







 这篇博客介绍了Pandas的两种核心数据结构——Series和DataFrame。Series是一维数据结构,包含data、index、dtype和name四个属性,可以通过列表或字典创建。DataFrame是二维表格数据,具有data、index、columns和dtype属性,可以使用二维列表或字典创建。博客还详细讲解了如何获取和操作这些数据结构的内容。
这篇博客介绍了Pandas的两种核心数据结构——Series和DataFrame。Series是一维数据结构,包含data、index、dtype和name四个属性,可以通过列表或字典创建。DataFrame是二维表格数据,具有data、index、columns和dtype属性,可以使用二维列表或字典创建。博客还详细讲解了如何获取和操作这些数据结构的内容。
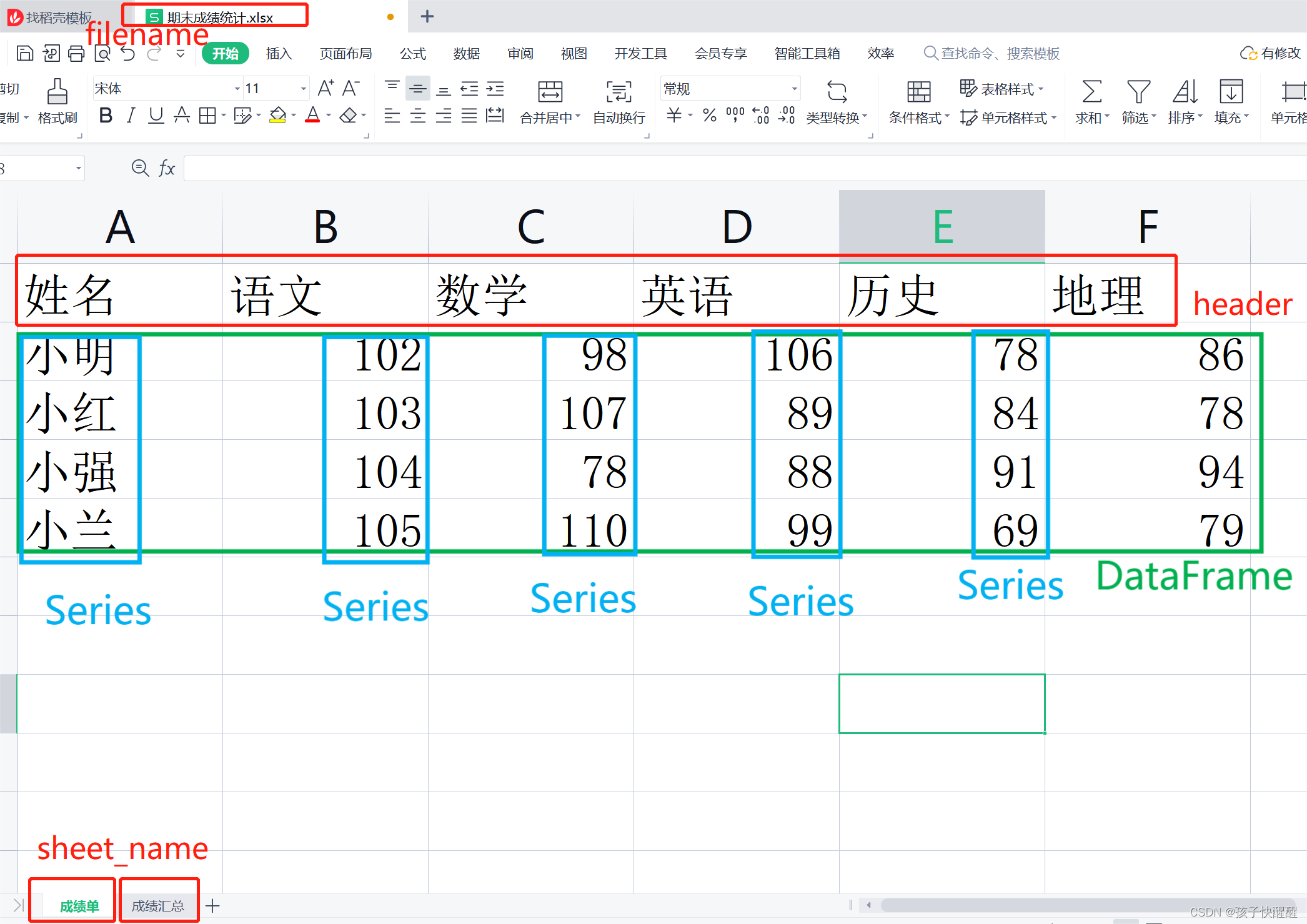
一、pandas有两种基本数据结构:DataFrame和Series
1、DataFrame可以看成一个矩形表格(比如m行n列的数据)甚至是整个表格,存储的是二维的数据。
2、Series则是DataFrame中的一列,存储的是一维的数据。
示例如下:
二、Series
1、属性组成
Series中包含data(序列值)、index(行索引)、dtype(存储类型)、name(序列名)四部分属性
2、创建Series
①使用列表创建(其中index、dtype、name等属性并不是必需要设置的)
import pandas as pd
s = pd.Series(data = [102,103,104,105],
index = ['小明','小强','小红','小兰'],
dtype = 'int',
name = '语文')
print(s)运行结果如下:
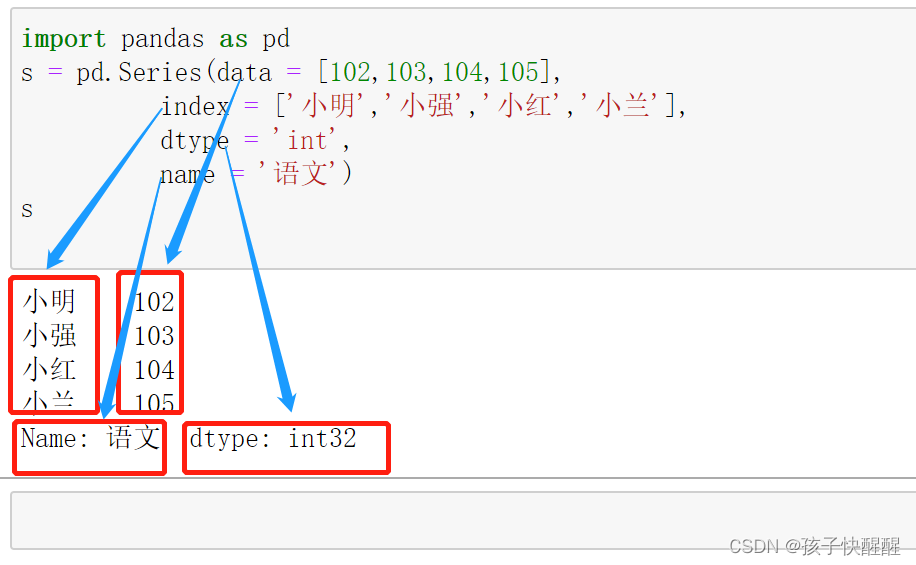
其中dtype:可选int、float、string、category、object
