










MTransE翻译
阅读时间:2024.03.23
领域:知识图谱,知识对齐
作者:Muhao Chen等人 UCLA
出处:IJCAI
Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment
用于交叉知识对齐的多语言知识图谱嵌入(MTransE)
Abstract
最近的许多工作已经证明了知识图谱嵌入在完成单语知识图谱方面的好处。由于相关的知识库是用几种不同的语言构建的,因此实现跨语言知识对齐将有助于人们构建连贯的知识库,并帮助机器处理不同人类语言之间实体关系的不同表达。不幸的是,通过人工实现这种高度期望的跨舌对齐是非常昂贵且容易出错的。因此,我们提出了 M T r a n s E MTransE MTransE,一个基于推理的多语言知识图谱嵌入模型,以提供一个简单和自动化的解决方案。通过在单独的嵌入空间中编码每种语言的实体和关系, M T r a n s E MTransE MTransE为每个嵌入向量提供了到其他空间中的跨语言对应物的转换,同时保留了单语嵌入的功能。我们部署了三种不同的技术来表示跨语言的过渡,即轴校准,平移向量和线性变换,并得出五个变种 M T r a n s E MTransE MTransE使用不同的损失函数。我们的模型可以在部分对齐的图上进行训练,其中只有一小部分三元组与跨语言对应项对齐。跨语言实体匹配和三重对齐验证的实验显示了良好的效果,一些变体在不同的任务中始终优于其他变体。我们还探讨了 M T r a n s E MTransE MTransE如何保留其单语对应物 T r a n s E TransE TransE的关键属性。
1 Introduction
多语言知识库,如 W i k i p e d i a Wikipedia Wikipedia[Wikipedia,2017], W o r d N e t WordNet WordNet [Bond and Foster,2013]和 C o n c e p t N e t ConceptNet ConceptNet [Speer and Havasi,2013]正在成为人们和AI相关应用程序的重要知识来源。这些知识库被建模为知识图谱,存储两个方面的知识:单语知识,包括以三元组形式记录的实体和关系,以及跨语言知识,在各种人类语言中匹配单语知识。
单语知识的覆盖问题已经得到了广泛的解决,并且用于完成单语知识库的基于解析的技术在过去已经得到了很好的研究[Culotta和Sorensen,2004; Zhou等人,2005; Sun等人,2011年]。最近,基于嵌入的技术得到了很大的关注,它提供了在低维嵌入空间中对实体进行编码的简单方法,并将关系捕获为实体向量之间的转换手段。给定一个三元组 ( h , r , t ) (h, r, t) (h,r,t),其中 r r r 是实体 h h h 和 t t t 之间的关系,则 h h h 和 t t t 分别表示为两个 k k k 维向量 h h h 和 t t t。函数 f r ( h , t ) f_r(\mathbf{h},\mathbf{t}) fr(h,t) 用于度量 ( h , r , t ) (h, r, t) (h,r,t)的可扩展性,这也意味着表征 r \mathbf r r 的变换 r r r。示例性地,基于预防的模型TransE[Bordes等人,2013]使用损失函数 f r ( h , t ) = ∥ h + r − t ∥ 1 f_r(\mathbf{h},\mathbf{t})~=~\|\mathbf{h}+\mathbf{r}-\mathbf{t}\|~^1 fr(h,t) = ∥h+r−t∥ 1,其中 r \mathbf r r 被表征为从知识图中的潜在连接模式学习的平移向量。该模型提供了一种灵活的方法来预测三元组中的缺失项,或验证生成的三元组的有效性。其他作品如 T r a n s H TransH TransH [Wang et al.,2014]和 T r a n s R TransR TransR [Lin等人,2015],引入了不同的损失函数,以其他形式表示关系翻译,并在完成知识图谱方面取得了可喜的成果。
虽然基于嵌入的技术可以帮助提高单语知识的完整性,但将这些技术应用于跨语言知识的问题在很大程度上尚未探索。这些知识,包括匹配相同实体的语言间链接(ILLs)和表示相同关系的三重对齐(TWA),对于同步独立发展的知识库的不同语言特定版本非常有帮助,因为需要进一步改进构建在知识库上的应用程序,例如问答系统,语义Web和Web搜索。尽管它的重要性,这种跨语言的知识基本上仍然完好无损。事实上,在最成功的知识库维基百科中,我们发现ILL覆盖了不到15%的实体对齐。
利用知识图谱嵌入跨语言知识无疑提供了一种通用的方法来帮助提取和应用这些知识。然而,这是一个不平凡的任务找到一种易于处理的技术来捕捉跨语言的过渡。这种转换比关系翻译更难捕获,原因有几个:(i) 跨语言转换比任何单语言关系翻译都具有更大的域;(ii) 它适用于实体和关系,这些实体和关系在不同语言之间具有不连贯的词汇表;(iii) 用于训练这种转换的已知对齐通常占知识库的一小部分。此外,单语知识图结构的特征必须得到很好的保留,以确保要对齐的知识的正确表示。
