










Relational Reflection Entity Alignment
关系反射实体对齐
ABSTRACT
实体对齐旨在识别来自不同知识图谱(KG)的等效实体对,这对于集成多源知识图谱至关重要。最近,随着 GNN 在实体对齐中的引入,近期模型的架构变得越来越复杂。我们甚至在这些方法中发现了两个反直觉的现象:(1)GNN 中的标准线性变换效果不佳。(2)许多为链接预测任务设计的先进知识图谱嵌入模型在实体对齐方面表现不佳。在本文中,我们将现有的实体对齐方法抽象为一个统一的框架Shape-Builder&Alignment,它不仅成功地解释了上述现象,而且导出了理想变换操作的两个关键标准。此外,我们提出了一种新的基于 GNN 的方法,关系反射实体对齐(RREA)。 RREA 利用关系反射转换以更有效的方式获取每个实体的关系特定嵌入。在真实数据集上的实验结果表明,我们的模型显着优于最先进的方法,在 Hits@1 上超出了 5.8%-10.9%。
1 INTRODUCTION
现有的实体对齐方法可以分为两大类:(1)基于翻译的 (2)基于GNN(通过聚合来自相邻节点的信息来生成嵌入)
在这些复杂的方法中观察到两个反直觉的现象:
Q1:为什么 GNN 的标准线性变换在实体对齐中效果不佳?
Q2:为什么很多先进的KG嵌入模型在实体对齐方面效果不佳?
提出了一个抽象实体对齐框架Shape-Builder & Alignment,成功地得出了解决上述问题的答案:(Q1)实体对齐假设分布之间的相似性,因此为了避免破坏形状,实体的范数和相对距离在变换后应保持不变。因此,变换矩阵必须是正交的。 (Q2)许多先进的知识图谱嵌入模型都有一个共同的关键思想——将实体嵌入转换为特定于关系的嵌入。然而,它们的变换矩阵很难满足正交性。这就是它们在实体对齐方面表现不佳的根本原因。
提出了实体对齐理想变换操作的两个关键标准:关系微分和维度等距。设计了一个新的转换操作,关系反射转换。这种新操作能够沿着不同的关系超平面反映实体嵌入,以构造关系特定的嵌入。同时,反射矩阵是正交的,易于证明,因此反射变换可以保持范数和相对距离不变。通过将这种提出的转换集成到 GNN 中,进一步提出了一种新颖的基于 GNN 的实体对齐方法,即关系反射实体对齐(RREA)。
主要贡献:
- 第一个将现有实体对齐方法抽象为统一框架的工作。通过这个框架,成功地推导出理想转换操作的两个关键标准:关系微分和维度等距。
- 这是设计满足上述两个标准的新转换操作“关系反射转换”的第一个工作。通过将此操作集成到 GNN 中,进一步提出了一种新的基于 GNN 的方法关系反射实体对齐(RREA)。
- 广泛的实验结果表明,该模型在所有现实世界数据集中始终被评为最佳模型,并且在 Hits@1 上比最先进的方法高出 5.8%-10.9%。此外,我们还进行了消融实验,以证明我们模型的每个组件都是有效的。