object代表混合类型,比如当data为['小红',23,158.4]这样的数据,即数据中存储了不同类型的数据时,dtype则为object
②使用字典创建(字典的键为索引index,值为数据data)
import pandas as pd
s = pd.Series({'小明':102,'小强':103,'小红':104,'小兰':105})
print(s)运行结果如下:

2、获取属性内容
通过“.”来获取
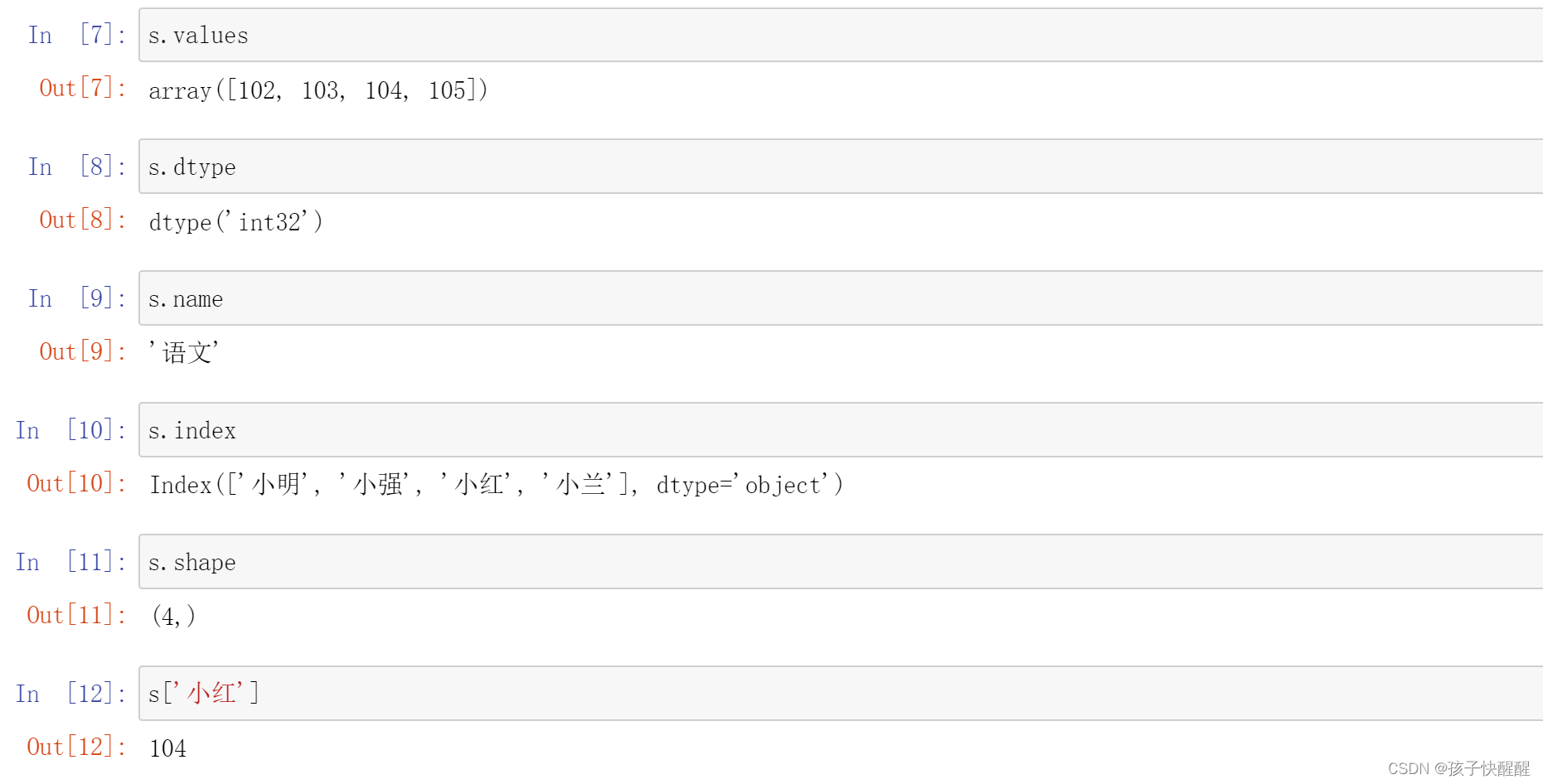
print(s.values)#获取data
print(s.dtype)#获取数据类型
print(s.name)#获取数据属性名
print(s.index)#获取数据行索引
#获取数据长度
print(s.shape) #(4,)
print(s.size) #4
print(len(s)) #4
print(s['小红'])#获取索引为“小红”时所对应的数据
运行结果如下:
3、获取部分数据
①获取前几行数据:head()
②获取后几行数据:tail()
③获取一部分数据:take()、切片
print(s.head()) #获取前五行数据
print(s.head(2)) #获取前两行数据
print(s.tail()) #获取后五行数据
print(s.tail(2)) #获取后两行数据
print(s.take([2,3]) #获取第三、四行数据
#切片操作,视为左闭右开区间,即[2,4),即取值2,3,也即获取第三、四行数据
print(s.take[2:4])
'''左闭右开区间[2,4),即取值2,3,也即第三、四行数据。
由于从第三行数据开始切片,步数为2,因此下一步取第五行数据,
但第五行数据不在[2,4)的范围,因此只能获取到第三行数据'''
print(s.take[2:4:2]) 三、DataFrame
1、属性组成
DataFrame的属性在Series的基础上增加了列索引columns,减少了name属性。
DataFrame的设置数据类型dtype时,表示要强制的数据类型,但只允许使用一种数据类型。
