










A benchmark and comprehensive survey on knowledge graph entity alignment via representation learning
Abstract
本文提供了使用表示学习新方法的代表性实体对齐技术的综合教程式综述。
1 Introduction
知识库是一种用于存储复杂的结构化和非结构化信息(通常是事实或知识)的技术。知识图谱(KG)是一种以图结构或拓扑为模型的知识库。
KGs 最重要的任务之一是实体对齐(entity alignment, EA),其目的是从不同 KGs 中识别代表相同现实世界实体的多个实体。
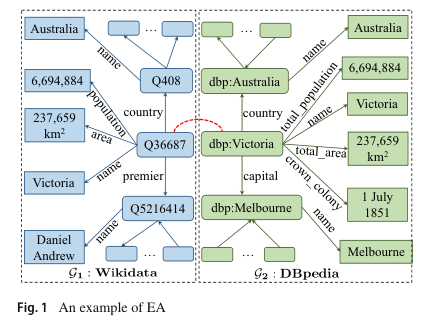
2 Preliminaries
相关问题(类似于KGs上的EA):两个源都是结构化:实体匹配、对象识别、记录链接,解决方案:寻找内容相似的数据库记录。
一个源是结构化的,另一个源是非结构化的:实体消解、实体链接,解决方案:找到与自然句子中识别出的命名实体内容相似的KG实体。
传统的EA技术使用数据挖掘或数据库方法(通常是启发式方法)来识别相似的实体(一些专注于通过不同实体相似性度量来提高实体匹配的有效性,其他一些侧重于实体匹配的效率)。这种方法很难实现高准确率和泛化。在过去的几年中,大量的EA研究采用深度学习的新方法来学习KG的有效向量表示(即嵌入),然后基于学到的表示执行 EA,从而获得了更好的准确率(表示学习方法)。它们还具有更好的泛化性,因为它们很少依赖特定的启发式算法。
现有EA论文讨论的框架缺少重要的机制(KG语义信息(关系谓词、属性谓词和属性值的字符串))的使用,使得这些框架不适用与许多EA技术
3 Generic framework of embedding-based EA
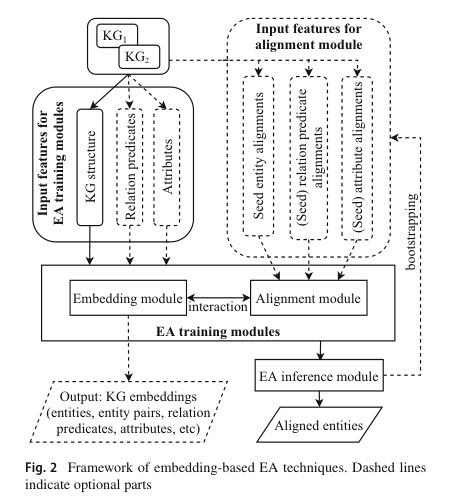
基于嵌入的EA方法通常由三个组件组成:嵌入模块、对齐模块和推理模块(嵌入模块和对齐模块可以交替或联合训练,两者共同构成了EA的训练模块)
嵌入模块: 旨在学习(通常是低维)向量表示,即实体的嵌入。分别计算每个KG的嵌入,使得G1和G2的嵌入落入不同的向量空间。原始信息可以作为嵌入模块的输入特征:KG结构(在原始KG数据中以关系三元组的形式存在)、关系谓词、属性谓词和属性值(可合并为“属性”)。输出:实习、实体对、关系谓词、属性等的嵌入。
KG嵌入:将输入特征“编码”到目标嵌入的过程。嵌入KG结构的机器学习模型,简称为KG结构嵌入模型,是 EA 技术的骨架。其他类型的信息(即关系谓词、属性谓词和属性值)通常采用字符串的形式。
KG结构嵌入模型主要遵循基于平移和基于 GNN 的两种范式之一。基于平移的模型主要利用关系三元组,而基于 GNN 的模型主要利用实体的邻域。
对齐模块: 旨在将两个KG的嵌入统一到同一个向量空间中,以便可以识别出对齐的实体。EA技术通常使用一组手动对齐的实体、关系谓词或属性,称为种子对齐。种子对齐通常作为输入特征来训练对齐模块(输入特征可以是原始信息,例如 KG 结构、关系谓词和属性,以及手动或自动创建的实体/关系/属性对齐。)。种子用于计算嵌入模块的损失函数,以学习统一的向量空间。损失函数定义的典型示例:
L = ∑ ( e 1 , e 2 ) ∈ S ∑ ( e 1 ′ , e 2 ′ ) ∈ S ′ × max ( 0 , [ γ + f a l i g n ( e 1 , e 2 ) − f a l i g n ( e 1 ′ , e 2 ′ ) ] ) \begin{aligned} \mathcal{L}&=\sum_{(e_1,e_2)\in\mathcal{S}}\sum_{(e_1^{\prime},e_2^{\prime})\in\mathcal{S}^{\prime}}\\&\times\max\left(0,\left[\gamma+f_{\mathrm{align}}(e_1,e_2)-f_{\mathrm{align}}(e_1^{\prime},e_2^{\prime})\right]\right) \end{aligned} L=(e1,e2)∈S∑(e1′,e2′)∈S′∑×max(0,[γ+falign(e1,e2)−falign(e1′,e2′)])