为了解决上述问题,我们提出了一个多语言知识图谱嵌入模型 M T r a n s E MTransE MTransE,使用两个组件模型,即知识模型和对齐模型的组合来学习多语言知识图结构。知识模型以特定语言版本的知识图对实体和关系进行编码。我们探索的方法,组织每个语言特定的版本在一个单独的嵌入空间,其中 M T r a n s E MTransE MTransE采用 T r a n s E TransE TransE作为知识模型。最重要的是,对齐模型在不同的嵌入空间中学习实体和关系的跨语言转换,其中考虑了以下三种跨语言对齐的表示:基于距离的轴校准,平移向量和线性变换。因此,我们得到五个变种的 M T r a n s E MTransE MTransE基于不同的损失函数,并确定最好的变种,通过比较它们的跨语言对齐任务使用两个部分对齐的三语图从维基百科三元组构建。我们还表明, M T r a n s E MTransE MTransE执行以及其单语对应 T r a n s E TransE TransE单语任务。
本文的其余部分组织如下。我们首先讨论相关的工作,然后在下面的部分介绍我们的方法。最后给出了实验结果,并对本文进行了总结。
2 Related Work
虽然据我们所知,以前没有关于学习多语言知识图嵌入的工作,但我们将描述与此主题密切相关的接下来的三个工作。
**知识图谱嵌入。**最近,在使用基于推理的方法来训练单语知识图嵌入方面取得了重大进展。为了表征三元组 ( h , r , t ) (h, r, t) (h,r,t),这个族的模型遵循一个共同的假设 h r + r ≈ t r \mathbf{h}_r+\mathbf{r}\approx\mathbf{t}_r hr+r≈tr,其中 h r \mathbf{h}_r hr和 t r \mathbf{t}_r tr是 h h h 和 t t t 的原始向量,或者在一定的变换下,w.r.t.关系 r r r。先驱者TransE [Bordes等人,2013]将 h r \mathbf{h}_r hr和 t r \mathbf{t}_r tr设置为原始 h \mathbf{h} h和 t \mathbf{t} t,并且在处理一对一关系方面取得了令人满意的结果。后来的工作通过在实体上引入关系特定的变换以获得不同的 h r \mathbf{h}_r hr和 t r \mathbf{t}_r tr,包括在 T r a n s H TransH TransH中的关系特定的超平面上的投影,来改进多映射关系上的 T r a n s E TransE TransE [Wang等人,2014], T r a n s R TransR TransR中异构关系空间的线性变换[Lin等人,2015], T r a n s D TransD TransD中的动态矩阵[Ji等人,2015]和其他形式[Jia等人,2016年; Nguyen等人,2016年]。所有这些 T r a n s E TransE TransE的变体都为不同的关系专门化了实体嵌入,因此以增加模型复杂性为代价提高了多映射关系的知识图完成。同时,基于预防的模型与其他模型有很好的协同性。例如, T r a n s E TransE TransE的变体与词嵌入相结合,以帮助从文本中提取关系[Weston等人,2013; Zhong等人,2015年]。
除此之外,还有一些非基于翻译的方法。其中一些方法,包括 U M UM UM[Bordes等人,2011]、 S E SE SE[Bordes等人,2012]、 B i l l i n e d Billined Billined[Jenatton等人,2012]和 H o l e Hole Hole[Nickel等人,2016],并不显式表示关系嵌入。其他模型包括基于神经的模型 S L M SLM SLM[Collobert and Weston,2008]和 N T N NTN NTN[Socher等人,2013],以及基于随机行走的模型 T A D W TADW TADW[Yang等人,2015A],它们对结构化和文本语料库都具有表现力和适应性,但过于复杂,无法纳入支持多语言知识的体系结构。
**多语种单词嵌入。**有几种方法学习平行文本语料库上的多语种单词嵌入。其中一些可以扩展到多语言知识图,例如 L M LM LM[Mikolov等人,2013]和 C C A CCA CCA[Faruqui和Dyer,2014],它们分别以线性变换和典型相关分析的形式在预训练的单语嵌入之间诱导离线转换。这些方法没有通过校准或与对齐模型联合训练来调整不一致的向量空间,因此在知识图上不能很好地执行,因为并行性只存在于很小一部分。一种更好的方法 O T OT OT[Xing等人,2015]联合学习了正则化嵌入和正交变换,但由于单语向量空间的不一致性和实体之间关系的巨大多样性,这被发现过于复杂。
**知识库对齐。**一些项目在知识库中进行跨语种对齐,代价是广泛的人工参与和为特定应用程序设计手工制作的功能。 