






文章目录
信息的表示和处理
虚拟地址空间
程序将内存视为一个非常大的数组,数组的元素是由一个个的字节组成,每个字节都由一个唯一的数字来表示,我们称为地址,这些所有的地址集合就成为虚拟地址空间
Byte and bit
1Byte=8bit
字数据大小
字长决定了虚拟地址空间的最大可以到多少,也就是说一个字长为w位的机器,虚拟地址的范围是0-2^w-1
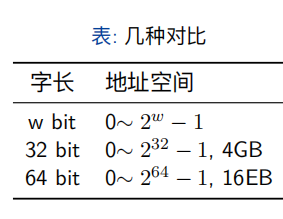
32位机器 虚拟地址空间最大为4GB
64位机器 虚拟地址空间最大为16EB
在迁移的过程中,大多数64位机器做了向后兼容,因此32位机器编译的程序可以运行在64位机器上
通过这条命令可以运行
linux>gcc -m32 -o hello32 hello.c
linux>gcc -m64 -o hello64 hello.c
通过修改编译选项,编译生成在64位机器上运行的程序
linux>gcc -m64 -o hello64 hello.c
寻址和字节顺序
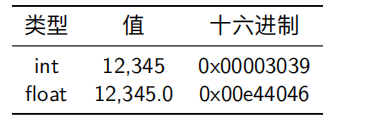
C语言中,支持整数和浮点数多种数据格式,下表列示不同数据类型在32位机器与在64位机器上所占字节数的大小

主要的区别在 long类型,char *
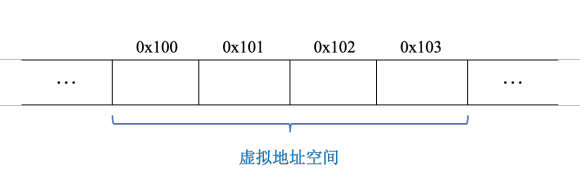
很多的数据类型都是占用了多个字节空间,对于我们需要存储的数据,需要知道的地址和数据是如何排布的
int 类型(0x01234567) 假设地址位于0x100,由于int类型占用4个字节。因此x被存储在0x100,0x101,0x102,0x103内存处
两个存储方法
- 大端法
最高有效字节存储在低地址处 - 小端法
最低有效字节存储在低地址处,最低有效字节存储在最前面
大多数Intel兼容机采用小端模式,IBM和Sun公司的机器大多数采用大端法。很多新的处理器支持双端法,可以配置成大端或者小端运行,利于基于ARM架构的处理器,支持双端法,但是Android系统和ios系统却只能运行小端模式。

测试代码
#include<stdio.h>
typedef unsigned char * byte_pointer;
//定义指针类型变量
void show_bytes(byte_pointer start ,int len){
int i;
for(i=0;i<len;i++){
printf("%.2x",start[i]);
//%x 输出指定参数的16进制形式
}
printf("\n");
}
void show_int(int x){
show_bytes((byte_pointer) &x,sizeof(x));
}

linux 和 window都是大端法
sun 公司是小端的
由于不同操作系统使用不同的存储分配规则,指针的值是完全不同的
指针的分配

浮点数和整数的存储方式是不同的
32位的机器,使用4字节的地址,64位的地址使用8字节的地址,虽然整型和浮点数都是对数值进行编码,但是却有着完全不同的字节模式
表示字符串的长度
字符串都是被编码为以NULL字符结尾的字符数组
结尾字符NULL的长度要被算上

const char*s=“abced”;
show_bytes((byte_pointer)s,strlen(s));

文本数据比二进制数据具有更强的平台独立性
结尾字符的十六进制被表示为0x00
使用ASCII码来表示字符,在任何系统上都会得到相同的结果,文本数据比二进制数据具有更强的平台独立性
布尔运算

