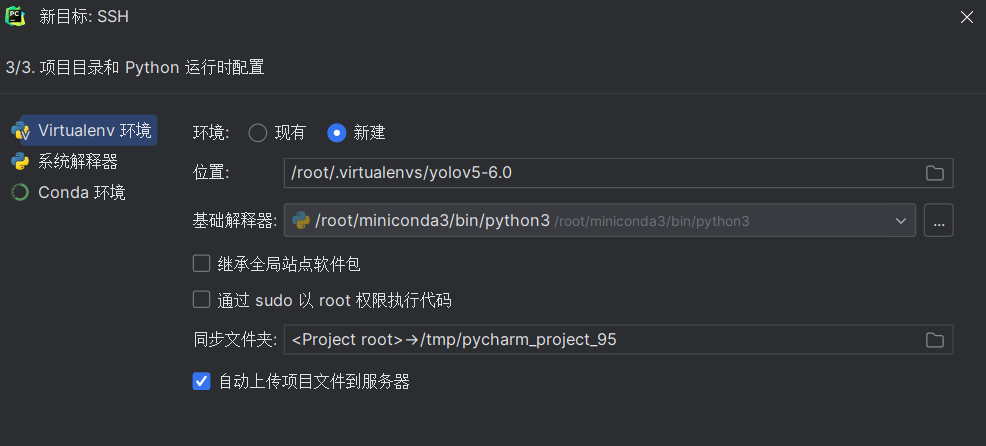
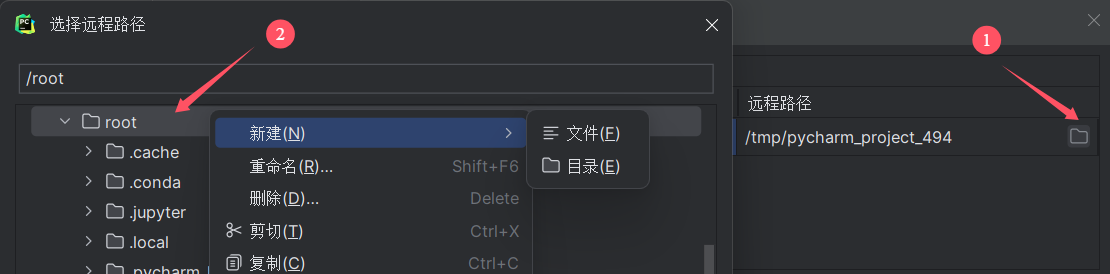
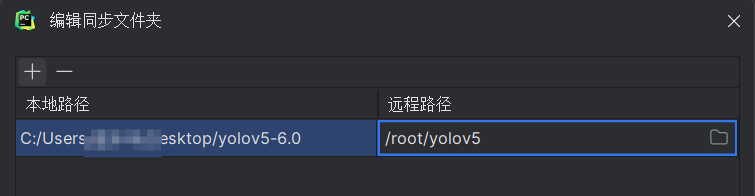
有了基础解释器以后,要创建对应的文件映射关系,就是把本地的文件夹上传到服务器对应的哪个地方,
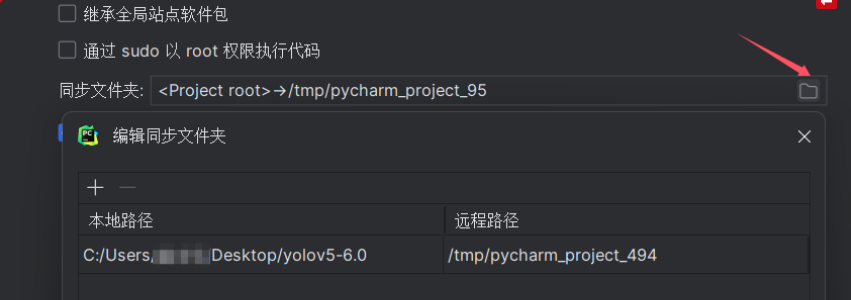
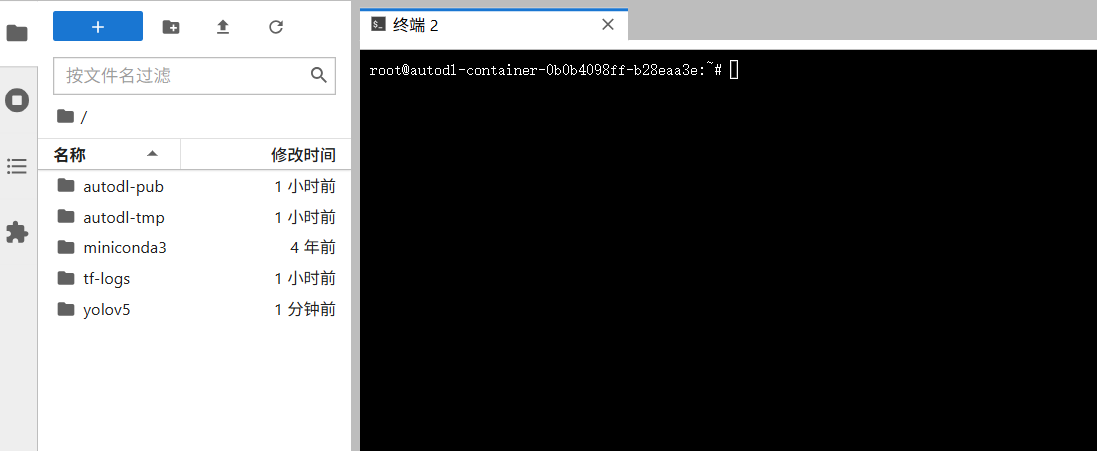
在远程路径下的root下就是用户目录下,新建目录可以命名yolov5,当然在其他地方都可以,我创建在这里只是方便我在jupyter上操作。然后点击确定,创建,应用,完成连接以后,本地文件就会上传到服务器上了。
接下来就可以在jupyter上面操作了
1.4安装环境变量
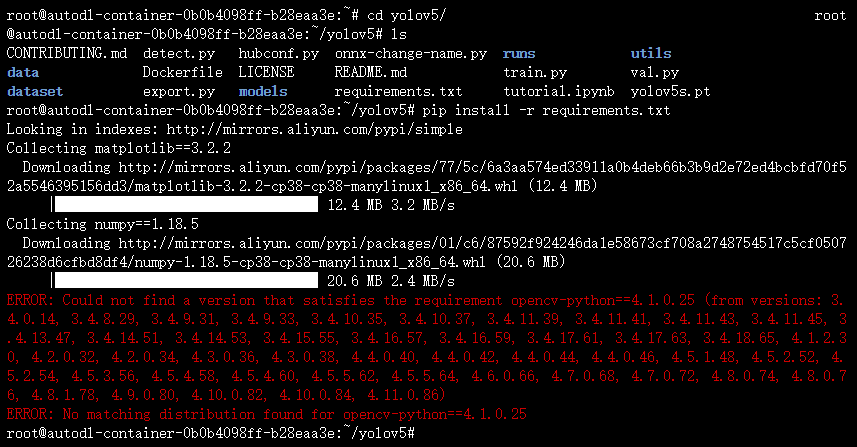
使用pip install -r requirements.txt安装这个库的时候出现一个错误,找不到这个版本的,所以换一个版本,我在requirements.txt里面换了一个opencv-python==4.1.2.30的版本,然后在安装pip install onnx-simplifier==0.3.6这些库是配套的。特别是numpy和onnx,请使用文件中指定的版本。
1.5训练模型
1.5.1配置数据集
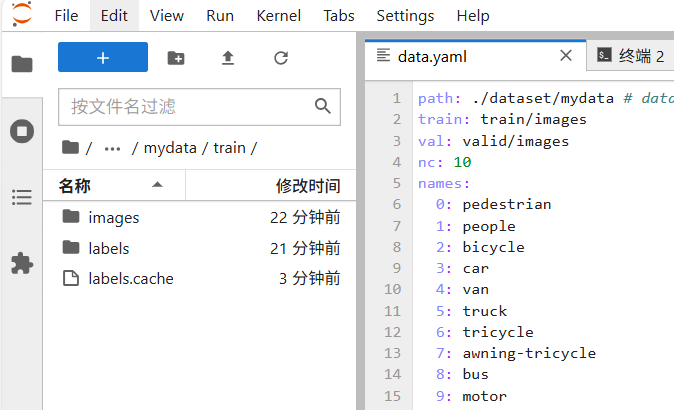