W i k i d a t a Wikidata Wikidata[Vrandeˇci´,2012年]和 D B p e d i a DBpedia DBpedia[Lehmann等人,2015]依靠众包来制造弊病和关系调整。 Y a g o Yago Yago[Mahdisoltani等人,2015]挖掘已知比赛的关联规则,其中结合了许多自信的分数,需要广泛的微调。许多其他作品需要图表外部的来源,从良好的模式或本体[Nguyen等人,2011;Suchanek等人,2011;Rinser等人,2013]到实体描述[Yang等人,2015b],这对许多知识库来说是不可用的,如 Y a g o Yago Yago、 W o r d N e t WordNet WordNet和 C o n c e p t N e t ConceptNet ConceptNet[Speer和Havasi,2013]。这样的方法还涉及复杂的模型依赖关系,这些依赖关系不容易处理和可重用。相比之下,基于嵌入的方法简单而通用,几乎不需要人工参与,并生成可用于其他NLP任务的独立于任务的特征。
3 Multilingual Knowledge Graph Embedding
在此,我们从多语言知识图的形式化开始我们的建模。
3.1 Multilingual Knowledge Graphs
在知识库中,我们用 L \mathcal L L来表示语言的集合,用 L 2 \mathcal{L}^2 L2来表示 L \mathcal L L的2-组合(即无序语言对的集合)。对于语言 L ∈ L L\in \mathcal L L∈L, G L G_L GL表示 L L L的语言专用知识图, E L E_L EL和 R L R_L RL分别表示实体表示和关系表示的对应词汇。 T = ( h , r , t ) T=(h, r, t) T=(h,r,t)表示 G L G_L GL中的三元组,使得 h , t ∈ E L h, t\in E_L h,t∈EL和 r ∈ R L r\in R_L r∈RL。粗体 h , r , t \mathbf{h}, \mathbf{r}, \mathbf{t} h,r,t分别表示头 h h h、关系 r r r和尾 t t t的嵌入向量。对于语言对 ( L 1 , L 2 ) ∈ L 2 , δ ( L 1 , L 2 ) (L_1,L_2)\in \mathcal{L}^2, \delta(L_1,L_2) (L1,L2)∈L2,δ(L1,L2)表示包含已经在 L 1 L_1 L1和 L 2 L_2 L2之间对齐的三元组对的对齐集合。例如,在英语和法语中,我们可能有((加利福尼亚州,首府,萨克拉门托),(Etat de California,Capale,Sacramento)) ∈ δ \in\delta ∈δ(英语,法语)。对齐集通常存在于多语言知识库中的一小部分[VrandeˇCi‘c,2012年;Mahdisoltani等人,2015年;Lehmann等人,2015年],这是我们希望扩展的知识的一部分。
我们的模型由两个组件组成,它们在知识库的两个方面进行学习:知识模型对来自每种语言特定的图结构的实体和关系进行编码,对齐模型从现有对齐学习跨语言转换。我们为 L 2 \mathcal L^2 L2中具有非空对齐集的每一种语言对定义一个模型。因此,对于具有两种以上语言的知识库,一组模型构成了解决方案。在下面,我们使用语言对 ( L i , L j ) ∈ L 2 (L_i,L_j)\in\mathcal{L}^2 (Li,Lj)∈L2作为示例来描述我们如何定义模型的每个组件。
3.2 Knowledge Model
对于每一种语言 L ∈ L L\in\mathcal L L∈L,都分配了一个专门的 k k k-维嵌入空间 R L k \mathbb{R}_L^k RLk来表示 E L E_L EL和 R L R_L RL的向量,其中 R \mathbb R R是实数域。我们对涉及到的每一种语言都采用了基于翻译的基本翻译方法,通过在不同的关系上下文中统一地表示嵌入,从而有利于跨语言任务。因此,其损失函数如下:
S K = ∑ L ∈ { L i , L j } ∑ ( h , r , t ) ∈ G L ∥ h + r − t ∥ S_K=\sum_{L\in\{L_i,L_j\}}\sum_{(h, r, t)\in G_L}\|\mathrm{\mathbf h+\mathbf r -\mathbf t}\| SK=L∈{Li,Lj}∑(h,r,t)∈GL∑∥h+r−t∥
它衡量了所有给定三元组的似是而非。通过最小化损失函数,知识模型保留了实体之间的单语关系,同时也作为对齐模型的正则化。同时,该知识模型将知识库划分为可并行训练的互不相交的子集。
3.3 Alignment Model
配准模型的目标是构造LI和LJ向量空间之间的转换。其损失函数如下:
S A = ∑ ( T , T ′ ) ∈ δ ( L i , L j ) S a ( T , T ′ ) S_A=\sum_{(T,T')\in\delta(L_i,L_j)}S_a(T,T') SA=(T,T′)∈δ(Li,Lj)∑Sa(T,T′)