C语言的位级运算
C语言中的一个特性就是支持按位进行布尔运算
确定位级表达式的结果的最好方法就是将16进制扩展成二进制表示,然后按位进行相应运算,最后转换成十六进制
位运算常见用法是实现掩码运算
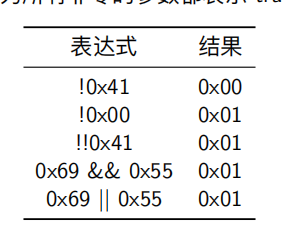
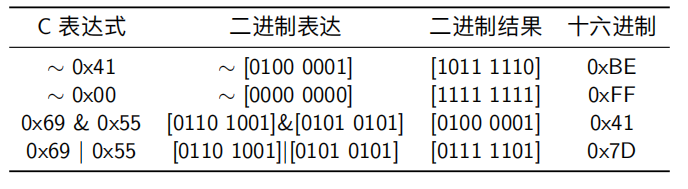
c语言中的位级运算
注意逻辑运算的运算符和位级运算容易混淆
逻辑运算还认为所有非零的参数都表示true
只有参数0表示false

数值信息的表示
有符号的二进制数的表示
十进制数有正负之分,二进制数也有正负之分,有正负号的二进制数称为真值
+1010110 -0110101就是真值。为了方便运算,在计算机中约定
0 正号
1 负号
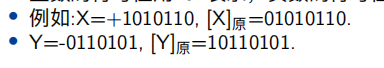
数值信息的表示
- 原码
0的原码不唯一
- 00000000
- 10000000

- 反码 保持符号位不变,其他数位1变为0 ,0变为1
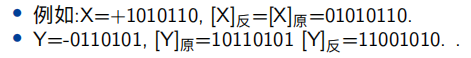
- 补码 保持符号位不变,其他数位1变为0 ,0变为1 最后再加1,负数的补码是它的反码加一
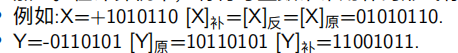
计算机中有符号整数常常用补码形式存储
对于任意一个数它的补码的补码是原码

计算机中二进制是从右向左运算的
补码的意义
两种理解方式
- -5原码1101最高位符号位,找补码需要找到与+5和10000的二进制码,我们只有4个bit,多出来的1会溢出达到效果,+5的原码是0101,设补码是1010这两个加起来是1111 ,还得+1才能让答案归零
- [-5]补码=1011此时最高位1不仅仅代表了负号,也代表了-8.。因此最高位代表-8,其余两个1表示+2,+1
-8+2+1=-5
通过补码我们可以直接知道对应的十进制数
对于一个4bit数据,补码能表达的最小数字为1000,即-8
最小的数字为1000 0000 即为 -2^8-1=-128 ,-128 最大的数为0111 1111 即为 127 下限为-128 共255个数字,也即1个Byte的范围为-128~127

无符号范围,二进制补码范围
Tmin=1000 Tmax=0111 UMax=1111
有符号和无符号数的转化
short int a =-123456;
unsigned short b = (unsigned short)a;
printf("a=%d,b=%d",a,b);


-
有符号转无符号
最高位Xw-1 等于1 此时有符号x表示一个负数,经过转换之后得到的无符号数等于有符号数加上2^w
当最高位Xw-1 等于0时,此时有符号数x表示一个非负数,得到的无符号数与有符号数是相等的。
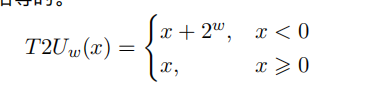
-
无符号转有符号
用U2T来表示无符号数到有符号数的函数映射,当最高位等于0的时候,无符号数可以表示的数值小于有符号数的最大值,此时转换后的数值不变
当最高位等于1时,无符号数可以表示的数值大于有符号数的最大值,在这种情况下,转换后得到有符号数等于该无符号数减去2^w
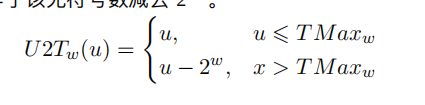
在c语言,在执行一个运算的时候,如果一个运算数是有符号数,另外一个运算数是无符号数,那么c语言会隐式的将有符号数强制转换成无符号数来执行运算
int i=-1;
unsigned int b=0;
if(a<b)
printf("-1<0");
else
printf("-1>0")
输出-1>0
第二个操作数是无符号数,第一个操作数a就隐式的转换成无符号数,这个表达式实际上比较的是
4294967295(2^32-1)<0
c语言中将一个较小的数据类型转换成较大的类型的时候,保持数值不变是可以的,但大转小不行
扩展一个数字的位表示
零扩展
将一个无符号数转换成更大的数据类型
将unsigned char 转换成unsigned short类型
a:8 bit
b:16 bit

