







从假阳性和假阴性的角度理解评价指标accuracy、precision、Recall、F1
现在有一个基本的二分类问题,就是判断源代码中是否存在漏洞
我们有两个分类器来对应处理该问题,但是我们应该如何判断这两个分类器的优劣好坏呢?
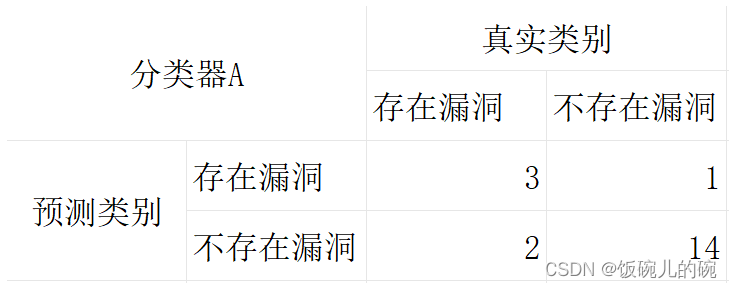
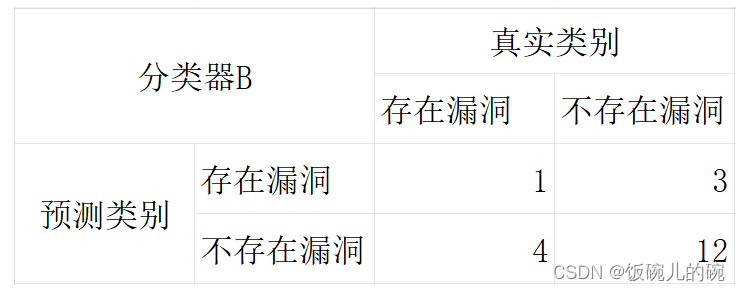
准确度accuracy =(1+12)/(1+3+4+12)
分类器到底分对了多少?
精确度precision =(1)/(1+3)
分类器分出存在漏洞中分正确的占了多少?
召回率Recall =(1)/(1+4)
在真实存在漏洞中分类器分正确了多少?
F1分数 F1 = 2*(precision *Recall )/(precision +Recall )
F1分数的本质是对精确度precision和召回率Recall的调和平均
由此看来,这两个分类器都有相同的特点,我们把它抽象出来,这就是混淆矩阵了
它包含四个主要值,分别是TP、FP、FN、TN

现在我们再来看四个指标的公式分别是什么
准确度accuracy =(TP+TN)/(TP+TN+FP+FN)
精确度precision =(TP)/(TP+FP)
召回率Recall =(TP)/(TP+FN)
F1分数 F1 = 2*(precision *Recall )/(precision +Recall )
假阴性:指的是在进行漏洞检测时,错误地将真正存在漏洞的代码或系统标记为没有漏洞。换句话说,它是指检测结果错误地未能发现真正存在的漏洞的情况
从评估指标上看的话,就是Recall越大,假阴性的概率也就越小
假阳性:指的是在进行漏洞检测时,错误地将不存在漏洞的代码或系统标记为存在漏洞。换句话说,它是指检测结果错误地不是漏洞标记为漏洞也即假漏洞
补充一点,有一种特殊情况是,在最终的评价指标上表现出来的是召回率达到100%,但精准度precision 很低,是由于模型对正例的预测过于激进,导致了大量的假阳性。这种情况通常出现在模型更倾向于将样本预测为正例,而忽略了负例的情况,也就是模型的假阳性极高,假阴性极低
实例分析:
当前有一个关于漏洞检测的二分类问题,假设总样本数为19336
经过分类器的预测分类后,下面是他的混淆矩阵
总结:
假阳性和假阴性是评价指标中的重要概念,对理解accuracy、precision、recall和F1指标的含义非常有帮助。
- 假阳性(False Positive, FP):指模型错误地将负样本预测为正样本的情况。换句话说,模型错误地将实际上是负样本的样本预测为正样本。
- 假阴性(False Negative, FN):指模型错误地将正样本预测为负样本的情况。换句话说,模型错误地将实际上是正样本的样本预测为负样本。
接下来,我们将accuracy、precision、recall和F1指标与假阳性和假阴性联系起来:
-
Accuracy(准确率):是模型正确预测的样本数占总样本数的比例。它可以通过以下公式计算:
Accuracy=(TP+TN)/(TP+TN+FP+FN)
其中,TP是真阳性(模型将正样本预测为正样本的样本数),TN是真阴性(模型将负样本预测为负样本的样本数)。
-
Precision(精确率):是所有被预测为正样本中真正为正样本的比例。它可以通过以下公式计算:
Precision=TP/(TP+FP)
Precision关注的是模型预测为正的样本中,有多少是真正的正样本。
-
Recall(召回率):是所有实际为正样本中被模型预测为正样本的比例。它可以通过以下公式计算:
Recall=TP/(TP+FN)
Recall关注的是模型能够找到所有正样本的能力。
-
F1 Score:是精确率和召回率的调和平均值,可以看作是综合考虑了模型的准确性和召回率。它可以通过以下公式计算:
F1 Score=2×(Precision×Recall)/(Precision+Recall)
F1 Score通常用于评价模型的综合性能,特别是在正负样本不均衡的情况下。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