其对齐分数 S a ( T , T ′ ) S_a(T,T') Sa(T,T′)迭代通过所有对齐的三元组。考虑了三种不同的对准评分技术:基于距离的轴校准、平移向量和线性变换。它们中的每一个都基于不同的假设,并构成了不同形式的 S a S_a Sa。
**基于距离的轴校准。**这种类型的对齐模型根据跨语言对应物的距离对对齐进行惩罚。该模型可以采用以下两种评分中的任何一种。
S a 1 = ∥ h − h ′ ∥ + ∥ t − t ′ ∥ S_{a_1}=\|\mathbf{h}-\mathbf{h}'\|+\|\mathbf{t}-\mathbf{t}'\| Sa1=∥h−h′∥+∥t−t′∥
S a 1 S_{a1} Sa1规定,同一实体的正确对齐的多语言表达往往具有紧密的嵌入向量。因此,通过最小化涉及已知对齐三元组上的 S a 1 S_{a1} Sa1的损失函数,对齐模型朝着重合不同语言中相同实体的向量的目标调整嵌入空间的轴。
S a 2 = ∥ h − h ′ ∥ + ∥ r − r ′ ∥ + ∥ t − t ′ ∥ S_{a_2}=\|\mathbf{h}-\mathbf{h}'\|+\|\mathbf{r}-\mathbf{r}'\|+\|\mathbf{t}-\mathbf{t}'\| Sa2=∥h−h′∥+∥r−r′∥+∥t−t′∥
S a 2 S_{a2} Sa2将关系对齐的惩罚叠加到 S a 1 S_{a1} Sa1,以显式收敛相同关系的坐标。
基于轴校准的对齐模型假定每种语言中的条目在空间上的出现情况类似。因此,它通过将给定实体或关系的向量从原语的空间推进到另一种语言的空间来实现跨语言的转换。
**平移向量。**该模型将跨语言转换编码为向量。它将对齐整合到图形结构中,并将跨语言转换描述为常规的关系翻译。因此,推导出了如下 S a 3 S_{a3} Sa3。
S a 3 = ∥ h + v i j e − h ′ ∥ + ∥ r + v i j r − r ′ ∥ + ∥ t + v i j e − t ′ ∥ S_{a_3}=\left\|\mathbf{h}+\mathbf{v}_{ij}^e-\mathbf{h}'\right\|+\left\|\mathbf{r}+\mathbf{v}_{ij}^r-\mathbf{r}'\right\|+\left\|\mathbf{t}+\mathbf{v}_{ij}^e-\mathbf{t}'\right\| Sa3= h+vije−h′ + r+vijr−r′ + t+vije−t′
其 V i j e V_{ij}^e Vije和 V i j r V_{ij}^r Vijr分别被部署为 L i L_i Li和 L j L_j Lj之间的实体专用和关系专用的翻译向量,使得我们具有用于嵌入以两种语言表达的相同实体 e e e 的向量 e , e ′ \mathbf{e},\mathbf{e}^{\prime} e,e′的 e + v i j e ≈ e ′ \mathbf{e}+\mathbf{v}_{ij}^{e}\approx\mathbf{e}^{\prime} e+vije≈e′,以及用于具有相同关系的那些向量的 r + v i j r ≈ r ′ \mathbf{r}+\mathbf{v}_{ij}^{r}\approx\mathbf{r}^{\prime} r+vijr≈r′。我们部署两个翻译向量而不是一个,因为不同的实体比关系多得多,使用一个向量很容易导致来自关系的信号不平衡。
这样的模型通过添加对应的平移向量来获得嵌入向量的跨语言转换。此外,很容易看出, v i j e = − v j i e \mathbf{v}_{ij}^{e}=-\mathbf{v}_{ji}^{e} vije=−vjie 和 v i j r = − v j i r \mathbf{v}_{ij}^{r}=-\mathbf{v}_{ji}^{r} vijr=−vjir成立。因此,当我们得到从 L i L_i Li到 L j L_j Lj的平移向量时,我们总是可以使用相同的向量在相反的方向上平移。
**线性变换。**最后一类对齐模型推导出嵌入空间之间的线性变换。如下所示, S a 4 S_{a4} Sa4将 k × k k\times k k×k方阵 M i j e M_{ij}^e Mije学习为从 L i L_i Li到 L j L_j Lj的实体向量的线性变换,给定 k k k为嵌入空间的维度。
S a 4 = ∥ M i j e h − h ′ ∥ + ∥ M i j e t − t ′ ∥ S_{a_4}=\begin{Vmatrix}\mathbf{M}_{ij}^e\mathbf{h}-\mathbf{h}'\end{Vmatrix}+\begin{Vmatrix}\mathbf{M}_{ij}^e\mathbf{t}-\mathbf{t}'\end{Vmatrix} Sa4= Mijeh−h′ + Mijet−t′
