






--------------------------------------------------------------问题------------------------------------------------------------

我原来模型保存是用ModelCheckpoint自动保存的,生成的是model.h5
然而用keras.models.load_model加载该模型时出现非utf-8编码方式,无法解码的bug
![]()

于是以为是保存的模型有问题,随参照网上用model.save保存模型,命名为model.keras

仍然用keras.models.load_model还是出现相同的bug
也试过把keras.models.load_model换成tf.keras.models.load_model,bug还是没变
------------------------------------------------------解决方法--------------------------------------------------------------
修改模型存放的路径(路径不能包含中文名!!!)

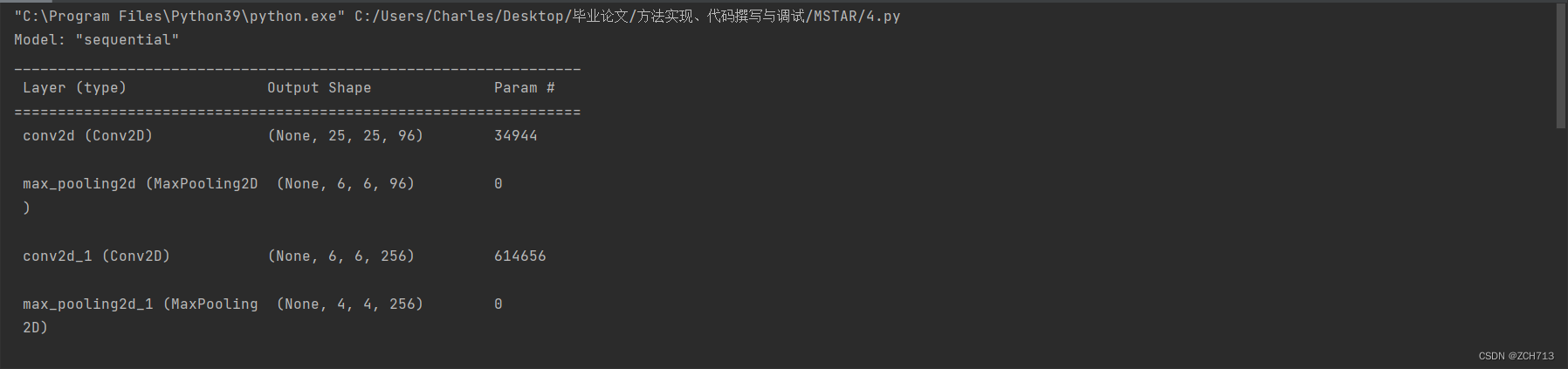
下面我用修改路径后的模型打印了一下模型架构是可以的















 4907
4907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