2 RELATED WORK
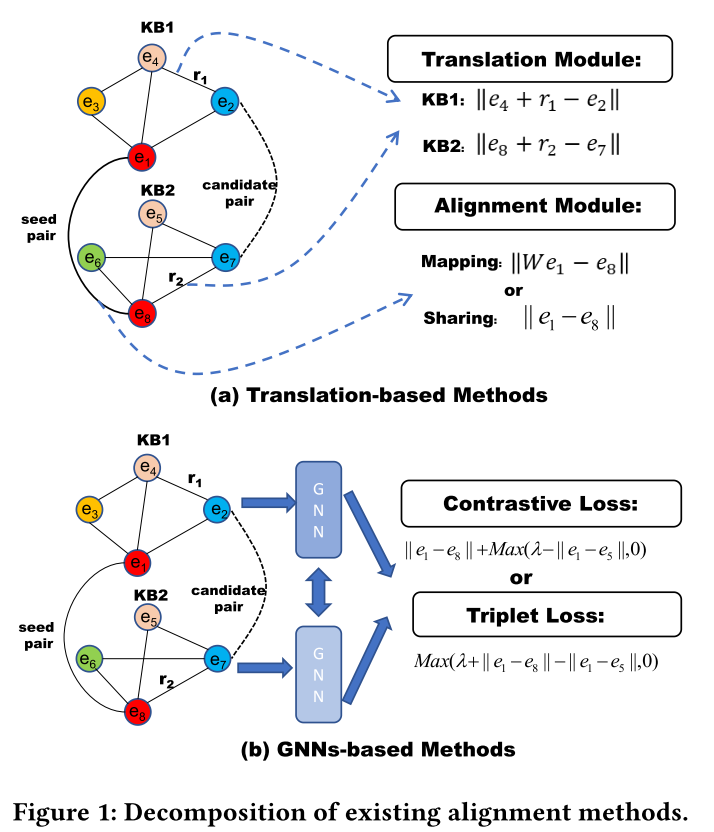
2.1 Translation-based Methods
基于翻译的方法(图1(a))通常由两个模块组成:翻译模块和对齐模块。
翻译模块的主要功能是通过基于翻译的知识图谱嵌入模型将随机初始化的嵌入约束为固定分布。
对齐模块:通过将预先对齐的实体作为种子,对齐模块负责将不同KG的嵌入对齐到统一的向量空间中。目前对齐模块有两种类型:(1)映射:通过线性变换矩阵将不同的知识图谱嵌入到统一的向量空间。(2)共享:共享方法通过让每个预对齐对直接共享相同的嵌入来将不同的知识图谱嵌入到统一的向量空间中。
2.2 GNNs-based Methods
基于 GNN 的方法(图1(b))
3 PRELIMINARY
3.1 Problem Formulation
KG 以三元组 ⟨𝑒𝑛𝑡𝑖𝑡𝑦_1,𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛,𝑒𝑛𝑡𝑖𝑡𝑦_2⟩ 的形式存储现实世界信息,KG定义为 G = ( E , R , T ) G = (E, R, T) G=(E,R,T),描述两个实体之间的关系。 P = { ( e i 1 , e i 2 ) ∣ e i 1 ∈ E 1 , e i 2 ∈ E 2 } i = 1 p P=\left\{(e_{i_{1}},e_{i_{2}})|e_{i_{1}}\in E_{1},e_{i_{2}}\in E_{2}\right\}_{i=1}^{p} P={(ei1,ei2)∣ei1∈E1,ei2∈E2}i=1p表示预对齐种子对的集合。
3.2 Datasets
DBP15K、DWY100K 随机分割 30% 的对齐对进行训练,保留 70% 进行测试。
4 A UNIFIED ENTITY ALIGNMENT FRAMEWORK
4.1 Shape-Builder & Alignment
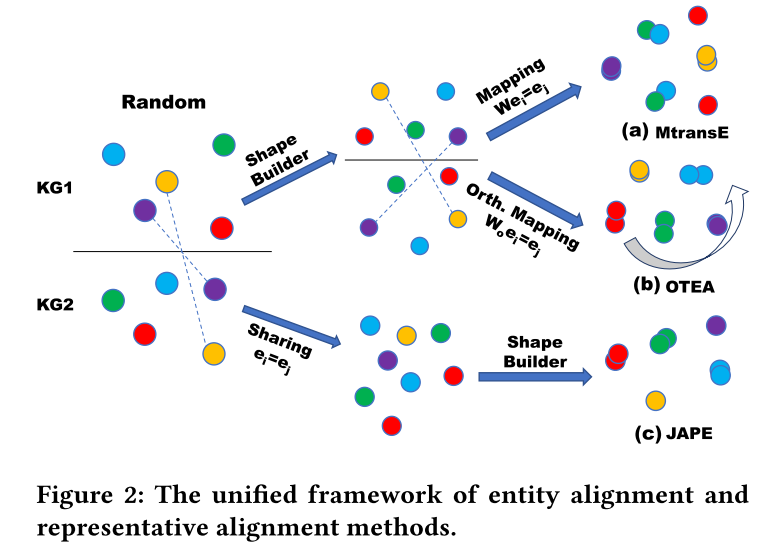
形状生成器:形状生成器的主要功能是将随机初始化的分布限制为我们定义为形状的特定分布。
对齐:当形状相似度成立时,可以通过预先对齐的种子来匹配不同的形状。
4.2 GNNs-based Methods Are Also Subject to Our Unified Framework
提出一个假设:基于 GNN 的方法也受我们的统一框架 Shape-Builder & Alignment 的约束。