S a 5 S_{a5} Sa5还引入了关系向量的第二线性变换 M i j r M_{ij}^r Mijr,其形状与 M i j e M_{ij}^e Mije相同。使用不同的矩阵也是由于实体和关系的不同冗余。
S a 5 = ∥ M i j e h − h ′ ∥ + ∥ M i j r r − r ′ ∥ + ∥ M i j e t − t ′ ∥ S_{a_5}=\left\|\mathbf{M}_{ij}^e\mathbf{h}-\mathbf{h}'\right\|+\left\|\mathbf{M}_{ij}^r\mathbf{r}-\mathbf{r}'\right\|+\left\|\mathbf{M}_{ij}^e\mathbf{t}-\mathbf{t}'\right\| Sa5= Mijeh−h′ + Mijrr−r′ + Mijet−t′
与轴线校准不同,基于线性变换的对齐模型将跨语言转换视为嵌入空间的拓扑变换,而不假设空间涌现的相似性。
通过应用相应的线性变换来获得向量的跨语言转换。值得注意的是,在训练过程(稍后将引入)中嵌入向量的正则化确保了线性变换的可逆性,使得 M i j e − 1 = M j i e M_{ij}^{e−1}=M^e_{ji} Mije−1=Mjie和 M i j r − 1 = M j i r M_{ij}^{r−1}=M^r_{ji} Mijr−1=Mjir。因此,即使模型只学习一个方向的变换,也始终启用还原方向上的过渡。
3.4 Variants of MTransE
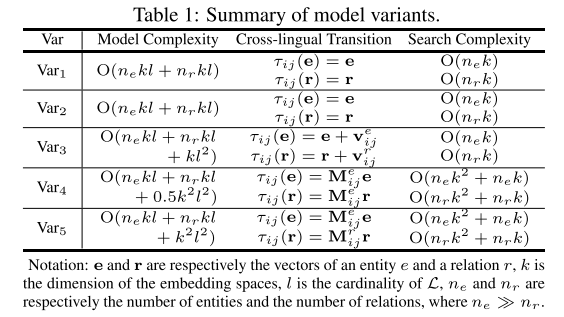
结合上述两个分量模型, M T r a n s E MTransE MTransE最小化如下损失函数 J = S K + α S A J=S_K + \alpha S_A J=SK+αSA,其中 α \alpha α是加权 S K S_K SK和 S A S_A SA的超参数。由于我们已经给出了对齐模型的五种变体,每一种变体都相应地定义了计算嵌入向量的跨语言转换的具体方法。我们将 V a r k Var_k Vark表示为采用第 k k k个比对模型的 M T r a n s E MTransE MTransE的变体,该模型使用了 S a k S_{ak} Sak。在实践中,跨语言对应源的搜索总是通过从跨语言转换的结果点查询最近的邻居来完成的。我们表示函数 τ i j \tau_{ij} τij,它映射一个向量从 L i L_i Li到 L j L_j Lj的跨语言转换,或者在双语上下文中简称为 τ \tau τ。如上所述,多语言场景中的解决方案包括在 L 2 \mathcal L^2 L2中的每个语言对上定义的相同变体的一组模型。表1总结了模型的复杂性、跨语言转换的定义以及为每个变体搜索跨语言对应项的复杂性。
3.5 Training
我们使用在线随机梯度下降来优化损失函数[Wilson和Martinez,2003]。在每个步骤中,我们通过设置 θ ← θ − λ ∇ θ J \theta \leftarrow \theta − \lambda\nabla_{\theta}J θ←θ−λ∇θJ来更新参数 θ \theta θ,其中 λ \lambda λ是学习速率。我们的实现不是直接更新 J J J,而是交替优化 S K S_K SK和 α S A \alpha S_A αSA。详细地说,在每个阶段,我们在不同的步骤组中对 θ ← θ − λ ∇ θ S K \theta \leftarrow \theta − \lambda\nabla_{\theta}S_K θ←θ−λ∇θSK和 θ ← θ − λ ∇ θ α S A \theta \leftarrow \theta − \lambda\nabla_{\theta}\alpha S_A θ←θ−λ∇θαSA进行优化。
我们强制任何实体嵌入向量的 l 2 l_2 l2范数为1的约束,从而将嵌入向量正则化到单位球面上。这一限制在文献[Bordes等人,2013;2014;Jenatton等人,2012]中使用,并具有两个重要的影响:(i)它有助于避免训练过程通过收缩嵌入向量的范数而使损失函数平凡地最小化的情况,以及(ii)它意味着 V a r 4 Var_4 Var4和 V a r 5 Var_5 Var5的线性变换的可逆性[Xing等人,2015]。
我们通过绘制单位球面上的均匀分布来初始化向量,并使用随机正交初始化来初始化矩阵[Saxe等人,2014]。在训练中没有使用负抽样,我们发现这对结果没有明显的影响。
4 Experiments
在这一部分中,我们将在两个跨语言任务上对所提出的方法进行评估:跨语言实体匹配和三对齐验证。我们还在两个单语任务上进行了实验。此外,一个带有知识匹配例子的案例研究被列入[Chen等人,2017]的附录。
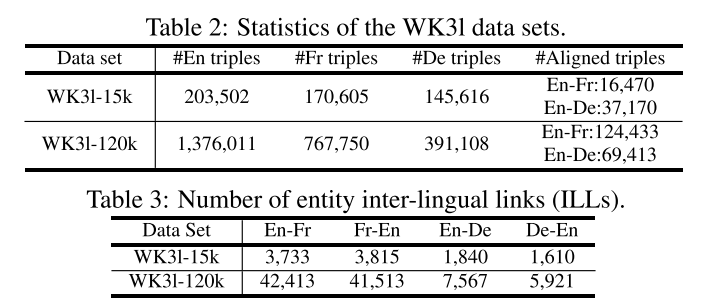