当有符号数表示非负数时,最高位是 0,此时扩展的数位进行补零即可;
当有符号数表示负数时,最高位是 1,此时扩展的数位需要进行补 1。

转换定理
当有符号数从一个较小的数据类型转换成较大类型时,进行符号位扩展,可以保持数值不变。
截断
将 int 类型强制类型转换成 short(16bit) 类型时, int 类型(32bit)高 16 位数据被丢弃,留下低16位的数据,因此截断一个数字,可能会改变它原来的数值。
- 无符号数:
将一个w位的无符号数,截断成 k 位时,丢弃最高的 w-k 位,截断操作可以对应于取模运算,即除以 2 的 k 次方之后得到的余数。 - 有符号数:
我们用无符号数的函数映射来解释底层的二进制位,这样一来我们就可以使用与无符号数相同的截断方式,得到最低 K 位;
我们将第一步得到的无符号数转换成有符号数。
无符号加法
unsigned char a=255;
unsigned char b=1;
unsigned char c=a+b;
printf("c=%d",c);
我们其期望的结果是256
实际为0
产生这个结果的原因是a+b超过了unsigned char 类型能表示的最大值255
’
无符号加法溢出
判断运算结果是否发生了溢出的函数
c语言不会自动判断
int uadd_ok(unsigned x,unsigned y){
unsigned sum=x+y;
return sum>=x;//溢出返回0,每一处返回1
}
补码加法溢出
有符号数的溢出分为正溢出和负溢出
-
正溢出
当x+y的和大于等于2^(w-1)时,发生正溢出,此时得到的结果会减去2^w -
负溢出
当x+y的和小于-2^(w-1)时发生负溢出,此时,此时得到的结果会加上2^w
char x=127;
char y=1;
char z=x+y;
printf("z=%d",z);
运行结果为-128,发生了正溢出
两种乘法
-
无符号数乘法
w位的无符号数x和y,二者的乘积可能需要2w位来表示,在c语言中,定义了无符号数乘法所产生的结果是w位,因此,运行结果会截取2w位中的低w位。截断采用取模的方式,运行结果等于x与y的乘积并对2的w次方取模 -
补码乘法
计算机的有符号数用补码来表示,补码乘法就是有符号数乘法,无论是无符号数乘法还是补码乘法,运算结果的位级表示都是一样的,只不过补码乘法比无符号数乘法多一步,需要将无符号数转换成补码(有符号数),虽然完整的乘积位级表示可能会不同,但是阶段后的位级表示都是相同的
两种除法
-
原码运算
对于一般的以2^w为因子的乘法,我们只需要对原码进行移动,相当于所有位数向左移动一个单位 ,即为1010=[10],除法只需要进行右移即可,对于原码不论正负,若某个数字乘2^w的倍数,则只需要对原码向左移动w个单位,空缺位补0 -
补码运算
对于补码,正数仍然按照原码规则进行计算,负数需要保证符号位不变,在向左移动时补零,向右移动时补1
【-5】补=1011,将其乘以2,则保持符号位的最高的1不变,其余位置向左移动一个单位,空出来的最后册加0,则为10110=【-10】补码 -
二进制小数
考虑含有小数值的二进制数,可以表示成下面这种方法