视觉实验: 如果假设正确,那么不同KG的分布应该具有视觉相似性。因此,为了验证假设,保留了 GCN-Align 中三重态损失的分离损失,然后GCN-Align从监督模型转变为自监督模型。
定量实验: 如果分布具有形状相似性,则一个 KG 中实体之间的相对距离应等于另一 KG 中实体之间的相对距离。形状相似性度量SS
实验结果符合预期:(1)随机嵌入之间的SS几乎为1。(2)虽然未经训练的GCN-Align具有一些最小聚类能力,但它仍然接近随机初始化。(3) TransE 和 GCN-Align 都成功地降低了分布的 SS,并且 GCN-Align 略好于 TransE。
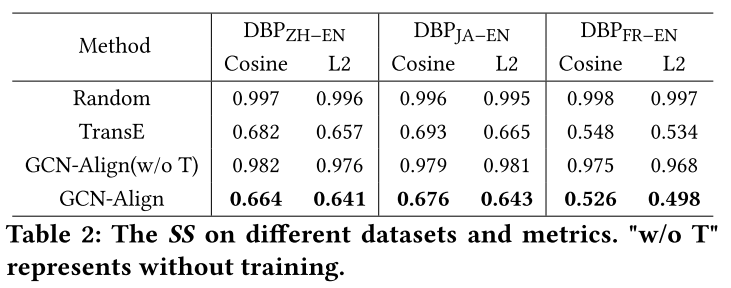
实验证明了 GNN 的聚合操作和分离损失一起组成了一个形状生成器。请注意,假设仅适用于纯粹基于结构信息(即三元组)的对齐方法。一些方法采用实体名称并通过机器翻译或跨语言词嵌入对其进行预对齐。在这些方法中,GNN 起到噪声平滑的作用,而不是实际对齐的作用。
4.3 Why Linear Transformation Not Work
验证Q1的答案,设计了两个实验:
(1) GCN-Align 实验:为了证明保持变换矩阵正交是必要的,我们测试了 GCN-Align(最简单的基于 GNN 的方法)的不同约束。为了在训练过程中保持
W
\mathbf W
W正交,我们采用以下约束:
L
o
=
∥
W
T
W
−
I
∥
2
2
L_o=\left\|W^TW-I\right\|_2^2\quad\quad\quad
Lo=
WTW−I
22
无约束方法最差
(2) 复杂 GNN 实验:为了进一步验证正交对于复杂方法也是必要的,使用 MuGNN、KECG 和 AliNet 测试正交和单位约束设置。正交约束和单位约束都提高了所有数据集上的性能。单位约束比正交约束稍好。
综上所述, GNN 中的变换矩阵 KaTeX parse error: Expected group after '_' at position 10: \mathbf M_̲应约束为正交,以确保变换后实体的范数和相对距离保持不变。单位矩阵不仅是正交的特殊情况,也是最简单的实现。
4.4 Why Advanced KG Embedding Not Work
这些先进方法都有一个关键思想:将通用实体嵌入转换为关系特定嵌入。然而,在它们最初的设计中,它们都没有对其变换矩阵施加任何约束。这种无约束的变换破坏了形状相似性,导致实体对齐任务的性能较差。
4.5 Key Criteria for Transformation Operation
实体对齐中理想的变换操作应该满足以下两个关键标准:
- 关系区分: 对应不同的关系类型,该操作可以将同一实体的嵌入变换到不同的关系空间中。
- 维度等距: 当同一KG中的两个实体变换到同一关系空间时,应保留它们的范数和相对距离。