**数据集。**本节报告了在三种语言数据集 W K 31 WK31 WK31上的实验结果。 W K 31 WK31 WK31在DBpedia的dbo:Person domain下包含英语(En)、法语(Fr)和德语(De)知识图谱,其中三元组的一部分通过验证实体上的语言间链接(ILLs)来对齐,以及DBpedia本体上的多语种标签上的一些关系。调整每种语言的实体数量以获得两个数据集。对于其三种语言中的每一种,WK31-15k与FB15k匹配节点数量(约15,000),FB15k是许多最近的作品使用的最大的单语言图[Zhong等人,2015;Lin等人,2015;Ji等人,2015;Jia等人,2016],并且WK31-120k中的节点数量是FB15k的几倍。对于这两个数据集,德国的图表比英国和法国的图表更稀疏。我们还收集了额外的实体 ILLs用于跨语言实体匹配的评估,其数量如表3所示。同时,我们从 C o n c e p t N e t ConceptNet ConceptNet[Speer和Havasi,2013]中获得了另一个三语数据集 C N 31 CN31 CN31。关于 C N 31 CN31 CN31的其他结果导致类似的评价结论在[Chen等人,2017]的附录中报告。
4.1 Cross-lingual Entity Matching
此任务的目标是在知识库中匹配来自不同语言的相同实体。由于候选空间很大,本任务更注重对一组候选进行排名,而不是获取最佳答案。我们在这两个数据集上执行这项任务,以比较 M T r a n s E MTransE MTransE的五个变体。
为了显示 M T r a n s E MTransE MTransE的优势,我们将 L M LM LM、 C C A CCA CCA和 O T OT OT(在第2节中介绍)改写为它们的知识图等效项。
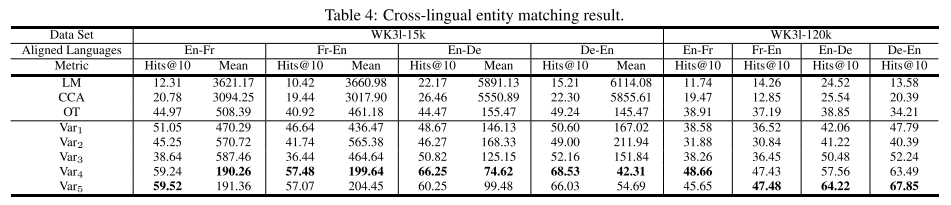
**评估协议。**每个 M T r a n s E MTransE MTransE变体都是在一个完整的数据集上进行训练的。 L M LM LM和 C C A CCA CCA是通过在单语图上引入不同训练知识模型之间的相应转换来实现的,同时使用对齐集作为锚。训练 O T OT OT与 M T r a n s E MTransE MTransE非常相似,我们将正交化过程添加到对齐模型的训练中,因为已经实施了向量的正则化。实体的语言间链接被用作检验的基础真理。我们把英语-法语和英语-德语之间的这些单向联系,即总共四个方向。对于每个 I L L ( e , e ′ ) ILL(e, e') ILL(e,e′),我们从 e e e的跨语言转换点(即, τ ( e ) \tau(\mathbf e) τ(e))执行 kNN搜索,并记录 e ′ e' e′的排名。按照惯例[Xing等人,2015;Jia等人,2016],我们在所有测试用例上聚集了两个度量,即不超过10次的排名 H i t s @ 10 Hits@10 Hits@10(百分比)比例和平均排名 M e a n Mean Mean。我们更喜欢更高的 H i t s @ 10 Hits@10 Hits@10和更低的 M e a n Mean Mean,这表明结果更好。
对于训练,我们在 { 0.001 , 01 , 0.01 , 0.1 } \{0.001, 0 1, 0.0 1, 0.1\} {0.001,01,0.01,0.1}中选择学习率 λ \lambda λ,在 { 1 , 2.5 , 5 , 7.5 } \{1, 2.5, 5, 7.5\} {1,2.5,5,7.5}中选择 α \alpha α,在损失函数中选择 l 1 l_1 l1或 l 2 l_2 l2范数,在 { 50 , 75 , 100 , 125 } \{50, 75, 100, 125\} {50,75,100,125}中选择维度 k k k。WK31-15k的最佳构型为 λ = 0.01 , α = 5 , k = 75 , V a r 1 、 V a r 2 λ=0.01, \alpha=5, k=75, Var_1、Var_2 λ=0.01,α=5,k=75,Var1、Var2的 l 1 l_1 l1范数, L M LM LM和 C C A CCA CCA其他变种和 O T OT OT的 l 2 l_2 l2范数。而在WK31-120k上,所有模型的最佳配置为 λ = 0.01 , α = 5 , k = 100 , l 2 \lambda=0.01,\alpha=5,k=100,l_2 λ=0.01,α=5,k=100,l2范数。在这两个数据集上的训练花费了400个epoch。