这种定点表示方法不能表示非常大的数
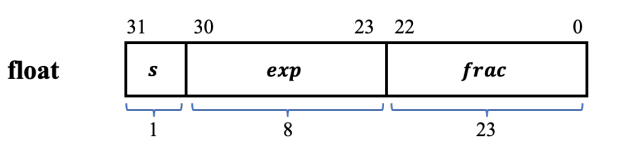
IEEE浮点表示(单精度)
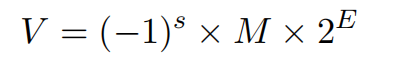
s:符号(31)
s=0:正数
s=1: 负数
e(exp): 阶码(23-30)8
w(frac): 尾数(0-22)23
32bit的float被这样划分
IEEE浮点表示(双精度)
对于64位双精度浮点数,二进制位与浮点数的关系
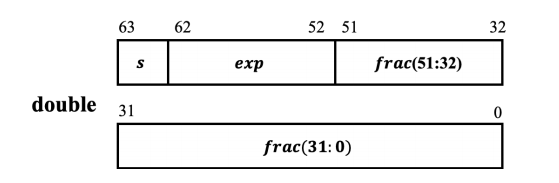
与单精度浮点数相比,双精度浮点数的符号位也是1位,阶码字段的长度为11位,小数字段的长度为52位
浮点数的数值
浮点数的数值可以分为三类(阶码的值决定)
- 规格化的值
阶码字段不全为0 - 非规格化的值
阶码字段二进制位全为0 - 特殊值
阶码字段全为1
- 无穷大
- 无穷小
- 不是数
规格化的值
单精度阶码的取值范围(00000001(1)-1111110(254))
双精度阶码的取值(1,2047)
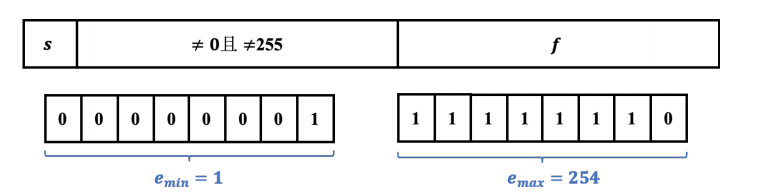
用小写e来表示这个8位二进制数
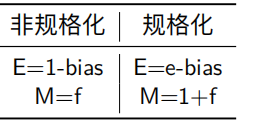
bias偏置量,偏置量的值与阶码字段的位数是相关的
阶码:E=e-bias
E=e-bias
bias
单精度。阶码字段长:8
bias(float)=(2^(8-1)-1)=127
双精度,阶码字段的长度:11
bias(double)=(2^(11-1)-1)=1023
e(float)[1-254],E=[-126,127]
e(double)[1-2047],E=[-1022,1023]
尾数M(frac)被定为1+f,单精度尾数的二进制表示
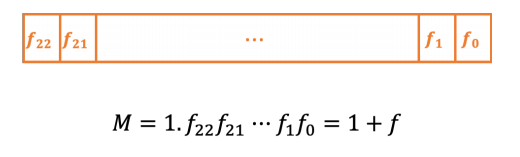
bias看精度
E=e-bias
M=1+f
非规格化的值(全为0)
阶码字段的二进制全为0
非规格化的数的两个用途(0andlimit=0)
-
- 两种表示数值0的方法,正零,负零
- 当符号位等于0,阶码字段全为0,小数字段也全为0的时候,此时表示正零。
- 当符号位s等于1,阶码字段全为0,小数字段也全为0的时候,此时表示负零。
-
- 非规格化的数是可以表示非常接近0的数。
当阶码字段的数是可以表示非常接近0的数,当阶码字段全为0的时候,阶码E的值等于1-bias,而尾数的值M=f,不包含隐藏的1。
E=1-bias
M=f
- 非规格化的数是可以表示非常接近0的数。
特殊值
阶码字段全为1,小数字段全为0时表示无穷大的数
两种无穷大
无穷大:阶码字段全为1,小数字段(f)全为0
- 正无穷大
s=0 - 负无穷大
s=1
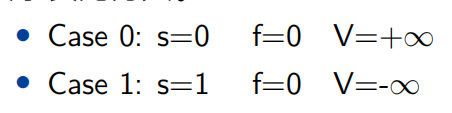
NaN(不为实数,且无法用无穷表示)
(阶码字段全为1,小数字段(f)不为0)
- 对-1开方
- 无穷减无穷
example:整数转单精度浮点型(float)
整型数12345转换成浮点数12345.0
整型数 12345
二进制数:
int 12,345
0000 0000 0000 0000 0011 0000 0011 1001
虽然int类型的变量占32bit,该数的高18=0
可以只看低14位
11 0000 0011 1001
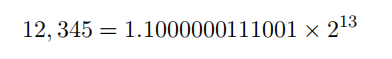
单精度的小数字段长度=23,需要多在末尾增加10个零
1 0000 0011 1001 0000 0000 00
得到浮点数的小数字段
从上图可以发现阶码E的值=13
单精度浮点数的bias=127=(2^(8-1)-1)
根据公式E=e-bias 根据公式 E=e-bias 可以计算出
e=E+bias=13+127=140
e的二进制表示
e=140=(1000 1100)B
得到阶码字段