5 THE PROPOSED METHOD
关系反射实体对齐(RREA):该方法在 GNN 中结合了关系反射变换,以同时满足关系区分和维度等距标准。
5.1 Relational Reflection Transformation
为了满足关键标准,设计了一种新的转换操作,即关系反射转换。令关系嵌入
h
r
h_r
hr 为法向量,有且仅有一个超平面
p
r
p_r
pr 和仅有一个对应的反射矩阵
M
r
M_r
Mr,使得:
M
r
=
I
−
2
h
r
h
r
T
(
12
)
M_r=I-2\boldsymbol{h}_r\boldsymbol{h}_r^T\quad\quad\quad\quad(12)
Mr=I−2hrhrT(12)
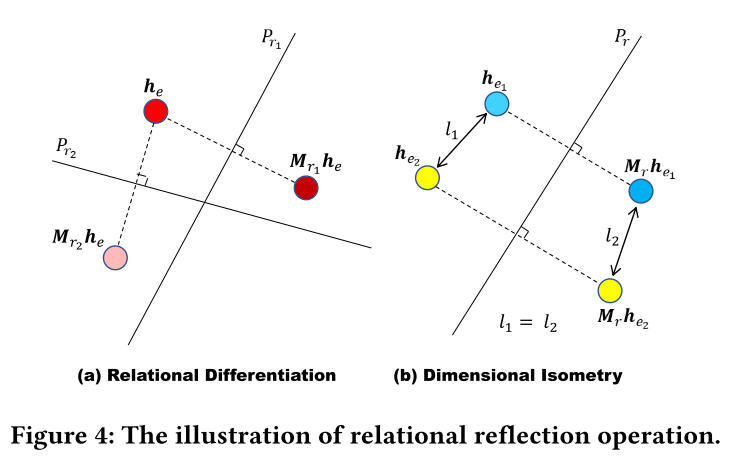
5.2 Relational Reflection Entity Alignment
RREA 由以下四个主要部分组成:
关系反射聚合层: 从𝑙-𝑡ℎ层得到 e i e_i ei 的输出特征如下:
h e i l + 1 = R e L U ( ∑ e j ∈ N e i e ∑ r k ∈ R i j α i j k l M r k h e j l ) ( 14 ) \boldsymbol{h}_{e_i}^{l+1}=\mathrm{ReLU}\Bigg(\sum_{e_j\in\mathcal{N}_{e_i}^e}\sum_{r_k\in\mathcal{R}_{ij}}\alpha_{ijk}^l\boldsymbol{M}_{r_k}\boldsymbol{h}_{e_j}^l\Bigg)\quad\quad(14) heil+1=ReLU(ej∈Neie∑rk∈Rij∑αijklMrkhejl)(14)
其中 N e i e \mathcal{N}_{e_{i}}^{e} Neie表示 e i e_i ei的邻近实体集, R i j R_{ij} Rij表示 e i e_i ei与 e j e_j ej之间的关系集合, M r k ∈ R d × d M_{r_{k}}\in\mathbb{R}^{d\times d} Mrk∈Rd×d是 r k r_k rk的关系反射矩阵。与将不同的 W r \mathbf W_r Wr分配给不同关系的RGCN相比,关系反射的可训练参数数量要少得多,因为 M r \mathbf M_r Mr的自由度仅为 d d d 而不是 d 2 d^2 d2。与GAT类似, α i j k l \alpha_{ijk}^{l} αijkl表示 M r k h e j l M_{r_k}h_{e_j}^l Mrkhejl的权重系数,其计算公式如下:
β i j k l = v T [ h e i l ∥ M r k h e j l ∥ h r k ] ( 15 ) α i j k l = e x p ( β i j k l ) ∑ e j ∈ N e i e ∑ r k ∈ R i j exp ( β i j k l ) ) ( 16 ) \beta_{ijk}^{l}=\boldsymbol{v}^{T}[\boldsymbol{h}_{e_{i}}^{l}\|\boldsymbol{M}_{r_{k}}\boldsymbol{h}_{e_{j}}^{l}\|\boldsymbol{h}_{r_{k}}]\quad\quad\quad\quad\quad(15)\\\alpha_{ijk}^{l}=\frac{exp(\beta_{ijk}^{l})}{\sum_{e_{j}\in\mathcal{N}_{e_{i}}^{e}}\sum_{r_{k}\in\mathcal{R}_{ij}}\exp(\beta_{ijk}^{l}))}\quad\quad(16) βijkl=vT[heil∥Mrkhejl∥hrk](15)αijkl=∑ej∈Neie∑rk∈Rijexp(βijkl))exp(βijkl)(16)
其中 v ∈ R 2 d v \in \mathbb R^{2d} v∈R2d 是用于计算权重系数的可训练向量。为了创建全局感知的图表示,我们堆叠多层 GNN 来捕获多跳邻域信息。来自不同层的嵌入被连接在一起以获得实体 e i e_i ei的最终输出特征 h e i o u t \mathbf h^{out}_{e_i} heiout:
h e i o u t = [ h e i 0 ∥ . . . ∥ h e i l ] h_{e_i}^{out}=[\begin{array}{c}h_{e_i}^0\|...\|h_{e_i}^l\end{array}]\quad\quad\quad heiout=[hei0∥...∥heil]
其中 h e i 0 \mathbf h^{0}_{e_i} hei0 表示 e i e_i ei 的初始嵌入。
双向嵌入(Dual-Aspect Embedding): 将关系嵌入的求和与实体嵌入连接起来以获得双方面嵌入。在本文中也采用双方面嵌入,公式如下:
h
e
i
M
u
l
=
[
h
e
i
o
u
t
∥
1
∣
N
e
i
r
∣
∑
r
j
∈
N
e
i
r
h
r
j
]
\boldsymbol{h}_{e_i}^{Mul}=\left[\boldsymbol{h}_{e_i}^{out}\Big\|\frac{1}{|\mathcal{N}_{e_i}^r|}\sum_{r_j\in\mathcal{N}_{e_i}^r}\boldsymbol{h}_{r_j}\right]