**结果。**在表4中涉及的四个跨语言匹配方向上,我们报告了WK31-15k的 H i t s @ 10 Hits@10 Hits@10和 M e a n Mean Mean,WK31-120k的 H i t s @ 10 Hits@10 Hits@10。正如预期的那样,在没有联合调整单语向量空间与知识对齐的情况下, L M LM LM和 C C A CCA CCA的表现远远好于其他两种方法。虽然正交性约束太强,无法在这些情况下强制执行,但 O T OT OT的性能最接近于最简单的 M T r a n s E MTransE MTransE情况。对于 M T r a n s E MTransE MTransE,在所有设置下, V a r 4 Var_4 Var4和 V a r 5 Var_5 Var5的表现都优于其他三个变种。这两个变体得到的结果相当接近,表明在 V a r 5 Var_5 Var5中学习额外的关系专用转换所造成的干扰对于实体专用转换来说是可以忽略的。相应地,我们认为 V a r 3 Var_3 Var3优于 V a r 4 Var_4 Var4和 V a r 5 Var_5 Var5的原因是它没有很好地区分过频繁的跨语言对齐和常规关系。因此,跨语言对齐的表征在很大程度上受到单语关系学习过程的负面影响。在此任务中,轴校准似乎不稳定。我们假设这一简单的技术受到两个因素的影响:特定语言版本之间的一致性和图表的密度。由于基于关系的校准的负面影响, V a r 2 Var_2 Var2的表现总是优于 V a r 1 Var_1 Var1。我们认为这是因为 T r a n s E TransE TransE没有像[Wang等人,2014]中解释的那样很好地捕捉到多重映射关系,因此干扰了整个嵌入空间的校准。尽管在WK31-15k中, V a r 1 Var_1 Var1在英语和法语图形之间的实体匹配方面仍然优于 V a r 3 Var_3 Var3,但当扩展到更大的数据集时,一致性会有所下降,从而阻碍校准。德国的图形是稀疏的,因此应该为精确构造嵌入向量设置障碍,并阻碍另一边的校准。因此,在WK31-15k上的英语-德语任务和WK31-120k上的英语-法语任务中, V a r 1 Var_1 Var1的表现仍然接近 V a r 3 Var_3 Var3,但在最后一次设置中被 V a r 3 Var_3 Var3超越。通常,使用线性变换的变体是最理想的。这一结论得到了他们在这项任务上有希望的结果的支持,这也反映在图1所示的精确度-召回曲线中。

4.2 Triple-wise Alignment Verification
这项任务是验证给定的一对对齐的三元组是否是真正的跨语言对应。它产生了一个分类器,帮助验证三重匹配的候选者[Nguyen等人,2011年;Rinser等人,2013年]。
**评估协议。**我们通过分离20%的比对集合来创建阳性病例。与[Socher等人,2013]类似,我们随机腐败正面案例以生成负面案例。具体地,给定一对正确对齐的三元组 ( T , T ′ ) (T,T') (T,T′),通过(i)用来自相同语言的另一个元素随机地替换两个三元组中的六个元素中的一个,或者(ii)用来自相同语言的另一个三元组随机替换 T T T或 T ′ T' T′来破坏它。病例(i)和(ii)分别为阴性病例,占阳性病例的100%和50%。我们在这些案例上使用了10折交叉验证来训练和评估分类器。
我们使用一种简单的基于阈值的分类器,类似于广泛使用的用于三重分类的分类器[Socher等人,2013;Wang等人,2014;Lin等人,2015]。对于给定的一对对齐的三元组 ( T , T ′ ) = ( ( h , r , t ) , ( h ′ , r ′ , t ′ ) ) (T,T^{\prime})=\big((h,r,t),(h^{\prime},r^{\prime},t^{\prime})\big) (T,T′)=((h,r,t),(h′,r′,t′)),相异函数被定义为 f d ( T , T ′ ) = ∥ τ ( h ) − h ′ ∥ 2 + ∥ τ ( r ) − r ′ ∥ 2 + ∥ τ ( t ) − t ′ ∥ 2 f_d(T,T')=\|\tau(\mathbf{h})-\mathbf{h}'\|_2+\|\tau(\mathbf{r})-\mathbf{r}'\|_2+\|\tau(\mathbf{t})-\mathbf{t}'\|_2 fd(T,T′)=∥τ(h)−h′∥2+∥τ(r)−r′∥2+∥τ(t)−t′∥2。分类器找到阈值 σ \sigma σ,使得 f d < σ f_d<\sigma fd<σ; σ \sigma σ表示正,否则表示负。 σ \sigma σ的值是通过最大化训练集上每个折叠的精度来确定的。这样一个简单的分类规则充分依赖于每个模型表示实体和关系的跨语言转换的精确度。
我们延续了上次实验中的相应配置,只是为了展示每个变量在受控变量下的性能。
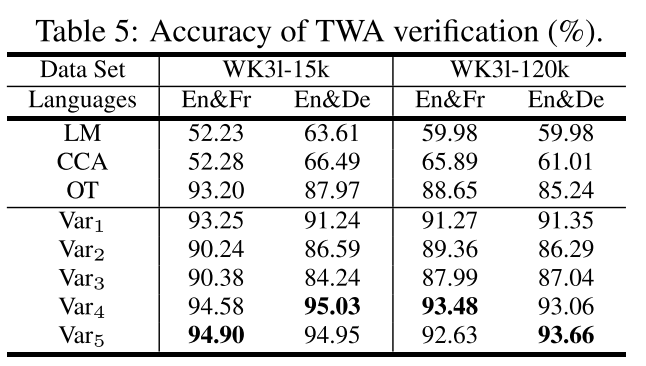