浮点数只能近似的表示实数运算
舍入
舍入的概念
对于值x,可能无法用浮点形式来精确地表示,因此我们希望可以找到**“最接近的值x”来代替x**,这就是舍入操作的任务。
四种不同的舍入方式
-
- 向偶数舍入
向最接近的值进行舍入(优先偶数)

- 向偶数舍入
-
- 向零舍入
把正数进行向下舍入,把负数进行向上舍入
- 向零舍入
-
- 向下舍入(平均值偏低)
总是朝着小的方向进行舍入
- 向下舍入(平均值偏低)
-
- 向上舍入(平均值偏高)
总是朝着大的方向进行舍入
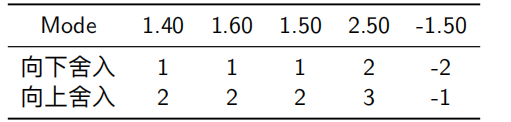
- 向上舍入(平均值偏高)
当遇到两个可能结果的中间数值的时候,舍入结果应该如何计算
向偶数舍入的结果要遵循最低有效数字是偶数的规则
避免了统计偏差,有一半向上舍入,有一半向下舍入
舍入example
-
将下面两个十进制小数精确到百分位
1.2349999(1.23)
1.2350001 (1.24)
这两个不是中间数(1.2350000)不需要考虑百分位是否为偶数
中间数(1.2350)考虑百分位是否为偶数,舍入百分位为偶数的1.24 -
向偶数舍入可以用在二进制小数上,将最低有效位的值0认为偶数,1认为奇数
例如10.11100当舍入小数点右边两位(百分位),这个数可能的两个值(11.00/10.11)的中间值,舍入的结果为(11.00)(偶数)
浮点运算加法需要注意的点
加法不具有结合性
- (3.14+1e10)-1e10=0.0
- 3.14+(1e10-1e10)=3.14
1对结果进行了舍入导致3.14丢失
乘法不具有分配性
(1e20*1e20)*1e-20=-∞
1e20*(1e20*1e-20)=1e20
1e20*1e20溢出失去精度
失去精度
- 溢出
- 舍入
乘法在加法上不具备分配性
1e20*(1e20-1e20)=0.01e20*1e20-1e20*1e20=NaN
2溢出失去精度
浮点运算的tips
- 缺乏结合性和分配性是一个比较严重的问题
- 当int ,float,double不同数据之间进行强制类型转换的时候,得到的结果可能会超出我们的预期
- int(32位)转换成float(s,exp,frac),数字不会溢出,但是可能会被舍入,这是由于单精度浮点数的小数字段是23位,可能出现无法保留精度的情况
- double(64bit(52))类型转换成float(bit(23))类型,由于float类型表示熟知的范围更小,所以可能会发生溢出
- float类型的精度相对于double较小,转换后还可能被舍入
- float类型或者double类型的浮点数转换成int类型,可能出现两种情况
-
- 向零舍入
-
- 发生溢出
-
计算机中的运算
整数4字节
实数4或8字节
复数8或16字节
内存空间有限,不能存储所有范围的数字
有限精度的运算:任何实数的代表都会导致存储的数字之间
许多结果都是无法表示的,任何导致这种数字的运算都必须通过发出错误或近似的结果来处理。
位运算
奇校验码 每个数位相异或
偶校验码 每个数位相异或取反
得到的奇校验码或偶校验码为1分别说明二进制1位数是奇数或偶数
二进制判断奇偶数就看二进制的最后一位
也就是将它与1相与,如果等于1就是奇数,如果等于0就是偶数
整数
整数通常以16,32或64位存储,64位则越来越多,这种增长的主要原因是整数被用于数组索引
数据集的增长需要更大的索引,1个32位的索引可以存储4GB的内存,对于更大数据集的需求使得64位索引成为必要
- 保留一位为符号位,剩下的31位为绝对大小。