损失函数旨在最小化种子实体对齐S中的实体对之间的距离,并最大化破坏的种子对齐S′中实体对之间的距离 ( e 1 ′ , e 2 ′ ) (e_1′, e_2′) (e1′,e2′)。破坏的种子对齐是通过用随机实体替换种子对齐中的实体而获得的负样本。
对齐评分函数:一对实体之间的距离由 f a l i g n f_{align} falign计算,称为对齐评分函数。它表明两个实体的(不)相似程度;两个实体越对齐(即彼此相似), f a l i g n f_{align} falign越小。最常用的对齐评分函数是余弦相似度、 L 1 L_1 L1范数(曼哈顿距离)和 L 2 L_2 L2范数(欧几里得距离)。
当有限的种子对齐可用时,自学习机制(bootstrapping)是一种常见的策略。
EA推理模块产生的那些对齐的实体/属性/关系作为训练数据反馈给对齐模块,这个过程可能会迭代多次。自学习机制可能有助于减少人力,但代价是更多的计算,因为它会多次迭代训练。
推理模块: 旨在预测来自 G 1 G_1 G1和 G 2 G_2 G2的一对实体是否对齐。
推理模块最常用的方法是最近邻搜索(NNS),它根据从 EA 训练模块获得的嵌入从 G 1 G_1 G1和 G 2 G_2 G2中找到与 e 1 e_1 e1最相似的实体。常用的相似度度量包括余弦相似度、欧几里得距离和曼哈顿距离。
NNS存在多对一对齐(来自一个KG的两个不同实体与来自另一个KG的相同实体对齐):添加一对一约束。
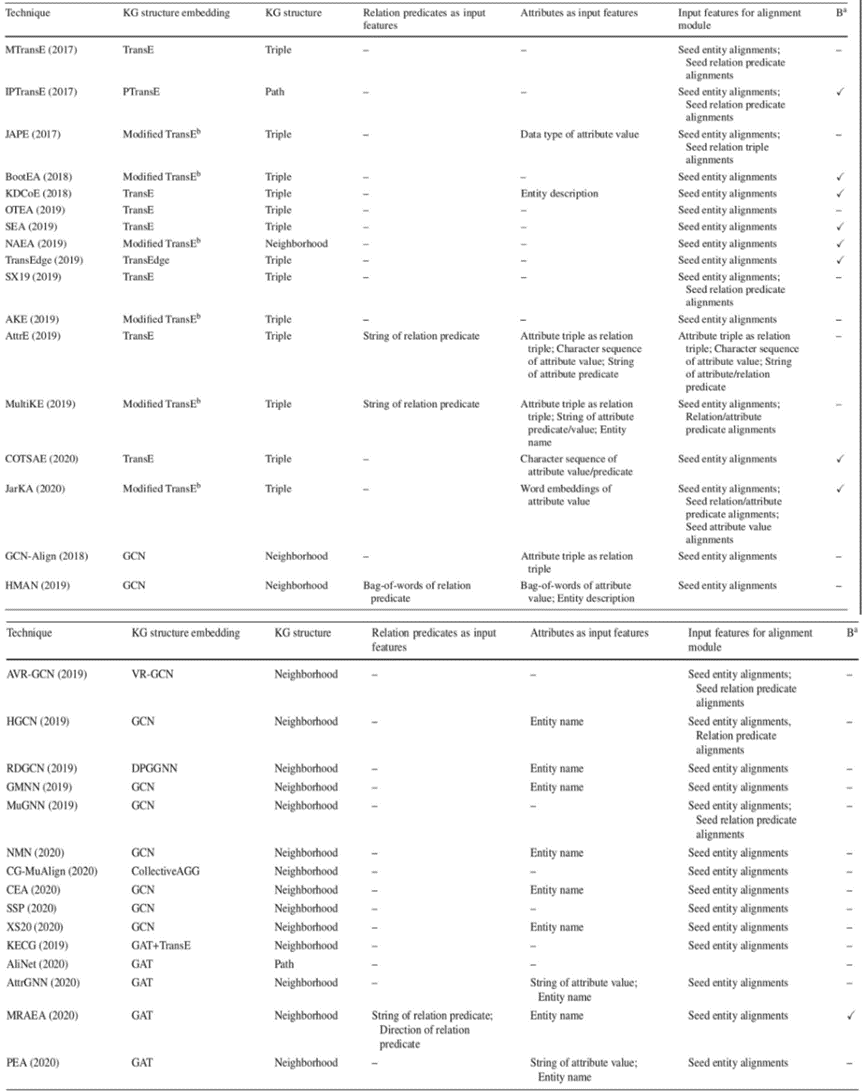
早期技术使用较少种类的信息。较新的技术使用所有四种类型(KG结构、关系谓词、属性谓词和属性值)的原始信息作为训练模块的输入特征,在对齐模块中也使用了各种类型的特征。通过实验研究发现,使用更多类型输入特征的技术往往具有更好的性能。
4 KG structure embedding models
4.1 Translation-based embedding models
基于平移的嵌入模型(单独处理每个三元组):基于平移的嵌入模型的本质是将KG中的关系视为头尾实体之间在向量空间中的“平移”运算。
TransE 是第一个基于平移的嵌入模型,它将实体和关系都嵌入到一个统一的(通常是低维的)向量空间中。主要思想是找到一套向量表示(实体和关系的嵌入),使得三元组评分函数为0.(实际上,所有实体和关系谓词的嵌入都是未知的,需要学习。此外,很可能不存在一套嵌入,使得所有关系的ftriple = 0。因此,学习的目的变成了找到一套嵌入来最小化ftriple对于KG中所有关系的和)
三元组评分函数:函数值越小,(h, r, t)越有可能是真实关系三元组
f triple ( h , r , t ) = ∣ ∣ h + r − t ∣ ∣ f_\text{triple}(h,r,t)=||h+r-t|| ftriple(h,r,t)=∣∣h+r−t∣∣
TransE模型的主要优点是它简单、易于理解,可以很好地处理一对一对称关系。**局限性:**在处理多对一、一对多、多对多等复杂关系时效果不佳。
负采样策略:它们是将真实三元组的头或尾实体用随机实体替换得到的。学习过程通常随机初始化所有嵌入,然后通过梯度下降最小化以下基于边界损失的目标函数:
L = ∑ ( h , r , t ) ∈ T r ∑ ( h ′ , r , t ′ ) ∈ T r ′ × max ( 0 , [ γ + f t r i p l e ( h , r , t ) − f t r i p l e ( h ′ , r ′ , t ′ ) ] ) \begin{aligned} \mathcal{L}&=\sum_{(h,r,t)\in \mathcal{T}_r}\sum_{(h^{\prime},r,t^{\prime})\in \mathcal{T}_r^{\prime}}\\&\times\max\left(0,\left[\gamma+f_{\mathrm{triple}}(h,r,t)-f_{\mathrm{triple}}(h^{\prime},r^{\prime},t^{\prime})\right]\right) \end{aligned} L=(h,r,t)∈Tr∑(h′,r,t′)∈Tr′∑×max(0,[γ+ftriple(h,r,t)−ftriple(h′,r′,t′)])
4.2 GNN-based embedding models
基于GNN的嵌入模型(专注于聚合来自实体邻域的信息,并结合图结构,以计算实体嵌入):
两个代表性模型:图卷积网络(GCN)和图注意力网络(GAT)
基于 GNN 的嵌入模型的本质是根据消息传递规则将邻域信息聚合到目标节点中,即嵌入信息通过边从相邻实体传播到目标实体。基于GNN的嵌入的优化目标是将具有相似邻域的实体映射为嵌入空间中彼此靠近的嵌入。
图卷积网络(GCN): 遵循图中消息传递的规则,通过聚合邻居和自身的特征,将目标节点的嵌入计算为低维向量(即嵌入)。
Q ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 Q ( l ) W ( l ) ) \boldsymbol{Q}^{(l+1)}=\sigma\left(\tilde{\boldsymbol{D}}^{-\frac{1}{2}}\tilde{\boldsymbol{A}}\tilde{\boldsymbol{D}}^{-\frac{1}{2}}\boldsymbol{Q}^{(l)}\boldsymbol{W}^{(l)}\right) Q(l+1)=σ(D~−21A~D~−21Q(l)W(l))
图注意力网络(GAT): 使用注意力机制聚合来自邻域的信息,使得可以关注最相关的邻居。
q i ( l + 1 ) = σ ( ∑ j ∈ N i α i j W q ( j ) l ) \boldsymbol{q}_i^{(l+1)}=\sigma\left(\sum_{j\in\mathcal{N}_i}\alpha_{ij}\boldsymbol{W}\boldsymbol{q}_{(j)}^l\right) qi(l+1)=σ j∈Ni∑αijWq(j)l
GAT类似于GCN,主要区别在于GCN的边权重(即邻接矩阵)不是学习的,但 GAT 的边权重(即注意力)是学习的。
变体:其他对称矩阵来代替GCN的邻接矩阵(例如,AGCN和DGCN)
5 Translation-based EA techniques
5.1 Techniques that only use KG structure
仅使用KG结构的技术:
MTransE: 使用 TransE将来自每个KG的实体和关系谓词嵌入到不同的嵌入空间中,对齐模块通过最小化所有种子关系三元组对齐的对齐评分函数的和来学习跨KG变换,如下:
L = ∑ ( t r 1 , t r 2 ) ∈ S t f a l i g n ( t r 1 , t r 2 ) {\mathcal L}=\sum_{(tr_{1},tr_{2})\in{\mathcal S}_{t}}f_{\mathrm{align}}(tr_{1},tr_{2}) L=(tr1,tr2)∈St∑falign(tr1,tr2)
为了计算对齐分数,MTransE使用三种策略来构建跨KG变换,包括基于距离的轴校准、变换向量和线性变换。根据实验研究,采用线性变换策略的MTransE性能最好。MTransE的推理模块使用NNS。
IPTransE: IPTransE 的对齐模块使用基于种子实体对齐的三种不同策略学习G1G2之间的变换:基于平移、线性变换和参数共享。在训练过程中,IPTransE采用引导并有两种策略将新对齐的实体添加到种子中:硬策略和软策略。其他技术通常应用硬策略,将新对齐的实体直接附加到种子对齐集合中,这可能会导致错误传播。在软策略中,可靠性分数被分配给新对齐的实体以减轻错误传播,这对应于对齐实体之间的嵌入距离。这可以通过向目标函数中添加一个损失项来实现。