heiMul=
heiout
∣Neir∣1rj∈Neir∑hrj
其中 N e i r \mathcal{N}_{e_i}^r Neir表示实体 e i e_i ei 周围的关系集。
训练的对齐损失函数: 为了使统一向量空间中的等价实体彼此靠近,采用以下三元组损失函数:
L
=
∑
(
e
i
,
e
j
)
∈
P
m
a
x
(
d
i
s
t
(
e
i
,
e
j
)
−
d
i
s
t
(
e
i
′
,
e
j
′
)
+
λ
,
0
)
L=\sum\limits_{\begin{pmatrix}e_i,e_j\end{pmatrix}\in P}max\left(dist\left(e_i,e_j\right)-dist\left(e_i',e_j'\right)+\lambda,0\right)
L=(ei,ej)∈P∑max(dist(ei,ej)−dist(ei′,ej′)+λ,0)
这里, e i ′ e'_i ei′和 e j ′ e'_j ej′代表由最近邻采样生成的 e i e_i ei和 e j e_j ej的负对。在训练过程中,采用与 GCN-Align相同的设置,使用曼哈顿距离作为距离度量。
d i s t ( e i , e j ) = ∥ h e i M u l − h e j M u l ∥ 1 dist\begin{pmatrix}e_i,e_j\end{pmatrix}=\begin{Vmatrix}h_{e_i}^{Mul}-h_{e_j}^{Mul}\end{Vmatrix}_1 dist(ei,ej)= heiMul−hejMul 1
CSLS 测试指标: Lample 等人提出跨域相似性局部缩放(CSLS)来解决跨语言词嵌入任务中存在的中心问题。测试过程中也采用 CSLS 作为距离度量。
5.3 Further Data Enhancement
半监督学习: 为了扩展训练数据,最近的一些研究采用迭代或引导策略来构建半监督模型。在本文中使用MRAEA提出的迭代策略来生成半监督数据。
无监督文本框架: 之前讨论的方法只关注知识图谱的结构信息。最近的一些方法提出将文本信息和结构信息结合起来。在本文中采用 MRAEA 的无监督文本框架(不需要标记数据)。
6 EXPERIMENTS
6.1 Experiment Setting
数据分割和指标: 根据之前的研究,随机分割 30% 的预对齐实体对作为训练数据,剩下的数据用于测试。使用 Hits@k 和平均倒数排名(MRR)作为评估指标。