- 将无符号数n解释为n-B
B是合理的基数,例如2^31

正负数旋转数线,将零的模式放回零处
二进制补码
二进制补码,整数的表示方法正式定义如下


- 每个整数对应的比特只有一个,没有重叠,特别是只有一个零
- 正数的前导位为0,负数前导位为1
- 假如有一个正数,可以通过翻转所有位然后加1,得到-n
整数溢出(overflow)
两个相同符号的数字相加,或者两个任意符号的数字相乘,c语言不会提示溢出
首先是非法的转换
还有就是除以0.0,出现浮点数溢出

除以0的情况,不输出

二进制加法
无符号数处理硬件处理有符号数
假定
求m+n
- 在
2^31以下得到正确结果,以上出现整数溢出

- m>0,n<0 ,m+n>0
范围为-2147483648~+2147483647,无符号情况下表示为0~4294967295。
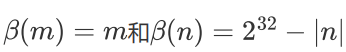
无符号加法变为
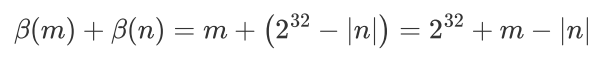
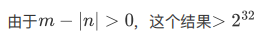
将这个数存储在33位得到正确的结果m-n,加上33位的一个比特
- m>0,n<0,m+n<0
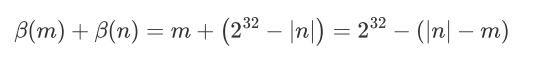
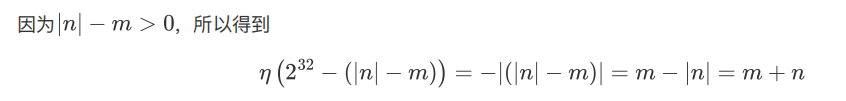
二进制数减法
两个整数的比较
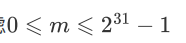
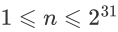
计算m-n的时候会发生什么
变成无符号加法
m+(2^32-n)
-
- 当m<|n|
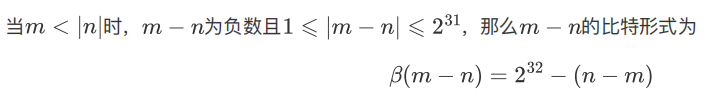