BootEA: 将EA建模为一对一的分类问题,将一个实体的对齐实体视为该实体的标签。它通过既从标记数据(种子实体对齐)中,又从未标记数据(预测对齐实体)中引导,迭代地学习分类器。当一个真实三元组中的实体,无论是头还是尾,存在于当前对齐的实体集S中,用S中的对齐实体替换该实体,生成一个新的三元组。嵌入模块的损失函数为:
L e = ∑ ( h , r , t ) ∈ T r max ( 0 , [ f t r i p l e ( h , r , t ) − γ 1 ] ) + β 1 ∑ ( h ′ , r ′ , t ′ ) ∈ T r ′ max ( 0 , [ γ 2 − f t r i p l e ( h ′ , r ′ , t ′ ) ] ) \begin{aligned} \mathcal{L}_{e}& =\sum_{(h,r,t)\in\mathcal{T}_{r}}\max\left(0,\left[f_{\mathrm{triple}}(h,r,t)-\gamma_{1}\right]\right) \\ &+\beta_{1}\sum_{(h^{\prime},r^{\prime},t^{\prime})\in\mathcal{T}_{r}^{\prime}}\max\left(0,\left[\gamma_{2}-f_{\mathrm{triple}}\left(h^{\prime},r^{\prime},t^{\prime}\right)\right]\right) \end{aligned} Le=(h,r,t)∈Tr∑max(0,[ftriple(h,r,t)−γ1])+β1(h′,r′,t′)∈Tr′∑max(0,[γ2−ftriple(h′,r′,t′)])
BootEA 的对齐模块是一对一的分类器,与公式1中的对齐方式不同,它使用 G 1 G_1 G1中的实体分布与 G 2 G_2 G2中预测类(即对齐实体)的分布之间的交叉熵损失:
L a = − ∑ e 1 ∈ E 1 ∑ e 2 ∈ E 2 ϕ e 1 ( e 2 ) log π ( e 2 ∣ e 1 ) \mathcal{L}_a=-\sum_{e_1\in\mathcal{E}_1}\sum_{e_2\in\mathcal{E}_2}\phi_{e_1}(e_2)\log\pi(e_2\mid e_1) La=−e1∈E1∑e2∈E2∑ϕe1(e2)logπ(e2∣e1)
BootEA的整体目标函数 L = L e + β 2 L a \mathcal L = \mathcal L_e + \beta_2\mathcal L_a L=Le+β2La,其中 β 2 \beta_2 β2是一个平衡超参数。
NAEA: 将 EA 表述为一对一的分类问题,但结合了基于平移和基于 GAT 的范式。NAEA除了关系级信息外,还嵌入了邻居级信息。
TransEdge: 解决了 TransE 的缺陷,即其关系谓词嵌入与实体无关,但实际上关系谓词嵌入应该取决于其上下文,即头实体和尾实体。TransEdge 提出了一种以边为中心的平移嵌入模型,该模型将关系谓词的上下文化(contextualized)嵌入视为从头实体到尾实体的平移。它将关系谓词上下文化为不同的边嵌入,其中关系谓词的上下文由其头和尾实体指定。通过三元组评分函数实现:
f t r i p l e ( h , r , t ) = ∥ h + ψ ( h c , t c , r ) − t ∥ f_{\mathrm{triple}}(h,r,t)=\|\boldsymbol{h}+\psi(\boldsymbol{h}_{c},\boldsymbol{t}_{c},\boldsymbol{r})-\boldsymbol{t}\| ftriple(h,r,t)=∥h+ψ(hc,tc,r)−t∥