如果没有定义强制的数据类型,就会自行推断
2、创建DataFrame
①使用列表创建(二维列表而不是一维列表)
其中一行列表表示一个学生的成绩
import pandas as pd
data = [[102,98,106,78,86],
[103,107,89,84,78],
[104,78,88,91,94],
[105,110,99,69,79]]
df = pd.DataFrame(data=data,
index = ['小明','小强','小红','小兰'],
columns = ['语文','数学','英语','历史','地理'])
print(df)输出df,运行结果如下: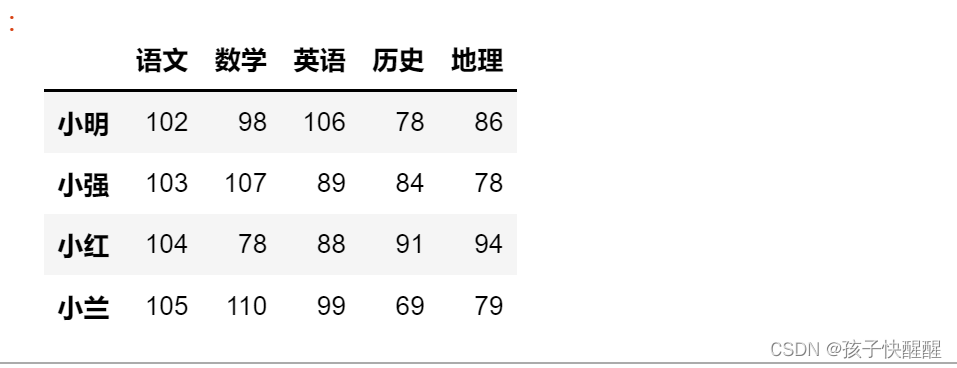
②使用字典创建(一个键对应一个列表而不是一个值)
其中一个列表表示一门课的所有成绩,所有的键构成了列索引
import pandas as pd
data = {'语文':[102,103,104,105],
'数学':[98,107,78,110],
'英语':[106,89,88,99],
'历史':[78,84,91,69],
'地理':[86,78,94,79]}
df = pd.DataFrame(data=data,index = ['小明','小强','小红','小兰'])3、获取属性内容
#返回列索引,一个列表
print(df.columns)
#获取列索引为‘语文’的数据
print(df['语文'])
#获取列索引为‘语文’和‘数学’的数据,两个中括号!!
print(df[['语文','数学']])
#获取行索引
print(df.index)
#获取所有列相应的数据类型
print(df.dtypes)
#获取数据
print(df.values)
#获取数据大小
print(df.shape) #返回元组:(4,5)运行结果如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