**结果。**表5显示了平均准确度,所有设置的交叉验证标准偏差均低于0.009。因此,结果在统计上足以反映分类器的性能。请注意,由于这是一个二进制分类问题,因此结果似乎比前一个任务的结果要好。直观地说,基于线性变换的 M T r a n s E MTransE MTransE性能稳定,在所有设置中都处于领先地位。我们还观察到,虽然 V a r 5 Var_5 Var5学习了一个额外的关系专用转换,但它的性能仍然相当接近 V a r 4 Var_4 Var4(最多相差0.85%)。简单 V a r 1 Var_1 Var1为亚军,最优解在1.65%~3.79%之间。然而, V a r 2 Var_2 Var2中的关系专用校准导致了一个显着的挫折(距离最优值4.12%∼8.44%)。由于未能区分跨语言对齐和规则关系, V a r 3 Var_3 Var3的表现略逊于 V a r 2 Var_2 Var2(4.52%∼10.79%)。同时,我们对WK31-15k中只有英法关系被破坏的否定格部分的准确性进行了筛选。五个变异体的得率分别为97.73%、93.78%、82.34%、98.57%和98.54%。 V a r 4 Var_4 Var4和 V a r 5 Var_5 Var5的接近精度表明,从 V a r 4 Var_4 Var4中的实体学习的唯一转换足以取代 V a r 5 Var_5 Var5中的关系专用转换来区分关系对齐,而学习 V a r 5 Var_5 Var5中的附加转换不会显著干扰原始转换。然而,它应用于轴校准的情况有所不同,因为 V a r 2 Var_2 Var2不仅没有改善,反而实际上损害了关系的跨语言转换。由于上述原因,在本实验中, L M LM LM和 C C A CCA CCA与 M T r a n s E MTransE MTransE并不匹配,而 O T OT OT的表现与 M T r a n s E MTransE MTransE的一些变体非常接近,但仍落后于 V a r 4 Var_4 Var4和 V a r 5 Var_5 Var5。
4.3 Monolingual Tasks
以上实验表明, M T r a n s E MTransE MTransE在处理跨语言任务方面具有很强的能力。现在,我们使用英语和法语版本的数据集,就文献 [Bordes et al, 2013; 2014] 中介绍的两项单语任务(即尾部预测(根据 h h h 和 r r r 预测 t t t)和关系预测(根据 h h h 和 t t t 预测 r r r)),报告 MTransE 与单语对应 TransE 的比较结果。与以往的工作[Bordes等人,2013年;Wang等人,2014年;Jia等人,2016年]一样,对于每个语言版本,10%的三元组被选为测试集,其余的成为训练集。每个 M T r a n s E MTransE MTransE变体在用于知识模型的训练集的两种语言版本上进行训练,而对齐集合和训练集之间的交集用于对齐模型。 T r a n s E TransE TransE接受培训集的任一语言版本的培训。同样,我们使用上一次实验中的配置。
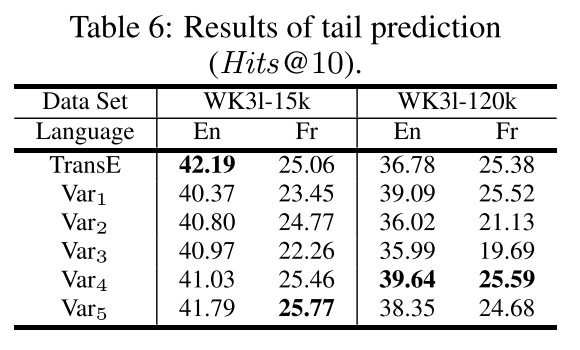
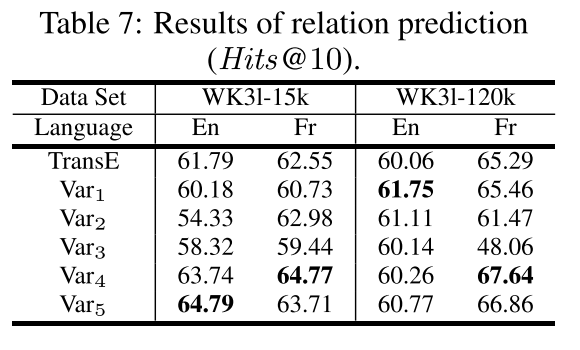
**结果。**表6和表7报告了 H i t s @ 10 Hits@10 Hits@10的结果。这意味着 M t r a n s E MtransE MtransE很好地保留了单语知识的特征。对于每种设置, V a r 1 , V a r 4 Var_1, Var_4 Var1,Var4和 V a r 5 Var_5 Var5的表现至少与 T r a n s E TransE TransE一样好,有些甚至在某些设置下优于 T r a n s E TransE TransE。这意味着在刻画单语关系方面,对齐模型对知识模型没有太大的干扰,但实际上可能会加强它,因为对齐模型统一了知识的连贯部分。由于目前还没有衡量这种连贯性,这个问题留到未来的工作中去解决。另一个值得进一步关注的问题是,其他涉及关系特定实体转换的知识模型[Wang等人,2014;Lin等人,2015;Ji等人,2015;Jia等人,2016;Nguyen等人,2016]可能会影响单语和跨语言任务。
5 Conclusion and Future Work
就我们所知,本文是第一个将知识图嵌入推广到多语言场景的工作。我们的模型 M T r a n s E MTransE MTransE描述了单语关系,并比较了三种不同的技术来学习实体和关系的跨语言对齐。在跨语言实体匹配和三对齐验证任务上的大量实验表明,线性变换技术是这三种技术中最好的。此外, M T r a n s E MTransE MTransE保留了单语知识图在单语任务中嵌入的关键特性。
这里的结果非常令人鼓舞,但我们也指出了进一步工作和改进的机会。特别是,我们应该探索如何用涉及特定于关系的实体转换的更高级的损失函数来取代 M T r a n s E MTransE MTransE中使用的简单的知识模型的损失函数。还可以进行更复杂的跨语言三重完成任务。将 M T r a n s E MTransE MTransE与多语言单词嵌入相结合[Xing等人,2015]是另一个有意义的方向,因为它将提供一个有用的工具,从多语言文本语料库中提取新的关系。
论文原文:https://arxiv.org/pdf/1611.03954.pdf
深度学习小白,知识图谱方向,欢迎大家一起学习交流,共同进步,本文如有错误欢迎指正!
















 1225
1225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