5.2 Techniques that exploit relation predicates and attributes
利用关系谓词和属性的技术:
JAPE: JAPE的嵌入模块有两个组件:结构嵌入和属性嵌入。结构嵌入是分别在 G 1 G_1 G1和 G 2 G_2 G2上使用TransE获得的,分别产生两个基于结构的实体嵌入矩阵 E s 1 E_s^1 Es1和 E s 2 E_s^2 Es2。属性嵌入是通过建模同一实体内或一对对齐种子实体间的属性共现得到的。
KDCoE: 建立在MTransE之上,通过实体描述(即 KG 中实体的文字描述)的嵌入来移动(shift)实体嵌入,实体描述被视为一种特殊属性三元组,其中属性值是对实体的文字描述。
AttrE: 是第一个利用属性值的技术。唯一不需要种子对齐的EA技术。AttrE 的嵌入模块使用TransE来学习来自G1和G2的实体的 KG 结构嵌入。AttrE的主要新颖之处在于对属性值的语义进行编码,并提出了三种编码方法:平均字符嵌入、LSTM聚合字符嵌入和聚合n-gram字符嵌入。另一个想法将属性三元组也解释为平移运算来学习属性嵌入,如下所示:
f triple ( e , a , v ) = ∥ e + a − τ ( v ) ∥ f_\text{triple}(e,a,v)=\|\boldsymbol{e}+\boldsymbol{a}-\boldsymbol{\tau(v)}\| ftriple(e,a,v)=∥e+a−τ(v)∥
MultiKE: 在各种特征上使用多视图学习。MultiK的嵌入模块将知识图谱的特征分为三个子集,称为视图:名称视图、关系视图和属性视图。为每个视图学习实体嵌入,然后进行组合。
COTSAE: 交替训练结构和属性嵌入,然后组合通过两种嵌入获得的对齐结果。
6 GNN-based EA techniques
基于GNN的EA技术
基于GNN的EA技术分为基于GCN和基于GAT的技术。它们通常通过实体的邻域对KG结构进行编码,其中许多将属性作为嵌入模块的输入特征,因为对齐的实体往往具有相似的邻域和属性。大多数基于GNN的技术在训练中仅使用种子实体对齐而不是其他类型的种子对齐。
6.1 GCN-based EA techniques
- 基于GCN的EA技术:
GCN-Align:从实体的结构信息中学习实体嵌入。GCN-Align还通过将属性三元组视为关系三元组来利用它们。具体来说,GCN-Align使用两个共享权重矩阵的GCN将 G 1 G_1 G1和 G 2 G_2 G2(每个KG一个GCN)的实体嵌入到统一空间中,由以下公式描述:
[ H s ( l + 1 ) ∥ H a ( l + 1 ) ] = σ ( D ^ − 1 2 A ^ D ^ − 1 2 [ H s ( l ) W s ( l ) ∥ H a ( l ) W a ( l ) ] ) [H_{s}^{(l+1)}\|H_{a}^{(l+1)}]=\sigma(\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}[H_{s}^{(l)}W_{s}^{(l)}\|H_{a}^{(l)}W_{a}^{(l)}]) [Hs(l+1)∥Ha(l+1)]=σ(D^−21A^D^−21[Hs(l)Ws(l)∥Ha(l)Wa(l)])
GCN-Align是通过最小化一个基于边界的损失函数来训练的。考虑到结构和属性嵌入,GCN-Align定义的对齐评分函数如下:
f a l i g n ( e 1 , e 2 ) = β ∥ h s ( e 1 ) − h s ( e 2 ) ) ∥ L 1 d s + ( 1 − β ) ∥ h a ( e 1 ) − h a ( e 2 ) ∥ L 1 d a \begin{aligned} f_{\mathrm{align}}(e_1,e_2) &=\beta\frac{\|\boldsymbol{h}_s(e_1)-\boldsymbol{h}_s(e_2))\|_{L_1}}{d_s}\\ &+(1-\beta)\frac{\|\boldsymbol{h}_a(e_1)-\boldsymbol{h}_a(e_2)\|_{L_1}}{d_a} \end{aligned} falign(e1,e2)=βds∥hs(e1)−hs(e2))∥L1+(1−β)da∥ha(e1)−ha(e2)∥L1