超参数选择: 选择具有以下候选集的超参数:嵌入维度 d ∈ { 75 , 100 , 150 , 200 } d \in \{75, 100, 150, 200\} d∈{75,100,150,200},边距 λ ∈ { 1.0 , 2.0 , 3.0 , 4.0 } \lambda \in \{1.0, 2.0, 3.0, 4.0\} λ∈{1.0,2.0,3.0,4.0},学习率 γ ∈ { 0.001 , 0.005 , 0.01 } \gamma \in \{0.001, 0.005, 0.01\} γ∈{0.001,0.005,0.01},GNN 的深度 l ∈ { 1 , 2 , 3 , 4 } l \in \{1, 2, 3, 4\} l∈{1,2,3,4},丢失率 μ ∈ { 0.2 , 0.3 , 0.4 , 0.5 } \mu \in \{0.2, 0.3, 0.4, 0.5\} μ∈{0.2,0.3,0.4,0.5}。对于所有数据集使用相同的配置: d = 100 , λ = 3 , l = 2 , μ = 0.3 , γ = 0.005 d = 100,\lambda = 3,l = 2,\mu = 0.3,\gamma = 0.005 d=100,λ=3,l=2,μ=0.3,γ=0.005。采用RMSprop对模型进行优化,epoch数设置为3000。
6.2 Baselines
根据现有方法使用的数据将其分为三类:
- 基本:这种方法仅使用数据集中的原始结构数据(即三元组):JAPE、GCN-Align、RSN、MuGNN、TransEdge、AliNet 和 MRAEA。
- 半监督:此类方法引入半监督来生成额外的结构数据:Boot-EA、NAEA、TransEdge(semi)、MRAEA(semi)。
- 文本:除了结构数据之外,文本方法还引入实体名称作为附加输入特征:GMNN、RDGCN、HGCN、MRAEA(text)和DGMC。
相应的,RREA也有三个版本:RREA(basic)、RREA(semi)和RREA(text)。
6.3 Main Results and Ablation Studies
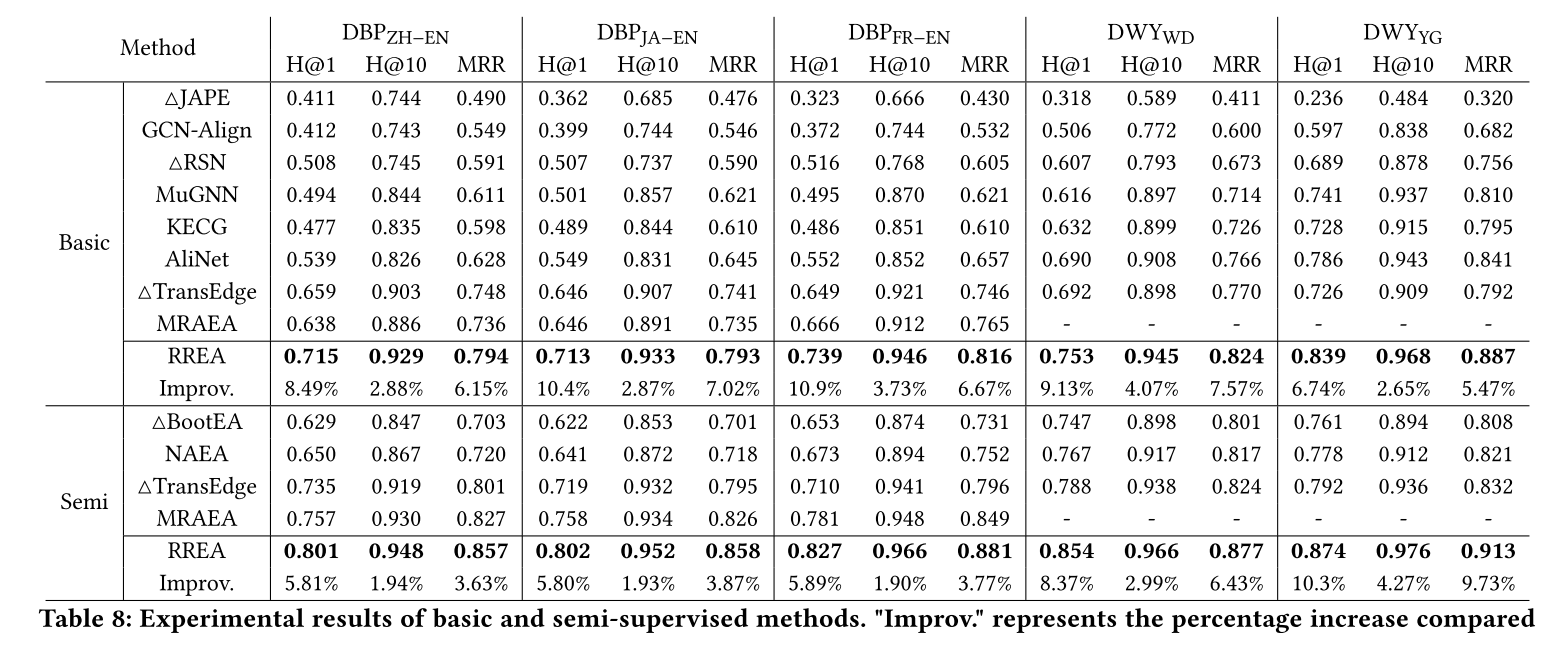
RREA 与基本和半监督方法。 RREA的性能在所有评估指标上始终被评为所有竞争基本方法和半监督方法中最好的。主要原因是反射转换为实体构建了关系特定的嵌入,可以更好地捕获关系信息。此外,半监督可以显着提高所有方法在所有数据集上的性能。

RREA 与文本方法。 RREA在所有数据集上取得了最好的成绩。由于RREA使用 MRAEA 提出的无监督文本框架,性能的提高完全归功于结构数据更好的建模。与其他监督模型(例如 DGMC、GMNN)相比,RREA(text)甚至在使用相同数据集时实现了更好的性能。