- 当m<|n|
-
- 当m>n
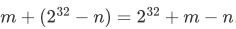
m-n>0,这个数大于2^32,将数字存储在33位得到正确的结果,加上33位的一个比特。
忽略溢出位
- 当m>n
1/10无法用二进制精确表示(重复)
使用bcd方案可以表示,但浪费位数很多
IBM Power架构支持
实数
1/3=0.33…使用二进制十进制无法准确表示
实数的表示
科学符号:一个显数和一个指数来表示
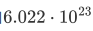
显数:6022
指数23
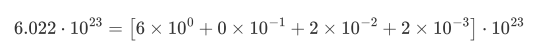
基数 计算机数字中是2
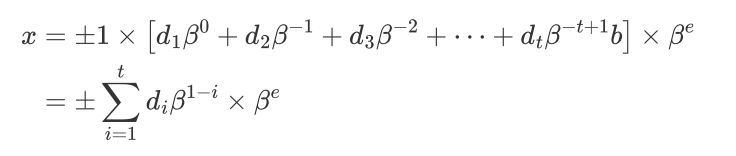
组成部分

符号位 :存储数字是整数还是负数的一个位
基数 β 数字系统的基数
0<=di<=β-1尾数或显数的位数 小数点的位置被隐含地假定为小数,小数点的位置被隐含地假定为紧随第一位的位置
t 尾数的长度
e∈[L,U]指数,通常L<0<U和L≈-U
e是超过某个最小值的无符号数字
数字0的比特模式被解释为e = L
溢出和下溢
不能表示
-
太大太小,落在空白处的数字
-
经过四舍五入或者截断才能表示,舍入误差分析领域的基础。

溢出我们可以存储的最大数字,其每个数字都等于β
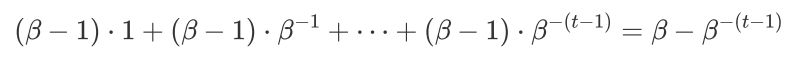
最小的数字是-(β-β^-(t-1))
- 任何大于前者或小于后者的情况都会导致溢出,大于前者或者小于后者都会导致溢出的情况发生
- 下溢最接近零的数字是
β-(t-1)*L,如果计算结果小于该值,就会导致一种叫做下溢的情况 - 只有少数实数可以被精确表示,这一事实是舍入误差分析领域的基础
- 溢出或者下溢的发生意味着你的计算将从这一点上出错,溢出将使计算本应是非零的地方以零进行,溢出被表示为inf,简称无限
计算遇到结束的情况是告诉编译器一个中断,用一个错误信息来停止计算
归一化和非归一化的数字
浮点数的一般定义
第一个数字是非零的的数字是归一化的

在二进制数的情况下,是第一个数字总是1,IEEE754标准中,每个浮点数的形式为
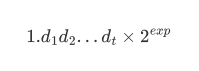
只有数字d1d2…dt被存储
下溢的重新定义
任何小于1*βL的数字现在都会导致下溢
渐进式下溢
试图计算一个绝对值小于该值的数,有时会通过使用非正常化的浮点数来处理
指数的特殊值不规范,在IEEE标准算术情况下是通过一个零指数域来实现的
这种比普通的浮点数计算要慢几十或几百倍
表示性误差
一个在计算机的数字系统中无法表示的实数
通过
普通四舍五入,向上四舍五入,向下四舍五入或者截断来近似表示,一个机器数x是它周围的所有x的代表,在尾数为t的情况下,这是与x不同的数字区间
在t+1个数字中,对于尾数部分,我们得到