HGCN: 利用关系表示来改进EA中的对齐过程。为了合并关系信息,HGCN在以下三个阶段联合学习实体和关系谓词嵌入:
第1阶段通过名为Highway-GCN的GCN变体计算实体嵌入,它将实体嵌入到统一的向量空间中。
第2阶段基于其头和尾实体表示获得关系谓词嵌入。该阶段首先分别计算连接到一个关系谓词的所有头实体和尾实体的平均嵌入。然后,两个平均嵌入的连接经过线性变换后得到关系谓词的嵌入。
第3阶段再次使用Highway-GCN,输入是第1阶段计算的实体嵌入以及与实体相关的所有关系谓词嵌入的和的连接。对齐模块将两个KG的Highway-GCN的输出映射到一个统一的向量空间。
GMNN: 将EA问题表述为两个主题实体图之间的图匹配。KG中的每个实体都对应一个主题实体图,该图由实体的单跳邻居和对应的关系谓词(即边)组成。这样的图表示实体的局部上下文信息。GMNN使用图匹配模型对两个主题实体图的相似度进行建模,用以表示两个对应实体对齐的概率。
图匹配模型由四层组成,包括输入表示层、节点级匹配层、图级匹配层和预测层。输入表示层使用GCN对两个主题实体图进行编码并获得实体嵌入。节点级匹配层计算来自两个主题实体图的每对实体的嵌入之间的余弦相似度。图级匹配层在每个主题实体图上运行GCN,以进一步在整个主题实体图中传播局部信息。然后将GCN的输出嵌入送入一个全连接神经网络,接一个逐元素的最大或均值池化方法,以获得每个主题实体图的图匹配表示。最后,预测层将图匹配表示作为输入,并使用softmax回归函数来预测实体对齐。
MuGNN:解决了KG之间的结构异质性,这种异质性可能导致应该对齐的实体的嵌入不相似。为了调和 G 1 G_1 G1和 G 2 G_2 G2的结构之间的异质性(即差异),MuGNN在嵌入模块中使用多通道 GNN,在面向KG补全和修剪专有实体的多个通道中编码KG。
MuGNN的一个通道,通过对每个K使用Horn规则来添加KG中缺失的关系谓词,以进行 KG 补全。然后通过参数共享将生成的两组规则相互传递。另一个通道修剪“专有实体”,即仅出现在两个KG之一的那些实体。
NMN: 同时学习 KG 结构信息和邻域差异,以便在存在结构异质性的情况下更好地捕获实体之间的相似性。旨在解决 KG 之间的结构异质性。
NMN 连接实体嵌入及其邻域表示以获得用于 EA 的最终嵌入。EA 通过测量最终嵌入之间的欧几里德距离来实现。
CEA: 考虑实体之间对齐决策的依赖性。提出了一个集体EA框架。使用结构、语义和字符串信号来捕获源和目标KG中实体之间相似性的不同方面,由三个独立的相似性矩阵表示。具体来说,结构相似度矩阵是基于GCN 输出的嵌入矩阵并利用余弦相似度计算得到的,语义相似度矩阵是根据词嵌入计算的,字符串相似度矩阵是通过实体名称之间的Levenshtein距离计算的。这三个矩阵进一步组合成一个融合矩阵。然后,CEA将EA表示为融合矩阵上经典的稳定匹配问题,以捕获相互依赖的EA决策,该决策由延迟接受算法解决。
6.2 GAT-based EA Techniques
- 基于GAT的EA技术
KECG: 旨在通过联合训练基于GAT的跨图模型和基于TransE的知识嵌入模型来协调KG之间的结构异质性问题。
KECG 中的跨图模型使用两个KG上的两个GAT来嵌入实体,对图结构信息进行编码。GAT中的注意力机制有助于忽略不重要的邻居并减轻结构异质性问题。GAT的投影矩阵W设置为对角矩阵,这减少了要学习的参数数量并增加了模型的泛化性。
KECG 中的知识嵌入模型使用TransE对每个 KG 中的结构信息进行单独编码。KECG 的总体目标函数是来自跨图模型和知识嵌入模型的损失函数的加权和。