消融研究。 RREA(basic)与 GCNAlign 相比有三个设计:(1)跨域相似性局部缩放;(2)关系反射聚合层;(3)双向嵌入。从 GCN-Align 基线开始,逐渐采用这些组件并以 Means±stds 报告结果。显然,所有这三种设计都显着提高了性能。与GCN-Align相比,CSLS的引入提高了约4%的性能。这表明实体对齐任务和跨语言词嵌入之间存在高度相关性。在模型中添加关系反射聚合层和双反射嵌入进一步分别为𝐻𝑖𝑡𝑠@1 带来了 15% 和 7% 的改进。这意味着这两种设计都将独特的信息引入模型中。这些消融实验表明我们的设计是有意义的并且带来了显着的改进。
6.4 Robustness Analysis
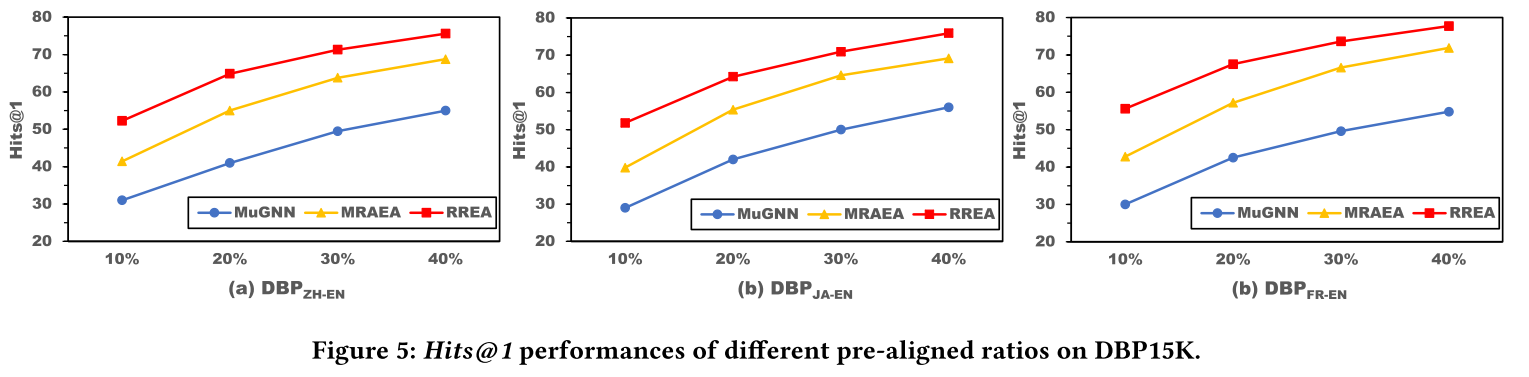
预调整比率的鲁棒性。 为了研究 RREA 在不同预对齐比率下的鲁棒性,比较了 DBP15K 上三种基于 GNN 的方法(MuGNN、MRAEA 和 RREA(basic))与不同预对齐对比率的性能。RREA 在训练数据的所有预对齐比率方面都显着优于对比方法。
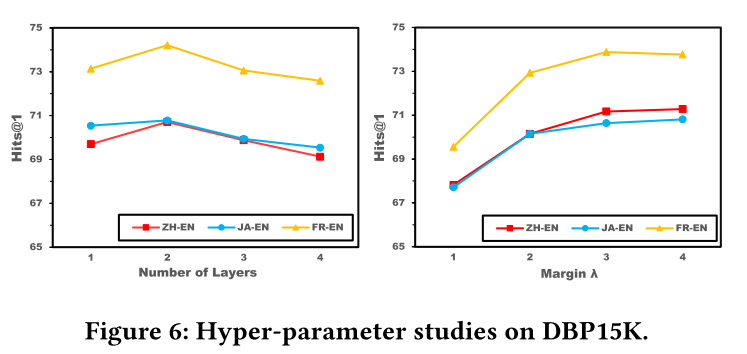
超参数的鲁棒性。 为了研究 RREA 对超参数的鲁棒性,改变层数 l l l 和边距 λ \lambda λ,同时保持其他超参数与默认设置一致。对于层深度 l l l,具有 2 层的 RREA 在所有数据集上实现了最佳性能。当堆叠更多层时,性能开始略有下降。堆叠更多层只会导致速度变慢,而不是性能更好。一般来说, l l l 和 λ \lambda λ对性能的影响有限,并且模型在超参数变化期间相对稳定。
7 CONCLUSIONS
在本文中,提出了实体对齐中的反直觉现象,这些现象被先前的研究所忽视。通过将现有的实体对齐方法抽象为一个统一的框架,成功地解释了问题并导出了实体对齐中转换操作的两个关键标准:关系微分和维度等距。受这些发现的启发,我们提出了一种基于 GNN 的新颖方法,即关系反射实体对齐(RREA),它利用了一种称为关系反射的新转换操作。实验结果表明,我们的模型在所有现实世界数据集中始终被评为最佳模型,并且在 Hits@1 上的性能优于最先进的方法 5.8% 以上。
论文链接:
https://arxiv.org/pdf/2008.07962.pdf
论文代码:
于 GNN 的新颖方法,即关系反射实体对齐(RREA),它利用了一种称为关系反射的新转换操作。实验结果表明,我们的模型在所有现实世界数据集中始终被评为最佳模型,并且在 Hits@1 上的性能优于最先进的方法 5.8% 以上。
论文链接:
https://arxiv.org/pdf/2008.07962.pdf
论文代码:
















 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