机器精度
机器精度是计算可达到的最大精度
要求单精度超过6位或者更多位数的精度,或者双精度超过15位,是没有意义的

对齐指数可以转移一个太小的操作数,在加法中这个操作数被忽略

IEEE 754二进制算术被ISO/IEC/IEEE 6055:2011取代
IEEE 854允许十进制算术

两个特殊量
- Inf无穷大
- NaN不是一个数字
Inf是指溢出或者除以0的结果
NaN:inf-inf
浮点数异常
异常
异常的结果取决于错误的类型

- 安静的NaN
- 信号NaN


建议使用NaN的最有效位is_quiet来区分这两个NaN
除以零
inf,如果一个结果不能作为一个有限的数字来表示,就会引发这个异常
下溢
如果一个数字太小,不能被表示,就会出现这个异常
不精确
如果出现不精确的结果,例如平方根,就会引发这个异常,如果没有在范围内,就会出现溢出
舍入误差分析
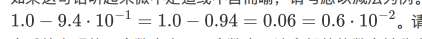
警戒位:声明的两个数字多了一个数字,这个多的数字就是警戒位
如果没有警戒位,这个运算中的9.4*10^-1=0.9
多重添加操作(FMA)

FMA可能比单独的乘法和假发更加精确,可以对中间结果使用更高的精度,例如使用80位扩展精度格式;
将涉及两次舍入
一次在乘法之后,一次在加法之后
一个FMA单元比单独的加法乘法单元更便宜
加法
指数对齐,两个数字中的较小的数字被写成较大的数字具有相同的指数。再加上尾数,最后对结果进行调整,使其再次成为一个标准化的数字
乘法
- 指数相加
- 尾数相乘
- 尾数被归一化
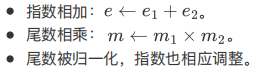

减法

关联性
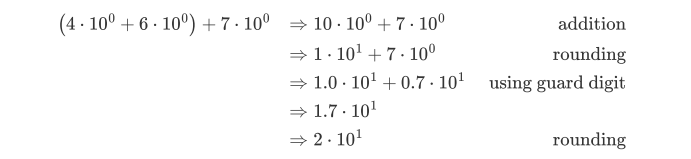
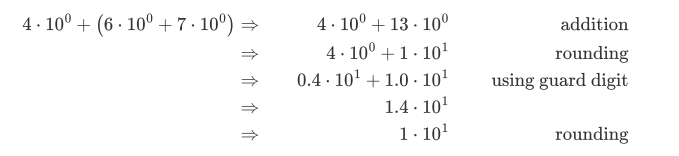
从较小的数字开始会得到更准确的结果
浮点数不满足结合律
表达式的求值顺序是由编程语言的定义决定的,或者至少是由编译器决定的
舍入误差的例子

并行运算中的舍入误差


c语言、c++中的类型标识符





打印位元模式

重新关联


常量表达式

表达式评估
在评估表达式 a+(b+c)时处理器会产生一个中间结果为b + c,这个结果没有分配给任何变量。
浮点单元的行为
四舍五入行为 (截断与四舍五入) 和渐进下溢的处理可由库函数或编译器选项控制。
改变舍入行为

设置四舍五入行为可以作为一个快速测试算法稳定性的方法
捕获异常情况
异常这个词有几种含义。
- 浮点异常是指“无效数字”的发生,比如通过溢出或除以零
- 如果发生任何类型的意外事件,编程语言可以"抛出异常",也就是中断正常的程序控制流程。
- gcc可以通过ffpe-trap=list捕获异常
其他计算机运算系统
扩展精度
英特尔处理器有80位寄存器用于存储中间结果
这些80位寄存器有一个奇怪的结构,有一个显著的整数位,可以产生不是任何定义数字的有效表示的位模式
定点运算

定点数字:N+F位存储

定点计算的用途


复数
c语言没有
c99和c++都有一个复数.h头文件
complex.h
如果经常只访问一个数组,最后单独为实部和虚部分配一个数组
- 从稳定性的角度来看,数学上的等价运算不需要表现得完全一样
- 即使是相同计算的重新排列也不会有相同的表现
- 必须分析计算机算法中的舍入行为
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