AliNet: 是基于观察到来自 G 1 G_1 G1和 G 2 G_2 G2的一些对齐实体不共享相似的邻域结构。通过既考虑直接邻居也考虑远邻来解决本该对齐的实体可能会被其他基于 GNN的EA技术遗漏。
AliNet通过实体邻域信息的受控聚合来学习实体嵌入。首先,使用 GCN 聚合直接(即单跳)邻居的信息。在 AliNet 每一层的最后,利用门控机制结合来自一跳和两跳邻居的信息。
MRAEA: 除了考虑从关系三元组结构中学习的结构信息外,还考虑元关系语义,包括关系谓词、关系方向和逆关系谓词。元关系语义通过结合元关系的嵌入(meta-relation-aware embedding)和结合关系的GAT(relation-aware GAT)集成到结构嵌入中。
计算结合元关系的嵌入(实体和关系谓词嵌入的连接):首先用“逆关系谓词”替换原始关系谓词,来为每个三元组创建一个“逆三元组”以扩展关系三元组集合,同时保持相同的头和尾实体不变。其次,目标实体的结合元关系的嵌入的实体和关系嵌入分量分别通过对相邻实体的分量进行平均来计算。
通过加入目标实体邻居的结合元关系的嵌入,结合关系的GAT生成每个实体的结合结构和关系的嵌入。
EPEA: 通过成对连接图(pairwise connectivity graph,PCG)学习实体对的嵌入,而不是单个实体的嵌入。EPEA首先生成PCG,其节点是来自 G 1 G_1 G1和 G 2 G_2 G2的实体对。在生成所有实体对作为 PCG 的节点后,基于属性相似性,EPEA使用CNN将实体对的属性编码为嵌入。然后将这些属性嵌入输入到GAT中,该GAT进一步结合结构信息并产生分数,该分数表示实体对是对齐实体对的概率。然后将该评分函数用作损失函数 L = ∑ ( e 1 , e 2 ) ∈ S ∑ ( e 1 ′ , e 2 ′ ) ∈ S ′ max ( 0 , [ γ + f a l i g n ( e 1 , e 2 ) − f a l i g n ( e 1 ′ , e 2 ′ ) ] ) \mathcal{L}=\sum_{(\mathrm{e}_1,\mathrm{e}_2)\in\mathcal{S}}\sum_{(\mathrm{e}_1^{\prime},\mathrm{e}_2^{\prime})\in\mathcal{S}^{\prime}}\max\left(0,\left[\gamma+\mathrm{f}_{\mathrm{align}}(\boldsymbol{e}_1,\boldsymbol{e}_2)-\mathrm{f}_{\mathrm{align}}(\boldsymbol{e}_1^{\prime},\boldsymbol{e}_2^{\prime})\right]\right) L=∑(e1,e2)∈S∑(e1′,e2′)∈S′max(0,[γ+falign(e1,e2)−falign(e1′,e2′)])中的 f a l i g n f_{align} falign来训练整个模型。推理模块以实体对嵌入作为输入,通过对评分函数值执行二分类来预测对齐实体对。
AttrGNN: 利用一个统一网络从关系三元组和属性三元组中学习嵌入。它将每个 KG 划分为四个子图,分别是实体名称的属性三元组、文字值的属性三元组、数字值的属性三元组和剩余三元组(即关系三元组)。对于每个子图,使用 GAT并基于属性以及KG 结构计算实体嵌入;然后,根据实体嵌入计算 G 1 G_1 G1和 G 2 G_2 G2之间的相似度矩阵。最后,对四个相似度矩阵进行平均,得到推理模块的最终相似度矩阵。
7 Datasets and experimental studies
7.1 Limitations of existing datasets
现有数据集有几个显著的局限性:双射、缺乏名称多样性和小规模。
双射: 许多现有论文,包括一些基准测试论文,都使用了由两个 KG 组成的数据集,其中一个 KG 中的几乎每个实体在另一个 KG 中都有且只有一个对齐的实体,即两个 KG 之间存在双射。支持此类数据集的应用对齐两个不同语言的 KG,即多语言EA。