创建目录dataset,然后再下面在创建一个目录mydata放置数据集,data.yaml文件也放在dataset下面,这个文件配置训练模型的数据集的,我选用的数据集是VisDrone2019,

1.5.2修改模型配置
这里主要是将上采样层替换为反卷积层,以适应HI3516平台。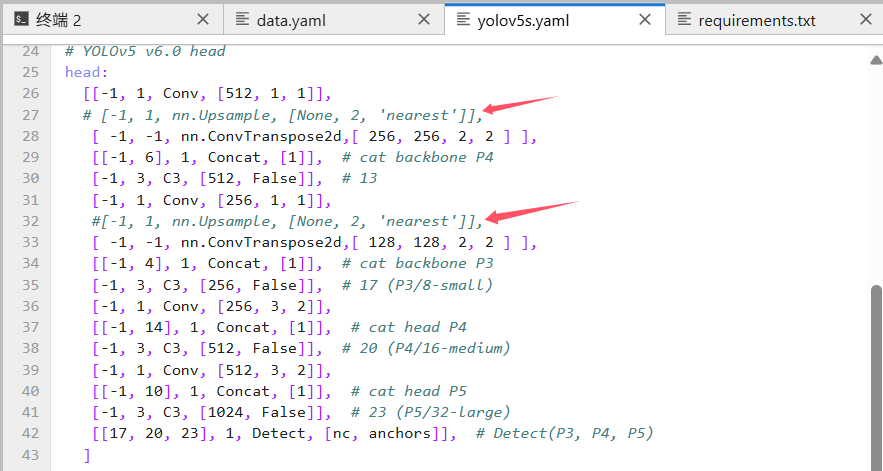
1.5.3训练模型
执行命令python train.py --data ./dataset/mydata/data.yaml --cfg ./models/yolov5s.yaml --epochs 100 --batch-size 8
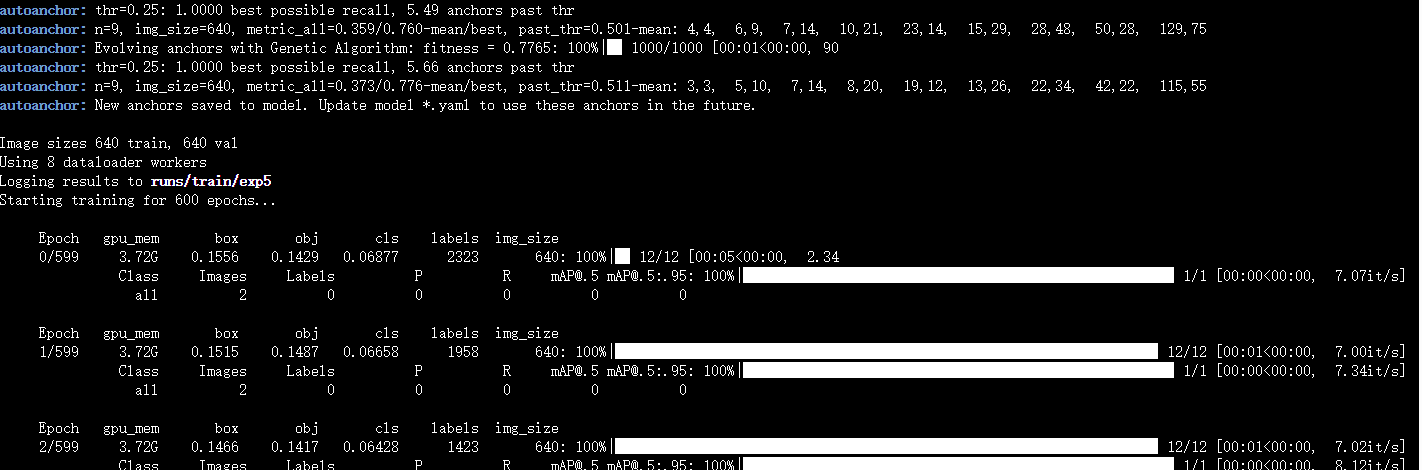
--data:指定数据集配置文件路径,这里使用的是上面修改过的data.yaml文件。--cfg:指定模型配置文件路径,这里使用的是修改过的models目录下的yolov5s.yaml文件。--epochs:指定训练轮次,请根据自身的数据集进行调整。--batch-size:指定批量大小,请根据您的硬件资源和数据集大小进行调整。
1.6pt->onnx
训练完成后,您可以在~/yolov5/runs/train目录下找到最新的训练文件夹(例如exp、exp1等)。打开该文件夹中的weights子文件夹,即可看到模型参数文件best.pt。回到终端。运行python export.py --data ./dataset/mydata/data.yaml --weights ./runs/train/exp7/weights/best.pt --batch 1 --img 640 640 --train --include onnx --opset 10
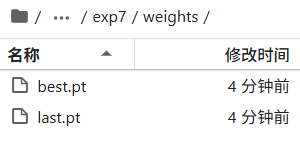
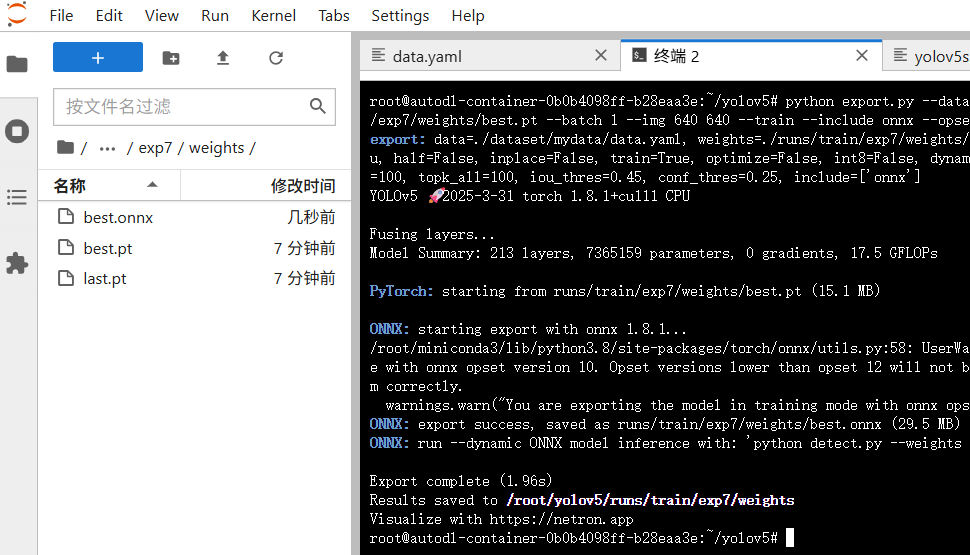
--data:指定数据集配置文件路径,这里使用的是制作的data.yaml文件。--weights:指定要转换的PyTorch模型文件路径,这里是3.3中训练完成后生成的best.pt- 转换完成后,您可以在
./runs/train/exp7/weights目录下看到生成的ONNX文件,文件名为best.onnx。
1.6.1简化模型
进入到训练好的目录下,执行python -m onnxsim best.onnx best-sim.onnx

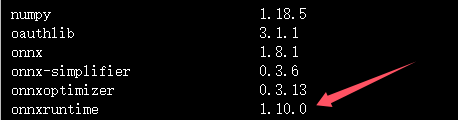
注意事项:但是这里不同版本的python中的pip list中onnxruntime版本不同,有的onnxruntime版本比较高然后就会跟numpy冲突,当时numpy和onnx-simplifier==0.3.6要按照版本,所以,必须要把onnxruntime降级才能简化模型,我这个1.10.0就可以简化模型。
1.6.2onnx神经网络层名称修改
这里需要注意一下,默认转出来的onnx,名称是是含有“.”这个特殊字符的,如果不修正,会在后续caffe->wk转换中出错。因此需要修改下模型的输入输出的名称,如下图所示(这个是参考的别人的错误的name,然后需要改的例子),

import onnx
# 1. 加载ONNX模型
pre_model_path = r"./best-sim.onnx"