缺乏名称多样性: 以前的大多数 EA 数据集都是由具有相同来源的KG构建的。来自两个KG的实体名称可能具有相同的表面标签;这样的名称成为“狡猾的特征”,可以用来轻松实现100%准确的EA(我们称之为缺乏名称多样性问题)。
小规模: 大多数现有数据集都是小规模到中等大小。
提出的基准DWY-NB具有所有三个理想属性:非双射、名称多样性和大尺寸。
7.2 Limitations of existing experimental studies
7.3 Our proposed benchmark DWY-NB
提出了一个名为DWY-NB(DW-NB、DY-NB)的新基准,其中 NB 代表非双射。该基准由两个常规规模的数据集和本小节末尾描述的大规模数据集组成;每个常规规模的数据集都由一对可用于评估EA技术的KG组成。DW-NB的两个KG分别是DBpedia和Wikidata的子集。DY-NB的两个KG分别是DBpedia和Yago的子集。DBpedia和Wikidata中的实体间的100,000个对齐的列表作为种子实体对齐。
解决双射问题:从两个KG的每一个中都随机删除一定百分比(默认为25%)的实体;确保从一个KG中删除的实体与从另一个KG中删除的实体不同,因此不是一个KG中的每个实体都会在另一个KG中具有对齐的实体。
解决名称多样性不足:为实体名称属性添加多样性,36% 的对齐实体具有不同的实体名称。
7.4 Experiments and results
实验1:种子实体对齐的影响 EA技术有效性的主要评估指标是hits@1(或 hits@k),它表示在 top-k 预测的对齐实体中正确对齐实体的百分比。
种子越多,所有技术的准确率就会越高。平均而言,利用属性三元组的技术比不用的性能更好。
实验2:属性三元组的效果 评估了利用属性三元组可以获得多少收益。
对于每一种技术,“使用属性”版本都优于“不使用属性”版本,特别是对于那些原本使用属性三元组的技术。这些表明,充分利用属性三元组可以显著提高准确率。
实验3:对齐模块对 KG 嵌入的影响 EA技术的训练优化两个目标,即KG嵌入和两个KG的对齐(联合或交替优化)
使用属性三元组的技术比不使用的技术获得更好的准确率。从EA技术获得的 KG 嵌入在下游任务中的性能可能稍好或稍差,具体取决于KG结构嵌入的范式。
实验4:多语言 本实验评估各种技术在多语言KG上的表现,采用先翻译成同一种语言的方法。
通过翻译方法使用属性,所有技术都有显著改进,包括原本就执行多语言EA 的技术(主要是所有基于GNN的技术)。为单语言EA设计的技术可以通过利用语义信息(例如属性)和自动翻译来很好地执行多语言EA。
实验5:可伸缩性 本实验评估各种技术随数据大小增长的表现。
对于相同的数据集大小,所有测试技术的运行时间相似。随着实体数量的增加,所有技术的准确率都会有所下降。这是因为对于一个KG中的相同实体,在更大的数据集的情况下,另一个KG中有更多与其相似的实体,这使得正确预测对齐的实体变得更加困难。
8 Conclusions and future directions
提出了一个框架来捕获这些技术的关键特征,提出了一个基准DWY-NB来解决现有基准数据集的局限性,并使用所提出的数据集进行了广泛的实验。实验研究显示了这些技术的比较性能,以及各种因素如何影响性能。从实验中得出的一个结论是,充分利用诸如属性三元组之类的语义信息可以显著提高准确率。AttrE和MultiKE在我们实验的各种设置中始终表现最佳。
在基准方面,可能会进一步探索更多的实验设置,例如改变具有相同名称的实体的比例(即“狡猾”特征的比例),以及关系三元组和属性三元组之间的比例。
深度学习小白,知识图谱方向,欢迎大家一起交流学习~
A Benchmark and Comprehensive Survey on Knowledge Graph Entity…

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