post_model_path = r"./best-modifiedsim.onnx"
model = onnx.load(pre_model_path)
# 2. 遍历所有节点,修改name中的`.`为`_`,并打印原始和修改后的名称
for node in model.graph.node:
original_name = node.name # 保存原始名称
modified_name = node.name.replace(".", "_") # 替换为下划线
node.name = modified_name # 更新节点名称
# 打印原始名称和修改后的名称
print(f"Original Name: {original_name}")
print(f"Modified Name: {modified_name}")
print("-" * 30) # 分隔符,方便查看
# 3. 保存修改后的模型
onnx.save(model, post_model_path)
print("Model has been modified and saved.") 我在转换的过程中没有遇到上面错误这种情况转换出来的文件就是下面这样的。所以这个best-modifiedsim.onnx就是我们接下来要操作的文件了。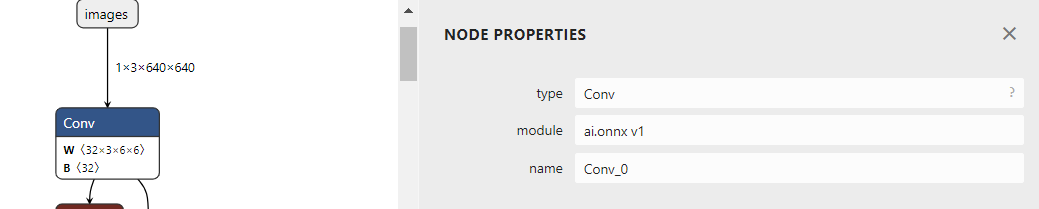

















 2607
2607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









